There are many kinds of Netty decoders, such as length-based, divider-based, private protocols. However, the overall thinking is the same.
Packet disassembly idea: When the data meets the decoding conditions, it is disassembled. Put it in an array. It is then sent to the business handler for processing.
Half-package idea: When the data read is not enough, save it until the decoding condition is satisfied, and then put it into the array. Send to business handler for processing.
Principle of unpacking
In the absence of netty, if the user needs to unpack, the basic principle is to constantly read data from the TCP buffer, and after each reading, it is necessary to determine whether it is a complete packet.
1. If the data currently read is not enough to be spliced into a complete business data package, keep the data and continue to read from the tcp buffer until a complete data package is obtained.
2. If the current read data and the read data are enough to splice into a data package, then the read data will be spliced onto the read data, so that the read data can be transmitted to the business logic as a complete business data package, and the redundant data will still be retained, so as to try to splice with the next read data.
Base Classes for Packing in netty
The unpacking in netty is the same as the above principle. In each Socket Channel, a pipeline will be added to the pipeline. The decoder inherits the base class ByteToMessageDecoder, and there will be an accumulator inside. Every time the data is read from the current Socket Channel, it will accumulate continuously, and then try to accumulate it to the base class ByteToMessageDecoder. The data is unpacked and decomposed into a complete business data package. Let's first analyze this class in detail.
The name means: a decoder that converts bytes into messages. People are like their names. And he is also an inbound handler, so we start with his channelRead method.
channelRead Method
Let's first look at the attributes in the base class. Cumulation is a ByteBuf-type accumulation area in this base class. Every time we read data from the current Socket Channel, it accumulates continuously. Then we try to unpack the accumulated data and break it into a complete business data package. If there is not a complete data package, then we can do so. Next time the TCP data arrives, continue to accumulate in this cumulation
public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter { //Accumulation area ByteBuf cumulation; private ByteToMessageDecoder.Cumulator cumulator; private boolean singleDecode; private boolean decodeWasNull; private boolean first; private int discardAfterReads; private int numReads; . . . }
channelRead method is called every time data is read from TCP buffer. The trigger point is in the read method of AbstractNioByteChannel. There is a while loop that reads continuously and triggers channelRead once read.
1 @Override 2 public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { 3 if (msg instanceof ByteBuf) { 4 // Extract one from the object pool List 5 CodecOutputList out = CodecOutputList.newInstance(); 6 try { 7 ByteBuf data = (ByteBuf) msg; 8 first = cumulation == null; 9 if (first) { 10 // First decoding 11 cumulation = data;//Direct assignment 12 } else { 13 // The second decoding will be data towards cumulation Additional and release data 14 cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data); 15 } 16 // Additional cumulation After the call decode Method decoding 17 // The main purpose is to accumulate the area. cumulation Content decode reach out Array 18 callDecode(ctx, cumulation, out); 19 } catch (DecoderException e) { 20 throw e; 21 } catch (Throwable t) { 22 throw new DecoderException(t); 23 } finally { 24 // If there are no readable bytes in the cumulative area, it may be above callDecode In the method, the cumulation Read it all, now writerIndex==readerIndex 25 // Every byte read, readerIndex Meeting+1 26 if (cumulation != null && !cumulation.isReadable()) { 27 // Zero the number of times 28 numReads = 0; 29 // Release accumulative zone,Because all the bytes in the accumulator have been read out. 30 cumulation.release(); 31 // Easy gc 32 cumulation = null; 33 // If more than 16 bytes have not been read, the read data will be discarded. readIndex Zero. 34 } else if (++ numReads >= discardAfterReads) { 35 numReads = 0; 36 //Discard the data you have read, and readIndex Zero. 37 discardSomeReadBytes(); 38 } 39 40 int size = out.size(); 41 decodeWasNull = !out.insertSinceRecycled(); 42 //Loop arrays, backward handler send data 43 fireChannelRead(ctx, out, size); 44 out.recycle(); 45 } 46 } else { 47 ctx.fireChannelRead(msg); 48 } 49 }
- Extract an empty array from the object pool.
- To determine whether the member variable is used for the first time, the data passed from unsafe is written into the cumulation accumulation area.
- After writing to the cumulative area, the decode method of the subclass is called in the callDecode method, and the content of the cumulative area is decoded. For each successful decoding, the channelRead method of the following node is called. If decoding is not successful, do nothing.
- If there is no unread data in the accumulation area, the accumulation area is released.
- If there is still unread data, and decoding more than 16 times (default), the accumulation area is compressed. Clear the read data, that is, set readIndex to 0.
- Call the fireChannelRead method to send the elements in the array to the handler that follows.
- Clear the array. It is returned to the object pool.
Here are the detailed steps.
Write Cumulative Zone
If the current accumulator has no data, it skips the memory copy directly and points the pointer of the byte container directly to the newly read data. Otherwise, it calls the accumulator to accumulate the data to the byte container.
ByteBuf data = (ByteBuf) msg; first = cumulation == null; if (first) { cumulation = data; } else { cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data); }
Let's look at the construction method.
protected ByteToMessageDecoder() { this.cumulator = MERGE_CUMULATOR; this.discardAfterReads = 16; CodecUtil.ensureNotSharable(this); }
You can see this.cumulator = MERGE_CUMULATOR; let's look at MERGE_CUMULATOR next.
public static final ByteToMessageDecoder.Cumulator MERGE_CUMULATOR = new ByteToMessageDecoder.Cumulator() { public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) { ByteBuf buffer; if (cumulation.writerIndex() <= cumulation.maxCapacity() - in.readableBytes() && cumulation.refCnt() <= 1) { buffer = cumulation; } else { buffer = ByteToMessageDecoder.expandCumulation(alloc, cumulation, in.readableBytes()); } buffer.writeBytes(in); in.release(); return buffer; } };
MERGE_CUMULATOR is a static constant in the class ByteToMessageDecoder, which overrides the cumulate method. Let's see how MERGE_CUMULATOR accumulates newly read data into byte containers.
The abstraction of ByteBuf in netty makes accumulation very simple, calling buffer.writeBytes(in) through a simple api, and adding new data to byte containers. In order to prevent the size of byte containers from being insufficient, expansion processing is carried out before accumulation.
static ByteBuf expandCumulation(ByteBufAllocator alloc, ByteBuf cumulation, int readable) { ByteBuf oldCumulation = cumulation; cumulation = alloc.buffer(oldCumulation.readableBytes() + readable); cumulation.writeBytes(oldCumulation); oldCumulation.release(); return cumulation; }
Expansion is also a memory copy operation. The added size is the size of the newly read data.
Pass the accumulated data to the business for unpacking
When the data is appended to the accumulation area, decode method is called to decode the data. The code is as follows:
public boolean isReadable() { //Written coordinates greater than read coordinates indicate that there is data to read. return this.writerIndex > this.readerIndex; } protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) { // If there are still readable bytes in the accumulator, decode them circularly because there are in It could be sticky packages, i.e. multiple times complete packages stick together and are connected by newline characters. // Underneath decode The method can only process a complete package, so the sticky package is processed in a loop here. while (in.isReadable()) { int outSize = out.size(); // Successful decoding of last loop if (outSize > 0) { // Processing a sticky package calls the following business once handler Of ChannelRead Method fireChannelRead(ctx, out, outSize); // take size Set to 0 out.clear();// if (ctx.isRemoved()) { break; } outSize = 0; } // Get readable bytes int oldInputLength = in.readableBytes(); // call decode Method: Put the decoded data into the channel out Array decode(ctx, in, out); if (ctx.isRemoved()) { break; } if (outSize == out.size()) { if (oldInputLength == in.readableBytes()) { break; } else { continue; } } if (isSingleDecode()) { break; } } }
Let's take a look at fireChannelRead
static void fireChannelRead(ChannelHandlerContext ctx, List<Object> msgs, int numElements) { if (msgs instanceof CodecOutputList) { fireChannelRead(ctx, (CodecOutputList)msgs, numElements); } else { //Downstream all decoded data hadder transmit for(int i = 0; i < numElements; ++i) { ctx.fireChannelRead(msgs.get(i)); } } }
The main logic of this method is that as long as the accumulated area has unread data, it can be read in a loop.
-
Call the decodeRemovalReentryProtection method, and call the decode method overridden by the subclass internally. Obviously, this is a template pattern. The logic of decode method is to decode the contents of the accumulated area according to the agreement, and if decoded successfully, add it to the array. At the same time, the method also checks the status of the handler. If it is removed from the pipeline, the content of the accumulated area will be refreshed directly to the later handler.
-
If the Context node is removed, the loop ends directly. If the size of the array before decoding is the same as that after decoding, and the number of readable bytes in the accumulated area remains unchanged, this reading will end directly without doing anything. If the number of bytes changes, it means that although the array has not increased, it is actually reading bytes, and then continue reading.
-
If the above judgment indicates that the array has read the data, but if the readIndex of the cumulative region does not change, an exception is thrown, indicating that the data has not been read, but the array has increased, and the operation of subclasses is incorrect.
-
If it is a single decoder, the decoding will end directly at one time, and if the data package is decoded at one time, then the in.isReadable() is false at the next loop, because writerIndex = this.readerIndex
So, the key to this code is that subclasses need to rewrite decode methods to decode accumulative data correctly and add it to the array. Each time the addition succeeds, the fireChannelRead method is called to pass the data in the array to the subsequent handler. Set the size of the array to 0 after completion.
So, if your business handler is in this place, it may be called many times. It may not be called at all. Depends on the values in the array.
The main logic of the decoder:
The data of read method is read into the accumulation area, and the data of the accumulation area is decoded by a decoder. Once the decoding is successful, the data in the array is put into an array, and the data in the array is transmitted to the handler one after another.
Clean up byte containers
After business unpacking is completed, only data is taken from the accumulation area, but this part of space is still reserved for the accumulation area, and the byte container adds the byte data to the tail every time it accumulates the byte data. If the accumulation area is not cleaned up, the time will be OOM, cleansing part of the code. as follows
finally { // If there are no readable bytes in the cumulative area, it may be above callDecode In the method, the cumulation Read it all, now writerIndex==readerIndex // Every byte read, readerIndex Meeting+1 if (cumulation != null && !cumulation.isReadable()) { // Zero the number of times numReads = 0; // Release accumulative zone,Because all the bytes in the accumulator have been read out. cumulation.release(); // Easy gc cumulation = null; // If more than 16 bytes have not been read, the read data will be discarded. readIndex Zero. } else if (++ numReads >= discardAfterReads) { numReads = 0; //Discard the data you have read, and readIndex Zero. discardSomeReadBytes(); } int size = out.size(); decodeWasNull = !out.insertSinceRecycled(); //Loop arrays, backward handler send data fireChannelRead(ctx, out, size); out.recycle(); }
- If there is no readable data in the accumulation area, zero the counter and release the accumulation area.
- If the above conditions are not met and the counter exceeds 16 times, the content of the accumulation area is compressed by deleting the read data. Set readIndex to 0. Remember the pointer structure of ByteBuf?
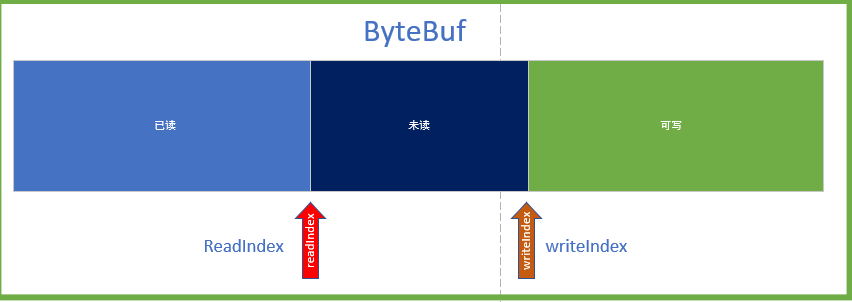
public ByteBuf discardSomeReadBytes() { this.ensureAccessible(); if (this.readerIndex == 0) { return this; } else if (this.readerIndex == this.writerIndex) { this.adjustMarkers(this.readerIndex); this.writerIndex = this.readerIndex = 0; return this; } else { //Read pointer exceeded Buffer Clean up half the capacity if (this.readerIndex >= this.capacity() >>> 1) { //Copy from readerIndex Start, copy this.writerIndex - this.readerIndex length this.setBytes(0, this, this.readerIndex, this.writerIndex - this.readerIndex); //writerIndex=writerIndex-readerIndex this.writerIndex -= this.readerIndex; this.adjustMarkers(this.readerIndex); //Reset the read pointer to 0 this.readerIndex = 0; } return this; } }
We see that discardSomeReadBytes mainly copy unread data to the original Buffer, reset readerIndex and writerIndex.
We see that we finally call the fireChannelRead method, trying to send the data in the array to the handler later. Why did you do that? Reasonably, at this point, the array can't be empty. Why should we send it again so cautiously?
If it is a single decoder, it needs to be sent, because the word decoder will not be sent in the callDecode method.
summary
It can be said that ByteToMessageDecoder is the core of the decoder. Netty uses the template pattern here, and the decode method is the method left for the extension of subclasses.
The main logic is to put all the data into the accumulation area, decode the data from the accumulation area and put it into an array. ByteToMessageDecoder will loop the array to call the handler method behind, sending the data frame by frame to the business handler. Complete this decoding logic.
In this way, whether it is sticking or unpacking, it can be perfectly realized.
All Netty decoders can be extended on this type, depending on the implementation of decode. Just follow the ByteToMessageDecoder agreement.