Learning summary
(1) Learn the principle and use of FastText, and divide the data set through 10 fold cross validation.
(2) Note fasttext.train_ The returned value result after predicted here is supervised. Because we want the label with the largest probability value, we will find a lump of model. predict (x) [0] [0]. Split ('') [- 1]. Don't panic, just go to the first label, and remove several pieces of things separated by the underline because the underline is added. We take the last lump is the desired label, ex: above__ label__baking will handle it.
1, Defects represented by existing text
There are some problems in one hot, Bag of Words, N-gram, TF-IDF and other methods: the converted vector dimension is very high and needs long training practice; The relationship between words is not considered, but statistics are carried out.
Deep learning is used for text representation, which can be mapped to a low dimensional space, such as FastText, Word2Vec and Bert.
2, FastText algorithm
2.1 algorithm Introduction
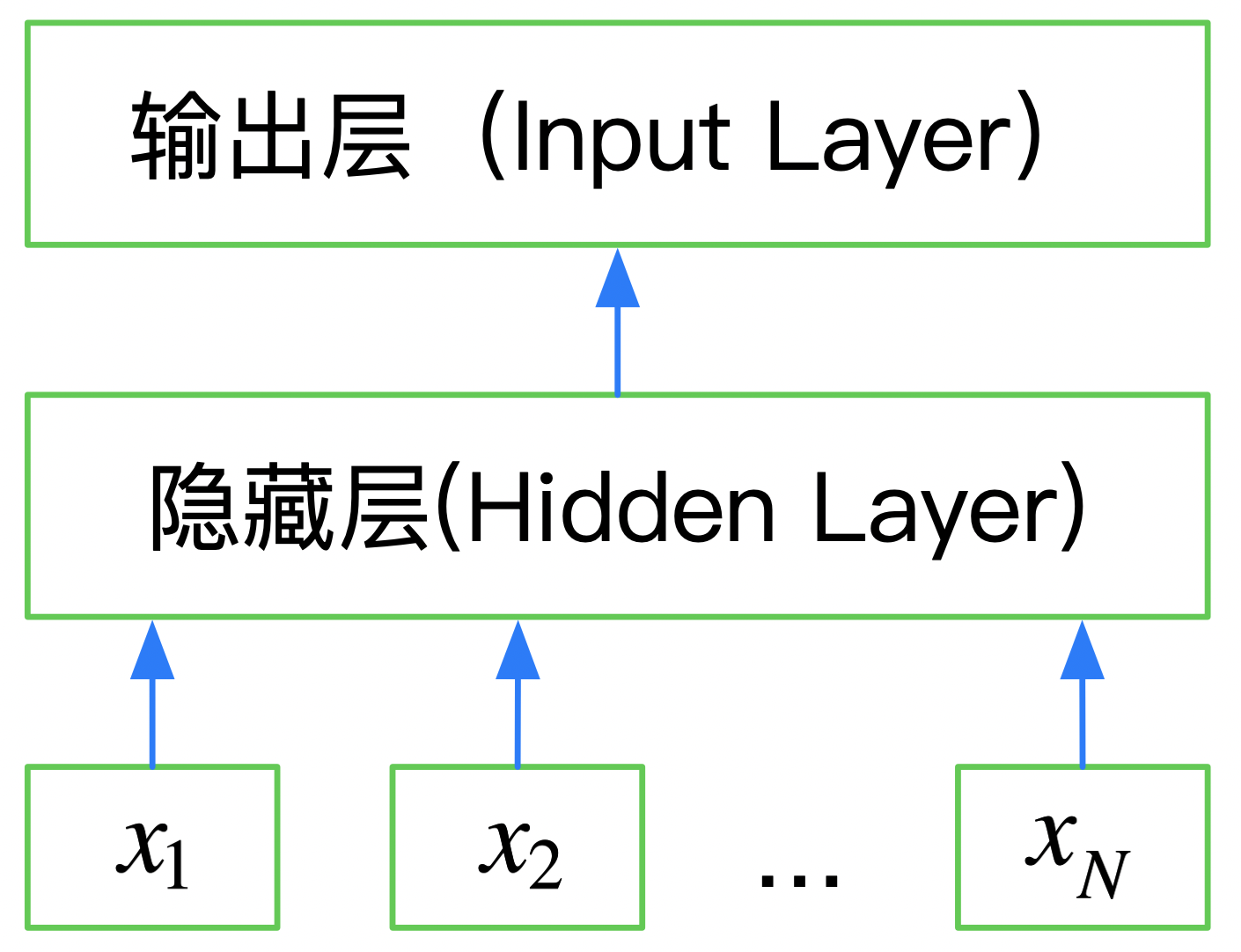
FastText is a three-layer neural network: input layer, hidden layer and output layer. The words are mapped to the dense space through the embedding layer, and then all the words in the sentence are averaged in the embedding space to complete the classification.
Specific papers: Bag of Tricks for Efficient Text Classification, https://arxiv.org/abs/1607.01759
FastText is superior to TF-IDF in text classification tasks:
- FastText uses the document vector obtained by the Embedding superposition of words to classify similar sentences into one category
- The embedded space dimension learned by FastText is relatively low and can be trained quickly
The first step is to download the fasttext package. If the command pip install fasttext cannot be downloaded in anaconda's prompt, you can directly download it in The website Find the whl file corresponding to your python interpreter version and download it. Then many blogs say that you can download it with the cmd command pip install, but I will report an error if I try, so you can go back to prompt to download and find it (the successful installation is shown below).
There is another detail to note, because the code will import fasttext at the beginning, that is, the file name cannot be named fasttext, otherwise it will conflict, that is, the error is as follows:
AttributeError: partially initialized module 'fasttext' has no attribute 'train_supervised' (most likely due to a circular import)
2.2 why fasttext is fast
1) Multithreading training: fastText uses multithreading for training. Each training thread does not lock when updating parameters, which will bring some noise to the parameter update, but will not affect the final result. Neither google's word2vec implementation nor the fastText library is locked. The default number of threads is 12, which can be set manually.
2) Layered softmax: fastText uses layered softmax when calculating softmax, which can greatly improve the operation efficiency.

(3) The use of Hierarchical softmax is actually the so-called Hoffman tree structure: each leaf node of the tree is a word, and the result of softmax is nothing more than a probability. When we want to find a word, we calculate the probability product in the path of the word.
2.3 interface parameters
First, look at fasttext.train, which will be used later_ Parameters of supervised:
input_file Training file path (required)
output Output file path (required)
label_prefix Tag Prefix default __label__
lr Learning rate default 0.1
lr_update_rate Learning rate update rate default 100
dim Word vector dimension default 100
ws Context window size default 5
epoch epochs quantity default 5
min_count Minimum word frequency default 5
word_ngrams n-gram set up default 1
loss loss function {ns,hs,softmax} default softmax
minn Minimum character length default 0
maxn Maximum character length default 0
thread Number of threads default 12
t Sampling threshold default 0.0001
silent Disable c++ Extended log output default 1
encoding appoint input_file code default utf-8
pretrained_vectors Specifies to use an existing word vector .vec file default None
Before adjusting parameters, there are such provisions for the samples of training data.
Each data + "\ t" + "label_prefix" + label
That is, the label is after each data, and the label is used_ Prefix (label_ft is used below).
3, fastText quick start
Learn here Facebook's fastText official document , the Chinese documents are a little less than the English documents. It is recommended to see the English documents here.
Chinese documents: http://fasttext.apachecn.org/#/doc/zh/supervised-tutorial
3.1 n-gram and n-char
(1)n-gram
Example: who am I? n-gram is set to 2
The n-gram features are who, who, am, am, I, i
(2)n-char
Example: where, n=3, Set start stop character<, > n-char The characteristics are,<wh, whe, her, ere, er>
Therefore, for Chinese, the output words may not need to be subdivided, so the n-char can be 0, but there will be a certain connection between the word and the word meaning, and the n-gram can be set according to the situation.
3.2 classification of multiple label s
There is an official chestnut to learn:
First, import the package and data for model training:
Here, the idea of dealing with multi classification is to set a two classification classifier for each label through fasttext.train_ Set the - loss one vs all or - loss ova parameter of supervised.
>>> import fasttext >>> model = fasttext.train_supervised(input="cooking.train", lr=0.5, epoch=25, wordNgrams=2, bucket=200000, dim=50, loss='ova') Read 0M words Number of words: 14543 Number of labels: 735 Progress: 100.0% words/sec/thread: 72104 lr: 0.000000 loss: 4.340807 ETA: 0h 0m
If you want to make as many predictions as possible, set the k parameter to - 1, and then set the threshold to 0.5 as long as the probability is greater than 0.5:
>>> model.predict("Which baking dish is best to bake a banana bread ?", k=-1, threshold=0.5)
((u''__label__baking, u'__label__bananas', u'__label__bread'), array([1.00000, 0.939923, 0.592677]))
>>> model.test("cooking.valid", k=-1)
(3000L, 0.702, 0.2)
Note the return value result after predict here. Because we want the label with the largest probability value, we will find a lump of model. Predict (x) [0] [0]. Split ('_') [- 1]. Don't panic. Just go to the first label, and then remove several pieces of things separated by underline because the underline is added. We take the last lump is the desired label, ex: above__ label__baking will handle it.
3, Text classification chestnut
See the notes for details.
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 5 09:04:43 2021
@author: 86493
"""
import pandas as pd
from sklearn.metrics import f1_score
import fasttext
# Convert to the format required by FastText
train_df = pd.read_csv('train_set.csv',
sep = '\t',
nrows =15000)
# astype is a cast type
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
train_df[['text', 'label_ft']].iloc[: -5000].to_csv('train.csv',
index = None,
header = None,
sep = '\t')
# word_ngrams=2 and NGram of the previous task_ Range is not the same meaning
model = fasttext.train_supervised('train.csv',
lr = 1.0, # Learning rate
wordNgrams = 2, # Letter combination length
verbose = 2, #
minCount = 1, # Filter words less than minCount
epoch = 25, # Number of iterations
loss = 'hs') # The default loss is negative sampling
# The last 5k test samples are used as the validation set to analyze the prediction results and generate a list
val_pred = [model.predict(x)[0][0].split('__')[-1] for x in train_df.iloc[-5000:]['text']]
print(f1_score(train_df['label'].values[-5000:].astype(str), # [10000:] OK
val_pred,
average = 'macro'))
During the running process, the final F1 value is 0.8229238895393863:
Read 9M words Number of words: 5341 Number of labels: 14 Read 9M words Number of words: 5341 Number of labels: 14 Progress: 0.1% words/sec/thread: 29827 lr: 0.999370 avg.loss: 2.461391 ETA: 0h18m 9s Read 9M words Number of words: 5341 Number of labels: 14 Progress: 0.2% words/sec/thread: 34835 lr: 0.998136 avg.loss: 2.420802 ETA: 0h15m34s Read 9M words Number of words: 5341 Number of labels: 14 Progress: 0.3% words/sec/thread: 32120 lr: 0.997353 avg.loss: 2.450788 ETA: 0h16m49s Read 9M words Number of words: 5341 Number of labels: 14 Progress: 0.6% words/sec/thread: 56698 lr: 0.993602 avg.loss: 2.382696 ETA: 0h 9m30s Read 9M words Number of words: 5341 Number of labels: 14 Progress: 1.1% words/sec/thread: 78496 lr: 0.988754 avg.loss: 2.180967 ETA: 0h 6m49s Read 9M words Number of words: 5341 Number of labels: 14 Progress: 1.4% words/sec/thread: 79590 lr: 0.986145 avg.loss: 2.087085 ETA: 0h 6m43s Read 9M words Number of words: 5341 Number of labels: 14 Progress: 2.7% words/sec/thread: 130232 lr: 0.973349 avg.loss: 1.691365 ETA: 0h 4m 3s Read 9M words Number of words: 5341 Number of labels: 14 . . . . . . . Progress: 97.4% words/sec/thread: 601597 lr: 0.025779 avg.loss: 0.150194 ETA: 0h 0m 1s Read 9M words Number of words: 5341 Number of labels: 14 Progress: 99.8% words/sec/thread: 603704 lr: 0.004354 avg.loss: 0.147263 ETA: 0h 0m 0s Read 9M words Number of words: 5341 Number of labels: 14 Progress: 100.0% words/sec/thread: 603532 lr: 0.000000 avg.loss: 0.146719 ETA: 0h 0m 0s 0.8229238895393863
4, Using validation sets to tune parameters
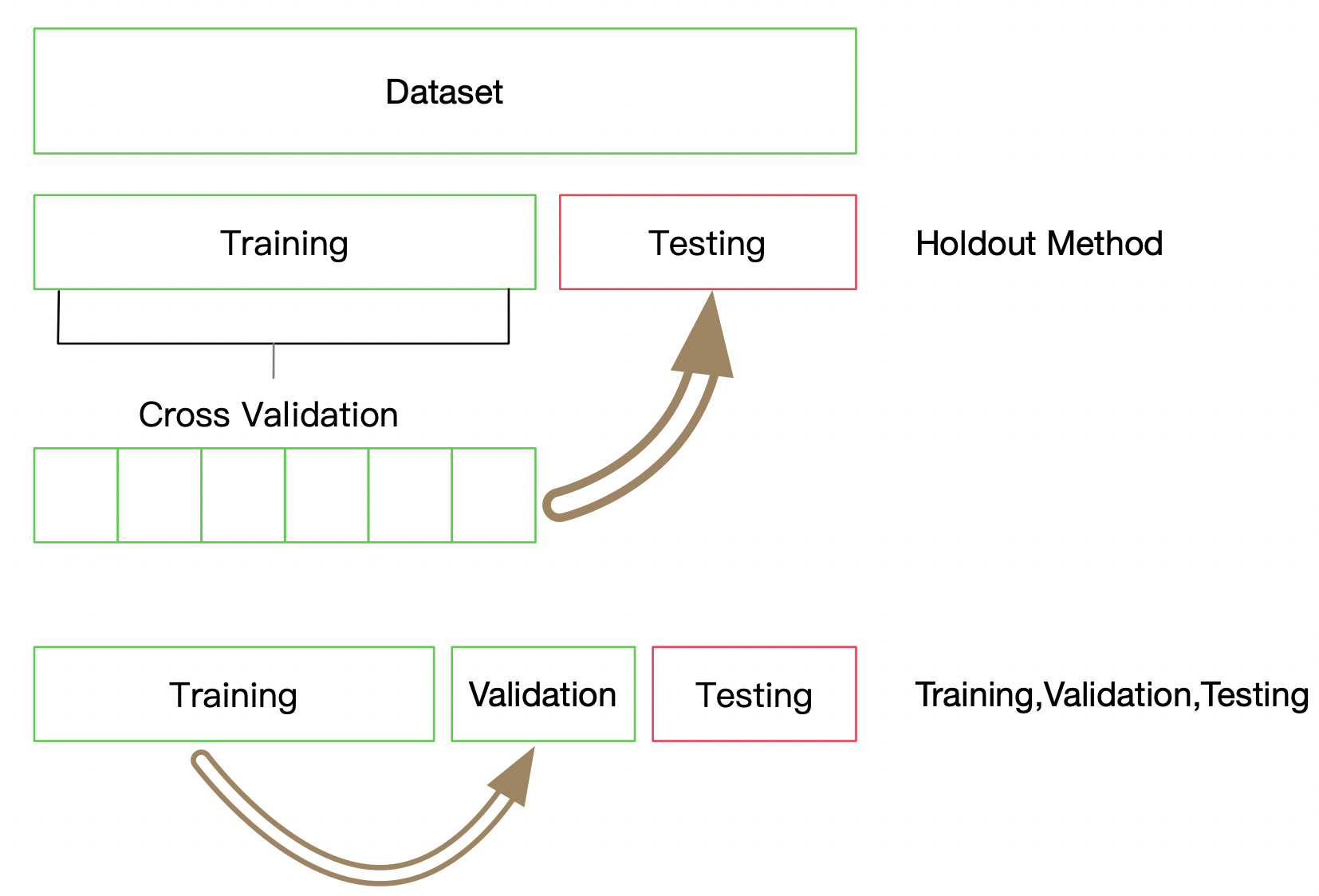
Adjustment parameters:
(1) By reading the document, you should find out the general meaning of these parameters, which will increase the complexity of the model.
(2) By verifying the accuracy of the model on the verification set, we can find out whether the model is over fitting or under fitting.
10 fold cross validation, each fold uses 9 / 10 of the data for training, and the remaining 1 / 10 is used as the validation set to test the effect of the model. It should be noted that the division of each fold must ensure that the label distribution is consistent with the distribution of the whole data set.
label2id = {}
for i in range(total):
label = str(all_labels[i])
if label not in label2id:
label2id[label] = [i]
else:
label2id[label].append(i)
Through 10 fold division, we select the last one to complete the remaining experiments, that is, the one with index 9 as the verification set and the one with index 1-8 as the training set, and then adjust the super parameters based on the results of the verification set to make the model performance better.
Reference
(1) Ali Tianchi platform
(2)fastText training and use
(3) Fasttext Chinese document: http://fasttext.apachecn.org/#/
(4)https://github.com/apachecn/fasttext-doc-zh/
(5) fastText official website: https://fasttext.cc/