In this article, you will see:
- Conceptual relationship among MySQL, SQL, ORM and serialize
- Use of sequenize
- The concept, usage, principle and difference of join table relation in sequenize
- How to optimize database query
1 Concept
MySQL
Most people know about MySQL and SQL. After all, it is written in textbooks. MySQL is a typical relational database. How to call it relational?
In short, relational database is a database composed of multiple two-dimensional row and column tables that can be connected with each other.Here are two points::: two-dimensional row list:: (reflected in the data structure of individual table) and:: Interconnection:: (reflected in the characteristics of table relationship and library engine).
Compared with NoSQL such as MongoDB, the advantages of two-dimensional row list are:
- Reliability brought by rigorous data structure: the data type and even size of each column are defined by the model, and everything is stable
- Convenience of understanding brought by "flat layer": every piece of data is "flat layer". After all, free nesting is really too Southern to read
SQL
Since the relational database is a unified standard, as long as each company implements it according to the standard, the rest can be unified, such as the access to the database.
This is what SQL does. It is just a string, which can be understood as a command to do any operation on a relational database. However, considering that relational design has simplified complex things, SQL does nothing more than these things:
- Define the library, the table itself, and the relationship between tables
- Add, delete, modify and query in a table
- With the help of inter table relationship, the data in multiple tables can be accessed jointly at one time
- Access some basic arithmetic functions
In short, if you put these together, in theory, you can do whatever you want with "only one SQL". Learn more: according to my knowledge level, I can only read Rookie course
ORM and Sequlize
But SQL is far from enough, because the string itself has no constraints. You may want to check a data, but you shake your hand and delete the library by mistake, so you can only run away. In addition, writing a bunch of strings in code is really ugly.
So there is something called orm. What is ORM? It literally means: "object relationship mapping":: it's a little windy.
In fact, it is to map database tables into language objects; Then, a bunch of methods are exposed to check the database, and ORM is responsible for converting method calls into SQL; Because the records in the table are in the form of key - value, the returned result of query is usually an object, which is convenient for using data. In this way, the convenience and stability of database access have been improved.
method SQL
Business logic <------> ORM <------> database
data object dataHowever, ORM is only a solution. On the right side, it is not limited by the database type. Any relational database that follows SQL is supported; On the left, it is not limited by language types. Each family has relatively mature implementation schemes, and even adds some language level optimization support according to language characteristics.
In nodejs, "Sequlizejs" is probably the most outstanding ORM implementation. Rooted in nodejs, Sequlizejs perfectly supports Promise call. Further, you can use async/await to closely bond with business code; If ts is used, the type reminder from the model definition can make the call easier.
The official documents are here: <Sequelize V5>
2 basic usage
Definition of table / model
As mentioned earlier, the first step of ORM is to establish the mapping between objects and data tables. In Sequlize, for example, we associate the table of a station
const Model = sequlize.define('station', {
id: {
field: 'id',
type: Sequelize.INTEGER,
allowNull: false,
primaryKey: true,
autoIncrement: true,
},
store_id: Sequelize.STRING(20),
name: Sequelize.STRING(20),
type: Sequelize.TINYINT,
status: Sequelize.TINYINT,
ip: Sequelize.STRING(20),
plate_no: Sequelize.STRING(20),
related_work_order_id: Sequelize.BIGINT,
});
It can be seen that during the definition process, the data type is referenced from the sequenize static attribute. These types can cover the types in the database, but the names are not corresponding. For details: lib/data-types.js
You can also customize the third parameter of define. These configurations will be incorporated into the define field of the Sequlize constructor to define the association behavior between the model and the data table, such as "automatically update_at and create_at in the table". Reference Model | Sequelize options in
However, the model belongs to the model and is used for ORM. The tables in the database should be built by themselves. Create SQL tables through the client or the following:
CREATE TABLE `station` ( `id` bigint(11) unsigned NOT NULL AUTO_INCREMENT, `store_id` varchar(20) NOT NULL DEFAULT '', `name` varchar(20) NOT NULL DEFAULT '', `type` tinyint(4) NOT NULL DEFAULT '0', `status` tinyint(4) NOT NULL DEFAULT '0', `ip` varchar(20) NOT NULL DEFAULT '', `related_work_order_id` bigint(20) NOT NULL DEFAULT '0', `created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP, `updated_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP, `plate_no` varchar(20) NOT NULL DEFAULT '', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8 COMMENT='Station table';
Basic CURD
Sequlize objects provide rich APIs, such as:
- findOne,findAll......
- create,upsert......
- aggregate,max......
There should be no need to repeat the call of API and the document /lib/model.js~Model Everything is arranged in the house. Here we mainly look at what Sequlize turns into when we call a basic api, which is very helpful to understand the corresponding relationship between ORM and SQL.
An example: findAll
When attributes are not given, serialize will take out the definitions in the model as attributes by default, which saves database operation cost and transmission bandwidth compared with Select *.The simplest, when I execute a
Station.findAll()
The SQL converted from Sequlize is like this
SELECT
`id`,
`store_id`,
`name`,
`type`,
`status`,
`ip`,
`plate_no`
FROM
`station` AS `station`;We can simply add some conditions:
Station.findAll({
attributes: [ 'ip' ],
where: {
status: 1,
},
order: [
[ 'name', 'ASC' ],
],
limit: 10,
offset: 5,
});
SQL (still very clear)
SELECT `ip` FROM `station` AS `station` WHERE `station`.`status` = 1 ORDER BY `station`.`name` ASC LIMIT 5, 10;
The second example: findOrCreate
Some advanced API s trigger database transactions:Things are usually not so simple, such as when I adjust
Station.findOrCreate({
where: {
id: 1,
},
defaults: {
name: 'haha',
},
});
You know, it can't be implemented in a SQL sentence, so sequlize starts the transaction and does "query - > judge - > Add"
START TRANSACTION; SELECT `id`, `store_id`, `name`, `type`, `status`, `ip`, `plate_no` FROM `station` AS `station` WHERE `station`.`id` = 2; INSERT INTO `station` (`id`,`name`) VALUES (2,`haha`); COMMIT;
3. Joint table query
3.1 why do we need to connect tables
Previously, we have a Station table, and now we have an additional Car table through station_id records the Station where the Car is located. I want to check the list of stations and the cars they contain.
find Station first, then where - station_id - in check the Car, and finally write logic to traverse the Station. It is feasible to insert the Car one by one. But on the one hand, one more query will increase the consumption of database resources, on the other hand, it also has more processing logic.
Therefore, we need to use the "inter table relationship" that "relational database" is good at to complete the above query and data consolidation at one time.
3.2 joint statement relationship
In Sequlize, the associated table relationship needs to be marked in the model associate method, usually in this format:
File.belongsTo(User, {...option});
Use include when checking
File.findOne({
include: [{ model: User }],
});
Like the model definition itself, this tag does not operate on the database, but establishes the relationship between models at the ORM layer. This relationship will be converted into a JOIN SQL statement such as "JOIN" when we call the JOIN table query.
The query operation is always "include", but whether to mark and which marking method to use determine whether the associated table query can be used in the subsequent query, as well as the SQL of the query and the organization of the query results.
First, clarify several concepts in a markup behavior
- Two models
- The relationship between the above query model and other table models is the relationship between the above query model and the source model
- Target model: a model with marked relationship. It does not obtain the ability of associated table query due to this mark (User above)
- Four Association keys
- foreignKey: foreign key, which is used to associate external models.:: a model with a foreign key is unique to the associated model:
- targetKey
- sourceKey
- otherKey: a substitute when a foreignKey is not enough
The relationships between tables usually include: one to one, one to many, and many to many.
3.3 one to one relationship (belongsTo / hasOne)
[serialize] one-to-one relationship document
[misunderstanding] I had a misunderstanding here before. I thought that "one-on-one" was "two-way and unique" like husband and wife, but it was not. Our relationship declaration can only be initiated in one direction from the source model, that is, the "one-to-one" relationship is also one-way. It can only ensure that "the source model record corresponds to a target model record", and vice versa.Like "son. Hasone", there is no guarantee that "father" has only one son.
One to one relationship can be marked by belongsTo and hasOne.
1 belongsTo
There is a} creator in the File_ ID mark the User (target model) to which you:: belong. Here, the User may not have only one File, but a File can only be associated with one User.
File.BelongsTo(User, {
foreignKey: 'creator_id', // If this is not defined, it will also be automatically defined as "target model name + target model primary key name", that is, user_id
targetKey: 'id', // The association key of the target model, the default primary key, is usually omitted
});
// Here is creator_ The ID is located on the source model File
2 hasOne
Condition or is there a} creator in the File model_ ID marks the User to which you belong. In this case, if the User is regarded as the source model, on the User side, assuming that a User has only one File, we need to get the File from the User:
User.HasOne(File, {
foreignKey: 'creator_id', // If this is not defined, it will also be automatically defined as "source model name + source model primary key name", that is, user_id
sourceKey: 'id', // The association key of the source model, the default primary key, is usually omitted
}
// Here is creator_ The ID is on the target model File
HasOne reverses the foreignKey to the source model, so it is convenient to use BelongsTo or HasOne for the location of foreignKey on the premise that targetKey and sourceKey use default values (usually the same).
3 BelongsTo and HasOne
BelongsTo and HasOne can define a "one-to-one" relationship. With the help of three key s, they can theoretically replace each other.

In fact, the converted SQL is the same:: LEFT JOIN::
# File.BelongsTo(User)
SELECT `FileClass`.`id`, `user`.`id` AS `user.id`
FROM `file` `FileClass`
LEFT JOIN `user` ON `FileClass`.`creator_id ` = `user`.`id`
# User.HasOne(File)
SELECT `UserClass`.`id`, `file`.`id` AS `file.id`
FROM `user` `UserClass`
LEFT JOIN `file` ON `UserClass`.`id ` = `file`.`creator_id `But at the "conceptual" level, "belonging" and "having one" are two different things. Which model is really "unique" relative to another model, then this model should have a foreignKey.
3.4 one to many (hasMany)
:: hasMany can be understood as "multi choice version of hasOne":: like hasOne, it is required here that: the "target model" belongs only to the "source model":
In the above scenario, there is a # creator in the File model_ ID marks the User you created. Here we get all the files created by the User.
User.HasMany(File, {
foreignKey: 'creator_id', // If this is not defined, it will also be automatically defined as "source model name + source model primary key name", that is, user_id
sourceKey: 'id', // The association key of the source model, the default primary key, is usually omitted
}
// Here is creator_ The ID is on the target model File
Deep differences between hasOne and hasOne
In fact: under findAll, SQL is the same as "one-to-one": (that is, ORM cannot limit the number of left joins. The so-called one-to-one is just "select one for all joins").
# User.HasMany(File)
SELECT `UserClass`.`id`, `file`.`id` AS `file.id`
FROM `user` `UserClass`
LEFT JOIN `file` ON `UserClass`.`id ` = `file`.`creator_id `:: findOne is different::: if you use hasOne, SQL only needs to give a global LIMIT 1, which means "I only want one source model and one target model in the JOIN"
# findOne: User.HasOne(File)
SELECT `UserClass`.`id`, `file`.`id` AS `file.id`
FROM `user` `UserClass`
LEFT JOIN `file` ON `UserClass`.`id ` = `file`.`creator_id `
LIMIT 1;However, if you mark hasMany and check with findOne, you are saying "one source model, but N target models associated with it". At this time, if the global gives LIMIT 1, the query results of the target model will be killed by mistake. Therefore, first "LIMIT" query itself to obtain "one source model", and then "LEFT JOIN" to obtain "its associated N target models"
# findOne: User.HasMany(File)
SELECT `UserClass`.`id`, `file`.`id` AS `file.id`
FROM (
SELECT `UserClass`.`id`,
FROM `user` `UserClass`
LIMIT 1
) `UserClass`
LEFT JOIN `file` ON `UserClass`.`id ` = `file`.`creator_id `3.5 many to many relationship
Sometimes, the target model and the source model are not unique to each other. A Group (folder) may have multiple users, and a User may also have multiple groups, which directly leads to: "adding foreignKey to any model is unreasonable":
We need the "intermediate model" as a matchmaker to maintain the relationship between the "target model" and the "source model". The intermediate model has two foreignkeys (one is replaced by another key), which are unique to both the target model and the source model.
User.BelongsToMany(Group, {
through: GroupUser, //
foreignKey: 'group_id', // If this is not defined, it will also be automatically defined as "target model name + target model primary key name", that is, user_id
otherKey: 'user_id',
}
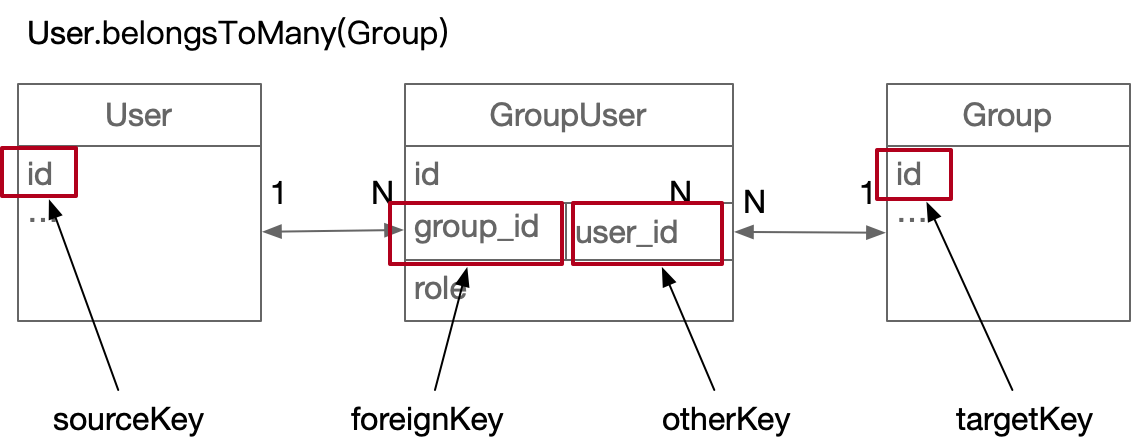
When findOne, the SQL is as follows: first join GroupUser # inner # Group, and then LEFT JOIN the result to User
# findOne(User): User.BelongsToMany(Group)
SELECT `UserClass`.`id`, `group`.`id` AS `group.id`
FROM (
SELECT `UserClass`.`id`,
FROM `user` `UserClass`
LIMIT 1
) `UserClass`
LEFT JOIN (`group_user` `group->GroupUser`
INNER JOIN `group` ON `group`.`id` = `group->GroupUser`.`group_id`)
ON `UserModel`.`id` = `group->GroupUser`.`user_id`;3.6 several joins
- left outer join (equivalent to left join, because the default is outer): take the behavior of the table on the left as the standard, merge and return the rows on the left; When there is no associated record on the right, the row is returned and the field added on the right is blank
- right join: Contrary to left, the right table shall prevail
- inner join: only when the left and right values are matched, can it be returned, which is equivalent to taking the intersection
- full join: return when any one of the two sides matches, which is equivalent to union set
In include, if required: true is configured, the SQL will change from LEFT JOIN to INNER JOIN, eliminating rows without associated records
4 optimization of database query
The things mentioned above are only "usable". In fact, the business query scenario is likely to be complex. If you write it at will, the DBA will call the door.
4.1 slow query, full table scan and index
In the field of database, people often mention "slow query", which refers to the query whose query time exceeds the specified time. The harm of slow query is that not only the request time of this query becomes longer, but also the system resources will be occupied for a long time, which will affect other queries or simply hang up the database.
The most common culprit of "slow query" is "full table scan", which means that the database engine searches the whole table one by one in order to find a record until it finds the record. Imagine if you have hundreds of millions of data and the data you want to check happens to be relatively backward. When will you find this? (the complexity is O(n)) so how not to "full table scan"?
For example, when you use the primary key to check a record, you will not scan the whole table.
File.findByPk(123);
Because MySQL adds "index" to the primary key column by default.
:: where is the index? MySQL establishes a btree:: (the implementation of different databases is different, but btree is the mainstream). In this way, "Station with id 318" only needs to be found along the root node, which means something like this:
3xx --> 31x --> 318
4.2 index other columns
So what if I check the normal column? You can also improve query efficiency through indexing.
File.findOne({
where: {
name: 'station1'
}
})
You can also manually add an index to this column:
create index index_name on file(name);
However, the implementation of this index is different from that of the primary key index. Instead of directly finding data records, it establishes btree on the primary key id. now the process of checking a "record with name station1" is similar to this:
start --> name: sta... --> name: statio --> name: station1 --> Get station1 of id: 816 --> id: 8xx --> id: 81x --> id: 816 --> Get the data of 816
If this path is too long, there is a further step. For frequently queried columns, such as File name and author, you can create an "overlay index":
create index index_name_and_address on file(name, author);
At this time, if I only check the author according to the name:
File.findOne({
where: {
name: 'station1'
},
attributes: ['author']
})
Because the address has been saved in the index, there is no need to access the source data:
start --> name: sta... --> name: statio --> name: station1 --> Get station1 of address: xxx
The more indexes, the better?
However, the index is not the more the better. Although the index improves the efficiency of query, it sacrifices the efficiency of insertion and deletion. Imagine that in the past, you only need to heap new data on the table, but now you have to modify the index. What's more troublesome is that the index is a balanced tree, and the whole tree needs to be adjusted in many scenarios. (why is the primary key self increasing by default? I guess it is also to reduce the cost of tree operation when inserting data)
Therefore, we generally consider adding an index to the column commonly used for "where" or "order".
4.3 query statement optimization
As mentioned earlier, adding indexes to common columns can improve query efficiency and make the query go through "btree" instead of "full table scan". But the premise is not to "select *" but to use attributes to extract only the columns you want:
where: {
attributes: ['id', 'name']
}
However, not all queries will follow "btree". Poor sql will still trigger full table scanning and generate slow queries, which should be avoided as far as possible.
When you where a column, MySQL only uses indexes for the following operators: <, < =, =, >, > =, BETWEEN, IN, and sometimes LIKE.Put it in sequenize:
Sequelize.Op.gt|gte|lt|lte|eq|between|in ...
For example, if you can use in, try not to use not in
// Not good
status: {
[Op.notIn]: [ 3, 4, 5, 6 ],
},
// good
status: {
[Op.in]: [ 1, 2 ],
},
The specific online search "avoid full table scanning" will not be carried out.
5 Summary
- MySQL operates through SQL, and ORM further abstracts the operation based on business programming language, and finally turns it into SQL. Sequenize is an ORM on node
- This paper introduces the model establishment and query syntax of sequenize
- There are three kinds of relations in the joint table. Through four kinds of marked associations, the concept, usage, principle and difference of these associations are discussed
- Index is of great significance to database optimization. At the same time, we should avoid not using index in sentences