You must have learned the differences between names, verbs, adjectives and adverbs before. These parts of speech are not idle, but useful classifications for many language processing tasks. As we will see, these classifications come from a simple analysis of the distribution of words in the text.
The process of classifying words according to their part of speech (POS) and labeling them is called POS tagging, which is called tagging for short. Part of speech is also called part of speech or lexical category. The set of tags used for a specific task is called a tag set. Our focus in this chapter is to use tags and automatically label text.
Use part of speech tagger:
import nltk
text=nltk.word_tokenize("customer found there are abnormal issue")
print(nltk.pos_tag(text))then.. Wrong report

You need to run nltk.download again to download and copy the file to the search path of the previous error prompt. lang time: Output results: [('customer', 'NN'), ('found ',' VBD '), ('there', 'EX'), ('are ',' VBP '), ('abnormal', 'JJ'), ('issue ',' NN ')]
Here we get each word and the part of speech of each word. The following table is a simplified part of speech tag set
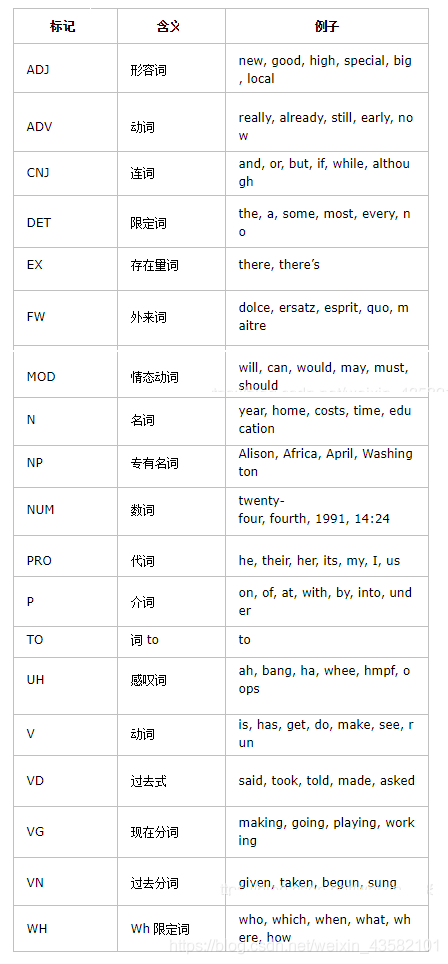
annotated corpus
Indicates the marked identifier: nltk.tag.str2tuple('word / type ') According to the Convention of NKTL, a labeled biao identifier is represented by an ancestor composed of identifier and tag. We can use the function str2tuple() to create such a special ancestor from the standard string representing a labeled identifier:
tagged_token = nltk.tag.str2tuple('fly/NN')
print(tagged_token)The output is ('fly ',' NN ')
We can construct a linked list of labeled identifiers from a string. The first step is to segment the string so that we can access individual word / tag strings, and then convert each into a primitive (using str2tuple()) Set: send = "" XXXXXXXX... XXXXXXXXXXXX ""
print([nltk.tag.str2tulpe(t) for t in sent.split()])
. . Read marked corpus
NLTK corpus provides a unified interface, which can ignore different file formats. Format: corpus.tagged_word()/tagged_sents(). Parameters can specify categories and fields
print(nltk.corpus.brown.tagged_words())
Output: [('The ',' AT '), ('Fulton', 'NP-TL'),...]
. . Simplified part of speech tag set
Annotated corpora use many different tag set conventions to annotate vocabulary. To help us get started, we'll see a simplified tag set.
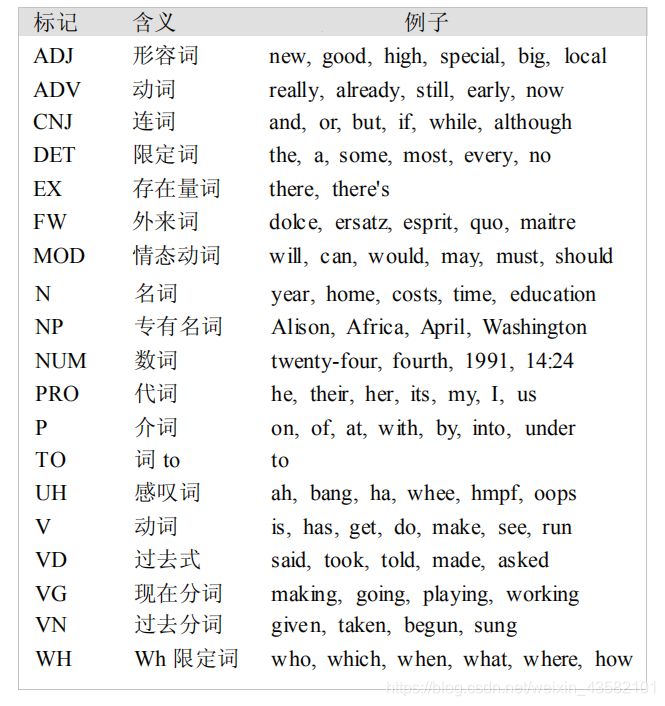
Let's take a look at those markers that are common in the news of brown corpus:
brown_news_tagged = nltk.corpus.brown.tagged_words() tag_fd = nltk.FreqDist(tag for (word,tag) in brown_news_tagged) print(tag_fd.keys())
Output: dict_keys([‘AT’, ‘NP-TL’, ‘NN-TL’, ‘JJ-TL’, ‘VBD’,…‘PN+HVD’, ‘FW-UH-TL’])
. . Nouns, verbs, adjectives, etc One more word, Nouns generally refer to people, places, things or concepts, such as women, Scotland, books, information, etc. Names may appear after qualifiers and adjectives. They can be verbs or subjects or objects.
Verbs are used to describe events and adjectives.
Adjectives modify nouns and can be used as modifiers or predicates.
Adverbs modify verbs to specify time, manner, place or the direction of the event described by the verb.
Take nouns as an example:
from nltk.corpus import brown
import nltk
word_tag = nltk.FreqDist(brown.tagged_words(categories="news"))
print([word+'/'+tag for (word,tag)in word_tag if tag.startswith('V')])
#Here are the different labels for finding money
wsj = brown.tagged_words(categories="news")
cfd = nltk.ConditionalFreqDist(wsj)
print(cfd['money'].keys())
Try to find the most frequent noun in each noun type
def findtag(tag_prefix,tagged_text):
cfd = nltk.ConditionalFreqDist((tag,word) for (word,tag) in tagged_text if tag.startswith(tag_prefix))
return dict((tag,list(cfd[tag].keys())[:5]) for tag in cfd.conditions())#The data type must be converted to list for slicing
tagdict = findtag('NN',nltk.corpus.brown.tagged_words(categories="news"))
for tag in sorted(tagdict):
print(tag,tagdict[tag])
Explore annotated corpora nltk.bigrams() and nltk.trigrams() are required to correspond to 2-gram model and 3-gram model respectively.
brown_tagged = brown.tagged_words(categories="learned") tags = [b[1] for (a,b) in nltk.bigrams(brown_tagged) if a[0]=="often"] fd = nltk.FreqDist(tags) fd.tabulate()
Auto label The simplest annotator is to assign a uniform tag to each identifier. The following is a marker that turns all words into NN. And use evaluate() to check. When many words are nouns, it helps to analyze for the first time and improve stability.
raw = 'I do not like eggs and ham, I do not like them Sam I am'
tokens = nltk.word_tokenize(raw)
default_tagger = nltk.DefaultTagger('NN')#Create a callout
print(default_tagger.tag(tokens)) # Call the tag() method to label
print(default_tagger.evaluate(brown_tagged_sents))Regular expression annotator Note that the rules here are fixed (at your own discretion). When the rules are more and more perfect, the accuracy is higher.
patterns = [
(r'.*ing$','VBG'),
(r'.*ed$','VBD'),
(r'.*es$','VBZ'),
(r'.*','NN')#For convenience, there are only a few rules]
regexp_tagger = nltk.RegexpTagger(patterns)
regexp_tagger.evaluate(brown_tagged_sents)Query locator
The query annotator stores the most likely tags, and the backoff parameter can be set. If the tag cannot be used, the annotator is used (this process is fallback)
fd = nltk.FreqDist(brown.words(categories="news"))
cfd = nltk.ConditionalFreqDist(brown.tagged_words(categories="news"))
most_freq_words = fd.most_common(100)
likely_tags = dict((word,cfd[word].max()) for (word,times) in most_freq_words)
baseline_tagger = nltk.UnigramTagger(model=likely_tags,backoff=nltk.DefaultTagger('NN'))