netty is used in the work, mainly to extend ChannelHandler, which can not avoid encoding and decoding the agreed protocol, so it is recorded.
Analysis of netty semi packet processor
Decoding is the process of converting binary stream into business data, that is, converting byte [] into business data that we can understand. netty provides the ByteToMessageDecoder, which is a half package processor. We need to rewrite it
decode is enough, but due to the problem of tcp packet sticking and unpacking, the received data needs to be split into a complete packet before decoding.
The difficulty of converting byte [] into message in the application layer lies in how to determine that the current packet is a complete packet. There are two schemes:
1. The thread listening to the current socket waits until the received byte can form a packet. The disadvantage of this method is to waste a thread to wait.
2. The second scheme is to build a local cache for each monitored socket. If the current monitoring thread encounters insufficient bytes, it will first store the obtained data in the cache, and then process other requests. When there is data here, it will continue to write new data into the cache until the data constitutes a complete packet.
ByteToMessageDecoder adopts the second scheme. There is an object ByteBuf in ByteToMessageDecoder, which is used to store the byte data received by the current Decoder.
Let's take a look at the ByteToMessageDecoder code. The core is here. How to disassemble a complete package
public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter {
ByteBuf cumulation;
private Cumulator cumulator = MERGE_CUMULATOR;
private boolean singleDecode;
private boolean decodeWasNull;
private boolean first;
private int discardAfterReads = 16;
private int numReads;
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {//The input parameter msg is ByteBuf, and the byte stream read by the channel is saved to the buffer msg
if (msg instanceof ByteBuf) {
RecyclableArrayList out = RecyclableArrayList.newInstance();//It is considered as a list, which stores multiple complete binary stream data read
try {
ByteBuf data = (ByteBuf) msg;//Binary stream
//Judge that calculation = = null; And assign the result to first. Therefore, if first is true, it means that data is received for the first time
first = cumulation == null;
if (first) {
cumulation = data;//If the data is received for the first time, the received data is directly assigned to the cache object calculation
} else {
// If it is not the first decoding, append data to the calculation and release data
//If the remaining space in the calculation is insufficient to store the received data, expand the capacity of the calculation
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);
}
// After getting the additional cumulation, we call the decode method to decode.
// In the decoding process, the fireChannelRead method is called, and the main purpose is to decode the content of the cumulative area to the array out.
callDecode(ctx, cumulation, out);
} catch (DecoderException e) {
throw e;
} catch (Throwable t) {
throw new DecoderException(t);
} finally {
//If there is no data readable in the calculation, it means that all binary data has been parsed
//At this time, release the calculation to save memory space.
//On the contrary, if the calculation is readable, the statement in if will not run because the calculation is not released
//Therefore, the binary data that has not been parsed by the user is cached.
if (cumulation != null && !cumulation.isReadable()) {
numReads = 0;// Zero the number of times
cumulation.release();// Release accumulation area
cumulation = null;// Accelerated ygc
} else if (++ numReads >= discardAfterReads) {
// If it exceeds 16 times, the cumulative area will be compressed, mainly discarding the read data and zeroing the readIndex.
// We did enough reads already try to discard some bytes so we not risk to see a OOME.
// See https://github.com/netty/netty/issues/4275
numReads = 0;
discardSomeReadBytes();
}
int size = out.size();
// If no data has been inserted into the array
decodeWasNull = !out.insertSinceRecycled();
// Loop the array and send data to the following handler. If the array is empty, it will not be called
fireChannelRead(ctx, out, size);
// Empty the contents of the array and restore the subscript of the array to the original value
out.recycle();
}
} else {
//If the msg type is ByteBuf, call the next handler directly for processing
ctx.fireChannelRead(msg);
}
}
//The callDecode method is mainly used to parse the data in the calculation and put the parsed results into the list < Object > out.
//Since the binary data cached in the calculation may contain multiple pieces of valid information, the decode method will be called multiple times by default in the callDecode method
//When overriding the decode method, we only parse one message at a time and add it to out. callDecode calls back to decode multiple times
//The same list < Object > out instance is passed in every time, so the message parsed every time is stored in the same out instance.
//When there is no data in the calculation to continue reading, or the number of elements in the list < Object > out does not change after calling the decode method, the callback of the decode method will be stopped.
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
try {
//If there is data readable in the calculation, keep calling decode in a loop
while (in.isReadable()) {
//Gets the number of elements in out after the last decode method call. If it is the first call, it is 0.
int outSize = out.size();
if (outSize > 0) {
//Use the ChannelRead method of the following business handler to read the parsed data
fireChannelRead(ctx, out, outSize);
out.clear();
// Check if this handler was removed before continuing with decoding.
// If it was removed, it is not safe to continue to operate on the buffer.
//
// See:
// - https://github.com/netty/netty/issues/4635
if (ctx.isRemoved()) {
break;
}
outSize = 0;
}
int oldInputLength = in.readableBytes();
//Callback the decode method, which is overwritten by the developer. It is used to parse the binary data contained in in and put the parsing result in out.
decode(ctx, in, out);
// Check if this handler was removed before continuing the loop.
// If it was removed, it is not safe to continue to operate on the buffer.
//
// See https://github.com/netty/netty/issues/1664
if (ctx.isRemoved()) {
break;
}
//outSize is the size of out in the last decode method call, out Size () is the current out size
//If the two are equal, it means that the current decode method call does not resolve valid information.
if (outSize == out.size()) {
//At this time, if it is found that the last time the decode method is called and the current decode method is called, the number of remaining readable bytes in is the same
//It means that the decode method does not read any data parsing
//(it may be a problem such as half package, that is, the remaining binary data is not enough to form a message), jump out of the while loop.
if (oldInputLength == in.readableBytes()) {
break;
} else {
continue;
}
}
//Dealing with human error. If you come to this code, it means outsize= out. size().
//That is, the decode method actually parses the valid information and puts it into out.
//But oldinputlength = = in Readablebytes(), indicating that no data is read in this decode method call
//But the element in out is added.
//This may be because the developer wrote the code incorrectly. For example, mock put a message into the List.
if (oldInputLength == in.readableBytes()) {
throw new DecoderException(
StringUtil.simpleClassName(getClass()) +
".decode() did not read anything but decoded a message.");
}
if (isSingleDecode()) {
break;
}
}
} catch (DecoderException e) {
throw e;
} catch (Throwable cause) {
throw new DecoderException(cause);
}
}
}
Let's take the FixedLengthFrameDecoder as an example to see how to parse and process a complete message
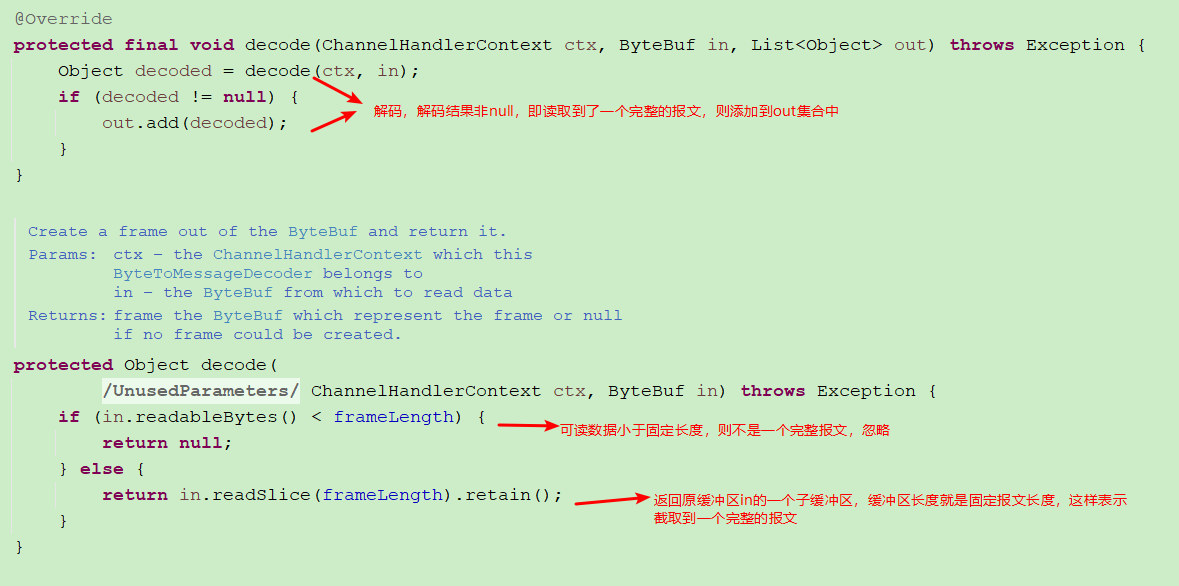
Here, the main logic of channelRead() is:
1. Fetch an empty array from the object pool;
2. Judge whether the member variable is used for the first time. Note that since the member variable is used here, this handler cannot be a handler in @ shareable state, otherwise you can't tell which channel the member variable is from. Write the data passed from unsafe into the ac cumulation area;
3. after writing to the cumulative area, the decode method of the subclass is called to try to decode the contents of the accumulated area, and each successful decode one calls the channelRead method of the latter node. If the decoding is not successful, do nothing;
4. If there is no unread data in the accumulation area, release the accumulation area;
5. If there is still unread data and the decoding exceeds 16 times (default), compress the accumulation area. Clear the read data, that is, set readIndex to 0;
6. Set the value of decodeWasNull. If no data was inserted last time, this value is true. When calling the channelReadComplete method, this value will trigger the read method (if not automatic reading), try to read data from the JDK channel, and repeat the previous logic. The main reason is that if you execute channelReadComplete without inserting any data, you will miss data;
7. Call the fireChannelRead method to send the elements in the array to the following handler;
8. Empty the array. And return it to the object pool.
After the data is added to the accumulation area, you need to call the decode method to decode. See the callDecode() method above for the code. The key code in callDecode() is to take the parsed data and call the decode(ctx, in, out) method. Therefore, if we inherit the ByteToMessageDecoder class to implement the logic of our own byte flow object, we need to override this method.
netty validation demo is as follows
Server
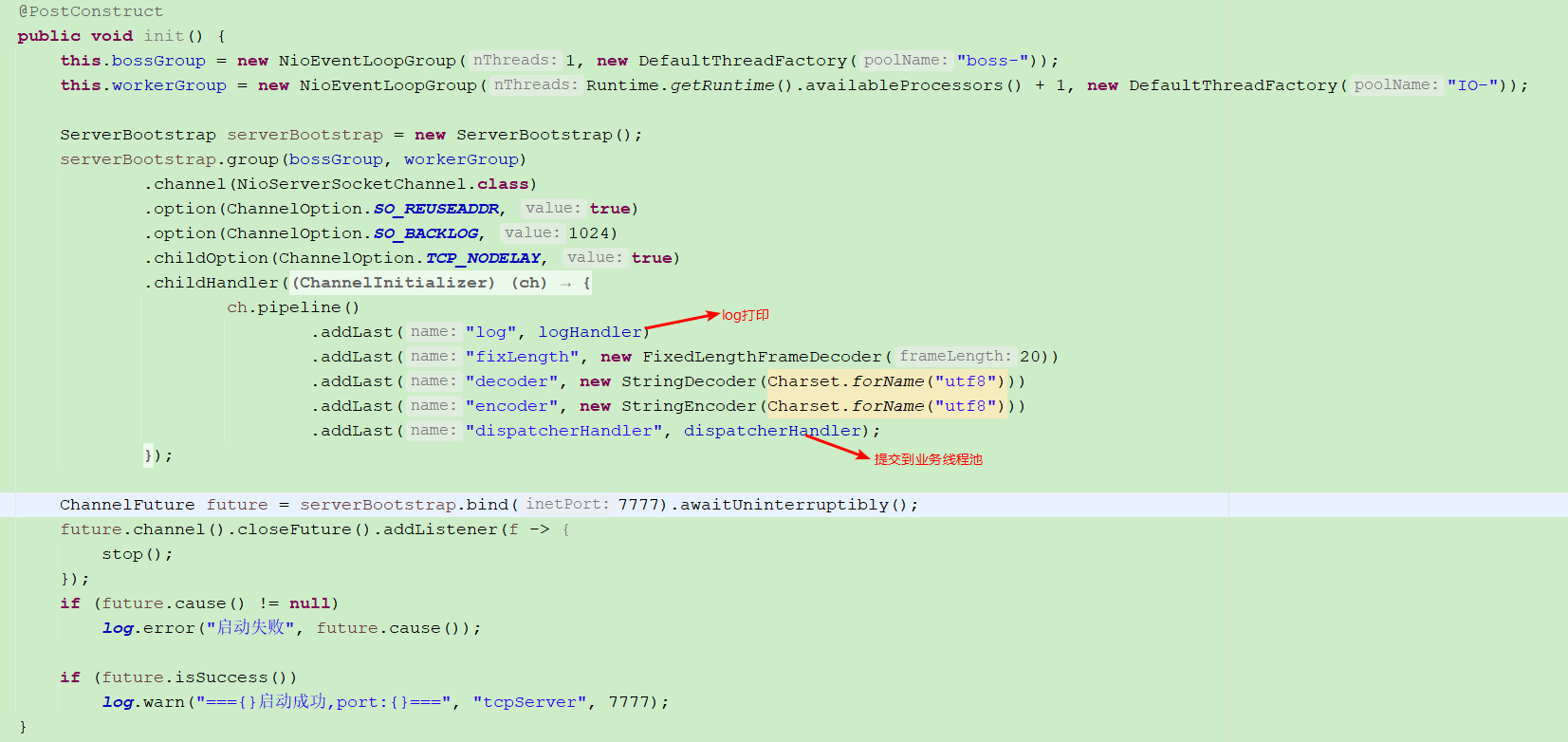
Verify sticking and unpacking
client
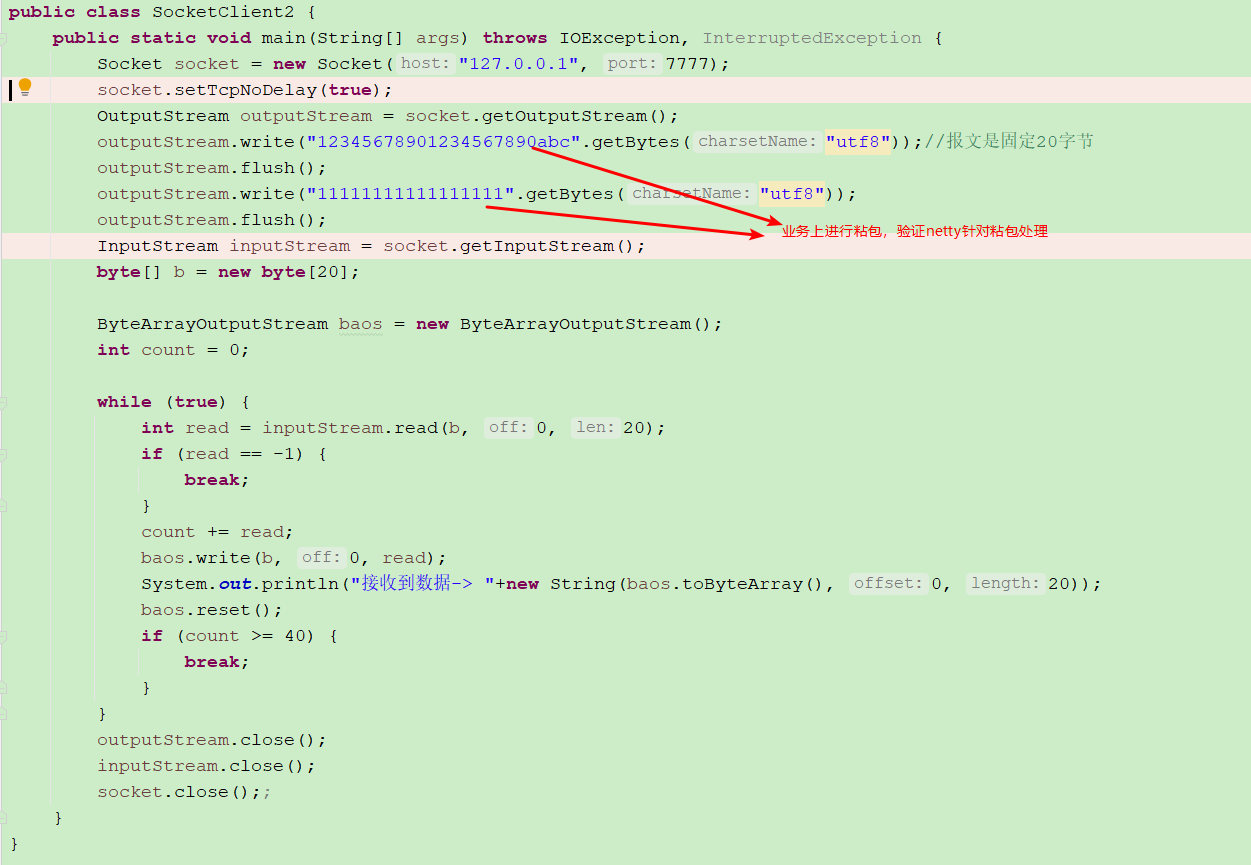
Through verification, it is found that for sticking and unpacking, netty will cache the read data to the buffer of the Channel, i.e. io netty. handler. codec. ByteToMessageDecoder#cumulation
For example, the first transmission: 123456789001234567890abc has a total of 23 bytes. The netty server reads 23 bytes, but only intercepts 20 bytes (intercepted by FixedLengthFrameDecoder) as a complete package to trigger the channelRead of pipeline.
Then send it for the second time: 11111111111111111111 has a total of 17 bytes. The netty server reads 17 bytes and accumulates them to the buffer calculation. Plus the last 3 bytes, it has a total of 20 bytes. It is a complete packet, and then triggers the channelRead of pipeline.
From the FixedLengthFrameDecoder, we can see that our general method for extending ByteToMessageDecoder is to read the binary stream from the input buffer, append it to the Channel buffer calculation, then intercept the buffer calculation, intercept a complete package, and then decode the package into business data. Then continue to loop to intercept the cumulative buffer calculation. If there is less than a complete package, the pipeline will not be passed back. For us, a complete package intercepted from the ac cumulation buffer should be saved to the input parameter list < Object > out.
Verify that the client writes one byte at a time
In the past, when tomcat had only bio, it was accessed by an accept thread, and then the socket was submitted to the business thread pool. The business thread read the input stream, decode, process, encode and output. If the client writes a byte, sleeps for 5s, and then writes another byte, then a client opens 200 threads, which can brush all the server threads. After using netty, what can be done to solve this problem? Or cumulative buffer io netty. handler. codec. Bytetomessagedecoder #calculation: write a byte to trigger the read event, and then the single byte is appended to the buffer calculation. Since it cannot be intercepted as a complete message (such as FixedLengthFrameDecoder), the pipeline does not trigger the backward propagation of channelRead until the client cheats and writes a complete package. Does this have any impact on the server? No, because the selector IO reading is non blocking, it will not cause IO thread blocking, so it has no impact.
Examples of customers tested are as follows
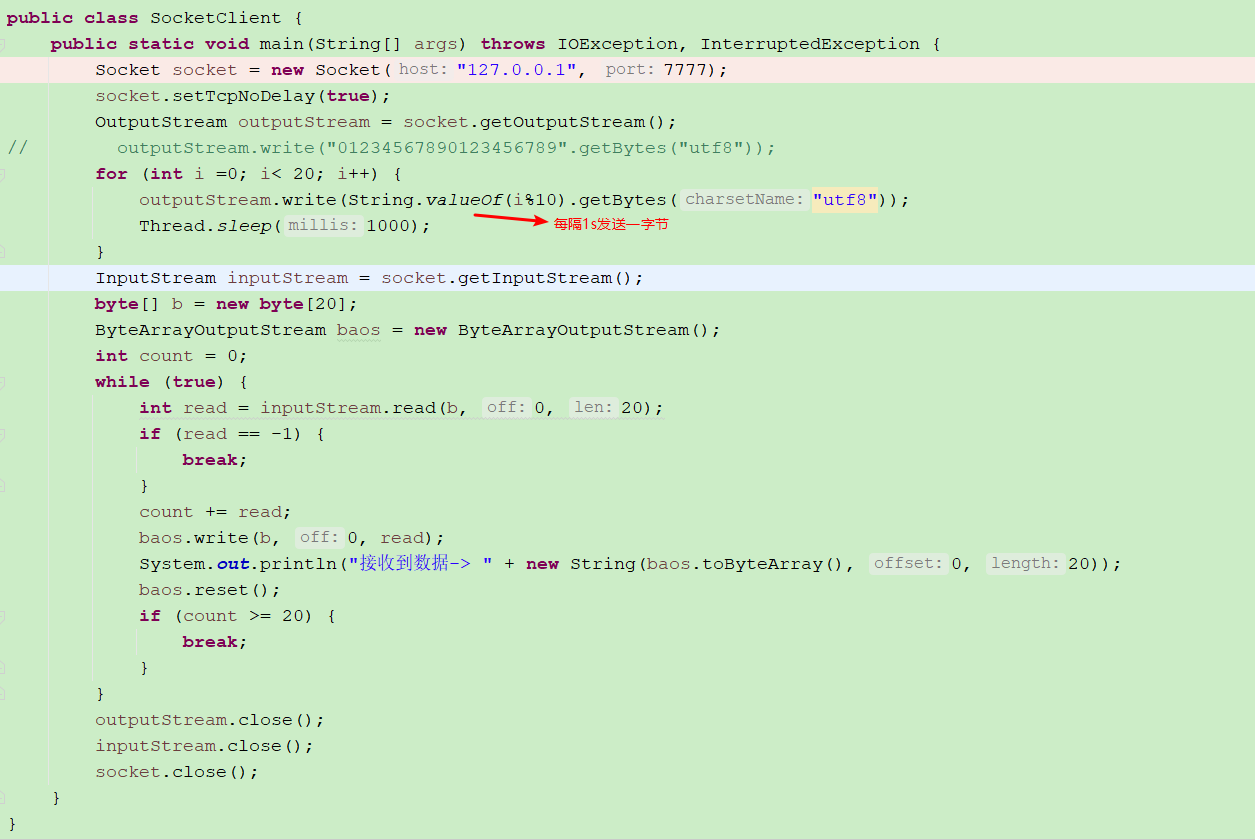
demo code in github Branch netty.
netty decoding summary
First, make sure to get a complete package (using the existing netty or inheriting the ByteToMessageDecoder rewrite), and then trigger the pipeline to decode. We can implement the decoding action ourselves (only inherit the inbound adapter, and we don't need to inherit the ByteToMessageDecoder)
netty Channel ac cumulation buffer
Each channel has a pipeline corresponding to it. If the pipeline has a decoder inherited from ByteToMessageDecoder, then the channel has a cumulative buffer ac cumulation. When is the cumulative buffer emptied? What is the maximum allowable size?
When the cumulative buffer is unreadable, it will be cleared. Unreadable means that the message is complete and has been decoded, that is, after all messages are decoded, the cumulative buffer will be cleared.
What is the maximum size of the ac cumulation buffer? It can't be seen from ByteToMessageDecoder.
Why is netty not suitable for transferring files
Netty handles the read event: the IO thread spins and handles the events of the channel registered on the Selector. NioEventLoop#run -> NioEventLoop#processSelectedKey(java.nio.channels.SelectionKey, io.netty.channel.nio.AbstractNioChannel) -> io. netty. channel. nio. AbstractNioByteChannel. NioByteUnsafe#read
@Override
public final void read() {
//ellipsis
ByteBuf byteBuf = null;
int messages = 0;
boolean close = false;
try {
int totalReadAmount = 0;
boolean readPendingReset = false;
do {
byteBuf = allocHandle.allocate(allocator);//Create buffer
int writable = byteBuf.writableBytes();
int localReadAmount = doReadBytes(byteBuf);//Write socket data to buffer
//ellipsis
pipeline.fireChannelRead(byteBuf);//Trigger channelRead of pipeline
byteBuf = null;
//ellipsis
} while (++ messages < maxMessagesPerRead);//Maximum 16 consecutive reads
pipeline.fireChannelReadComplete();//Trigger channelReadComplete of pipeline
//ellipsis
} catch (Throwable t) {
handleReadException(pipeline, byteBuf, t, close);
} finally {
//ellipsis
}
}
There are two reasons:
1. Because the EventLoop is executed serially, if the file is too large, the loop will end 16 times when reading the input stream. If this is the case for most channels, it will seriously block the read event processing of other channels.
2. After each reading, trigger the channelRead of pipeline and save the read data to the accumulation buffer io netty. handler. codec. Bytetomessagedecoder #calculation, which will cause the memory used by the accumulation buffer to be too large.
Why is dubbo not suitable for transferring problem pieces
The default maximum message size of dubbo is 8m. Why is this set? Why is it not recommended to transfer files or large messages in official documents?
The reasons are as follows:
1. The serialization adopted by Dubbo needs to serialize the object at one time. If the object is large (including files), serializing the object at one time and loading it into memory will lead to oom.
2. By default, Dubbo uses netty, which is a single connection model. A client has only one tcp connection to a server, and netty message sending is also serial unlocked. If an object is relatively large, it will cause the channel to write & flush all the time, resulting in blocking the sending queue of other channels (queuing in taskQueue can not be processed in time), The delay in sending will eventually lead to the timeout of other consumer s on the client.
3. Large objects will also cause the dubbo server to read, which will block the data reading of other channel s. For the same reason as 2, netty uses serial lock free. If one task executes, it will block other tasks.
Since the single connection model has this disadvantage, why should dubbo adopt it? Because of resource saving, tcp resources are valuable, and a single connection can meet the rpc scenario; rpc scenarios usually have few servers and many clients. If tcp connections are created for each client, the number of tcp connections will be full, because it is unknown how many clients will call the server.
dubbo can also use the multi connection model. When the client sends, it uses the polling mechanism to select a tcp connection from the tcp connection pool to send. But this is not usually recommended.
Therefore, dubbo is only suitable for business tabloid transmission (less than 8m by default), and is not suitable for large message and file transmission.
Why is http suitable for transferring files
http is suitable for transferring files from the client and server
client
Use httpclient and other tools to transfer files. For example, the file to be transferred is local. Only one Buffer size of the file is read at a time, and then the data of this Buffer can be sent through Socket; In this way, the data existing in memory at the same time will only have a Buffer size, which will not have the problem of reading all data into memory like Dubbo.
Server
For the web service container is tomcat, when Tomcat reads the form data, it will first temporarily store the message to the disk, and then read the message content in the disk through FileItem. Therefore, for the Server side, the complete message data will not be read into the memory at one time, so there will be no problem of excessive memory occupation.
Therefore, the normal upload files are uploaded by the client directly connected to the oss without passing through the intermediate system, which will not lead to the problems of connection blocking and bandwidth occupation of our system.