1, Introduction to reptiles
1. Concept
Web crawler (also known as web spider, web robot, more often called web chaser in FOAF community) is a program or script that automatically grabs World Wide Web information according to certain rules. Other infrequently used names include ants, automatic indexing, emulators, or worms.
2. Type
According to the system structure and implementation technology, web crawlers can be roughly divided into the following types: General Purpose Web Crawler, Focused Web Crawler, Incremental Web Crawler and Deep Web Crawler. The actual web crawler system is usually realized by the combination of several crawler technologies.
3. Scope of use
- As a web page collector of search engine, capture the whole Internet, such as Google, Baidu, etc.
- As a vertical search engine, capture specific topic information, such as video websites, recruitment websites, etc.
- As a testing tool for testing the front-end of the website, it is used to evaluate the robustness of the front-end code of the website.
4. Legality
Robots protocol: also known as robot protocol or crawler protocol, this protocol makes an agreement on the scope of the website content captured by the search engine, including whether the website wants to be captured by the search engine and what content is not allowed to be captured. Based on this, the Web Crawler "consciously" captures or does not capture the website content. Since its launch, robots protocol has become an international practice for websites to protect their own sensitive data and the privacy of Internet users.
5. Search strategy
Web page crawling strategies can be divided into depth first, breadth first and best first. Depth first will lead to the problem of crawler trapped in many cases. At present, the common methods are breadth first and best first.
6. Basic structure
- URL management module
- Download module
- Parsing module
- Storage module
2, Environmental preparation
Installation and configuration of Anaconda:
The most detailed Anaconda installation tutorial in history
Packages to install:
requests,beautifulsoup4,html5lib
The instructions are as follows:
pip install beautifulsoup4
pip install requests
pip install html5lib
3, Climb the ACM topic website of Nanyang Institute of Technology
ACM topic website of Nanyang Institute of Technology
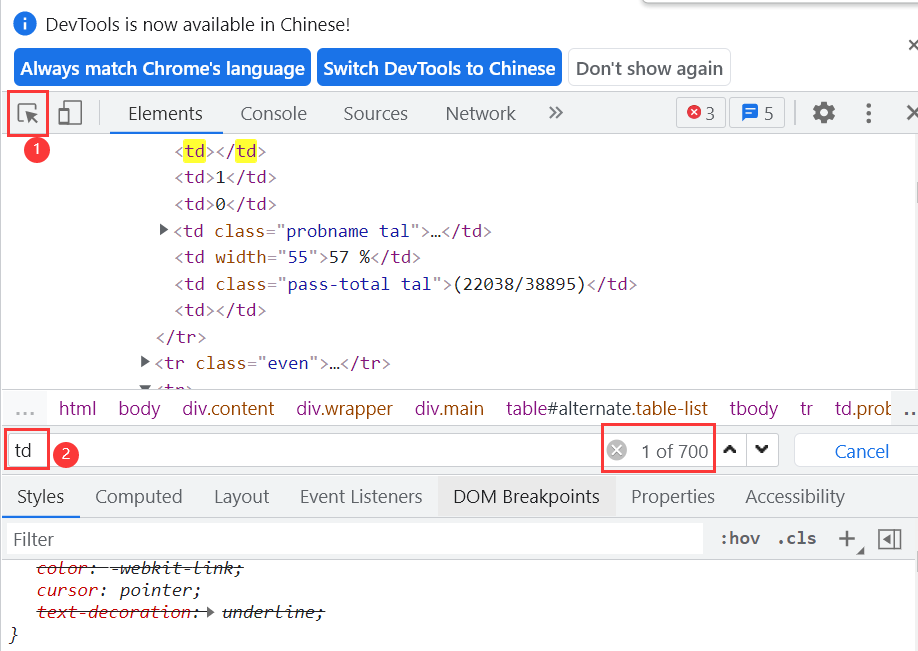
By viewing the web page source code, we can see that the title number, title, pass rate and other data we need are all in the TD tag of the figure
Press F12 on the website page to enter the developer mode. Enter td in the search box to display more than 700 relevant data
Create one where you need it csv file
Open the Jupiter notebook in anaconda for encoding
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# Simulate browser access
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# Header
csvHeaders = ['Question number', 'difficulty', 'title', 'Passing rate', 'Number of passes/Total submissions']
# Topic data
subjects = []
# Crawling problem
print('Topic information crawling:\n')
# tqdm job: displays the crawling progress in the form of progress bar
# Crawl all topic information on page 11
for pages in tqdm(range(1, 11 + 1)):
# get request page pages
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
# Abnormal judgment
r.raise_for_status()
# Set encoding
r.encoding = 'utf-8'
# Create a beautiful soup object to parse the html page data
soup = BeautifulSoup(r.text, 'html.parser')
# Get all td Tags
td = soup.find_all('td')
# Store all the information about a topic
subject = []
# Traverse all td
for t in td:
if t.string is not None:
subject.append(t.string) # Gets the string in td
if len(subject) == 5: # Every five is a topic of information
subjects.append(subject)
subject = []
# Storage topic
with open('F:/Anaconda3/project/1.csv(This is mine.csv (file path)', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) # Write header
fileWriter.writerows(subjects) # Write data
print('\n Topic information crawling completed!!!')
The operation results are as follows:
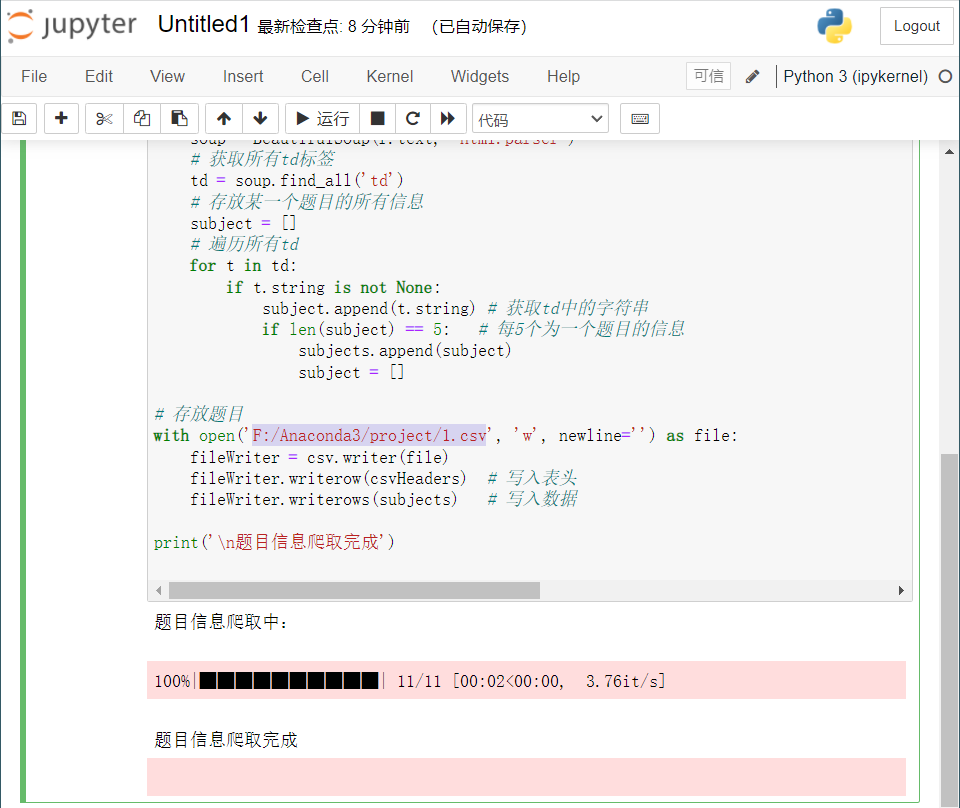
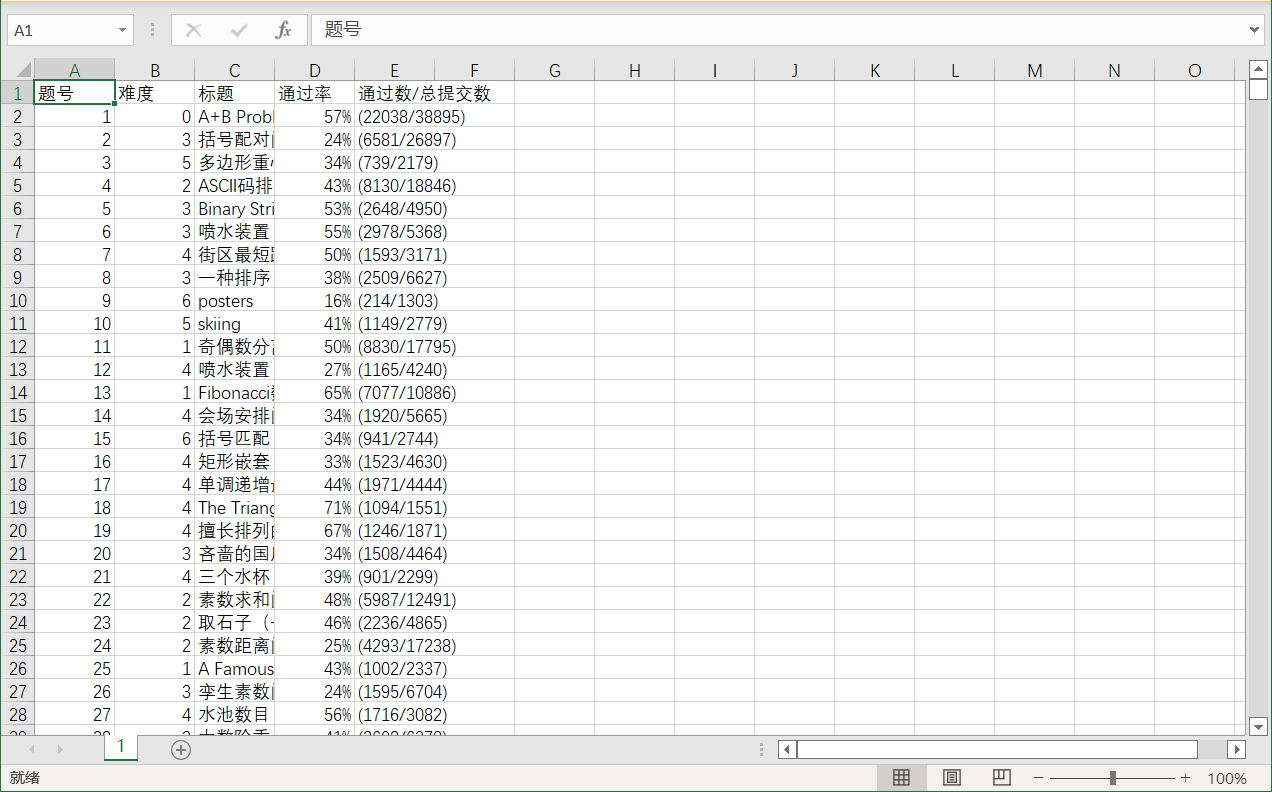
see. csv file content:
4, Climb the news website of Chongqing Jiaotong University
Chongqing Jiaotong University News Network
The codes are as follows:
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# Simulate browser access
cqjtu_Headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44'
}
#csv header
cqjtu_head=["date","title"]
#Storage content
cqjtu_infomation=[]
def get_page_number():
r=requests.get(f"http://news.cqjtu.edu.cn/xxtz.htm",headers=cqjtu_Headers)
r.raise_for_status()
r.encoding="utf-8"
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html5lib')
page_num=soup.find_all('script',page_array)
page_number=page_num[4].string#It seems that the positioning only depends on the label is not the only one, so it can only be positioned manually
page_number=page_number.strip('function a204111_gopage_fun(){_simple_list_gotopage_fun(')#Delete anything other than the number of pages
page_number=page_number.strip(',\'a204111GOPAGE\',2)}')
page_number=int(page_number)#Convert to number
return page_number
def get_time_and_title(page_num,cqjtu_Headers):#Number of pages, request header
if page_num==69 :
url='http://news.cqjtu.edu.cn/xxtz.htm'
else :
url=f'http://news.cqjtu.edu.cn/xxtz/{page_num}.htm'
r=requests.get(url,headers=cqjtu_Headers)
r.raise_for_status()
r.encoding="utf-8"
array={#Select according to class
'class':'time',
}
title_array={
'target':'_blank'
}
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html.parser')
time=soup.find_all('div',array)
title=soup.find_all('a',title_array)
temp=[]
for i in range(0,len(time)):
time_s=time[i].string
time_s=time_s.strip('\n ')
time_s=time_s.strip('\n ')
#Clear spaces
temp.append(time_s)
temp.append(title[i+1].string)
cqjtu_infomation.append(temp)
temp=[]
def write_csv(cqjtu_info):
with open('F:/Anaconda3/project/2.csv', 'w', newline='',encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(cqjtu_head)
fileWriter.writerows(cqjtu_info)
print('Crawling information succeeded')
page_num=get_page_number()#Get pages
for i in tqdm(range(page_num,0,-1)):
get_time_and_title(i,cqjtu_Headers)
write_csv(cqjtu_infomation)
Operation results:
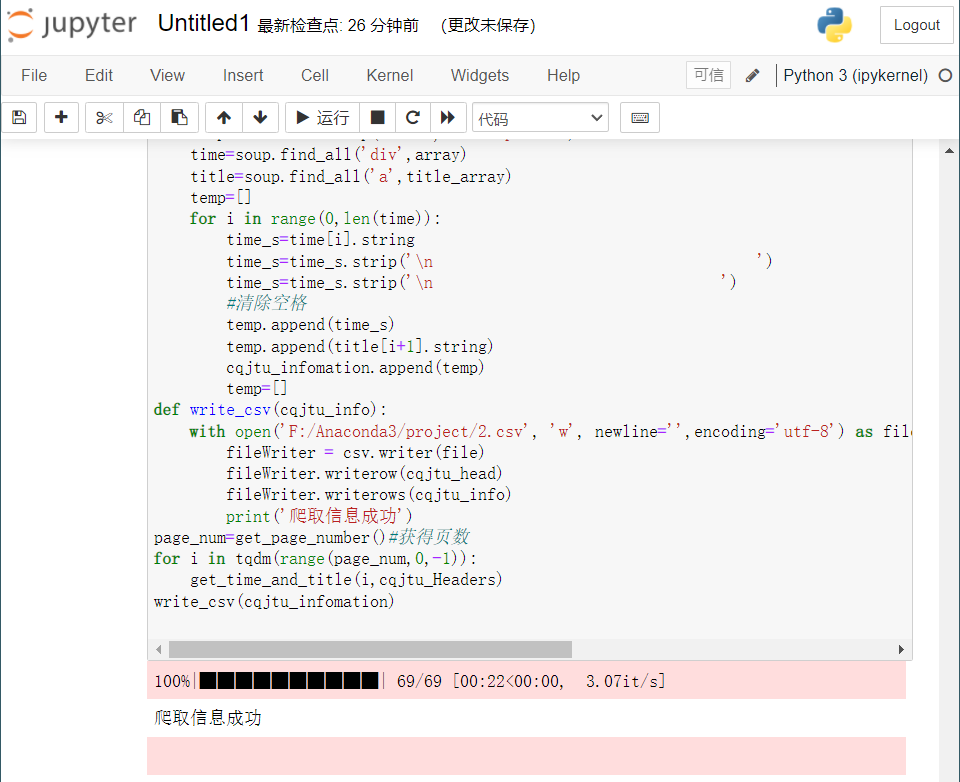
see. csv file
The message is displayed as garbled code, which may be a problem with the character set. Open it with Notepad instead
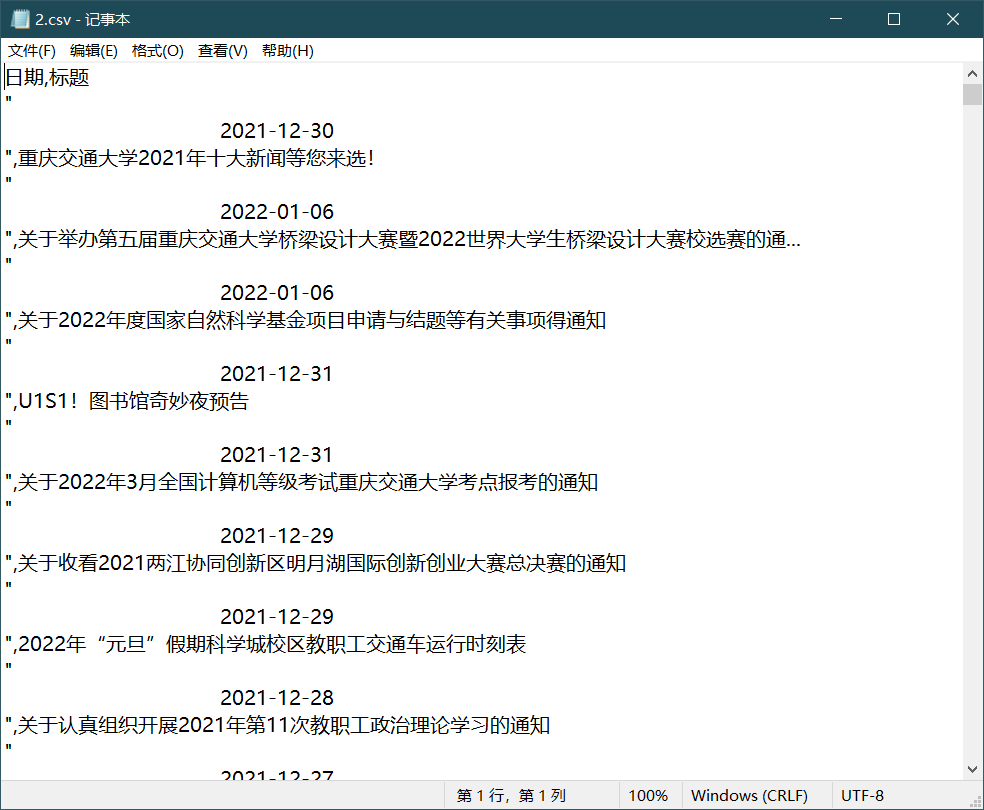
Information crawling succeeded
reference resources
What is a reptile?
Crawler - Introduction to Python Programming 1