The traditional statistical language model is a nonparametric model, that is, the conditional probability is estimated directly by counting, but the main disadvantage of this nonparametric model is poor generalization and can not make full use of similar context
The idea of using neural network to train language model was first proposed by Xu Wei of Baidu IDL (deep learning Research Institute). NNLM (neural network language model) is a classic model in this regard. For details, please refer to the paper published by bengio on JMLR in 2003. Original address: http://jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
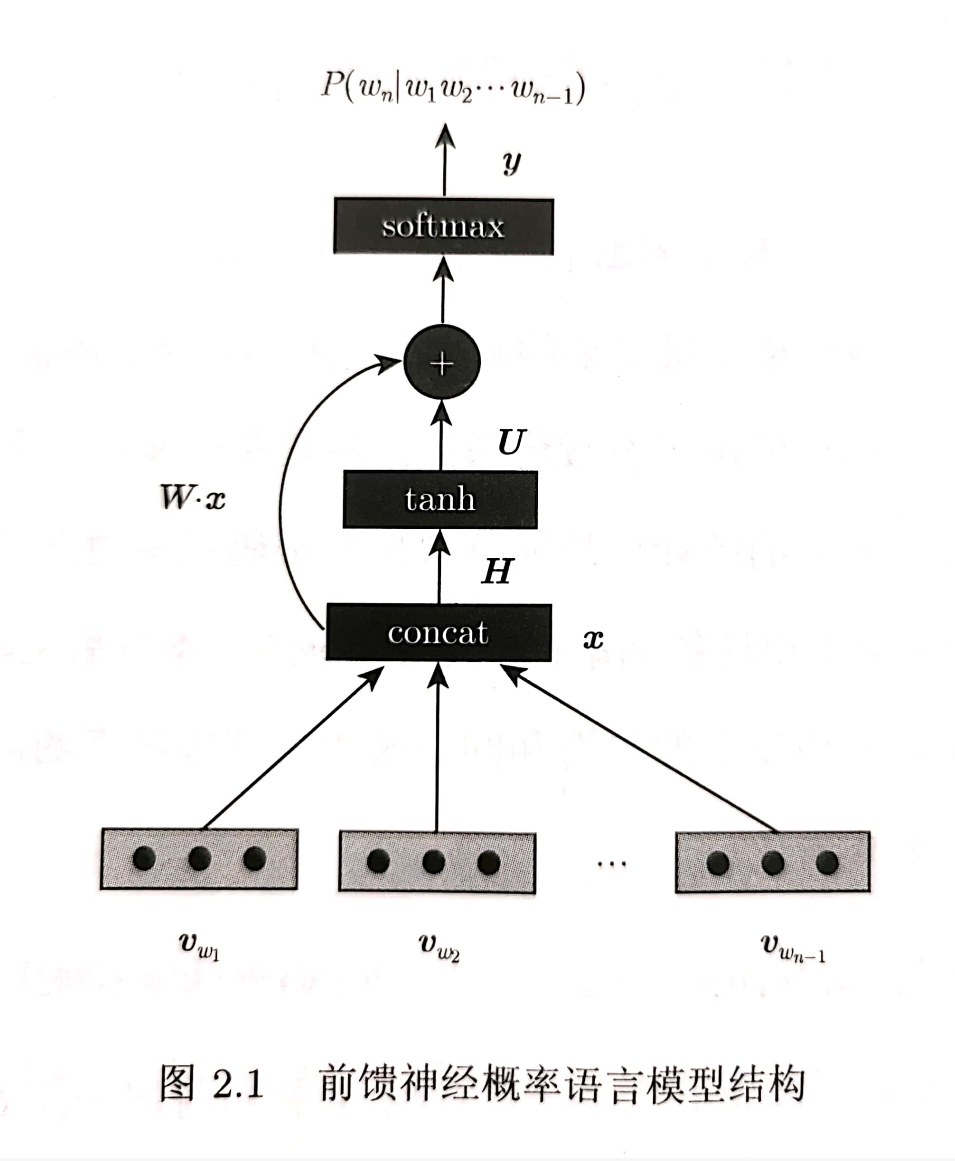
And tradition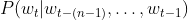 The NNLM model directly evaluates the n-ary conditional probability through a neural network structure. The basic idea can be expressed as follows:
The NNLM model directly evaluates the n-ary conditional probability through a neural network structure. The basic idea can be expressed as follows: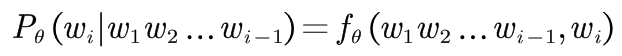
Where, function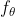 The two input variables are context and current word,
The two input variables are context and current word,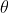 Represent the parameters of the model, such as weights in neural networks
Represent the parameters of the model, such as weights in neural networks
Each word entered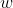 Corresponding to a vector
Corresponding to a vector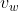 , n-1 vectors are spliced to form the input column vector x, which is expressed as follows:
, n-1 vectors are spliced to form the input column vector x, which is expressed as follows:
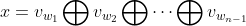
Column vector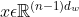 ,
,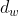 Represents the word vector dimension. The network structure is formalized as follows:
Represents the word vector dimension. The network structure is formalized as follows:
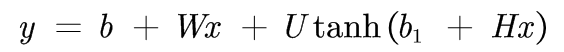
Among them,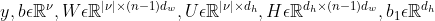 , all learnable parameters,
, all learnable parameters, 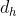 Expressed as hidden layer dimension (number of neurons), each dimension of output y corresponds to the output value of each word in this table in the neural network. Finally, the result is normalized by softmax:
Expressed as hidden layer dimension (number of neurons), each dimension of output y corresponds to the output value of each word in this table in the neural network. Finally, the result is normalized by softmax:
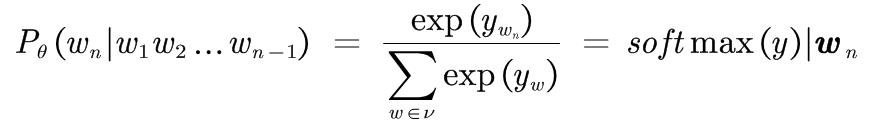
The model uses maximum likelihood estimation to optimize the parameters, and the goal is to maximize the probability of observation data:
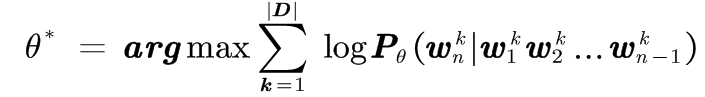
The probability parameter is the k-th n-gram phrase in the training corpus set D. the training data has divided the text preprocessing into n-gram phrases. Is an optional parameter. If the input layer and the output layer are not directly connected (as shown by the green dotted line in the figure), you can make
Is an optional parameter. If the input layer and the output layer are not directly connected (as shown by the green dotted line in the figure), you can make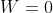
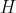 Is the weight matrix from input layer to hidden layer.
Is the weight matrix from input layer to hidden layer.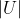 Is the weight matrix from hidden layer to output layer.
Is the weight matrix from hidden layer to output layer.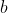 and
and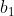 They are the offset parameters of the hidden layer and the output layer respectively.
They are the offset parameters of the hidden layer and the output layer respectively.
Code from https://github.com/graykode/nlp-tutorial/blob/master/1-1.NNLM/NNLM.py
# %%
# code by Tae Hwan Jung @graykode
import torch
import torch.nn as nn
import torch.optim as optim
def make_batch():
input_batch = []
target_batch = []
for sen in sentences:
word = sen.split() # space tokenizer
input = [word_dict[n] for n in word[:-1]] # create (1~n-1) as input
target = word_dict[word[-1]] # create (n) as target, We usually call this 'casual language model'
input_batch.append(input)
target_batch.append(target)
return input_batch, target_batch
# Model
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(n_class, m)
self.H = nn.Linear(n_step * m, n_hidden, bias=False)
self.b1 = nn.Parameter(torch.ones(n_hidden))
self.U = nn.Linear(n_hidden, n_class, bias=False)
self.W = nn.Linear(n_step * m, n_class, bias=False)
self.b = nn.Parameter(torch.ones(n_class))
def forward(self, X):
X = self.C(X) # X : [batch_size, n_step, m]
X = X.view(-1, n_step * m) # [batch_size, n_step * m]
tanh = torch.tanh(self.b1 + self.H(X)) # [batch_size, n_hidden]
output = self.b + self.W(X) + self.U(tanh) # [batch_size, n_class]
return output
if __name__ == '__main__':
n_step = 2 # number of steps, n-1 in paper
n_hidden = 2 # number of hidden size, h in paper
m = 2 # embedding size, m in paper
sentences = ["i like dog", "i love coffee", "i hate milk"]
word_list = " ".join(sentences).split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
n_class = len(word_dict) # number of Vocabulary
model = NNLM()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
input_batch, target_batch = make_batch()
input_batch = torch.LongTensor(input_batch)
target_batch = torch.LongTensor(target_batch)
# Training
for epoch in range(5000):
optimizer.zero_grad()
output = model(input_batch)
# output : [batch_size, n_class], target_batch : [batch_size]
loss = criterion(output, target_batch)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()
# Predict
predict = model(input_batch).data.max(1, keepdim=True)[1]
# Test
print([sen.split()[:2] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])Summarize the advantages and disadvantages
advantage:
1. When n increases to n+1, the parameters of neural network language model increase less than that of traditional model, but increase linearly.
2. In practice, the performance index of this model is significantly better than that of the traditional model, and it is easier to be extended to high-order n-ary syntax.
3. The model uses the vector representation of words, and the same words in different positions can share parameters, so that the model can share statistical information between different contexts, which has stronger generalization.
Disadvantages:
The computational overhead is higher, which comes from normalization and matrix multiplication. Some methods introduced later, such as negative sampling and some optimization in static word vector model, can improve this disadvantage.
reference material:
Understanding of neural network language model (NNLM)_ lilong117194 blog - CSDN blog_ nnlm
Language model: from n-ary model to NNLM - Zhihu