class is a production bert_lstm's factory has an initialization function (init) and two instance method function functions (forward, init_hidden)
instance method refers to the Bert after processing initialization in the factory_ Function of LSTM
There is also a class method, which refers to the function of processing the factory, which is not involved here.
A bert_lstm requires output_size,n_layers,hidden_dim,bidirectional,lstm,dropout (all self. Things) can be constructed
When using the instance method, you need to know which Bert to use_ LSTM is used for processing, but because it has not been initialized, a position must be vacated and replaced by self temporarily. After the specific initialization parameters are given, an original Bert is generated_ After LSTM, the original bert_lstm for processing operations.
class bert_lstm(nn.Module):
def __init__(self, hidden_dim, output_size, n_layers, bidirectional=True, drop_prob=0.5):
super(bert_lstm, self).__init__()
drop_prob: when training the network, the network neural unit is temporarily discarded according to a certain probability. It has randomness and is used to prevent over fitting. It is generally set to 0.5
self.output_size = output_size
self.n_layers = n_layers
self.hidden_dim = hidden_dim
self.bidirectional = bidirectional
# bert ------------- key point: the bert model needs to be embedded into the user-defined model
self.bert = BertModel.from_pretrained("bert_base_chinese")
for param in self.bert.parameters():
param.requires_grad = True
# LSTM layers
self.lstm = nn.LSTM(768, hidden_dim, n_layers, batch_first=True, bidirectional=bidirectional)
# dropout layer
self.dropout = nn.Dropout(drop_prob)
# linear and sigmoid layers
if bidirectional:
self.fc = nn.Linear(hidden_dim * 2, output_size)
else:
self.fc = nn.Linear(hidden_dim, output_size)
# self.sig = nn.Sigmoid()
def forward(self, x, hidden):
batch_size = x.size(0)
# Generate bert word vector
x = self.bert(x)[0] # bert word vector
The dimension of X (a tensor) after convolution or pooling is (batchsize, channels, x, y). Take the value of position 0, that is, the value of batchsize, as batch_size
# lstm_out
# x = x.float()
lstm_out, (hidden_last, cn_last) = self.lstm(x, hidden)
# print("3shape:") #[32,100,768]
# print(lstm_out.shape)
# print(hidden_last.shape) #[4, 32, 384]
# print(cn_last.shape) #[4, 32, 384]
# The two-way modification needs to be handled separately
if self.bidirectional:
# Forward to the last layer, the last moment
hidden_last_L = hidden_last[-2]
# print("hidden_last_L.shape:")
# print(hidden_last_L.shape) #[32, 384]
# Reverse the last layer, the last moment
hidden_last_R = hidden_last[-1]
# print("hidden_last_R.shape:")
# print(hidden_last_R.shape) #[32, 384]
# Splice
hidden_last_out = torch.cat([hidden_last_L, hidden_last_R], dim=-1)
# print("hidden_last_out.shape:")
# print(hidden_last_out.shape,'hidden_last_out') #[32, 768]
else:
hidden_last_out = hidden_last[-1] # [32, 384]
# dropout and fully-connected layer
out = self.dropout(hidden_last_out)
# print('out.shape:')
# print(out.shape) #[32,768]
out = self.fc(out)
return out
Call init in ConvLSTMCell_ Hidden function to get the initial hidden_state
def init_hidden(self, batch_size):
weight = next(self.parameters()).data
number = 1
if self.bidirectional:
number = 2
if (USE_CUDA):
hidden = (weight.new(self.n_layers * number, batch_size, self.hidden_dim).zero_().float().cuda(),
weight.new(self.n_layers * number, batch_size, self.hidden_dim).zero_().float().cuda()
)
else:
hidden = (weight.new(self.n_layers * number, batch_size, self.hidden_dim).zero_().float(),
weight.new(self.n_layers * number, batch_size, self.hidden_dim).zero_().float()
)
return hidden
According to the above code, a Bert can be constructed by providing parameters_ lstm
output_size = 1
hidden_dim = 384 # 768/2
n_layers = 2
bidirectional = True # This is True and bidirectional LSTM
net = bert_lstm(hidden_dim, output_size, n_layers, bidirectional)
Prediction function (not belonging to class bert_lstm)
The main class is BasicTokenizer, which does some basic operations such as case conversion, unicode conversion, punctuation segmentation, lowercase conversion, Chinese character segmentation and accent removal. Finally, it returns an array of words (Chinese is an array of words)
def predict(net, test_comments):
comments_list = pretreatment(test_comments) # Preprocessing to remove punctuation
# Convert to word id
tokenizer = BertTokenizer.from_pretrained("bert_base_chinese")
According to bert_base_chinese Dictionary vocab The tokenizer can decompose each sentence into one word, i.e. one word
comments_list_id = tokenizer(comments_list, padding=True, truncation=True, max_length=120, return_tensors='pt')
tokenizer_id = comments_list_id['input_ids']
inputs = tokenizer_id
batch_size = inputs.size(0)
# initialize hidden state
h = net.init_hidden(batch_size)
if (USE_CUDA):
inputs = inputs.cuda()
net.eval()
When training the model, you will add: net Train(), used in front when testing the model: net eval()
with torch.no_grad():
The tensor will not automatically seek the derivation during back propagation, so as to save memory.
output = net(inputs, h)
When output is an element tensor, use item to get the element value.
if output.item() >= 0:
print("For prediction results:Forward")
else:
print("The prediction result is:Negative direction")
if __name__ == '__main__':
np.random.seed(2020)
torch.manual_seed(2020) # Seed the CPU to generate random numbers so that the results are deterministic
USE_CUDA = torch.cuda.is_available()
if USE_CUDA:
torch.cuda.manual_seed(2020) # Set random seeds for the current GPU;
path = 'ChnSentiCorp_htl_8000.csv' # Training set path
data = pd.read_csv(path, encoding='gbk')
# print(data)
comments_list = pretreatment(list(data['review'].values))#Preprocess the contents of the review column in the csv file
lenth = len(comments_list)
print('the length of data set is:',lenth)
print('the raw comments_list:',comments_list)
comments_list[:1]
print('after [:1] :',comments_list)
tokenizer = BertTokenizer.from_pretrained("bert_base_chinese")
comments_list_id = tokenizer(comments_list, padding=True, truncation=True, max_length=200, return_tensors='pt')
#Split the data set into test set, verification set and training set according to 1.5:1.5:7
X = comments_list_id['input_ids']#x is the comment content
y = torch.from_numpy(data['label'].values).float()#y is label
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=True, stratify=y,
random_state=2020)
X_valid, X_test, y_valid, y_test = train_test_split(X_test, y_test, test_size=0.5, shuffle=True, stratify=y_test,
random_state=2020)
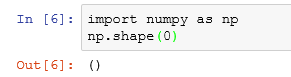
The role of the shape function: LINK
(1) When the parameter is a number, return null:
(2) The parameter is a one-dimensional matrix, which returns the length of the first dimension:
(3) The parameter is a two-dimensional matrix, which returns the length of the first dimension and the second dimension:

#The shape function reads the matrix shape
X_train.shape
# print(X_train.shape)
y_train.shape
# print(y_train.shape)
# Create Tensor datasets for validation sets, test sets, and training sets
train_data = TensorDataset(X_train, y_train)
valid_data = TensorDataset(X_valid, y_valid)
test_data = TensorDataset(X_test, y_test)
# Amount of data loaded each time
batch_size = 5
# make sure the SHUFFLE your training data
train_loader = DataLoader(train_data, shuffle=True, batch_size=batch_size, drop_last=True)
valid_loader = DataLoader(valid_data, shuffle=True, batch_size=batch_size, drop_last=True)
test_loader = DataLoader(test_data, shuffle=True, batch_size=batch_size, drop_last=True)
#print('valid_loader', valid_loader)
# Take a batch in the training set for output inspection
dataiter = iter(train_loader)
sample_x, sample_y = dataiter.next()
print('Sample comment size: ', sample_x.size()) # batch_size, seq_length
print('Sample comment: \n', sample_x)# True comment content
print()
print('Sample label size: ', sample_y.size()) # batch_size
print('Sample label: \n', sample_y)# Real label
# Model building
if (USE_CUDA):
print('Training on GPU.')
else:
print('No GPU available, training on CPU.')
# Construct bert_lstm
output_size = 1
hidden_dim = 384 # 768/2
n_layers = 2
bidirectional = True # This is True and bidirectional LSTM
net = bert_lstm(hidden_dim, output_size, n_layers, bidirectional)
# Training model
# Learning rate, loss function, optimizer
lr = 0.00001
criterion = nn.BCELoss()
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
# Parameters of model training
epochs = 2
# step
print_every = 5
clip = 5 # Gradient clipping to solve the problem of gradient explosion
# Put the model from CPU into GPU for training
if (USE_CUDA):
net.cuda()
net.train()# train function should be used before model training and eval function should be used before testing
# Use the divided training set to train the model according to the set training times
for e in range(epochs):
# initialize hidden state
h = net.init_hidden(batch_size)
counter = 0
# The training set loads the training according to the batch value
for inputs, labels in train_loader:
counter += 1
if (USE_CUDA):
inputs, labels = inputs.cuda(), labels.cuda()
h = tuple([each.data for each in h])
# Remove unnecessary loading code to alleviate memory overflow
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
# Set the parameter gradient of the model to 0
net.zero_grad()
output = net(inputs, h)
# print('label:')
# print(labels.long())
# print(labels.size)
# wang these are used for testing to test whether the model is trained normally
'''
print('output', output) # wang
print('output_sigmoid', torch.sigmoid(output.squeeze())) # wang
print('labels', labels) # wang
print('train_max',torch.max(torch.sigmoid(output.squeeze()), 0)[1])
print('pred_max', torch.max(torch.nn.Softmax(dim=1)(output), 1)[1]) Make in softmax After operation dim This dimension adds up to 1
'''
'''
out_max = torch.sigmoid(output.squeeze()) #wang
print('out_before', out_max) #wang
out_max=torch.max(out_max) #wang
print('out_after', out_max.item()) #wang
'''
loss = criterion(torch.sigmoid(output.squeeze()), labels.float())
loss.backward()
nn.utils.clip_grad_norm_(net.parameters(), clip)
optimizer.step()
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
# For each step, the loss of verification set is calculated
if counter % print_every == 0:
net.eval()
with torch.no_grad():
val_h = net.init_hidden(batch_size)
val_losses = []
for inputs, labels in valid_loader:# Validation set validation
val_h = tuple([each.data for each in val_h])
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
if (USE_CUDA):
inputs, labels = inputs.cuda(), labels.cuda()
output = net(inputs, val_h)
val_loss = criterion(torch.sigmoid(output.squeeze()), labels.float())
# print('loss:')
# print(val_loss)
val_losses.append(val_loss.item())
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
net.train()
print("Epoch: {}/{}...".format(e + 1, epochs),
"Step: {}...".format(counter),
"Loss: {:.6f}...".format(loss.item()),# Loss of training set
"Val Loss: {:.6f}".format(np.mean(val_losses)))# Loss of validation set
# test
test_losses = [] # track loss
num_correct = 0
# init hidden state
h = net.init_hidden(batch_size)
net.eval()
# Calculate test set loss
for inputs, labels in test_loader:
h = tuple([each.data for each in h])
if (USE_CUDA):
inputs, labels = inputs.cuda(), labels.cuda()
output = net(inputs, h)
test_loss = criterion(torch.sigmoid(output.squeeze()), labels.float())
test_losses.append(test_loss.item())
output = torch.nn.Softmax(dim=1)(output)
prediction = torch.max(output, 1)[1]
# print('prediction_type',type(prediction)) #wang
# print('prediction_size', pred.size()) #wang
# compare predictions to true label
correct_tensor = prediction.eq(labels.long().view_as(prediction)) # The label is processed into the same shape as the prediction, that is, it can be compared
correct = np.squeeze(correct_tensor.numpy()) if not USE_CUDA else np.squeeze(correct_tensor.cpu().numpy())# The tensor in the CPU can be taken out directly. The tensor in the GPU needs to be put into the CPU first, that is The cpu() method can then be taken out
num_correct += np.sum(correct)# Calculate the correct predicted quantity
print("Test loss: {:.3f}".format(np.mean(test_losses)))
# Calculate the accuracy of the test set
test_acc = num_correct / len(test_loader.dataset)
print("Test accuracy: {:.3f}".format(test_acc))
# test
comment1 = ['exo Illegitimate meals follow members into the dormitory. Can the company strengthen supervision in the future? What's all this']
predict(net, comment1)
comment2 = ['The best film of the same period is true without hypocrisy']
predict(net, comment2)
comment3 = ['It's said that it's so happy to have a barbecue when you come back from work in the evening']
predict(net, comment3)
comment4 = ['The film is worth it. It needs a second brush']
predict(net, comment4)
comment5 = ['Police brutality? Isn't the life of black people life? Can the world continue to stink']
predict(net, comment5)
comment6 = ['The food in this restaurant is not bad, but the price is a little high']
predict(net, comment6)
comment7 = ['Is there any kind-hearted person willing to adopt this cat? It's very good and beautiful']
predict(net, comment7)
comment8 = ['The atmosphere in the entertainment industry really needs to be straightened out. There must be more than one person who evades taxes']
predict(net, comment8)
# Model saving
torch.save(net.state_dict(), './Two categories of Hotel Reviews_parameters.pth')
output_size = 1
hidden_dim = 384 # 768/2
n_layers = 2
bidirectional = True # This is True and bidirectional LSTM
net = bert_lstm(hidden_dim, output_size, n_layers, bidirectional)
net.load_state_dict(torch.load('./Two categories of Hotel Reviews_parameters.pth'))# Model loading
# move model to GPU, if available
if (USE_CUDA):
net.cuda()
comment1 = ['Japan wants to discharge nuclear sewage into the sea. The community of shared future is not a joke. Most people only see a profitable community, but we should bear the disaster together!!']
predict(net, comment1)