MySQL-binlog2sql: non master-slave real-time synchronization + recovery of mistakenly deleted data
1. Introduction
1) Introduction
For DBA s or developers, data is sometimes deleted or updated by mistake. If it is an online environment and has a great impact, it needs to be rolled back quickly.
The traditional recovery method is to use the backup to rebuild the instance, and then apply the binlog after removing the wrong SQL to recover the data. This method is time-consuming and laborious, and even requires shutdown and maintenance. It is not suitable for fast rollback. Some teams also use LVM snapshots to shorten the recovery time, but the disadvantage of snapshots is that they will affect the performance of mysql. There are many open source flashback tools that are easy to use and efficient, such as binlog2sql and mysqlbinlog_flashback. These tools have alleviated a lot of pain for DBA s in their work. The following is a practical exercise on the use of binlog2sql.
2) Function
- Data fast rollback (flashback)
- Repair of data inconsistency after master-slave switching
- Generating standard SQL from binlog brings derivative functions (SQL can be executed directly ~)
3) For two scenarios
- Scenario 1: used to pull binlog and synchronize to other databases
- Whether adding, deleting, modifying or querying, all data should be synchronized to another database, and all data should be consistent
- Required database
- Source database, here is [mysql234]
- Target database, here is [mysql236]
- Automatically synchronize all binlog data to the target database
- Required database
- Whether adding, deleting, modifying or querying, all data should be synchronized to another database, and all data should be consistent
- Scenario 2: binlog2sql is mainly used for emergency recovery
- Data deleted for misoperation is used for emergency data recovery
- Required database
- Main database, here is [mysql234]
- Manually synchronize binlog deleted data
- Required database
- Data deleted for misoperation is used for emergency data recovery
- Difference between the two: - B option
- The biggest difference lies in the addition of this option, which is to reverse parse the processed pure sql statements, that is:
- insert resolves to delete
- delete resolves to insert
- update will not change
- The biggest difference lies in the addition of this option, which is to reverse parse the processed pure sql statements, that is:
2. Conditions precedent
Principle: for the delete operation, the delete information is retrieved from the binlog to generate the rollback statement of the insert. For the insert operation, the rollback SQL is delete. For the update operation, rollback SQL should exchange the values of SET and WHERE.
1) Install MySQL
See: MySQL installation deployment startup
2) Modify MySQL configuration
For source database
cat my.cnf [mysqld] server_id = 1 log_bin = /var/log/mysql/mysql-bin.log max_binlog_size = 1G binlog_format = row binlog_row_image = full((default)
3. Install binlog2sql
Download from the official website: Poke me~
Baidu cloud link: Poke me~ Extraction code: peng
It is recommended that the files packaged by Baidu cloud have been tested by me. Don't worry about the version. After downloading and uploading, you can directly execute the following decompression and installation commands
- List of dependent toolkits required for installation
- python-pip
- PyMySQL
- python-mysql-replication
- wheel argparse
1) Decompress
mkdir /opt/binlog2sql/packages && cd /opt/binlog2sql/packages # Upload package # Unzip to the upper layer unzip binlog2sql.zip -d /binlog cd /binlog tar xf pip-10.0.1.tar.gz tar xf PyMySQL-0.8.0.tar.gz tar xf wheel-0.31.0.tar.gz unzip binlog2sql-master.zip unzip python-mysql-replication-master.zip rm -f *.gz *.zip # View directory [root@web2 ~]# ll total 20K drwxr-xr-x 5 root root 4.0K Jan 4 2018 binlog2sql-master drwxrwxrwx 4 root root 4.0K Apr 20 2018 pip-10.0.1 drwxr-xr-x 4 501 games 4.0K Dec 20 2017 PyMySQL-0.8.0 drwxr-xr-x 7 root root 4.0K Mar 1 2018 python-mysql-replication-master drwxr-xr-x 4 2000 2000 4.0K Apr 2 2018 wheel-0.31.0
2) Installation
If an error is reported, install python3: yum install -y python3 and replace the python below with python3
# Installation dependent environment cd PyMySQL-0.8.0/ python setup.py install cd ../wheel-0.31.0/ python setup.py install cd ../python-mysql-replication-master/ python setup.py install # Detect dependent installation. already indicates that it has been installed cd ../pip-10.0.1/ pip freeze > requirements.txt pip install -r requirements.txt
3) Add alias
It is convenient to call with one click, and there is no need to execute the path of python+py separately~
You can directly use binlog2sql instead of Python / opt / binlog2sql / binlog2sql master / binlog2sql / binlog2sql.py
echo "alias binlog2sql='python /opt/binlog2sql/binlog2sql-master/binlog2sql/binlog2sql.py'" >> ~/.bashrc source ~/.bashrc
4. Prepare test data
1) Database and table building
CREATE DATABASE `peng` DEFAULT CHARACTER SET utf8mb4; USE peng; CREATE TABLE `binlog_test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4;
2) Insert data
Record the time of inserting data, accurate to seconds, which is [2021-11-19 15:20:06]
PS: several seconds in advance
INSERT INTO `peng`.`binlog_test` (`id`, `name`) VALUES (1, 'Insert data 1'); INSERT INTO `peng`.`binlog_test` (`id`, `name`) VALUES (1, 'Insert data 2'); INSERT INTO `peng`.`binlog_test` (`id`, `name`) VALUES (1, 'Insert data 3');
3) View data
mysql> SELECT * FROM `peng`.`binlog_test`; +----+---------------+ | id | name | +----+---------------+ | 1 | Insert data 1 | | 2 | Insert data 2 | | 3 | Insert data 3 | +----+---------------+ 3 rows in set (0.00 sec)
4) Simulated false deletion of data
Simulate the developer to delete data by mistake. At this time, the time is about [2021-11-19 15:32:14]
PS: if the time of deleting data by mistake is not clearly recorded, the recovery can be delayed for a few seconds or minutes. If there is a large amount of data, the smaller the time interval, the faster the troubleshooting!
-
Delete the selected two records
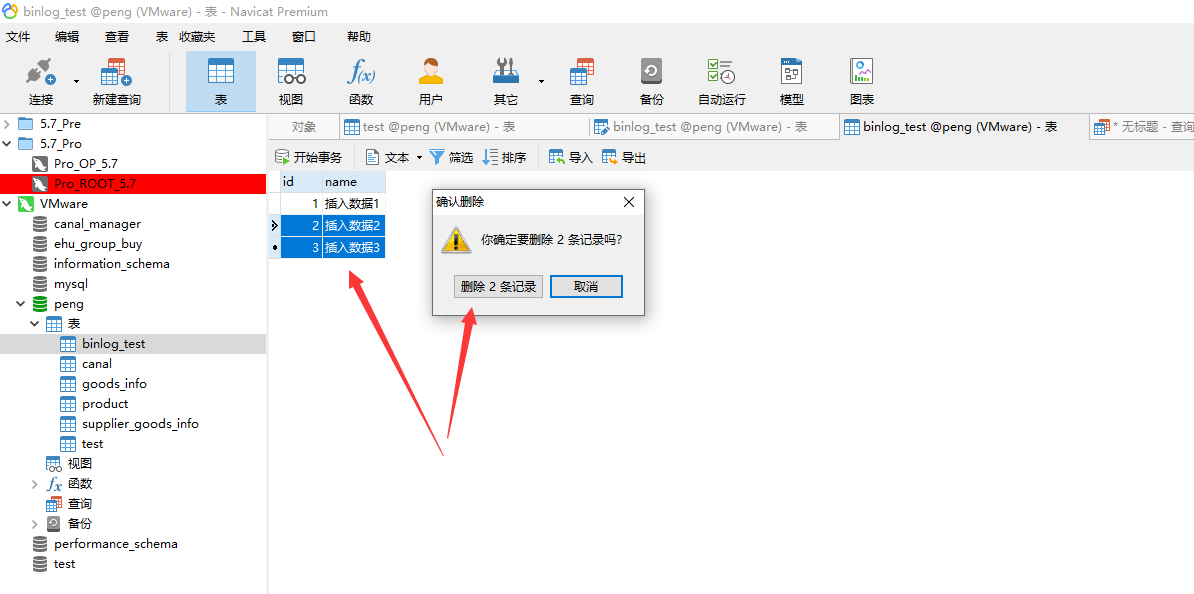
-
After deletion, it is found that there is only one piece of data left
[root@myslq ~]# mysql234 mysql> select * from peng.binlog_test; +----+---------------+ | id | name | +----+---------------+ | 1 | Insert data 1 | +----+---------------+ 1 row in set (0.00 sec)
5. Scenario 1 (real-time data synchronization)
For scene understanding, see: Scene introduction
After export, it will be automatically optimized into pure sql statements. There are no useless parts that can be directly executed in the database~
1) Case
1. Data export
Before exporting, ask about the time to delete data by mistake, accurate to seconds. Based on the above example, if you can't remember clearly, delay a few seconds later: [2021-11-19 15:33:00]
After export, it can be seen that the three inserted and two deleted records have records, followed by position and operation time records
1> Export command
binlog2sql -h 172.23.0.234 -P 3306 -u root -peHu2016 -d peng -t binlog_test --start-file='mysql-bin.000006' --start-datetime='2021-11-19 15:20:00' --stop-datetime='2021-11-19 15:23:00' > binlog1.sql
2> Export results
[root@web2 ~]# cat binlog1.sql INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (1, 'Insert data 1'); #start 4741 end 4925 time 2021-11-19 15:20:31 INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (2, 'Insert data 2'); #start 4956 end 5140 time 2021-11-19 15:20:38 INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (3, 'Insert data 3'); #start 5171 end 5355 time 2021-11-19 15:20:44 DELETE FROM `peng`.`binlog_test` WHERE `id`=2 AND `name`='Insert data 2' LIMIT 1; #start 5386 end 5570 time 2021-11-19 15:32:01 DELETE FROM `peng`.`binlog_test` WHERE `id`=3 AND `name`='Insert data 3' LIMIT 1; #start 5601 end 5785 time 2021-11-19 15:32:01
2. Data import
Check the corresponding position point, data information and time point. After confirmation, it can be imported to another database
Another database should have a corresponding structure, a library or table with the same name, or another database that has imported the full amount of data into this database (provided that the data inserted above is inserted after importing the full amount)
PS: if there is a large amount of data, you can import sql directly outside the database or use database tools to import
Import the above sql on the other machine and find that the data is the same as the source database. It is successful~
1> Import command
INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (1, 'Insert data 1'); #start 4741 end 4925 time 2021-11-19 15:20:31 INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (2, 'Insert data 2'); #start 4956 end 5140 time 2021-11-19 15:20:38 INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (3, 'Insert data 3'); #start 5171 end 5355 time 2021-11-19 15:20:44 DELETE FROM `peng`.`binlog_test` WHERE `id`=2 AND `name`='Insert data 2' LIMIT 1; #start 5386 end 5570 time 2021-11-19 15:32:01 DELETE FROM `peng`.`binlog_test` WHERE `id`=3 AND `name`='Insert data 3' LIMIT 1; #start 5601 end 5785 time 2021-11-19 15:32:01
2> Import results
[root@web2 binlog2sql]# mysql236 mysql> INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (1, 'Insert data 1'); #start 4741 end 4925 time 2021-11-19 15:20:31 Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (2, 'Insert data 2'); #start 4956 end 5140 time 2021-11-19 15:20:38 Query OK, 1 row affected (0.01 sec) mysql> INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (3, 'Insert data 3'); #start 5171 end 5355 time 2021-11-19 15:20:44 Query OK, 1 row affected (0.00 sec) mysql> DELETE FROM `peng`.`binlog_test` WHERE `id`=2 AND `name`='Insert data 2' LIMIT 1; #start 5386 end 5570 time 2021-11-19 15:32:01 Query OK, 1 row affected (0.00 sec) mysql> DELETE FROM `peng`.`binlog_test` WHERE `id`=3 AND `name`='Insert data 3' LIMIT 1; #start 5601 end 5785 time 2021-11-19 15:32:01 Query OK, 1 row affected (0.00 sec)
3> View data consistency
Check whether it is consistent with the source database data
-
Source database
mysql> select * from binlog_test; +----+---------------+ | id | name | +----+---------------+ | 1 | Insert data 1 | +----+---------------+ 1 row in set (0.00 sec)
-
Target database
mysql> select * from binlog_test; +----+---------------+ | id | name | +----+---------------+ | 1 | Insert data 1 | +----+---------------+ 1 row in set (0.00 sec)
2) Automatic synchronization
For automatic synchronization, the purpose is to enable the target database to pull the binlog of the source database in real time, and then synchronize it to the target database itself
1. Configure source database
Ensure that the binlog update interval of the source database depends on the set max_binlog_size and frequent data insertion rate
binlog maximum storage setting: 1G by default. It is recommended to modify it to 500M to facilitate fast pull processing
1> Configure max_binlog_size size
# View the current binlog storage maximum mysql> show variables like 'max_binlog_size'; +-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | max_binlog_size | 524288000 | +-----------------+-----------+ 1 row in set (0.00 sec) # Permanent modification (with units or directly write bytes) vim /etc/my.cnf max_binlog_size=500m #max_binlog_size=524288000 # Temporary modification (no units, only bytes) set global max_binlog_size=524288000;
2> Binlog update frequency calculation
The purpose is whether to change -- start file ='mysql-bin.000006 ', that is, binlog file name during export. If the amount of data is very frequent, it needs to be replaced
After testing, 500M binlog storage will not be filled quickly. As long as this file is not filled within 24 hours a day to generate a new binlog, we can save a lot of things
The following is the test calculation process, which is configured as: max_binlog_size=500m, because binlog is stored in the unit of event. If the last event is larger than 500m, it is normal. Generally, there are not too many events
1> > calculation process
# Get list
mysql> show binary logs;
+------------------+-----------+
| Log_name | File_size |
+------------------+-----------+
| mysql-bin.000010 | 525055100 |
| mysql-bin.000011 | 528614358 |
| mysql-bin.000012 | 550397479 |
| mysql-bin.000013 | 524430486 |
| mysql-bin.000014 | 527412076 |
| mysql-bin.000015 | 554424041 |
| mysql-bin.000016 | 524289004 |
| mysql-bin.000017 | 524288328 |
| mysql-bin.000018 | 529522538 |
| mysql-bin.000019 | 543769836 |
| mysql-bin.000020 | 524327234 |
| mysql-bin.000021 | 524288472 |
| mysql-bin.000022 | 604406562 |
| mysql-bin.000023 | 524313044 |
| mysql-bin.000024 | 524288456 |
| mysql-bin.000025 | 550211581 |
| mysql-bin.000026 | 524288363 |
| mysql-bin.000027 | 524608627 |
| mysql-bin.000028 | 541076047 |
| mysql-bin.000029 | 524663266 |
| mysql-bin.000030 | 524288106 |
| mysql-bin.000031 | 61796217
# Write a script to get binlog size
cat >> select_binlog.sh <<EOF
mysql -h 172.23.0.234 -u root -peHu2016 -e 'show binary logs;' | awk 'NR > 20 {print}' >> $file
echo "" >> $file
EOF
# It shall be executed every half an hour
*/30 * * * * /bin/sh /root/scripts/select_binlog.sh &>/dev/null
# view log
2021-11-22 15:30:01
mysql-bin.000029 524663266
mysql-bin.000030 524288106
mysql-bin.000031 49655438
2021-11-22 16:00:01
mysql-bin.000029 524663266
mysql-bin.000030 524288106
mysql-bin.000031 55292913
2021-11-22 16:30:01
mysql-bin.000029 524663266
mysql-bin.000030 524288106
mysql-bin.000031 66880555
2021-11-22 17:00:01
mysql-bin.000029 524663266
mysql-bin.000030 524288106
mysql-bin.000031 76985855
# calculation
30 What is the difference in minutes
55292913 - 49655438 = 5637475 ≈ 5m
66880555 - 55292913 = 11587642 ≈ 11m
76985855 - 66880555 = 10105300 ≈ 9m
# The same return is calculated as 10M, and the binlog size that can be generated within 24h is calculated
10 * 24 = 240m
2> Conclusion
The result is 240m, just half of the 500m we defined, so we can directly obtain the last binlog (i.e. the latest binlog) every day
It is suggested that the calculation should be carried out after the test day, which will be more accurate
-
As the company's business grows in the future, it needs to be calculated at intervals. If it exceeds 500m, a new binlog will be generated:
if judgment shall be defined at the beginning of the script to judge whether the binlog is within the expected range of the script. if a sudden increase in data generates a new binlog, an alarm will be given and the script will not be executed to prevent data inconsistency
-
The binlog pull command needs to be added in the get script: one pull command for one binlog (for multiple, use the for loop)
Changing Max is not recommended_ binlog_ Size, the data pull synchronization will gradually slow down with the file size
- The first to last entries do not specify the time, but only the logfile (pull the whole binlog);
- The last specification can also specify logfile and start_time,stop_time: less data, fast speed
- Do not specify start_time is pulled from the beginning of binlog by default and ends at stop_time
- Do not specify stop_time is the current time from start_time start
- PS: if none is specified, the entire binlog will be pulled
- PS: even if there are duplicate sql statements, it doesn't matter, because the judgment condition is that all fields of the table structure meet the requirements before changing the data. Under the condition of repeated execution, it can't all meet the requirements
-
The import script does not need to be changed. It has been processed during get and can be imported directly~
-
2. Precautions
During synchronization, the script is executed every 1 minute to pull the data between the current time and the previous 1 minute to keep the data synchronized every minute
PS: the minimum unit of Linux scheduled task is minutes
1> Repeated sql
The test results of repeated sql statements are as follows:
Conditions are all field conditions of a piece of data, and other data will not be deleted or modified by mistake
- insert: no impact. An error will be reported and this data will be updated repeatedly without delaying the subsequent sql execution;
- update: no impact. update this data repeatedly;
- Delete: no effect. Duplicate deletion will not report an error, but it will not delete other data by mistake;
2> Synchronization binlog interval
-
Synchronization script: executed every minute to ensure real-time data synchronization
-
Script condition synchronization interval: ensure that no updated data is missed and the amount of updated data is small
- start_time: 2021-11-22 12:04:33 (example: the first minute)
- stop_time: 2021-11-22 12:05:33 (example: current time)
3> Time acquisition format example
- Current time: date +% f '% H:% m:% s': 2021-11-22 13:45:00
- First five minutes: date - D '5 mins ago' "+% F% H:% m:% s": 2021-11-22 13:40:00
- First hour: 1 days ago
- First 1 minute: 1 hour ago
- 1 min ago
- First 1 second: 1 second
3. Nail alarm
Condition: when the binlog is not unique after filtering (multiple new binlogs are generated), call the alarm script, send the alarm information and terminate the script
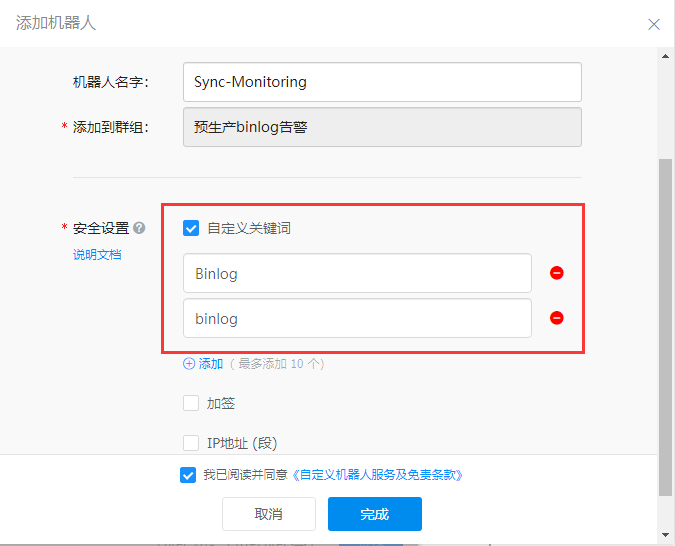
1> Create a nailing robot
1. Nailing - plus sign - initiate group chat - optional - enter group name - create
2. Enter the created group - Settings - group assistant only - add robot - plus sign - user defined robot - add - name - user defined Keyword - keywords contained in the alarm) - complete
3. Copy Webhook
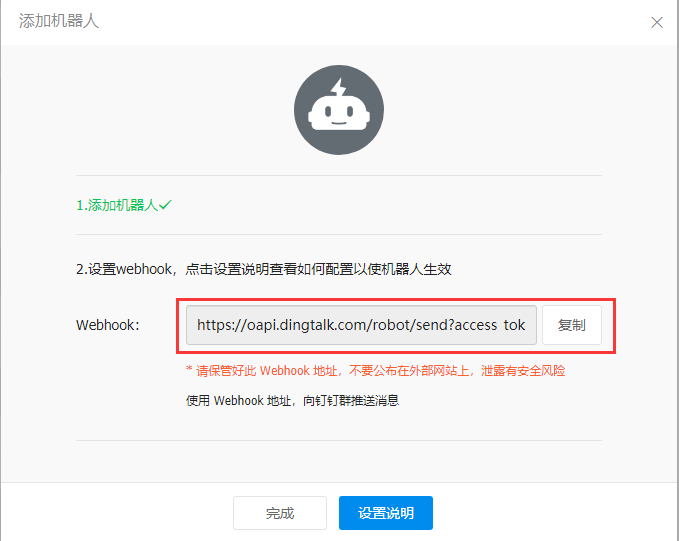
2> Nail alarm script
monitoring.sh needs to change three configurations:
Dingding_Url: fill in the Webhook copied when creating the nailing robot,
Subject: nailing alarm title, user defined
Body: nail alarm content, user defined
#!/bin/bash
function SendMessageToDingding(){
Dingding_Url="https://oapi.dingtalk.com/robot/send?access_token=138a41123s4dc6d39db75cdda5f0876q88f20c748dae6c"
# Send nail message
curl "${Dingding_Url}" -H 'Content-Type: application/json' -d "
{
\"actionCard\": {
\"title\": \"$1\",
\"text\": \"$2\",
\"hideAvatar\": \"0\",
\"btnOrientation\": \"0\",
\"btns\": [
{
\"title\": \"$1\",
\"actionURL\": \"\"
}
]
},
\"msgtype\": \"actionCard\"
}"
}
# When calling the script, you can manually enter the title and content (here, $1 and $2 are for testing)
Subject="$1" # Nail alarm title
Body="$2" # Nail alarm content
### PS:
# When calling the production environment, $1 and $2 need to manually define the alarm content;
# Put the whole script into the if judgment. If a certain condition is not met, execute the whole alarm code block
###
SendMessageToDingding $Subject $Body
3> Test script
At least one item of title or content must carry the customized keyword binlog (the keyword specified when creating the nailing robot), otherwise the sending fails!
PS: the title and content itself cannot have spaces, and can be separated by punctuation, such as:
[root@web2 ~]# sh monitoring.sh 'alarm Title binlog' 'I am the alarm content!'
{"errcode":0,"errmsg":"ok"}
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-ettze40r-163745371055) (C: \ users \ Peng \ appdata \ roaming \ typora \ user images \ image-20211122190421421. PNG)]
4. Synchronization script
Script structure directory:
[root@web2 binlog]# tree /binlog /binlog ├── 2021-11-23_19-09-08.sql └── scripts ├── monitoring.sh ├── sync.log └── sync.sh
Auto sync script: sync.sh
#!/bin/bash
################################## variable ##################################
# Database variables
HOST='172.23.0.234'
HOST236='172.23.0.236'
USER='root'
PORT='3306'
PWD='eHu2016'
DATABASE='peng'
TABLE='binlog_test'
# binlog2sql variable
START_FILE=`mysql -h $HOST -u $USER -p$PWD -e 'show binary logs;' | awk 'END {print}'| awk '{print $1}'`
START_TIME=`date -d '1 mins ago' "+%F %H:%M:%S"`
STOP_TIME=`date +%F' %H:%M:%S'`
SQL_NAME=/binlog/`date +%F'_%H-%M-%S'`.sql
# Nail alarm
SYNC_LOG=/binlog/scripts/sync.log
DINGDING='/binlog/scripts/monitoring.sh'
################################## export ##################################
function GET(){
/usr/bin/python /opt/binlog2sql/binlog2sql-master/binlog2sql/binlog2sql.py -h $HOST -P $PORT -u $USER -p$PWD -d $DATABASE "--start-datetime=$START_TIME" "--stop-datetime=$STOP_TIME" --start-file $START_FILE > $SQL_NAME
if [ $? -eq 0 ];then
# When the 'binlog' is not unique after filtering (multiple new 'binlogs' are generated), call the alarm script, send the alarm information and terminate the script
if [ `du -sh $SQL_NAME | awk '{print $1}'` == 0 ];then
rm -f `find /binlog -type f -a -size 0c` && exit
fi
# Category count export statement
TIME=`date +%F'|%H:%M:%S'`
INSERT_COUNT=`cat $SQL_NAME | grep INSERT | wc -l`
UPDATE_COUNT=`cat $SQL_NAME | grep UPDATE | wc -l`
DELETE_COUNT=`cat $SQL_NAME | grep DELETE | wc -l`
DATA_COUNT=`cat $SQL_NAME | wc -l`
## Task execution status -- > send nail alarm and write it to the log
cat >> $SYNC_LOG <<EOF
$STOP_TIME from $START_FILE Export data succeeded! Of which:
INSERT: $INSERT_COUNT strip
UPDATE: $UPDATE_COUNT strip
DELETE: $DELETE_COUNT strip
total: $DATA_COUNT strip
EOF
else
echo "$STOP_TIME from $START_FILE Failed to export data!" >> $SYNC_LOG
/usr/bin/sh $DINGDING "Binlog Pull failure alarm" "$TIME|FROM: $START_FILE[$SQL_NAME]"
fi
}
################################## Import ##################################
function IMPORT(){
/usr/bin/mysql -h $HOST236 -u $USER -p$PWD < $SQL_NAME
## Task execution status -- > send nail alarm and write it to the log
if [ $? -eq 0 ];then
cat >> $SYNC_LOG <<EOF
$STOP_TIME from $START_FILE Import data succeeded! Of which:
INSERT: $INSERT_COUNT strip
UPDATE: $UPDATE_COUNT strip
DELETE: $DELETE_COUNT strip
total: $DATA_COUNT
#######################################################
EOF
else
echo "$STOP_TIME from $START_FILE Import data succeeded!" >> $SYNC_LOG
echo "Document source: $SQL_NAME There are duplicate entries, which can be ignored~" >> $SYNC_LOG
echo "#######################################################" >> $SYNC_LOG
/usr/bin/sh $DINGDING "Binlog Import duplicate alarm" "$TIME|FROM: $START_FILE[$SQL_NAME]There are duplicate entries, which can be ignored~"
fi
}
# Function body call
GET
IMPORT
5. Start test
Synchronization steps: all synchronization steps should record the time, accurate to seconds!
Full synchronization
Differential synchronization
- prevent data differences (there will be duplicate data entries in this step, which has been tested and does not affect data consistency)
Automatic synchronization
- add scheduled tasks and execute them every minute
Check data consistency
Monitor the sync log in real time and check whether the data in the target database corresponds to the server
- data correspondence: check the sql file of get, filter a statement, and query the target database according to the conditions. If the data exists, the synchronization is successful!
Start presentation > > >
1> Full synchronization
Import the target database into the full backup of the source database
PS: full backup starts at 00:00:00 every day. For example, the time of this backup is 2021-11-22 00:00:00
mysql -uroot -peHu2016 < /backup/full.sql
2> Differential synchronization
Timestamp concept:
1. The scheduled task time of the source database is 2021-11-22 00:00:00, and the import full standby time is 2021-11-22 10:35:00, so the difference is 10h;
2. It is necessary to calculate the time difference between the full standby and the current time, which is greater than this time difference to prevent data omission, so the first synchronization of start datetime is specified as 12h (record the current time);
3. Based on the last recorded time, modify the start datetime again to the time when the synchronization was just performed, and then go back 1 minute (record the current time);
4. Observe the import interval of the record time. Up to now, the synchronization command should be able to complete the export and import within 10 minutes, and then proceed to the automatic synchronization step~
Duplicate data:
For duplicate data entries, I have tested them and can import them safely without affecting data consistency (INSERT, UPDATE, DELETE)
1> > source database export
Full standby time: 2021-11-22 00:00:00
Export time: 2021-11-21 22:00:00
Current time: 2021-11-22 10:33:23
PS: the export time is based on the full standby time. Push forward 2h to avoid data omission
/usr/bin/python /opt/binlog2sql/binlog2sql-master/binlog2sql/binlog2sql.py -h 172.23.0.234 -P 3306 -u root -peHu2016 -d peng "--start-datetime=2021-11-21 22:00:00" "--stop-datetime=2021-11-22 10:33:23" --start-file mysql-bin.000006 > `date +%F'_%H-%M-%S'`.sql
2> > import to target library
/usr/bin/mysql -h 172.23.0.236 -u root -peHu2016 < 2021-11-22_10-33-38.sql # Such errors are normal during the test, and the execution of insert or delete statements fails because the judgment condition is that all fields and a piece of data do not correspond, so the execution will not succeed and the subsequent sql execution will not be affected Warning: Using a password on the command line interface can be insecure. ERROR 1062 (23000) at line 1: Duplicate entry '2' for key 'PRIMARY'
3> Automatic synchronization
After differential synchronization, it is ensured that the export and import commands can be executed within 10 minutes:
Monitor the synchronization log tail / binlog / scripts / sync.log in real time, and perform the following operations:
1> > Add Scheduled Tasks
-
The modified timestamp is 10 mins
START_ The time variable is specified as: date - D '10 mins ago' +% F% H:% m:% s "
echo '*/1 * * * * /usr/bin/sh /binlog/sync.sh &>/dev/null' >> /var/spool/cron/root
-
Monitor the data 10 minutes before pulling
[root@web2 ~]# tailf /binlog/scripts/sync.log ####################################################### 2021-11-24 13:18:01 from mysql-bin.000006 Export data succeeded! Of which: INSERT: 31 strip UPDATE: 11 strip DELETE: 30 strip Total: 72 articles 2021-11-24 13:18:01 from mysql-bin.000006 Import data succeeded! Document source:/binlog/2021-11-24_13-18-01.sql There are duplicate entries, which can be ignored~
2> > modify the timestamp to 2 mins
Modify the timestamp after the monitoring log is successfully imported: start_ The time variable is specified as: date - D '2 mins ago' +% F% H:% m:% s "
PS: if the log shows that the import is completed within 1 minute, this can be directly modified to 1 min
-
Modify the timestamp to 2 mins
sed -i 's/10 mins/2 mins/g' sync.sh
-
Monitor the data 2 minutes before pulling
####################################################### 2021-11-24 13:20:01 from mysql-bin.000006 Export data succeeded! Of which: INSERT: 3 strip UPDATE: 2 strip DELETE: 2 strip Total: 7 articles 2021-11-24 13:20:01 from mysql-bin.000006 Import data succeeded! Document source:/binlog/2021-11-24_13-20-01.sql There are duplicate entries, which can be ignored~
3> > modify the timestamp to 1 mins
Modify the timestamp after the monitoring log is successfully imported: start_ The time variable is specified as: date - D '1 mins ago' +% F% H:% m:% s "
There will also be a log prompt of [duplicate entry], but there will be no duplicate log in the second run
-
Modify the timestamp to 1 mins
sed -i 's/2 mins/1 mins/g' sync.sh
-
Monitor the data 1 minute before pulling
####################################################### 2021-11-24 13:21:01 from mysql-bin.000006 Export data succeeded! Of which: INSERT: 2 strip UPDATE: 1 strip DELETE: 1 strip Total: 4 articles 2021-11-24 13:21:01 from mysql-bin.000006 Import data succeeded! Of which: INSERT: 2 strip UPDATE: 1 strip DELETE: 1 strip Total: 4 Document source:/binlog/2021-11-24_13-21-01.sql There are duplicate entries, which can be ignored~
-
Monitor the data 1 minute before pulling again
At this time, the displayed log is still the previous log, indicating that there is no duplicate sql or new data. If there is a new sql, a new data log will be output;
So far, all steps of automatic synchronization have been completed, and sync.log has been successfully imported. There should be no output unless there is repeated sql execution
####################################################### 2021-11-24 13:21:01 from mysql-bin.000006 Export data succeeded! Of which: INSERT: 2 strip UPDATE: 1 strip DELETE: 1 strip Total: 4 articles 2021-11-24 13:21:01 from mysql-bin.000006 Import data succeeded! Of which: INSERT: 2 strip UPDATE: 1 strip DELETE: 1 strip Total: 4 Document source:/binlog/2021-11-24_13-21-01.sql There are duplicate entries, which can be ignored~
2. Scenario 2 (data emergency recovery)
For scene understanding, see: Scene introduction
Idea: in a real scenario, the generated rollback sql often needs to be further filtered to see if there are dml statements of other tables and non delete statements of this table, combined with grep, editor, etc
PS1: use the - B option to generate rollback sql and check whether the rollback sql is correct (Note: insert will also be resolved into delete statement!!!)
When using the - B conversion, first export the sql without the - B option, and delete all statements except the delete statement. Otherwise, the insert will be resolved to delete, and you will be blabbering after execution
PS2: why only roll back the transform delete statement?
Insert and update are insert and update statements, which have not been deleted, so there is no need to rollback, and even if the rollback is carried out, one more statement will be inserted accordingly;
delete deletes the record, so you only need to restore the deleted record
1) Prepare data
1. Insert data
INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (1, 'Insert data 1'); INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (2, 'Insert data 2'); INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (3, 'Insert data 3');
2. View data
mysql> select * from binlog_test; +----+---------------+ | id | name | +----+---------------+ | 1 | Insert data 1 | | 2 | Insert data 2 | | 3 | Insert data 3 | +----+---------------+ 3 rows in set (0.00 sec)
3. Simulated deletion
Record deletion time: 2021-11-24 16:38:43
-
Delete data
DELETE FROM `peng`.`binlog_test` WHERE `id`=1; DELETE FROM `peng`.`binlog_test` WHERE `id`=2; DELETE FROM `peng`.`binlog_test` WHERE `id`=3;
-
View data, deleted
mysql> select * from binlog_test; Empty set (0.00 sec)
2) Data recovery
Add the - B option to de parse sql. This option is mainly used to recover deleted data
PS:
- insert resolves to delete
- delete resolves to insert
- update will not change
1. Data pull
--Start datetime: the time of deleting data. If you forget, it can be 1 minute or more in advance. Duplicate sql will not be executed and subsequent sql execution will not be affected
--Stop datetime: current time
-
Pull command
The deletion time is 2021-11-24 16:38:43, and the pull time is also specified as the timestamp. If the pull is wrong, the specified time will be advanced by a few seconds
binlog2sql -h 172.23.0.234 -P 3306 -u root -peHu2016 -d peng -t binlog_test --start-file='mysql-bin.000006' --start-datetime='2021-11-24 16:38:43' --stop-datetime='2021-11-24 16:45:45' -B > recover.sql [root@web2 ~]# !vim
-
Pull result
The sql statement whose data has been deleted has been obtained
At this time, the result has been de parsed, three inserts are parsed as delete, and two deletes are parsed as insert
[root@web2 ~]# cat recover.sql INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (3, 'Insert data 3'); #start 29232 end 29416 time 2021-11-24 16:38:43 INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (2, 'Insert data 2'); #start 29017 end 29201 time 2021-11-24 16:38:43 INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (1, 'Insert data 1'); #start 28802 end 28986 time 2021-11-24 16:38:43
2. Data import
be careful! When there is too much data, it is inevitable that there will be insert statements, and the insert statements will be de parsed into delete statements at the same time. We only need to recover the data, so we can eliminate the de parsed delete statements and only retain the de parsed insert statements
1> Import command
INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (3, 'Insert data 3'); #start 29232 end 29416 time 2021-11-24 16:38:43 INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (2, 'Insert data 2'); #start 29017 end 29201 time 2021-11-24 16:38:43 INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (1, 'Insert data 1'); #start 28802 end 28986 time 2021-11-24 16:38:43
2> Execution process
mysql> INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (3, 'Insert data 3'); #start 29232 end 29416 time 2021-11-24 16:38:43 Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (2, 'Insert data 2'); #start 29017 end 29201 time 2021-11-24 16:38:43 NTO `peng`.`binlog_test`(`id`, `name`) VALUES (1, 'Insert data 1'); #start 28802 end 28986 time 2021-11-24 16:38:43Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO `peng`.`binlog_test`(`id`, `name`) VALUES (1, 'Insert data 1'); #start 28802 end 28986 time 2021-11-24 16:38:43 Query OK, 1 row affected (0.00 sec)
3> Query whether the data is recovered
Query whether the deleted data has been recovered:
mysql> select * from binlog_test; +----+---------------+ | id | name | +----+---------------+ | 1 | Insert data 1 | | 2 | Insert data 2 | | 3 | Insert data 3 | +----+---------------+ 3 rows in set (0.00 sec)