Key points of this chapter:
- Using NLTK to understand corpus
- Import corpus
- NLTK Library
- Install nltk library and corpus
Using NLTK to understand corpus
Import corpus
with open("./text.txt") as f: text = f.read()
print(type(text)) print(text[:200])
<class 'str'> [ Moby Dick by Herman Melville 1851 ] ETYMOLOGY . ( Supplied by a Late Consumptive Usher to a Grammar School ) The pale Usher -- threadbare in coat , heart , body , and brain ; I see him now . He was
- This is a local corpus, which can be obtained from here if necessary: Chain
Answer: https://pan.baidu.com/s/1EPWqGO5bpWs80MPr49s1KQ Password: df6b
NLTK Library
Learn about:
import nltk import numpy as np import matplotlib.pyplot as plt %matplotlib inline
0, local corpus to Text
text = text.split(' ') text = nltk.text.Text(text)
type(text)
nltk.text.Text
Here are some common methods of Text class:
1. Search text
Article search: concordance()
concordance() function, the word index view shows each occurrence of a specified word, along with some context. Check out the word monstrous in Moby Dick:
text.concordance("monstrous")
Displaying 11 of 11 matches: ong the former , one was of a most monstrous size . ... This came towards us , ON OF THE PSALMS . " Touching that monstrous bulk of the whale or ork we have r ll over with a heathenish array of monstrous clubs and spears . Some were thick d as you gazed , and wondered what monstrous cannibal and savage could ever hav that has survived the flood ; most monstrous and most mountainous ! That Himmal they might scout at Moby Dick as a monstrous fable , or still worse and more de th of Radney .'" CHAPTER 55 Of the Monstrous Pictures of Whales . I shall ere l ing Scenes . In connexion with the monstrous pictures of whales , I am strongly ere to enter upon those still more monstrous stories of them which are to be fo ght have been rummaged out of this monstrous cabinet there is no telling . But of Whale - Bones ; for Whales of a monstrous size are oftentimes cast up dead u
Similar search: similar()
We can find out by adding the function name SIMAR after the text name to be queried, and then inserting the relevant words into the brackets: we can use the. SIMAR method to identify the words similar to the search words in the article:
text.similar("monstrous")
true contemptible christian abundant few part mean careful puzzled mystifying passing curious loving wise doleful gamesome singular delightfully perilous fearless
Context search: common UU contexts()
The common context function allows us to study the common context of two or more words, such as mongstrous and very. We must enclose these words in square brackets and round brackets, separated by commas:
text.common_contexts(["monstrous","very"])
No common contexts were found
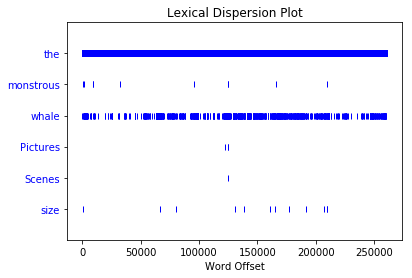
Visual word frequency: dispersion [plot()
This function is used to visualize the occurrence of words in the text. Judge the position of words in the text: how many words are in front of the text from the beginning. This location information can be represented by discrete graphs. Each vertical line represents a word, and each line represents the entire text:
text.dispersion_plot(['the',"monstrous", "whale", "Pictures", "Scenes", "size"])
2. Vocabulary count
Length: len()
len(text)
260819
De duplication: set()
print(len(set(text)))
19317
Sort: sorted(set(text))
sorted(set(text))[-10:]
['zag', 'zay', 'zeal', 'zephyr', 'zig', 'zodiac', 'zone', 'zoned', 'zones', 'zoology']
The number of a word: count()
text.count('the')
13721
3. Word frequency distribution
FreqDist()
How can we automatically identify the words that best reflect the theme and style of the text? Imagine finding the 50 most frequently used words in a book?
They are built into NLTK. Let's use FreqDist to find the 50 most common words in Moby Dick:
from nltk.book import FreqDist// If there is a problem with the import, you need to install the corpus, please see the last fdist1 = FreqDist(text) fdist1.most_common(10)
[(',', 18713),
('the', 13721),
('.', 6862),
('of', 6536),
('and', 6024),
('a', 4569),
('to', 4542),
(';', 4072),
('in', 3916),
('that', 2982)]
- (on the left is the word, on the right is the number of times the word appears in the article)
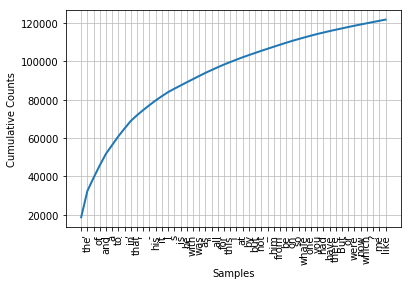
Cumulative word frequency map
Is there any word in the previous example that can help us grasp the theme or style of this text? Just one word, whale, a little bit of information! It has appeared more than 900 times. The rest of the words don't tell us about the text; they're just "pipeline" English. What proportion of these words in the text? We can generate a cumulative frequency map of these words using:
fdist1.plot(50, cumulative=True)
Meaningful granularity
The words counted by the above word frequency have no practical significance. I think we should consider the words whose length is greater than 7 and whose word frequency is greater than 7
fdist2 = FreqDist(text) sorted(w for w in set(text) if len(w)>7 and fdist2[w]>7)[:10]
['American', 'Atlantic', 'Bulkington', 'Canallers', 'Christian', 'Commodore', 'Consider', 'Fedallah', 'Greenland', 'Guernsey']
- So you can see the information in the text
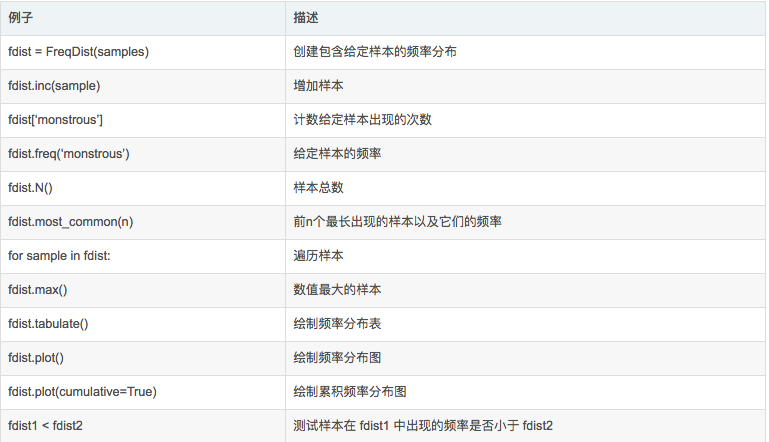
Functions defined in word frequency distribution class
4. Collocation and disyllabic words
A collocation is a sequence of words that often appear together. red wine is a match and the wine is not. The collocations() function can do these:
text.collocations()
Sperm Whale; Moby Dick; White Whale; old man; Captain Ahab; sperm whale; Right Whale; Captain Peleg; New Bedford; Cape Horn; cried Ahab; years ago; lower jaw; never mind; Father Mapple; cried Stubb; chief mate; white whale; ivory leg; one hand
Install nltk library and corpus
1. Install nltk Library
$ pip install nltk
2. Install nltk corpus
Auto install:
If there's a ladder, directly
improt nltk nltk.download()
Offline installation:
Due to the inability to access foreign websites, nltk is installed offline;
You can download it directly from here. Link: https://pan.baidu.com/s/1Vxc0RT8Vae3A5v1k1FjhTQ Password: 1drd
After downloading, put it into / user / user name / nltk_data, and then it can be used normally
Now import:
from nltk.book import *

