1. Introduction to Q & a system
Q & a system is usually divided into:
- Task robot
- Chat robot
- Solution robot (customer service robot)
The three are designed for different application scenarios:
- Task based robots are mainly used to complete some specific tasks of users, such as buying air tickets, phone recharge or weather consultation.
- Chat robot is mainly used for in-depth aimless communication with users;
- Solution robot (customer service robot) is used to solve users' problems, such as commodity purchase consultation, commodity return consultation, etc.
Task based questions:
1) : "what's the weather like in Chengdu today";
2) : "what about tomorrow";
3) : "the day after tomorrow".
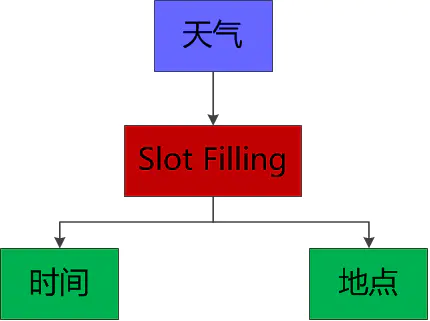
Slot Filling
First of all, "what's the weather like in Chengdu today" is a weather question (including entity "place" and "time"), which can be answered;
Then, the sentence "what about tomorrow" only contains entity information ("time") and does not contain location information. If intention classification is directly adopted, this response cannot be completed;
Finally, "the day after tomorrow" also contains only entity information ("time").
For this kind of multi round conversation scenario, you can respond by slot filling (slot filling is composed of multiple slot values, for example, the weather scenario requires the entity slot values "place" and "time"). "Tomorrow" and "the day after tomorrow" only include the "time" entity, but the above "what's the weather like in Chengdu today" includes the "place" "Entity", just replace the entity below ("time") with the entity above ("time").
Problem solving:
1) : "how much is iphone X";
2) How much is the postage;
3) : "can I return it without reason?"
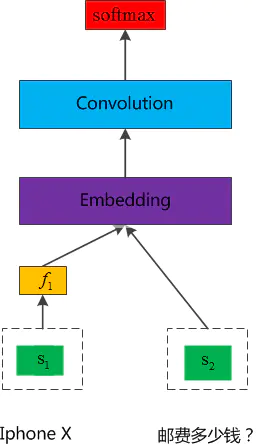
Feature stitching context model
The multi round dialogue here involves three intentions: commodity purchase, pre-sales freight and return and exchange policy, and the subsequent intention analysis needs the conversation intention mentioned above, which is a typical multi round dialogue process.
First, "how much is iphone X" can be answered by classifying the intention of a single sentence;
While "how much is the freight?" it is necessary to judge whether the freight consulted by the user belongs to pre-sales freight or after-sales freight. At this time, the intention analysis can be carried out by combining the above problems (1: extracting the intention features above and adding them to the current problem can solve some context scenario problems; 2: combining the above and current problems, the intention analysis of the context can be carried out by using the deep learning algorithm).
Finally, "can you return goods without reason" needs to know the information of the goods before you can answer the user's questions. Therefore, you need the above commodity "iphone X" (you can save the entity and commodity information in the dialogue for the following response).
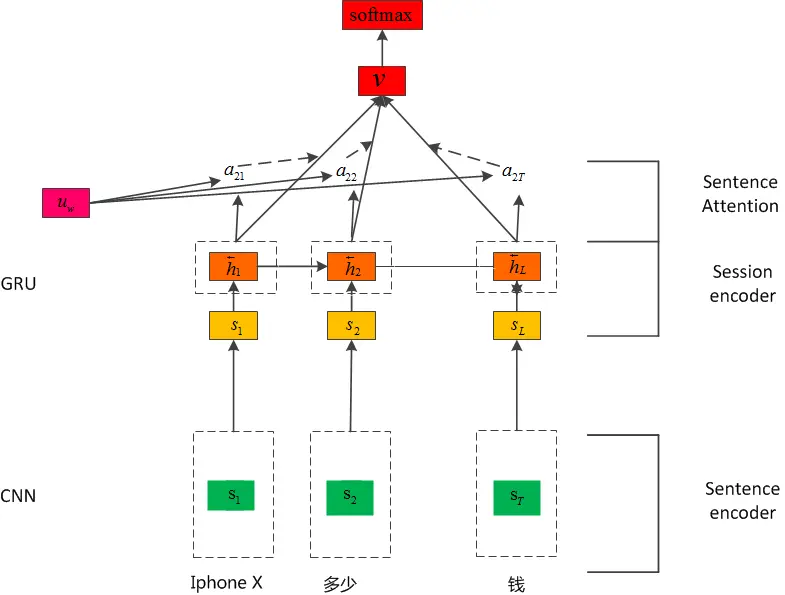
Hierarchical context model (H-CNN-GRU)
At this time, in the process of multiple rounds of dialogue, the single sentence input in the process of user input is incomplete. slot filling and simple extraction of the above features are not suitable, but the combination of multiple sentence input can complete the response here
Chatty question

Chat record
For the chat questions, because the user has no clear intention, it is not suitable for intention classification. Here, we can use the generative model to generate the corresponding answers according to a large number of chat corpus of user history (the answers obtained by the generative model may have grammar and coherence problems, but the conversation in the chat scene does not require high sentence grammar and coherence, which is relatively arbitrary) .
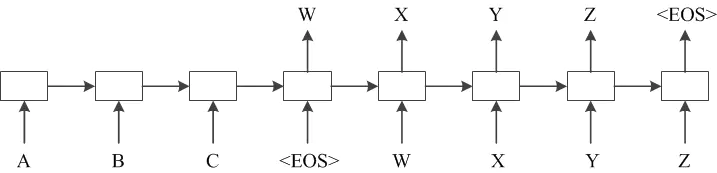
seq2seq model
Conclusion: when we analyze a person, we usually involve IQ and EQ. IQ lies in the ability to solve problems, and EQ lies in the way to solve problems. When implementing a robot question answering system, we should also consider IQ and EQ. here is only an analysis of some special cases in the question answering system. A complete question answering system still needs a lot of research His work, such as making the answer of the question and answer system more anthropomorphic (user emotion analysis)
2. Application of context classification algorithm based on Attention mechanism in question answering system
Text classification is the basic algorithm in natural language processing. In the application of dialogue system, text classification algorithm can be used to judge the user's consultation intention. However, a single problem can not capture the user's intention well. Usually, the user's intention can be better judged by combining the user's above consultation with the sentence.
Here we need to establish a context based classification model to judge the user's ultimate intention combined with the above information.
There are two common methods:
1) Non end-2-end modeling: first extract the above topics, intentions or keywords, and then model in combination with the current problem.
2) end-2-end modeling: directly extract the above information through the time series model and establish the model in combination with the current problem.
This article mainly refers to the Hierarchical Attention Networks for Document Classification , this paper introduces the application of attention mechanism in English text classification. This paper adopts document level classification, that is, document is composed of sense, and sense is composed of word, so it naturally has hierarchical relationship. Taking word as granularity input network, word level features are extracted to obtain the feature vector representing sense, and then the sense level vector is input into the network to extract sense level features In order to assign different weights to different words and different senses, this paper designs a hierarchical attention mechanism to improve the performance of the model.
When designing the context model, this paper makes a slight modification, takes the single sentence in a session as the input of the first layer, and then takes the features extracted from each single sentence in the first layer as the input of the second layer, so as to obtain the final session level feature output. Attention mechanism is not popular recently, and is widely used in nlp and image processing. Here, it is also after the feature extraction of the first layer , an attention layer is designed to extract the features of sentences more accurately. However, after the feature extraction in the session layer, the same attention is not designed, because in the dialogue system, the closer to the current sentence, the more important the sentence is. Therefore, here we extract the final output of the time series model as the final feature.
The design diagram of the overall algorithm is as follows:
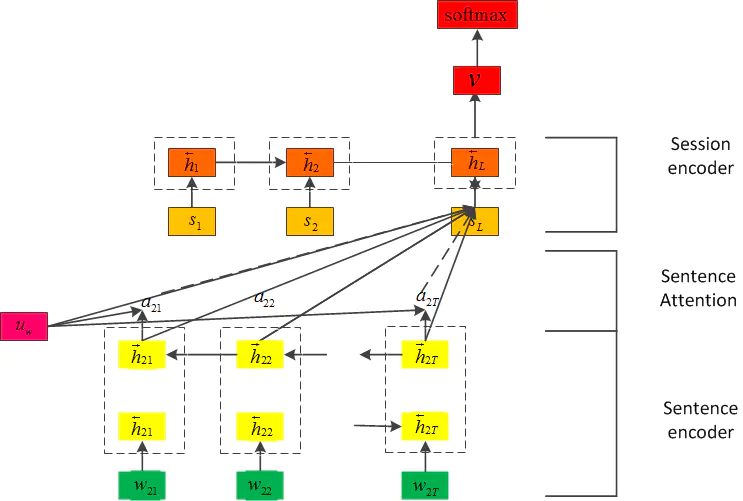
When processing Chinese, the accuracy and speed of LSTM network are worse than CNN network. Therefore, the network structure of this paper is adjusted and the LSTM network in the first layer is replaced by CNN network. In this paper, the Attention mechanism is added to both layer 1 and layer 2, but it is found that the effect of adding Attention to layer 1 is not improved, so Attention is only used in layer 2. After the integration of CNN and LSTM, the whole network structure has become very complex, and GRU is a simplified version of LSTM. GRU is more effective when there is less corpus. Therefore, GRU is used to replace the LSTM of the second layer network, that is, there is the final model H-CNN-GRU network:
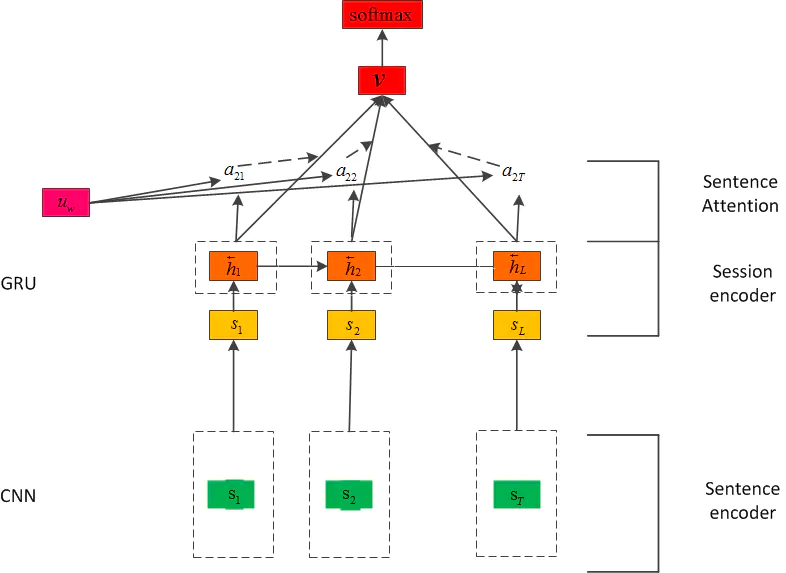
Experimental steps:
1: This experiment uses single sentence questions and corresponding tags as input. Before the experiment, the problem is first segmented by word, and then the problem is pre trained by word 2vec (here, the method of word segmentation is used to avoid the trouble of word segmentation, and a high accuracy can also be obtained).
2: Since the GRU/LSTM with fixed length is used in this experiment, the questions and answers need to be truncated (too long) or supplemented (too short).
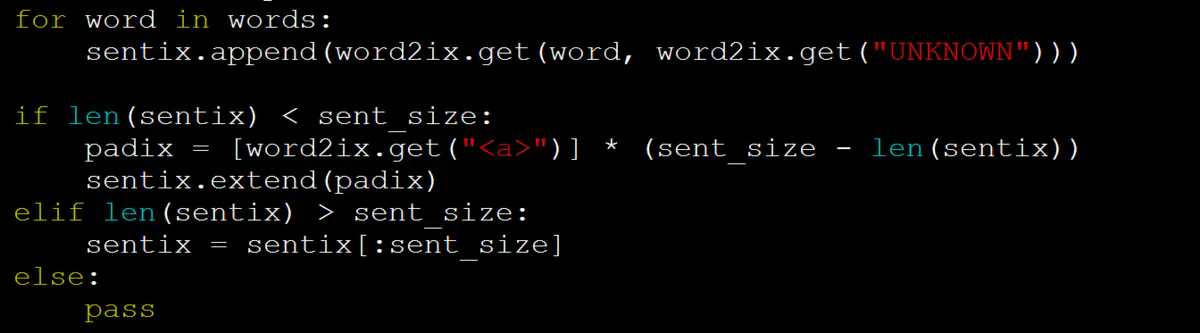
3: Experimental modeling Input. In this experiment, the single sentence problem and label are modeled (q, l). q represents the problem and l represents the label.

4: Embed the problem (batch_size*session_len, sentence_len, embedding_size).

5: For the problems contained in all sessions in a batch, the GRU/LSTM model is used to calculate the characteristics.
1) : in the first layer, fixed length sentences are used for feature extraction of single sentence problems, and two-way dynamic rnn is tried, which does not improve the effect, and the calculation speed is relatively slow.
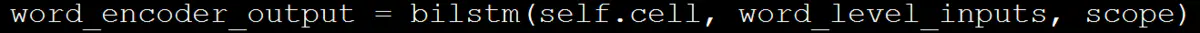
6: The output vector of GRU/LSTM model is (batch_size, seq_len, rnn_size), so it is necessary to extract the feature of the output feature vector. The common feature extraction method is to take the output of the last step of the model as the feature of the next layer, but this feature extraction method only takes the feature of the last step and discards other feature information. Therefore, in this experiment, the Attention mechanism is used to calculate the weight of each step of the feature, and then weighted average.
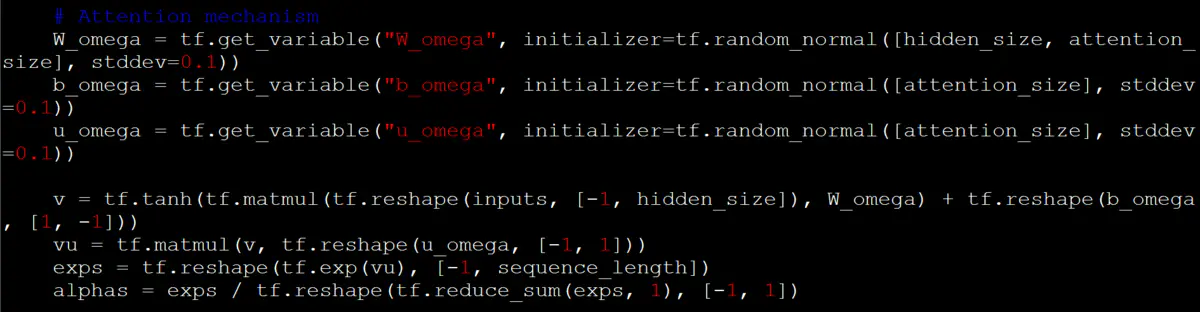
7: The single sentence level feature output of the first layer is used as the input of the session level encoder of the second layer.
1) : here, dynamic rnn is used for feature extraction, because the problems contained in each session are not fixed.
2) : instead of bidirectional rnn, unidirectional rnn is used, and attention and AVG are not added_ Pool or max_pool, because the closer to the current sentence, the more important it should be.

7: The characteristics of the model output are linearly transformed.
8: For multi class text classification, the output of linear transformation needs to be passed through softmax.
Parameter setting:
1: Here, the optimization function adopts Adam used in the paper (SGD has been tried, the learning rate is 0.1, and the effect is poor).
2. The learning rate is 2e-4.
3: 60 rounds of training.
4,embedding_ The size is 150 dimensions.
5. The attention is 100 dimensions.
6,batch_size 128 is used here.
7. The question length is limited to 60 words.
8,rnn_ The size is 201.
9. Each level of feature extraction in this algorithm only uses a single layer. Due to the time-consuming calculation, it does not try the way of different levels and multiple levels.
10. Dropout is 0.5 (dropout is executed at both input and output, and the effect is poor in a single dropout experiment)
Note: from the analysis results of online data, H-CNN-GRU algorithm can achieve good results in processing context scenes.
3. Build a query and answer system based on retrieval
The main implementation of the retrieval based question answering system is to match the similarity between the user's input questions and the questions in the database, and return the answers of the questions with the highest similarity to the user (you can also return top n most similar questions, which will be returned to the user's answers after the user selects the most similar questions)
Data introduction:
dev-v2.0.json: this data contains the pair of questions and answers, which exists in JSON format.
Print as follows:
{'paragraphs': [{'context': 'Beyoncé Giselle Knowles-Carter (/biːˈjɒnseɪ/ bee-YON-say) (born September 4, 1981) is an American singer, songwriter, record producer and actress. Born and raised in Houston, Texas, she performed in various singing and dancing competitions as a child, and rose to fame in the late 1990s as lead singer of R&B girl-group Destiny\'s Child. Managed by her father, Mathew Knowles, the group became one of the world\'s best-selling girl groups of all time. Their hiatus saw the release of Beyoncé\'s debut album, Dangerously in Love (2003), which established her as a solo artist worldwide, earned five Grammy Awards and featured the Billboard Hot 100 number-one singles "Crazy in Love" and "Baby Boy".',
'qas': [{'answers': [{'answer_start': 269, 'text': 'in the late 1990s'}],
'id': '56be85543aeaaa14008c9063',
'is_impossible': False,
'question': 'When did Beyonce start becoming popular?'},
{'answers': [{'answer_start': 207, 'text': 'singing and dancing'}],
'id': '56be85543aeaaa14008c9065',
'is_impossible': False,
'question': 'What areas did Beyonce compete in when she was growing up?'},
{'answers': [{'answer_start': 526, 'text': '2003'}],
'id': '56be85543aeaaa14008c9066',
'is_impossible': False,
'question': "When did Beyonce leave Destiny's Child and become a solo singer?"},
{'answers': [{'answer_start': 166, 'text': 'Houston, Texas'}],
'id': '56bf6b0f3aeaaa14008c9601',
'is_impossible': False,
'question': 'In what city and state did Beyonce grow up? '},
{'answers': [{'answer_start': 276, 'text': 'late 1990s'}],
'id': '56bf6b0f3aeaaa14008c9602',
'is_impossible': False,
'question': 'In which decade did Beyonce become famous?'},
{'answers': [{'answer_start': 320, 'text': "Destiny's Child"}],
'id': '56bf6b0f3aeaaa14008c9603',
'is_impossible': False,
'question': 'In what R&B group was she the lead singer?'},
{'answers': [{'answer_start': 505, 'text': 'Dangerously in Love'}],
'id': '56bf6b0f3aeaaa14008c9604',
'is_impossible': False,
'question': 'What album made her a worldwide known artist?'},
{'answers': [{'answer_start': 360, 'text': 'Mathew Knowles'}],
'id': '56bf6b0f3aeaaa14008c9605',
'is_impossible': False,
'question': "Who managed the Destiny's Child group?"},
{'answers': [{'answer_start': 276, 'text': 'late 1990s'}],
'id': '56d43c5f2ccc5a1400d830a9',
'is_impossible': False,
'question': 'When did Beyoncé rise to fame?'},
{'answers': [{'answer_start': 290, 'text': 'lead singer'}],
'id': '56d43c5f2ccc5a1400d830aa',
'is_impossible': False,
'question': "What role did Beyoncé have in Destiny's Child?"},
{'answers': [{'answer_start': 505, 'text': 'Dangerously in Love'}],
'id': '56d43c5f2ccc5a1400d830ab',
'is_impossible': False,
'question': 'What was the first album Beyoncé released as a solo artist?'},
{'answers': [{'answer_start': 526, 'text': '2003'}],
'id': '56d43c5f2ccc5a1400d830ac',
'is_impossible': False,
'question': 'When did Beyoncé release Dangerously in Love?'},
{'answers': [{'answer_start': 590, 'text': 'five'}],
'id': '56d43c5f2ccc5a1400d830ad',
'is_impossible': False,
'question': 'How many Grammy awards did Beyoncé win for her first solo album?'},
{'answers': [{'answer_start': 290, 'text': 'lead singer'}],
'id': '56d43ce42ccc5a1400d830b4',
'is_impossible': False,
'question': "What was Beyoncé's role in Destiny's Child?"},
{'answers': [{'answer_start': 505, 'text': 'Dangerously in Love'}],
'id': '56d43ce42ccc5a1400d830b5',
'is_impossible': False,
'question': "What was the name of Beyoncé's first solo album?"}]},
2.1 import required libraries
import json from matplotlib import pyplot as plt import re import string import nltk from nltk.corpus import stopwords from nltk.tokenize import word_tokenize from nltk.stem.porter import PorterStemmer from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity from queue import PriorityQueue as PQueue from functools import reduce
2.2 reading files
Read the training file and write the contents into two lists respectively (one list corresponds to the question set and the other list corresponds to the answer set)
def read_corpus():
"""
Read the given corpus and write the question list and answer list into the database respectively qlist, alist Inside. In this process, there is no need to do any processing for characters
qlist = ["Question 1", "Question 2 "," question 3 " ....]
alist = ["Answer 1", "Answer 2", "Answer 3" ....]
Make sure that each question corresponds to the answer (subscript position is consistent)
"""
qlist = []
alist = []
with open("data/train-v2.0.json", 'r') as path:
fileJson = json.load(path)
json_list=fileJson['data']
for data_dict in json_list:
for data_key in data_dict:
if data_key=="paragraphs":
paragraphs_list=data_dict[data_key]
for content_dict in paragraphs_list:
for qas_key in content_dict:
if "qas" == qas_key:
qas_list = content_dict[qas_key]
for q_a_dict in qas_list:
if len(q_a_dict["answers"]) > 0:
qlist.append(q_a_dict["question"])
alist.append(q_a_dict["answers"][0]["text"])
print("qlist len:" + str(len(qlist)))
print("alist len:" + str(len(alist)))
assert len(qlist) == len(alist) # Make sure the length is the same
return qlist, alist
2.3 understanding data (visual analysis / Statistics)
Understanding the data is the first step of any AI work, which requires a more intuitive understanding of the data on the opponent.
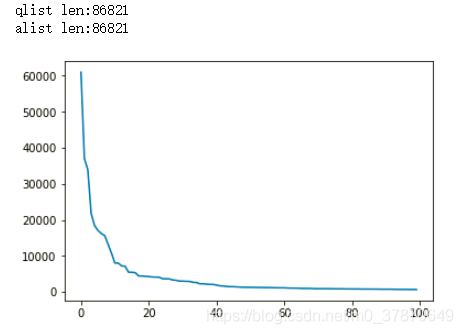
def data_analysis(data):
# TODO: how many words are there in qlist? How many different words appear in total?
# TODO: count the frequency of each word in qlist, arrange these frequencies in order, and then draw a plot
qlist_word = []
word_dic = {}
for sentences in data:
cur_word = sentences[:len(sentences) - 1].strip().split(" ")
qlist_word += cur_word
for word in cur_word:
if word in word_dic.keys():
word_dic[word] = word_dic[word] + 1
else:
word_dic[word] = 1
#Count the total number of different words in qlist
word_total = len(set(qlist_word)) # 53306
word_dic=sorted(word_dic.items(), key = lambda x:x[1], reverse = True)
# Visualize the words with the first 100 occurrences
x = range(100)
y = [c[1] for c in word_dic[:100]]
plt.figure()
plt.plot(x, y)
plt.show()
qlist, alist = read_corpus()
data_analysis(qlist)
Print as follows:
2.4 text preprocessing
For qlist, alist performs text preprocessing. The following operations can be considered:
- Stop word filtering (search the "english stop words list" on the Internet, and many web pages containing stop words will appear, or directly use NLTK's own)
- Convert to lower_case: This is a basic operation
- Remove some useless symbols: such as continuous exclamation marks!!!, Or some strange words.
- Remove the words with low frequency: for example, the number of occurrences is less than 10,20
- Processing of numbers: after word segmentation, only some words may be numbers, such as 44415. All these numbers are regarded as one word. This new word can be defined as "#number"
- Stemming (using porter stemming): because it is in English, stemming can also be done
Please note that it is not necessary to follow the above order. Think about the specific processing order, and then choose a reasonable order
def data_pre(temp_list):
stop_words = set(stopwords.words('english'))
stemmer = PorterStemmer()
pattern = re.compile('[{}]'.format(re.escape(string.punctuation)))#Regular matching special symbols
word_list_list = []
word_dict = {}
for line in temp_list:
temp_word_list = []
sentence = pattern.sub("", line) # 1. Remove some useless symbols
sentence = sentence.lower() # 2. Convert to lower_case
word_list = sentence.split()
for word in word_list:
if word not in stop_words: # 3. Filter stop words
word = "#number" if word.isdigit() else word # 4. Digital special processing
word = stemmer.stem(word) # 5. Stem extraction (including word form reduction)
word_dict[word] = word_dict.get(word, 0) + 1
temp_word_list.append(word)
word_list_list.append(temp_word_list)
return word_dict, word_list_list
#6. Remove words with low frequency
def filter_words(in_list=[], in_dict={}, lower=0, upper=0):
word_list = []
for key, val in in_dict.items():
if val >= lower and val <= upper:
word_list.append(key)
new_list = []
for line in in_list:
words = [w for w in line if w in word_list]
new_list.append(' '.join(words))
return new_list
2.5 text representation
The presentation method of TF IDF is used here, and the package provided in sklearn is used here.
from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer() # Define a TF IDF vectorizer X = vectorizer.fit_transform(qlist) # The results are stored in the X matrix
2.6 for the user's input questions, find the questions with the highest similarity of top 5, and return the five potential answers
def top5results(input_q):
"""
Questions given user input input_q, Return the most likely TOP 5 Problem. The following points need to be done:
1. For user input input_q First do a series of preprocessing, and then convert to tf-idf Vector (using the above vectorizer)
2. Calculate the similarity with the problems in each library
3. Find the most similar top5 The answer to the question
"""
stop_words = set(stopwords.words('english'))
stemmer = PorterStemmer()
pattern = re.compile('[{}]'.format(re.escape(string.punctuation))) # Regular matching special symbols
input_q = pattern.sub("", input_q) # 1. Remove some useless symbols
input_q = input_q.lower() # 2. Convert to lower_case
word_list = input_q.split()
temp_word_list=[]
for word in word_list:
if word not in stop_words: # 3. Filter stop words
word = "#number" if word.isdigit() else word # 4. Digital special processing
word = stemmer.stem(word) # 5. Stem extraction (including word form reduction)
temp_word_list.append(word)
new_input=' '.join(temp_word_list)
vectorizer = TfidfVectorizer(smooth_idf=False) # Define a TF IDF vectorizer
X = vectorizer.fit_transform(new_qlist) # The results are stored in the X matrix
#Pay attention to fit_transform is training, and transform is adding new data
input_vec = vectorizer.transform([new_input])# The results are stored in the X matrix
res = cosine_similarity(input_vec, X)[0]
#That is, the first k high-frequency words are output, and the priority queue is used to optimize the speed
pq = PQueue()
for i, v in enumerate(res):
pq.put((1.0 - v, i))
top_idxs = [] # top_idxs stores the following table of problems with the highest similarity (existing in qlist)
for i in range(5):
top_idxs.append(pq.get()[1])
print(top_idxs) # top_idxs stores the following table of problems with the highest similarity (existing in qlist)
# hint: use the priority queue to find top results. Think about why you can do this?
# Because the first value of the priority queue can be a floating point number, it can be converted to priority by using 1.0-similarity
result = [alist[i] for i in top_idxs]
return result # Return the answer corresponding to the question with the highest similarity as the top 5 answer
qlist, alist = read_corpus()
q_dict, q_list_list = data_pre(qlist)
new_qlist = filter_words(q_list_list, q_dict, 2, 1000)
print(top5results("when did Beyonce start becoming popular?"))
print(top5results("what languge does the word of 'symbiosis' come from"))
Print as follows:
qlist len:86821 alist len:86821 [0, 60835, 39267, 23136, 693] ['in the late 1990s', 'mandolin-based guitar programs', 'Particularly since the 1950s, pro wrestling events have frequently been responsible for sellout crowds at large arenas', 'early DJs creating music in their own homes', 'Agnèz Deréon'] [7786, 41967, 8154, 27470, 7844] ['Greek', 'living together', 'Persian and Sanskrit', '1570s', 'the evolution of all eukaryotes']
2.7 optimization using inverted table method
The biggest disadvantage of the above algorithm is that each user problem needs to calculate the similarity with all the problems in the library. Assuming that there are many problems in our library, this will be a very inefficient method. One solution is to find a problem description similar to the current input from the library by inverted table. Then do the cosine similarity calculation for these candidates. This will save a lot of time.
Optimization based on inverted table. Here, we can define a hash like_ Map, such as inverted_index = {}, and then store where the documents containing each keyword appear. That is, first judge the documents containing these keywords (for example, at least one appears) through keyword search, and then compare the similarity of candidates.
from functools import reduce
inverted_idx = {} # Make a simple inverted list
for i in range(len(qlist)):
for word in qlist[i].split():
if word in inverted_idx:
inverted_idx[word].append(i)
else:
inverted_idx[word] = [i]
for key in inverted_idx:
inverted_idx[key] = sorted(inverted_idx[key])
# Find the intersection of two set s
def intersections(set1, set2):
return set1.intersection(set2)
def top5results_invidx(input_q):
"""
Questions given user input input_q, Return the most likely TOP 5 Question. The following points need to be done:
1. Use inverted table to filter candidate
2. For user input input_q First do a series of preprocessing, and then convert to tf-idf Vector (using the above vectorizer)
3. Calculate the similarity with the problems in each library
4. Find the most similar top5 The answer to the question
"""
# Process input string
stop_words = set(stopwords.words('english'))
stemmer = PorterStemmer()
pattern = re.compile('[{}]'.format(re.escape(string.punctuation))) # Regular matching special symbols
sentence = pattern.sub("", input_q)
sentence = sentence.lower()
word_list = sentence.split()
result_list = []
for word in word_list:
if word not in stop_words:
word = "#number" if word.isdigit() else word
word = stemmer.stem(word)
result_list.append(word)
# Find the relevant index in the inverted table for the candidate set of answers
candidate_list = []
for word in result_list:
if word in inverted_idx:
idx_list = inverted_idx[word]
candidate_list.append(set(idx_list))
# Index of candidate questions
# print(candidate_list)
candidate_idx = list(reduce(intersections, candidate_list))
input_seg = ' '.join(result_list)
vectorizer = TfidfVectorizer(smooth_idf=False) # Define a TF IDF vectorizer
X = vectorizer.fit_transform(new_qlist) # The results are stored in the X matrix
input_vec = vectorizer.transform([input_seg])
# Calculate the similarity in all candidate indexes
similarity_list = []
for i in candidate_idx:
similarity = cosine_similarity(input_vec, X[i])[0]
similarity_list.append((i, similarity[0]))
res_sorted = sorted(similarity_list, key=lambda k: k[1], reverse=True)
print(type(res_sorted))
# Retrieve top 5 answers according to the index
answers = []
i = 0
for (idx, score) in res_sorted:
if i < 5:
answer = alist[idx]
answers.append(answer)
i += 1
return answers
2.8 text representation Optimization: use word vectors to represent text
The methodology used above is based on the bag of words model.
Such a methodology has two main problems:
- The similarity between words cannot be calculated
- The sparsity is very high. In 2.7, we use word vector as the representation of text.
Word vectors need to be downloaded: https://nlp.stanford.edu/projects/glove/ (download glove.6B.zip) and use the word vector with d=100 (100 dimensions).
Read glove.6B
Read the embedding of each word. This is the matrix of D*H, where D is the size of the dictionary and H is the size of the word vector. How to express the sentence vector given by us for each word? Among them, the simplest way is the sentence vector = the average of the word vector (appearing in the question sentence) , if a given word does not appear in the dictionary, the word is ignored.
def load_glove(path):
#The first element stores vectors with all zeros, representing those that do not exist in the dictionary
vocab = {}
embedding = []
vocab["UNK"] = 0
embedding.append([0] * 100)
with open(path, 'r', encoding='utf8') as f:
i = 1
for line in f:
row = line.strip().split()
vocab[row[0]] = i
embedding.append(row[1:])
i += 1
return vocab, embedding
2.9 for the user's input questions, find the questions with the highest similarity of top 5, and return the five potential answers
def top5results_emb(input_q=''):
"""
Questions given user input input_q, Return the most likely TOP 5 Problem. The following points need to be done:
1. Use inverted table to filter candidate
2. For user input input_q,Convert to sentence vector
3. Calculate the similarity with the problems in each library
4. Find the most similar top5 The answer to the question
"""
path = "data/glove.6B.100d.txt"
# Vacab is a dictionary and embedding is a matrix of len(vacab)*100.
vocab, embedding= load_glove(path)
stop_words = set(stopwords.words('english'))
pattern = re.compile('[{}]'.format(re.escape(string.punctuation)))
sentence = pattern.sub("", input_q)
sentence = sentence.lower()
word_list = sentence.split()
result_list = []
for word in word_list:
if word not in stop_words:
word = "#number" if word.isdigit() else word
result_list.append(word)
input_q = " ".join(result_list)
qlist, alist = read_corpus()
q_dict, q_list_list = data_pre(qlist)
new_qlist = filter_words(q_list_list, q_dict, 2, 1000)
inverted_idx = {} # Make a simple inverted list
for i in range(len(new_qlist)):
for word in new_qlist[i].split():
if word in inverted_idx:
inverted_idx[word].append(i)
else:
inverted_idx[word] = [i]
for key in inverted_idx:
inverted_idx[key] = sorted(inverted_idx[key])
candidates = []
for word in result_list:
if word in inverted_idx:
ids = inverted_idx[word]
candidates.append(set(ids))
candidate_idx = list(reduce(intersections, candidates)) # Candidate question index
input_q_vec=word_to_vec(input_q,vocab, embedding)
scores = []
for i in candidate_idx:
vec = word_to_vec(new_qlist[i], vocab, embedding)
score = cosine_similarity([input_q_vec, vec])[0]
scores.append((i, score[1]))
scores_sorted = sorted(scores, key=lambda k: k[1], reverse=True)
# Retrieve top 5 answers according to the index
answers = []
i = 0
for (idx,score) in scores_sorted:
if i < 5:
answer = alist[idx]
answers.append(answer)
i += 1
return answers
print(top5results_emb("when did Beyonce start becoming popular?"))
print(top5results_emb("what languge does the word of 'symbiosis' come from"))
print(top5results_emb("In her music, what are some?"))
3. Other similarity calculation
word2vec, WMD, doc2vec, etc
Optimization: use ES and its own TF-IDF
Original link:
come on.
thank!
strive!