The English book "C++ Concurrency in Action" has been translated by different people in China. There is a version translated by four translators. Douban knows about the wind review in general. Chen Xiaowei translated well. Here are my reading notes of the translator's books.
Hello, the concurrent world of C + +
1.1 what is concurrency
The simplest and most basic concurrency refers to the simultaneous occurrence of two or more independent activities.
Concurrency can be seen everywhere in life. We can talk while walking, or make different movements with both hands at the same time, and each of us lives an independent life - when I'm swimming, you can watch the ball game, and so on.
1.1.1 concurrency in computer system
Concurrency in the computer field refers to the simultaneous execution of multiple independent tasks in a single system, rather than some activities in sequence.
Through task scheduling, the system makes task switching under the granularity of time slice, so that users can not feel the gap. This is also called concurrency.
Multiprocessor computers can realize hardware concurrency.
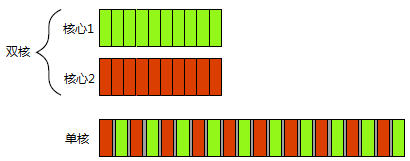
Figure 1.2 shows the task switching of four tasks on a dual core processor, which is still an ideal situation for neatly dividing tasks into blocks of the same size. In fact, many factors will lead to uneven segmentation and irregular scheduling.
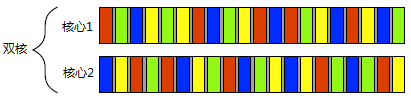
1.1.2 concurrent approaches
Approach 1: a process contains a thread, and interaction is inter process communication;
Approach 2: a process contains multiple threads, and interaction is the communication between threads.
Multi process concurrency
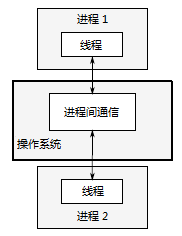
As shown in Figure 1.3, independent processes can transmit messages (signals, sockets, files, pipes, etc.) through regular communication channels between processes. However, this kind of communication between processes is usually either complex or slow, because the operating system will provide certain protection measures between processes to prevent one process from modifying the data of another process. Another disadvantage is the fixed overhead of running multiple processes: it takes time to start the process, the operating system needs internal resources to manage the process, and so on.
Of course, the above mechanisms are not useless: the operating system provides additional protection operations and higher-level communication mechanisms between processes, which means that it is easier to write safe concurrent code. In fact, in a programming environment similar to Erlang, processes are used as the basic building blocks of concurrency.
There is an additional advantage of using multiple processes to achieve concurrency - you can run independent processes on different machines by using remote connection (networking may be required). Although this increases communication costs, it may be a low-cost way to improve parallel available rows and performance on well-designed systems.
Multithreading concurrency
Another way of concurrency is to run multiple threads in a single process. Threads are much like lightweight processes: each thread runs independently of each other, and threads can run in different instruction sequences. However, all threads in the process share the address space, and all threads access most of the data - the global variable is still global, and the references or data of pointers and objects can be passed between threads. Although memory is usually shared between processes, this sharing is usually difficult to establish and manage. Because the memory address of the same data is different in different processes. Figure 1.4 shows two threads in a process communicating through shared memory.
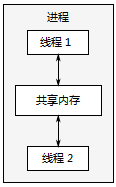
The sharing of address space and the lack of data protection between threads reduce the recording workload of the operating system, so the overhead associated with using multiple threads is far less than using multiple processes. However, the flexibility of shared memory comes at a price: if data is accessed by multiple threads, programmers must ensure that the data accessed by each thread is consistent (we will cover the problems that may be encountered in data sharing between threads and how to use tools to avoid these problems in chapters 3, 4, 5 and 8 of this book). The problem is not unanswered, as long as you pay proper attention when writing code, which also means that you need to do a lot of work on thread communication.
1.2 why use concurrency?
There are two main reasons: separation of concerns (SOC) and performance.
1.2.1 to separate concerns
When writing software, it's a good idea to separate concerns; By separating relevant code from irrelevant code, the program can be easier to understand and test, so as to reduce the possibility of error. Even if the operations in some functional areas need to occur at the same time, concurrency can still be used to separate different functional areas; If you don't explicitly use concurrency, you have to write a task switching framework, or actively call a piece of irrelevant code in the operation.
1.2.2 for performance
Multiprocessor systems are becoming more and more common. If you want to take advantage of the increasing computing power, you must design multitasking concurrent software.
There are two ways to use concurrency to improve performance. One is business logic parallelism, that is, task parallelism, and the other is data parallelism, such as image processing.
1.2.3 when not to use concurrency
Basically, the only reason not to use concurrency is that the benefits are not as good as the costs. Concurrent code increases the development cost, higher complexity and error risk. Don't use concurrency unless the potential performance gain is large enough or the separation of concerns is clear enough.
In addition, threads are limited resources. If too many threads run at the same time, it will consume a lot of operating system resources, making the operating system run more slowly as a whole. Moreover, because each thread needs a separate stack space, running too many threads will also exhaust the available memory or address space of the process. For a flat architecture process with 4GB(32bit) available address space, this is indeed a problem: if each thread has a 1MB stack (which is allocated by many systems), 4096 threads will use up all address space and leave no space for code, static data or heap data. Even if 64 bit (or larger) systems do not have this direct address space limitation, other resources are limited: if you run too many threads, you will eventually have problems. Although thread pools (see Chapter 9) can be used to limit the number of threads, this is not a panacea, it also has its own problems.
When the client / server (C/S) application starts an independent thread for each link on the server side, it can work normally for a small number of links, but when the same technology is used for high demand servers that need to handle a large number of links, it will also exhaust system resources because of too many threads. In this scenario, using thread pools can optimize performance (see Chapter 9).
1.3 concurrency and multithreading in C + +
It is new to provide standardized support for C + + concurrency through multithreading. Only under the C++11 standard can we write multithreaded code that does not depend on platform extension. Before understanding the many rules in C + + thread library, let's first understand its development history.
1.3.1 C + + multithreading history
C++98(1998) standard does not recognize the existence of threads, and the operation effects of various language elements are written in the form of sequential abstract machine. Moreover, the memory model is not formally defined, so it is impossible to write multithreaded applications without compiler related extensions under the C++98 Standard.
Of course, compiler vendors are free to add extensions to the language and add the popular multithreading APIs in C language - those in POSIX standard and Microsoft Windows API - which makes many C + + compiler vendors support multithreading through various platform related extensions. Therefore, when C + + itself does not support parallel syntax, programmers have written a large number of C + + multithreaded programs.
1.3.2 the new standard supports concurrency
The new C++11 standard not only has a new thread aware memory model, but also extends the C + + Standard Library: it includes various classes for managing threads (see Chapter 2), protecting shared data (see Chapter 3), synchronous operations between threads (see Chapter 4), and low-level atomic operations (see Chapter 5).
The new C + + thread library is largely based on the experience of the above-mentioned C + + class library. In particular, as the main model of the new class library, many classes have the same name and structure as the related classes in the Boost library. With the progress of the C + + standard, the Boost thread library has also made changes in many aspects with the C + + standard. Therefore, users who used Boost before will find that they are very familiar with the thread library of C++11.
The new C + + standard directly supports atomic operations and allows programmers to write efficient code by defining semantics, so that they do not need to understand the assembly instructions related to the platform.
1.3.3 efficiency of C + + thread library
For efficiency, C + + classes integrate some underlying tools. In this way, we need to understand the cost difference between using high-level tools and using low-level tools. This cost difference is the abstraction cost. This class library can achieve high efficiency (with very low abstraction cost) on most mainstream platforms.
1.3.4 platform related tools
Provide a native in the C + + thread library_ Handle () member function, which allows you to directly operate the underlying implementation by using platform related API s. In essence, any use of native_ The operations performed by handle () are completely platform dependent.
1.4 getting started
#include <iostream>
#include <thread> //①
void hello() //②
{
std::cout << "Hello Concurrent World\n";
}
int main()
{
std::thread t(hello); //③
t.join(); //④
}
2 thread management
2.1 basis of thread management
2.1.1 start thread
void do_some_work(); std::thread my_thread(do_some_work);
class background_task
{
public:
void operator()() const
{
do_something();
do_something_else();
}
};
background_task f;
std::thread my_thread(f);
One thing to note is that when you pass a function object into a thread constructor, you need to avoid“ The most troublesome grammar analysis"(C++'s most vexing parse, Chinese Introduction ). If you pass a temporary variable instead of a named variable; The C + + compiler resolves it to a function declaration rather than a definition of a type object.
For example:
std::thread my_thread(background_task());
This is equivalent to a declaration called my_thread function, which takes a parameter (the function pointer points to the function without parameters and returns the background_task object), and returns a function of std::thread object instead of starting a thread.
This problem can be avoided by using the method of naming function objects in the front, or using multiple sets of parentheses ①, or using the new unified initialization syntax ②.
As follows:
std::thread my_thread((background_task())); // 1
std::thread my_thread{background_task()}; // 2
Using lambda expressions can also avoid this problem. Lambda expression is a new feature of C++11, which allows the use of a local function that can capture local variables (to avoid passing parameters, see Section 2.2). For a specific understanding of lambda expressions, read section A.5 of Appendix A. The previous example can be rewritten to the type of lambda expression:
std::thread my_thread([]{
do_something();
do_something_else();
});
After starting the thread, you need to know whether to wait for the thread to end (plug-in - see section 2.1.2) or let it run autonomously (separate - see section 2.1.3). If a decision has not been made before the destruction of the std::thread object, the program will terminate (the destructor of std::thread will call std::terminate()). Therefore, even if there are exceptions, it is necessary to ensure that the thread can run correctly_ Join_ (joined) or_ Separation_ (detached).
Listing 2.1 the function has ended, and the thread still accesses local variables
struct func
{
int& i;
func(int& i_) : i(i_) {}
void operator() ()
{
for (unsigned j=0 ; j<1000000 ; ++j)
{
do_something(i); // 1. Potential access hazards: dangling references
}
}
};
void oops()
{
int some_local_state=0;
func my_func(some_local_state);
std::thread my_thread(my_func);
my_thread.detach(); // 2. Do not wait for the thread to end
} // 3. The new thread may still be running
In this example, it has been decided not to wait for the end of the thread (detach() ② is used), so when the oops() function is completed ③, the function in the new thread may still be running. If the thread is still running, it will call do_something(i) function ① will access the destroyed variables. Like a single threaded program - allows you to continue holding pointers or references to local variables after the function is completed; Of course, this is never a good idea - when this happens, the error is not obvious, which makes multithreading more error prone.
The conventional way to deal with this situation is to make the thread function fully functional and copy the data into the thread rather than into the shared data. If you use a callable object as a thread function, the object will be copied to the thread, and then the original object will be destroyed immediately. However, you need to be cautious about pointers and references contained in objects, as shown in listing 2.1. Using a function that can access local variables to create a thread is a bad idea (unless it is quite certain that the thread will end before the function is completed). In addition, you can use the join() function to ensure that the thread ends before the function completes.
2.1.2 wait for the thread to complete
If you need to wait for a thread, the related std::thread instance needs to use join(). In this case, because the original thread does nothing in its life cycle, it makes little profit to use an independent thread to execute the function, but in actual programming, the original thread either has its own work to do; Or it will start multiple sub threads to do some useful work and wait for these threads to end.
This means that you can only use join() once for a thread; Once you have used join(), the std::thread object cannot be added again. When you use joinable(), it will return false.
2.1.3 waiting under special circumstances
If you want to separate a thread, you can use detach() directly after the thread starts. If you intend to wait for the corresponding thread, usually when you want to use join() in the absence of exception, you need to call join() in the exception handling process, thereby avoiding the termination of the thrown exception.
Listing 2.2 waiting for the thread to complete
struct func; // This is defined in listing 2.1
void f()
{
int some_local_state=0;
func my_func(some_local_state);
std::thread t(my_func);
try
{
do_something_in_current_thread();
}
catch(...)
{
t.join(); // 1
throw;
}
t.join(); // 2
}
The code uses a try/catch block to ensure that the function ends only after the thread accessing the local state exits.
One way is to use "resource acquisition is initialization" (RAII), and provide a class to use join() in the destructor, as shown in the following listing. See how it simplifies the f() function.
Listing 2.3 using RAII to wait for the thread to complete
class thread_guard
{
std::thread& t;
public:
explicit thread_guard(std::thread& t_):
t(t_)
{}
~thread_guard()
{
if(t.joinable()) // 1
{
t.join(); // 2
}
}
thread_guard(thread_guard const&)=delete; // 3
thread_guard& operator=(thread_guard const&)=delete;
};
struct func; // This is defined in listing 2.1
void f()
{
int some_local_state=0;
func my_func(some_local_state);
std::thread t(my_func);
thread_guard g(t);
do_something_in_current_thread();
} // 4
2.1.4 background running thread
Using detach() will make the thread run in the background, which means that the main thread cannot interact directly with it. That is, it will not wait for the thread to end; If the thread is separated, it is impossible for an std::thread object to reference it. The separated thread does run in the background, so the separated thread cannot be added. However, the C + + runtime ensures that when the thread exits, the relevant resources can be recycled correctly, and the ownership and control of the background thread will be handled by the C + + runtime.
It is often called a detached thread_ Daemon thread_ (daemon threads), in UNIX, daemon threads refer to threads that do not have any explicit user interface and run in the background. The characteristic of this kind of thread is to run for a long time; The life cycle of a thread may start from the beginning to the end of an application. It may monitor the file system in the background, clean up the cache, or optimize the data structure.
std::thread t(do_background_work); t.detach(); assert(!t.joinable());
Listing 2.4 using a detach thread to process other documents
void edit_document(std::string const& filename)
{
open_document_and_display_gui(filename);
while(!done_editing())
{
user_command cmd=get_user_input();
if(cmd.type==open_new_document)
{
std::string const new_name=get_filename_from_user();
std::thread t(edit_document,new_name); // 1
t.detach(); // 2
}
else
{
process_user_input(cmd);
}
}
}
2.2 passing parameters to thread functions
Passing a parameter to a callable object or function in the std::thread constructor is simple. It should be noted that the default parameters should be copied to the thread independent memory. Even if the parameters are in the form of reference, they can be accessed in the new thread.
void f(int i, std::string const& s); std::thread t(f, 3, "hello");
The code creates a thread that calls f(3, "hello"). Note that function f requires an std::string object as the second parameter, but the literal value of the string is used here, that is, the type char const *. After that, the conversion of literal value to std::string object is completed in the context of thread. It should be noted that when the pointer to the dynamic variable is passed to the thread as a parameter, the code is as follows:
void f(int i,std::string const& s);
void oops(int some_param)
{
char buffer[1024]; // 1
sprintf(buffer, "%i",some_param);
std::thread t(f,3,buffer); // 2
t.detach();
}
In this case, buffer ② is a pointer variable, pointing to the local variable, and then the local variable is passed to the new thread ② through buffer. Moreover, the function is likely to crash (oops) before the literal value is converted to an std::string object, resulting in some undefined behavior. And you want to rely on implicit conversion to convert the literal value into the std::string object expected by the function, but because the constructor of std::thread will copy the supplied variable, only the string literal value that is not converted to the expected type is copied.
The solution is to convert the literal value to an std::string object before passing it to the std::thread constructor:
void f(int i,std::string const& s);
void not_oops(int some_param)
{
char buffer[1024];
sprintf(buffer,"%i",some_param);
std::thread t(f,3,std::string(buffer)); // Use std::string to avoid dangling pointers
t.detach();
}
You may also encounter the opposite situation: you expect to pass a reference, but the entire object is copied. This can happen when a thread updates a data structure passed by reference, such as:
void update_data_for_widget(widget_id w,widget_data& data); // 1
void oops_again(widget_id w)
{
widget_data data;
std::thread t(update_data_for_widget,w,data); // 2
display_status();
t.join();
process_widget_data(data); // 3
}
Although update_ data_ for_ The second parameter of widget ① is expected to pass in a reference, but the constructor ② of std::thread is unknown; The constructor ignores the expected parameter types of the function and blindly copies the provided variables. When the thread calls update_ data_ for_ When using the widget function, the parameter passed to the function is the reference of the internal copy of the data variable, not the reference of the data itself. Therefore, when the thread ends, the internal copy data will be destroyed in the data update phase, and the process_widget_data will receive the unmodified data variable ③. For developers familiar with std::bind, the solution to the problem is obvious: you can use std::ref to convert the parameters into the form of reference, so you can change the call of the thread to the following form:
std::thread t(update_data_for_widget,w,std::ref(data));
After that, update_ data_ for_ The widget will receive a reference to a data variable instead of a copy of the data variable.
If you are familiar with std::bind, you should not be surprised by the above parameter passing form, because the operations of std::thread constructor and std::bind are defined in the standard library. You can pass a member function pointer as the thread function and provide an appropriate object pointer as the first parameter:
class X
{
public:
void do_lengthy_work();
};
X my_x;
std::thread t(&X::do_lengthy_work,&my_x); // 1
In this code, the new thread will be my_x.do_lengthy_work() as thread function; my_ The address ① of X is provided to the function as a pointer object. You can also provide parameters for the member function: the third parameter of the std::thread constructor is the first parameter of the member function, and so on.
class X
{
public:
void do_lengthy_work(int);
};
X my_x;
int num(0);
std::thread t(&X::do_lengthy_work, &my_x, num);
Interestingly, the parameters provided can be moved, but not copied. "Move" means that the data in the original object is transferred to another object, and the transferred data is no longer saved in the original object. std::unique_ptr is such a type, which provides automatic memory management mechanism for dynamically allocated objects. Only one STD:: unique is allowed at the same time_ The PTR implementation points to a given object, and when the implementation is destroyed, the pointed object will also be deleted. The move constructor and move assignment operator allow an object to be in multiple STD:: unique_ Transfer in PTR implementation (for more information on "mobile", please refer to section A.1.1 of Appendix A). After using move to transfer the original object, a null pointer is left. A move operation can convert an object to an acceptable type, such as a function parameter or the type returned by a function. When the original object is a temporary variable, the move operation will be performed automatically. However, when the original object is a named variable, std::move() needs to be used to move the display during the transfer. The following code shows the usage of std::move and how std::move transfers a dynamic object to a thread:
void process_big_object(std::unique_ptr<big_object>); std::unique_ptr<big_object> p(new big_object); p->prepare_data(42); std::thread t(process_big_object,std::move(p));
Specify STD:: move (P), big in the constructor of std::thread_ The ownership of the object object is first transferred to the internal storage of the newly created thread, and then passed to the process_big_object function.
STD:: unique in standard thread library_ There are several classes with similar semantic types in the ownership of PTR, and std::thread is one of them. Although, the std::thread instance is not like std::unique_ptr can occupy the ownership of a dynamic object, but it can occupy other resources: each instance is responsible for managing an execution thread. The ownership of the execution thread can be transferred among multiple std::thread instances, which depends on the mobility and non replicability of the std::thread instance. Non replicability guarantees that an std::thread instance can only be associated with one execution thread at the same time point; Mobility allows programmers to decide which instance has ownership of the actual execution thread.
2.3 transfer thread ownership
Suppose you want to write a function that starts a thread in the background. You want to call this function through the ownership returned by the new thread, rather than waiting for the thread to end; Or the opposite idea: to create a thread and transfer ownership in the function, you must wait for the thread to end. In short, the ownership of new threads needs to be transferred.
This is why std::thread is introduced into mobile. There are many in the C + + standard library_ Resource possession_ (resource owning) type, such as std::ifstream,std::unique_ptr and std::thread are removable, but cannot be copied. This shows that the ownership of the execution thread can be moved in the std::thread instance. An example will be shown below. In the example, two execution threads are created and ownership is transferred between std::thread instances (t1,t2 and t3):
void some_function(); void some_other_function(); std::thread t1(some_function); // 1 std::thread t2=std::move(t1); // 2 t1=std::thread(some_other_function); // 3 std::thread t3; // 4 t3=std::move(t2); // 5 t1=std::move(t3); // 6 assignment operation will crash the program
First, the new thread begins to be associated with t1. When t2 is explicitly created with std::move(), ownership of t1 is transferred to t2. After that, t1 is no longer associated with the execution thread; Execute some_ The function of function is now associated with t2.
Then, the thread associated with a temporary std::thread object starts ③. Why not explicitly call std::move() to transfer ownership? Because the owner is a temporary object - the move operation will be called implicitly.
t3 uses the default construction method to create ④, which is not associated with any execution thread. Call std::move() to transfer the ownership of the thread associated with t2 to ⑤ in t3. Since t2 is a named object, you need to explicitly call std::move(). After the movement operation ⑤ is completed, t1 and some are executed_ other_ The thread of function is associated, t2 is not associated with any thread, and t3 is associated with some_function is associated with the thread of the function.
The last move operation will be some_ The ownership of the function thread is transferred ⑥ to t1. However, t1 already has an associated thread (the thread executing some_other_function), so here the system directly calls std::terminate() to terminate the program and continue to run.
std::thread supports movement, which means that the ownership of the thread can be transferred outside the function, just like the following program.
Listing 2.5 function returns std::thread object
std::thread f()
{
void some_function();
return std::thread(some_function);
}
std::thread g()
{
void some_other_function(int);
std::thread t(some_other_function,42);
return t;
}
When the ownership can be passed inside the function, the std::thread instance is allowed to be passed as a parameter. The code is as follows:
void f(std::thread t);
void g()
{
void some_function();
f(std::thread(some_function));
std::thread t(some_function);
f(std::move(t));
}
The container of std::thread object. If the container is move sensitive (for example, STD:: vector < >) in the standard, the move operation is also applicable to these containers. Once you know this, you can write code similar to that in listing 2.7, which mass produces some threads and waits for them to end.
Listing 2.7 mass production threads, waiting for them to finish
void do_work(unsigned id);
void f()
{
std::vector<std::thread> threads;
for(unsigned i=0; i < 20; ++i)
{
threads.push_back(std::thread(do_work,i)); // Generate thread
}
std::for_each(threads.begin(),threads.end(),
std::mem_fn(&std::thread::join)); // Call join() on each thread
}
2.4 determining the number of threads at runtime
std::thread::hardware_concurrency() is a very useful function in the new C + + standard library. This function will return the number of threads that can be concurrent in a program at the same time. For example, in a multi-core system, the return value can be the number of CPU cores. The return value is just a hint. When the system information cannot be obtained, the function will also return 0.
2.5 identifying threads
The thread ID type is std::thread::id, which can be retrieved in two ways. First, you can get by calling the member function of std::thread object_ ID () to get it directly. If the std::thread object is not associated with any execution thread, get_id() will return the default construction value of std::thread::type, which means "no thread". The second way is to call std:: this_ in the current thread. thread::get_id() (this function is defined in the < thread > header file) can also obtain the thread ID.
std::thread::id objects can be copied and compared freely, because identifiers can be reused. If the STD:: Thread:: IDs of two objects are equal, they are the same thread, or both are "thread free". If not, it represents two different threads, or one has a thread and the other has no thread.
The thread library will not restrict you to check whether the thread ID is the same. std::thread::id type objects provide quite rich comparison operations; For example, provide sorting for different values. This means that programmers are allowed to treat it as the key value of the container, sort it, or compare it in other ways. Compare std::thread::id of different values in the default order, so this behavior is predictable: when a < B, B < C, get a < C, and so on. The standard library also provides STD:: hash < std::thread::id > containers, so std::thread::id can also be used as the key value of unordered containers.
std::thread::id master_thread;
void some_core_part_of_algorithm()
{
if(std::this_thread::get_id()==master_thread)
{
do_master_thread_work();
}
do_common_work();
}
3 sharing data between threads
3.1 problems caused by shared data
When it comes to shared data, the problem is likely to be caused by the modification of shared data. If the shared data is read-only, the read-only operation will not affect the data, let alone involve the modification of the data, so all threads will obtain the same data. However, when one or more threads want to modify the shared data, there will be a lot of trouble. In this case, care must be taken to ensure that all threads work properly.
The concept of invariants will be helpful to the programs written by programmers - the description of special structures; For example, "variable contains the number of items in the list". Invariants are usually destroyed in one update, especially complex data structures, or large data structures need to be changed in one update.
Each node in the double linked list has a pointer to the next node in the list and a pointer to the previous node. Among them, the invariant is the pointer to the "next" node B in node A and the forward pointer. In order to delete a node from the list, the pointers of both nodes need to be updated. When one side is updated, the invariant is destroyed until the other side is also updated; After both sides are updated, the invariant is stable again.
The steps to delete a node from a list are as follows:
1. Find the node to delete N 2. Update previous node point N Let this pointer point to N Next node of 3. After updating, the next node points to N Let this pointer point to N Previous node of 4. Delete node N
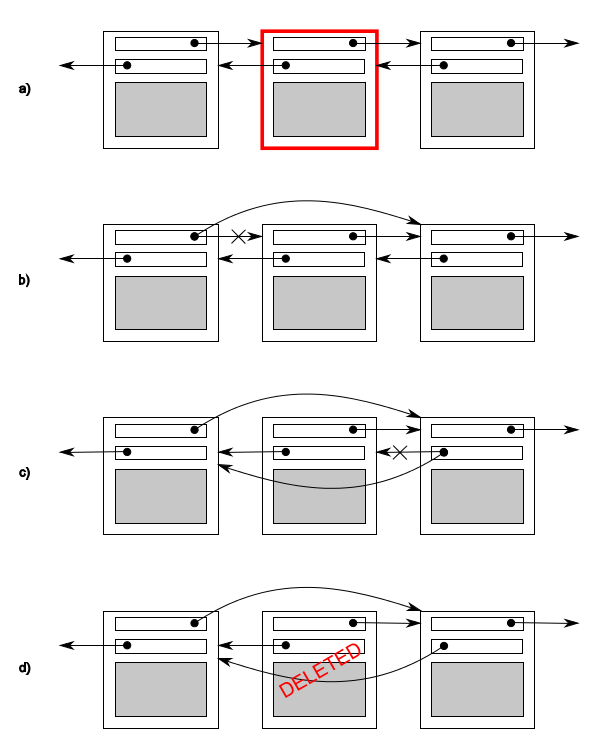
In the figure, b and c point in the same direction, which is inconsistent with the original, which destroys the invariant. The potential problem between threads is to modify the shared data, resulting in the destruction of invariants. This is a common error in parallel code: conditional contention.
3.1.1 conditional competition
The C + + standard also defines the term data competition, a special conditional competition: concurrent modification of an independent object. Data competition is the cause of (terrible) undefined behavior.
Vicious conditional competition usually occurs when modifications to more than one data block are completed, for example, modifications to two connection pointers. Because the operation needs to access two independent data blocks, independent instructions will modify the data block, and when one thread may be in progress, the other thread will access the data block. Because the probability of occurrence is too low, conditional competition is difficult to find and reproduce.
3.1.2 avoid vicious competition
Here are some methods to solve the vicious conditional competition. The simplest way is to adopt some protection mechanism for the data structure to ensure that only the modified thread can see the intermediate state when the invariant is destroyed. From the perspective of other access threads, the modification is either completed or not started. The C + + standard library provides many similar mechanisms.
Another option is to modify the design of data structure and invariants. The modified structure must be able to complete a series of indivisible changes, that is, to ensure that each invariant remains in a stable state, which is the so-called lock free programming. However, it is difficult to get the right result in this way. At this level, both the subtle differences in the memory model and the ability of threads to access data will complicate the work.
Another way to deal with conditional competition is to use the transaction method to deal with the update of data structure (here "processing" is the same as updating the database). Some of the required data and reads are stored in the transaction log, and then the previous operations are combined into one step before committing. When the data structure is modified by another thread or the processing has been restarted, the commit cannot be performed, which is called "software transaction memory". This is a very popular research field in theoretical research. This concept will not be introduced in this book, because there is no direct support for STM in C + +. However, the basic idea will be mentioned later.
The most basic way to protect shared data structures is to use the mutex provided by the C + + standard library.
3.2 using mutex to protect shared data
Mutex is the most common data protection mechanism in C + +, but it is not a "silver bullet"; It is important to carefully organize the code to protect the correct data and avoid competitive conditions within the interface. However, mutex itself has problems, which can also cause deadlock, or too much (or too little) data protection.
3.2.1 using mutex in C + +
In C + +, the mutex is created by instantiating std::mutex, locked and unlocked by calling the member function lock(). However, it is not recommended to call member functions directly in practice, because calling member functions means that you must remember to call unlock() at each function exit, including exceptions. The C + + standard library provides a template class STD:: lock of RAII syntax for mutex_ Guard, which provides locked mutex during construction and unlocks it during deconstruction, so as to ensure that a locked mutex will always be unlocked correctly. The following program list shows how to use STD:: Lock constructed by std::mutex in multithreaded programs_ Guard instance to protect the access of a list. std::mutex and STD:: lock_ Guards are declared in the < mutex > header file.
Listing 3.1 using mutexes to protect lists
#include <list>
#include <mutex>
#include <algorithm>
std::list<int> some_list; // 1
std::mutex some_mutex; // 2
void add_to_list(int new_value)
{
std::lock_guard<std::mutex> guard(some_mutex); // 3
some_list.push_back(new_value);
}
bool list_contains(int value_to_find)
{
std::lock_guard<std::mutex> guard(some_mutex); // 4
return std::find(some_list.begin(),some_list.end(),value_to_find) != some_list.end();
}
When all member functions lock the data when calling and unlock the data at the end, it ensures that the invariants are not destroyed during data access.
Of course, it's not always ideal. You must have noticed that when one of the member functions returns a pointer or reference to protect data, it will destroy the protection of data. Accessible pointers or references can access (and possibly modify) protected data without being restricted by mutexes. The data protected by mutex needs to be very careful in the design of the interface to ensure that the mutex can lock any access to the protected data without leaving a back door.
3.2.2 carefully organize code to protect shared data
Using mutex to protect data is not just adding an STD:: lock to every member function_ The guard object is so simple; A lost pointer or reference will make this protection useless.
Listing 3.2 inadvertently passes a reference to protected data
class some_data
{
int a;
std::string b;
public:
void do_something();
};
class data_wrapper
{
private:
some_data data;
std::mutex m;
public:
template<typename Function>
void process_data(Function func)
{
std::lock_guard<std::mutex> l(m);
func(data); // 1 pass "protect" data to user function
}
};
some_data* unprotected;
void malicious_function(some_data& protected_data)
{
unprotected=&protected_data;
}
data_wrapper x;
void foo()
{
x.process_data(malicious_function); // 2 pass a malicious function
unprotected->do_something(); // 3 access protected data without protection
}
Process in the example_ Data doesn't seem to have any problems. std::lock_guard protects the data well, but calling the function func ① provided by the user means that foo can bypass the protection mechanism and replace the function malicious_function is passed in ②, and do is called without locking the mutex_ something().
3.2.3 find the internal competition conditions of the interface
Listing 3.3 implementation of STD:: stack container
template<typename T,typename Container=std::deque<T> >
class stack
{
public:
explicit stack(const Container&);
explicit stack(Container&& = Container());
template <class Alloc> explicit stack(const Alloc&);
template <class Alloc> stack(const Container&, const Alloc&);
template <class Alloc> stack(Container&&, const Alloc&);
template <class Alloc> stack(stack&&, const Alloc&);
bool empty() const;
size_t size() const;
T& top();
T const& top() const;
void push(T const&);
void push(T&&);
void pop();
void swap(stack&&);
};
Although empty() and size() may be correct when called and returned, their results are unreliable; When they return, other threads can freely access the stack, and may push() multiple new elements into the stack, or pop() some elements already in the stack. In this case, the previous results from empty() and size() are problematic.
In particular, when the stack instance is not shared, if the stack is not empty, it is safe to use empty() to check and then call top() to access the elements at the top of the stack. The following code is shown:
stack<int> s;
if (! s.empty()){ // 1
int const value = s.top(); // 2
s.pop(); // 3
do_something(value);
}
The above is single thread safe code: using top() on an empty stack is undefined behavior. For shared stack objects, this call sequence is no longer safe, because between the call empty() ① and the call top() ②, there may be a pop() call from another thread and delete the last element. This is a classic conditional competition. Mutex is used to protect the internal data of the stack, but it still can not prevent the occurrence of conditional competition. This is the inherent problem of the interface.
How to solve it? The problem occurs in the interface design, so the solution is to change the interface design.
Table 3.1 a possible execution sequence
| Thread A | Thread B |
|---|---|
| if (!s.empty); | |
| if(!s.empty); | |
| int const value = s.top(); | |
| int const value = s.top(); | |
| s.pop(); | |
| do_something(value); | s.pop(); |
| do_something(value); |
When the thread runs, it calls top() twice. The stack has not been modified, so each thread can get the same value. The value has been processed twice. This kind of conditional competition, because there seems to be no error, will make this Bug difficult to locate.
This requires major changes in the interface design. One of the proposals is to use the same mutex to protect top() and pop().
Option 1: pass in a reference
The first option is to take the reference of the variable as a parameter and pass it into the pop() function to obtain the desired "pop-up value":
std::vector<int> result; some_stack.pop(result);
In most cases, this method is good, but it has obvious disadvantages: you need to construct an instance of the type in the stack to receive the target value. For some types, this is unrealistic, because temporarily constructing an instance is not cost-effective from the perspective of time and resources. For other types, this does not always work, because some parameters required by the constructor may not be available at this stage of the code. Finally, the need for assignable storage types is a major limitation: even if mobile constructs or even copy constructs are supported (thus allowing a value to be returned), many user-defined types may not support assignment operations.
Option 2: copy constructor or move constructor without exception throw
For pop() functions with return values, there are only concerns about "exception safety" (you can throw an exception when you return a value). Many types have copy constructors, which will not throw exceptions. With the support of "right value reference" in the new standard (see Appendix A, section A.1 for details), many types will have a mobile constructor, which will not throw exceptions even if they do the same thing as the copy constructor. A useful option is to limit the use of thread safe stacks and allow the stack to safely return the required values without throwing exceptions.
Option 3: return pointer to pop-up value
The third option is to return a pointer to the pop-up element rather than a direct return value. The advantage of pointers is free copy and no exceptions. The disadvantage is that returning a pointer needs to manage the memory allocation of the object. For simple data types (such as int), the overhead of memory management is much greater than the direct return value. For the interface of this scheme, use std::shared_ptr is a good choice; It can not only avoid memory leakage (because when the pointer in the object is destroyed, the object will also be destroyed), but also the standard library can fully control the memory allocation scheme, so there is no need for new and delete operations. This optimization is very important: each object in the stack needs to use new for independent memory allocation. Compared with the non thread safe version, this scheme is quite expensive.
Option 4: "option 1 + option 2" or "option 1 + option 3"
For common code, flexibility should not be ignored. When you have selected option 2 or 3, it is also easy to choose 1. These options are provided to users to choose the most suitable and economical scheme for themselves.
Example: define a thread safe stack
Listing 3.4 thread safe stack class definition (Overview)
#include <exception>
#include <memory> // For std::shared_ptr<>
struct empty_stack: std::exception
{
const char* what() const throw();
};
template<typename T>
class threadsafe_stack
{
public:
threadsafe_stack();
threadsafe_stack(const threadsafe_stack&);
threadsafe_stack& operator=(const threadsafe_stack&) = delete; // 1 assignment operation is deleted
void push(T new_value);
std::shared_ptr<T> pop();
void pop(T& value);
bool empty() const;
};
Cutting down the interface can achieve maximum security and even limit some operations on the stack. Using std::shared_ptr can avoid the problem of memory allocation management and avoid using new and delete operations multiple times.
Listing 3.5 extended (thread safe) stack
#include <exception>
#include <memory>
#include <mutex>
#include <stack>
struct empty_stack: std::exception
{
const char* what() const throw() {
return "empty stack!";
};
};
template<typename T>
class threadsafe_stack
{
private:
std::stack<T> data;
mutable std::mutex m;
public:
threadsafe_stack()
: data(std::stack<T>()){}
threadsafe_stack(const threadsafe_stack& other)
{
std::lock_guard<std::mutex> lock(other.m);
data = other.data; // 1 execution copy in constructor body
}
threadsafe_stack& operator=(const threadsafe_stack&) = delete;
void push(T new_value)
{
std::lock_guard<std::mutex> lock(m);
data.push(new_value);
}
std::shared_ptr<T> pop()
{
std::lock_guard<std::mutex> lock(m);
if(data.empty()) throw empty_stack(); // Before calling pop, check whether the stack is empty
std::shared_ptr<T> const res(std::make_shared<T>(data.top())); // Allocate the return value before modifying the stack
data.pop();
return res;
}
void pop(T& value)
{
std::lock_guard<std::mutex> lock(m);
if(data.empty()) throw empty_stack();
value=data.top();
data.pop();
}
bool empty() const
{
std::lock_guard<std::mutex> lock(m);
return data.empty();
}
};
In the previous discussion on the top() and pop() functions, vicious conditional competition has emerged because the granularity of locks is too small and the operations that need to be protected are not fully covered. However, too large locked particles can also be problematic. Another problem is that a global mutex protects all shared data. When there is a large amount of shared data in a system, threads can run forcibly and even access data in different locations, offsetting the performance improvement brought by concurrency. In the first version of Linux kernel designed for multiprocessor system, a global kernel lock was used. Although the lock works normally, the performance of the dual core processing system is much worse than that of the two single core systems, especially the four core system. Too many requests compete to occupy the kernel, making threads that depend on the processor unable to work well. Subsequently, the modified Linux kernel added a fine-grained locking scheme, because there was less kernel competition. At this time, the performance of the four core processing system is almost four times that of the single core processing.
Another potential problem arises when a given operation requires two or more mutexes: deadlocks. Contrary to conditional contention, two different threads wait for each other and do nothing.
3.2.4 Deadlock: problem description and solution
Imagine a toy, which consists of two parts. You must get these two parts before you can play. For example, a toy drum needs a drum hammer and a drum to play. Now there are two children who like playing with this toy very much. When one of the children gets the drum and the drum hammer, they can play as much as they want. When another child wants to play, he has to wait for the other child to finish. Imagine that the drum and the drum hammer are placed in different toy boxes, and both children want to play the drum at the same time. After that, they went to the toy box to find the drum. One of them found the drum and the other found the drum hammer. Now the problem is that unless one of the children decides to let the other play first, he can give his part to the other child; But when they all hold on to all their parts without giving, no one can play the drum.
Now there are no children competing for toys, but threads compete for locks: a pair of threads need to do some operations on all their mutexes, in which each thread has a mutex and waits for the other to unlock. In this way, no thread can work because they are waiting for each other to release the mutex. This situation is deadlock. Its biggest problem is that two or more mutexes lock an operation.
The general advice to avoid deadlock is to always lock two mutexes in the same order: always lock mutex A before mutex B, and there will never be deadlock.
std::lock -- it can lock multiple (more than two) mutexes at one time without side effects (deadlock risk). In the following program list, let's see how to use std::lock in a simple exchange operation.
Listing 3.6 using std::lock() and std::lock() in the swap operation_ guard
// std::lock() here needs to contain < mutex > header files
class some_big_object;
void swap(some_big_object& lhs,some_big_object& rhs);
class X
{
private:
some_big_object some_detail;
std::mutex m;
public:
X(some_big_object const& sd):some_detail(sd){}
friend void swap(X& lhs, X& rhs)
{
if(&lhs==&rhs)
return;
std::lock(lhs.m,rhs.m); // 1
std::lock_guard<std::mutex> lock_a(lhs.m,std::adopt_lock); // 2
std::lock_guard<std::mutex> lock_b(rhs.m,std::adopt_lock); // 3
swap(lhs.some_detail,rhs.some_detail);
}
};
Use std::lock to lock LHS M or RHS M, an exception may be thrown; In this case, the exception is propagated outside of std::lock. When std::lock successfully acquires a lock on a mutex, and when it attempts to acquire a lock from another mutex, an exception will be thrown, and the first lock will be automatically released with the exception. Therefore, std::lock either locks both locks or neither lock.
Although std::lock can avoid deadlock in this case (acquiring more than two locks), it can't help you acquire one of the locks.
3.2.5 advanced guidance for avoiding deadlock
Although lock is the general cause of deadlock, it does not rule out that deadlock occurs in other places. In the case of no lock, only each std::thread object needs to call join(), and two threads can produce deadlock. This is very common. One thread will wait for another thread, and other threads will also wait for the end of the first thread. Therefore, deadlock will also occur when three or more threads wait for each other. In order to avoid deadlock, the guidance here is: when the opportunity comes, don't give up. The following provides some personal guidance and suggestions on how to identify deadlocks and eliminate the waiting of other threads.
Avoid nested locks
The first suggestion is often the simplest: when a thread has acquired a lock, don't acquire the second one. If you can stick to this suggestion, because each thread holds only one lock, there will be no deadlock on the lock. Even the most common cause of deadlock caused by mutex may be plagued by deadlock in other aspects (such as mutual waiting between threads). When you need to acquire multiple locks, use an std::lock to do this (lock the operation of acquiring locks) to avoid deadlock.
Avoid calling user supplied code when holding a lock
: because the code is provided by the user, you have no way to determine what the user wants to do; User programs can do anything, including acquiring locks. When you hold the lock, call the code provided by the user; If user code wants to acquire a lock, it will violate the first guidance and cause deadlock (sometimes, this is unavoidable).
Acquire locks using a fixed sequence
When hard conditions require you to obtain more than two (including two) locks, and you cannot use std::lock to obtain them alone; Then it's best to get them (locks) in a fixed order on each thread.
In order to traverse the linked list, the thread must ensure to obtain the lock of the next node on the premise of obtaining the mutex lock of the current node, and ensure that the pointer to the next node will not be modified at the same time. Once the lock on the next node is acquired, the lock of the first node can be released because there is no need to hold it.
This "hand-in-hand" lock mode allows multiple threads to access the list and provides different nodes for each accessed thread. However, in order to avoid deadlock, nodes must be locked in the same order: if two threads try to traverse the list with "hand-in-hand" lock in reverse order, they will execute to the middle of the list, and A deadlock occurs. When nodes A and B are adjacent in the list, the current thread may try to acquire locks on A and B at the same time. Another thread may have acquired the lock on node B and tried to acquire the lock on node A - A classic deadlock scenario.
When node B in nodes A and C is being deleted, if A thread needs to obtain the lock on node B after obtaining the lock on nodes A and C, A deadlock may occur when A thread traverses the list. Such A thread may try to lock node A or node C first (according to the traversal direction), but later it will find that it cannot obtain the lock on B, because the thread has obtained the lock on B and also obtained the locks on A and C when executing the deletion task.
Here is A way to avoid deadlock and define the traversal order. Therefore, A thread must lock A before it can obtain the lock of B. after locking B, it can obtain the lock of C. This will eliminate the possibility of deadlock on the list that does not allow reverse traversal. Similar conventions are often used to build other data structures.
Use lock hierarchy
Listing 3.7 uses hierarchical locks to avoid deadlocks
hierarchical_mutex high_level_mutex(10000); // 1
hierarchical_mutex low_level_mutex(5000); // 2
int do_low_level_stuff();
int low_level_func()
{
std::lock_guard<hierarchical_mutex> lk(low_level_mutex); // 3
return do_low_level_stuff();
}
void high_level_stuff(int some_param);
void high_level_func()
{
std::lock_guard<hierarchical_mutex> lk(high_level_mutex); // 4
high_level_stuff(low_level_func()); // 5
}
void thread_a() // 6
{
high_level_func();
}
hierarchical_mutex other_mutex(100); // 7
void do_other_stuff();
void other_stuff()
{
high_level_func(); // 8
do_other_stuff();
}
void thread_b() // 9
{
std::lock_guard<hierarchical_mutex> lk(other_mutex); // 10
other_stuff();
}
The example also shows another point, STD:: lock_ Guard < > templates are used with user-defined mutex types. Although hierarchical_mutex is not part of the C + + standard, but it is easy to write; A simple implementation is shown in listing 3.8. Although it is a user-defined type, it can be used for STD:: lock_ In the guard < > template, because its implementation has three member functions to meet the mutually exclusive operations: lock(), unlock() and try_lock(). Although you haven't seen try yet_ How to use lock (), but it is very simple to use: when the lock on the mutex is held by a thread, it will return false instead of the thread waiting for the call until it can obtain the lock on the mutex. In the internal implementation of std::lock(), try_lock() will be used as part of the deadlock avoidance algorithm.
Table 3.8 simple implementation of hierarchical mutex
class hierarchical_mutex
{
std::mutex internal_mutex;
unsigned long const hierarchy_value;
unsigned long previous_hierarchy_value;
static thread_local unsigned long this_thread_hierarchy_value; // 1
void check_for_hierarchy_violation()
{
if(this_thread_hierarchy_value <= hierarchy_value) // 2
{
throw std::logic_error("mutex hierarchy violated");
}
}
void update_hierarchy_value()
{
previous_hierarchy_value=this_thread_hierarchy_value; // 3
this_thread_hierarchy_value=hierarchy_value;
}
public:
explicit hierarchical_mutex(unsigned long value):
hierarchy_value(value),
previous_hierarchy_value(0)
{}
void lock()
{
check_for_hierarchy_violation();
internal_mutex.lock(); // 4
update_hierarchy_value(); // 5
}
void unlock()
{
this_thread_hierarchy_value=previous_hierarchy_value; // 6
internal_mutex.unlock();
}
bool try_lock()
{
check_for_hierarchy_violation();
if(!internal_mutex.try_lock()) // 7
return false;
update_hierarchy_value();
return true;
}
};
thread_local unsigned long
hierarchical_mutex::this_thread_hierarchy_value(ULONG_MAX); // 8
Extension of override lock
When the code can avoid deadlock, std::lock() and std::lock_guard can form a simple lock to cover most cases, but sometimes it needs more flexibility. In these cases, you can use STD:: unique provided by the standard library_ Lock template. Such as std::lock_guard, which is a parameterized mutex template class, and provides many RAII type locks to manage std::lock_guard type, which can make the code more flexible.
3.2.6 std::unique_lock -- flexible lock
std::unqiue_lock uses freer invariants, such as std::unique_lock instances are not always related to the data types of mutexes. They are more useful than STD: lock_ The guard is more flexible. First, you can add std::adopt_lock is passed into the constructor as the second parameter to manage the mutex; You can also use std::defer_lock is passed in as the second parameter, indicating that the mutex should remain unlocked. In this way, it can be used by STD:: unique_ Obtained by lock() function of lock object (not mutex), or passed std::unique_lock object into std::lock(). Listing 3.6 can be easily converted to listing 3.9, using std::unique_lock and std::defer_lock ① instead of std::lock_guard and std::adopt_lock. The code length is the same and almost equivalent. The only difference is: std::unique_lock takes up more space than std::lock_guard is a little slower. There is a price to pay for flexibility, which is to allow std::unique_lock instance without mutex: the information has been stored and updated.
Listing 3.9 std::lock() and STD:: unique in the swap operation_ Use of lock
class some_big_object;
void swap(some_big_object& lhs,some_big_object& rhs);
class X
{
private:
some_big_object some_detail;
std::mutex m;
public:
X(some_big_object const& sd):some_detail(sd){}
friend void swap(X& lhs, X& rhs)
{
if(&lhs==&rhs)
return;
std::unique_lock<std::mutex> lock_a(lhs.m,std::defer_lock); // 1
std::unique_lock<std::mutex> lock_b(rhs.m,std::defer_lock); // 1 std::def_lock leaves an unlocked mutex
std::lock(lock_a,lock_b); // 2 mutex is locked here
swap(lhs.some_detail,rhs.some_detail);
}
};
In listing 3.9, because std::unique_lock supports lock(), try_lock() and unlock() member functions, so STD:: unique_ The lock object is passed to std::lock() ②. These member functions with the same name do the actual work at the lower level, and only update STD:: unique_ The flag in the lock instance to determine whether the instance has a specific mutex. This flag is to ensure that unlock () is called correctly in the destructor. If the instance has mutex, the destructor must call unlock(); However, when there is no mutex in the instance, the destructor cannot call unlock (). This flag can be used through owns_lock() member variable to query.
As you might expect, this sign is stored somewhere. Therefore, std::unique_lock objects are usually larger in volume than STD:: lock objects_ The guard object is large. When STD:: unique is used_ Lock replaces std::lock_guard, because the logo will be properly updated or checked, there will be some minor performance penalties. When std::lock_guard has been able to meet your needs, so I suggest you continue to use it. When you need more flexible locks, you'd better choose std::unique_lock, because it is more suitable for your task. You have seen an example of deferred lock. Another case is that the ownership of the lock needs to be transferred from one domain to another.
3.2.7 transfer of ownership of mutually exclusive quantities in different domains
std::unique_lock is a movable but non assignable type.
std::unique_lock<std::mutex> get_lock()
{
extern std::mutex some_mutex;
std::unique_lock<std::mutex> lk(some_mutex);
prepare_data();
return lk; // 1
}
void process_data()
{
std::unique_lock<std::mutex> lk(get_lock()); // 2
do_something();
}
std::unique_ The flexibility of lock also allows an instance to relinquish its locks before destroying them. You can use unlock() to do this, just like a mutex: std::unique_lock's member functions provide functions similar to locking and unlocking mutexes. std::unique_ The ability of a lock instance to release a lock before it is destroyed. When it is not necessary to hold a lock, it can be selectively released in a specific code branch. This is very important for application performance, because the increase of lock holding time will lead to performance degradation, and other threads will wait for the release of the lock to avoid exceeding the operation.
3.2.8 granularity of lock
Selecting granularity is very important for locks. In order to protect the corresponding data, it is also important to ensure that the lock has the ability to protect these data.
If many threads are waiting for the same resource, when a thread holds a lock for too long, it will increase the waiting time. When possible, lock the mutex and only access the shared data; An attempt was made to process out of lock data. In particular, do some time-consuming actions, such as locking the input / output operation of files. File input / output is usually hundreds or thousands of times slower than reading or writing data of the same length from memory. Therefore, unless the lock is intended to protect access to the file, or executing the input / output operation will delay the execution time of other threads, which is not necessary (because the file lock blocks many operations), so the performance benefits of multithreading will be offset.
This can indicate that when only one mutex protects the entire data structure, there may not only be more competition for locks, but also increase the lock holding time. More operation steps need to obtain the lock on the same mutex, so the lock holding time will be longer. The double blow on cost also provides double incentives and possibilities for the transfer to fine-grained locks.
Listing 3.10 lock mutexes one at a time in the comparison operator
class Y
{
private:
int some_detail;
mutable std::mutex m;
int get_detail() const
{
std::lock_guard<std::mutex> lock_a(m); // 1
return some_detail;
}
public:
Y(int sd):some_detail(sd){}
friend bool operator==(Y const& lhs, Y const& rhs)
{
if(&lhs==&rhs)
return true;
int const lhs_value=lhs.get_detail(); // 2
int const rhs_value=rhs.get_detail(); // 3
return lhs_value==rhs_value; // 4
}
};
3.3 alternative facilities for protecting shared data
Mutex is the most common mechanism, but it is not the only way to protect shared data. There are many alternatives that can provide more appropriate protection in specific situations.
A particularly extreme (but very common) situation is that shared data needs to be protected during concurrent access and initialization, but then needs to be implicitly synchronized. This may be because the data is created as read-only, so there is no synchronization problem; Or because the necessary protection is part of the operation on the data, it is performed implicitly. In any case, locking a mutex after data initialization is purely to protect its initialization process (which is unnecessary), and it will bring unnecessary impact to performance. For the above reasons, the C + + standard provides a mechanism to purely protect the initialization process of shared data.
3.3.1 initialization process of protecting shared data
Suppose you share a source with a, which is expensive to build. It may open a database connection or allocate a lot of memory.
Lazy initialization is very common in single threaded code - every operation needs to check the source first. In order to know whether the data is initialized, and then decide whether the data needs to be initialized before it is used:
std::shared_ptr<some_resource> resource_ptr;
void foo()
{
if(!resource_ptr)
{
resource_ptr.reset(new some_resource); // 1
}
resource_ptr->do_something();
}
Listing 3.11 delayed initialization (thread safety) procedure using a mutex
std::shared_ptr<some_resource> resource_ptr;
std::mutex resource_mutex;
void foo()
{
std::unique_lock<std::mutex> lk(resource_mutex); // All threads are serialized here
if(!resource_ptr)
{
resource_ptr.reset(new some_resource); // Only the initialization process needs protection
}
lk.unlock();
resource_ptr->do_something();
}
This code is quite common and enough to show unnecessary threading problems. Many people can think of better ways to do this, including the infamous double check lock mode:
void undefined_behaviour_with_double_checked_locking()
{
if(!resource_ptr) // 1
{
std::lock_guard<std::mutex> lk(resource_mutex);
if(!resource_ptr) // 2
{
resource_ptr.reset(new some_resource); // 3
}
}
resource_ptr->do_something(); // 4
}
The first time the pointer reads data, it does not need to acquire the lock ①, and it only needs to acquire the lock when the pointer is NULL. Then, after obtaining the lock, the pointer will be checked again ② (this is the part of double check), so as to prevent another thread from initializing after the first check, and let the current thread obtain the lock.
Why is this model infamous? Because there is potential condition competition here, the read operation ① not protected by lock is not synchronized with the write operation ③ protected by lock in other threads. Therefore, there will be conditional competition, which not only covers the pointer itself, but also affects the object it points to; Even if a thread knows that another thread has finished writing to the pointer, it may not see the newly created some_resource instance, then call do_ After something () ④, incorrect results are obtained. This example is in a typical conditional competition - data competition, which will be specified as "undefined behavior" in the C + + standard. This kind of competition can certainly be avoided. You can read Chapter 5, where there is more discussion on the memory model, including the composition of data competition.
The C + + Standard Committee also believes that the processing of conditional competition is very important, so the C + + standard library provides std::once_flag and std::call_once to deal with this situation. Instead of locking mutexes and explicitly checking pointers, each thread only needs to use std::call_once, in STD:: call_ At the end of once, you can safely know that the pointer has been initialized by other threads. Using std::call_once consumes less resources than explicitly using mutexes, especially when initialization is complete.
std::shared_ptr<some_resource> resource_ptr;
std::once_flag resource_flag; // 1
void init_resource()
{
resource_ptr.reset(new some_resource);
}
void foo()
{
std::call_once(resource_flag,init_resource); // It can be initialized completely once
resource_ptr->do_something();
}
Listing 3.12 using STD:: call_ Deferred initialization of once as a class member (thread safe)
class X
{
private:
connection_info connection_details;
connection_handle connection;
std::once_flag connection_init_flag;
void open_connection()
{
connection=connection_manager.open(connection_details);
}
public:
X(connection_info const& connection_details_):
connection_details(connection_details_)
{}
void send_data(data_packet const& data) // 1
{
std::call_once(connection_init_flag,&X::open_connection,this); // 2
connection.send_data(data);
}
data_packet receive_data() // 3
{
std::call_once(connection_init_flag,&X::open_connection,this); // 2
return connection.receive_data();
}
};
It is worth noting that std::mutex and std::one_flag instances cannot be copied and moved, so when you use them as class member functions, if you need them, you have to display and define these special member functions.
3.3.2 protect data structures that are rarely updated
Imagine that in order to resolve the domain name to its related IP address, we store a DNS entry table in the cache. Typically, a given number of DNS remains constant for a long time. Although new entries may be added to the table when users visit different websites, the data may remain unchanged throughout its life cycle. Therefore, it becomes very important to regularly check the effectiveness of entries in the cache; However, it also needs an update. Maybe this update only changes some details.
Using std::mutex to protect data structures is obviously overreacting. It is better to use boost:: shared than using std::mutex instances for synchronization_ Mutex to synchronize.
Listing 3.13 using boost::shared_mutex protects data structures
#include <map>
#include <string>
#include <mutex>
#include <boost/thread/shared_mutex.hpp>
class dns_entry;
class dns_cache
{
std::map<std::string,dns_entry> entries;
mutable boost::shared_mutex entry_mutex;
public:
dns_entry find_entry(std::string const& domain) const
{
boost::shared_lock<boost::shared_mutex> lk(entry_mutex); // 1
std::map<std::string,dns_entry>::const_iterator const it=
entries.find(domain);
return (it==entries.end())?dns_entry():it->second;
}
void update_or_add_entry(std::string const& domain,
dns_entry const& dns_details)
{
std::lock_guard<boost::shared_mutex> lk(entry_mutex); // 2
entries[domain]=dns_details;
}
};
3.3.3 nested locks
When a thread has acquired an std::mutex (locked) and locked it again, this operation is wrong, and if it continues to try to do so, it will produce undefined behavior. However, in some cases, it is possible for a thread to try to get the same mutex multiple times without releasing it once. This is possible because the C + + standard library provides std::recursive_mutex class. Before the mutex locks other threads, you must release all the locks you have, so when you call lock() three times, you must also call unlock() three times. Use STD:: Lock correctly_ guard<std::recursive_mutex > and STD:: unique_ lock<std::recursive_mutex > can help you deal with these problems.
4 synchronous concurrent operation
4.1 waiting for an event or other condition
In the evening, I waited on the train to arrive and leave the station in the early morning, either waiting without sleeping, or waiting to be awakened by the conductor.
The second option is to use STD:: this while waiting for the thread to check the gap_ thread::sleep_ For() for periodic intermission (see Section 4.3 for details):
bool flag;
std::mutex m;
void wait_for_flag()
{
std::unique_lock<std::mutex> lk(m);
while(!flag)
{
lk.unlock(); // 1 unlock mutex
std::this_thread::sleep_for(std::chrono::milliseconds(100)); // 2. Sleep for 100ms
lk.lock(); // 3 re lock mutex
}
}
Here, bloggers understand it as a poll.
4.1.1 waiting for conditions to be met
Listing 4.1 using std::condition_variable processing data waiting
std::mutex mut;
std::queue<data_chunk> data_queue; // 1
std::condition_variable data_cond;
void data_preparation_thread()
{
while(more_data_to_prepare())
{
data_chunk const data=prepare_data();
std::lock_guard<std::mutex> lk(mut);
data_queue.push(data); // 2
data_cond.notify_one(); // 3
}
}
void data_processing_thread()
{
while(true)
{
std::unique_lock<std::mutex> lk(mut); // 4
data_cond.wait(
lk,[]{return !data_queue.empty();}); // 5
data_chunk data=data_queue.front();
data_queue.pop();
lk.unlock(); // 6
process(data);
if(is_last_chunk(data))
break;
}
}
4.1.2 using conditional variables to build thread safe queues
Listing 4.2 std::queue interface
template <class T, class Container = std::deque<T> >
class queue {
public:
explicit queue(const Container&);
explicit queue(Container&& = Container());
template <class Alloc> explicit queue(const Alloc&);
template <class Alloc> queue(const Container&, const Alloc&);
template <class Alloc> queue(Container&&, const Alloc&);
template <class Alloc> queue(queue&&, const Alloc&);
void swap(queue& q);
bool empty() const;
size_type size() const;
T& front();
const T& front() const;
T& back();
const T& back() const;
void push(const T& x);
void push(T&& x);
void pop();
template <class... Args> void emplace(Args&&... args);
};
When you ignore construction, assignment and exchange operations, you have three groups of operations left: 1 Query the status of the whole queue (empty() and size());2. Query each element in the queue (front() and back()); 3. Modify the queue (push(), pop() and empty()). This is the same as the stack in 3.2.3, so you will also encounter conditional competition on the inherent interface. Therefore, you need to merge front() and pop () into one function call, just like merging top() and pop () in stack implementation. The difference from the code in listing 4.1 is that when using a queue to transfer data among multiple threads, the receiving thread usually needs to wait for the data to be pushed in. Here we provide two variants of the pop () function: try_pop() and wait_and_pop(). try_pop(), which attempts to pop data from the queue, will always return directly (in case of failure), even if there is no value to retrieve; wait_and_pop() will wait until there is a value to retrieve before returning. When you use the previous stack to implement your queue, the queue interface you implement may be as follows:
Listing 4.3 interface of thread safe queue
#Include < memory > / / to use std::shared_ptr
template<typename T>
class threadsafe_queue
{
public:
threadsafe_queue();
threadsafe_queue(const threadsafe_queue&);
threadsafe_queue& operator=(
const threadsafe_queue&) = delete; // Simple assignment is not allowed
void push(T new_value);
bool try_pop(T& value); // 1
std::shared_ptr<T> try_pop(); // 2
void wait_and_pop(T& value);
std::shared_ptr<T> wait_and_pop();
bool empty() const;
};
Listing 4.4 extracts push() and wait from listing 4.1_ and_ pop()
#include <queue>
#include <mutex>
#include <condition_variable>
template<typename T>
class threadsafe_queue
{
private:
std::mutex mut;
std::queue<T> data_queue;
std::condition_variable data_cond;
public:
void push(T new_value)
{
std::lock_guard<std::mutex> lk(mut);
data_queue.push(new_value);
data_cond.notify_one();
}
void wait_and_pop(T& value)
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk,[this]{return !data_queue.empty();});
value=data_queue.front();
data_queue.pop();
}
};
threadsafe_queue<data_chunk> data_queue; // 1
void data_preparation_thread()
{
while(more_data_to_prepare())
{
data_chunk const data=prepare_data();
data_queue.push(data); // 2
}
}
void data_processing_thread()
{
while(true)
{
data_chunk data;
data_queue.wait_and_pop(data); // 3
process(data);
if(is_last_chunk(data))
break;
}
}
Listing 4.5 thread safe queues using conditional variables (full version)
#include <queue>
#include <memory>
#include <mutex>
#include <condition_variable>
template<typename T>
class threadsafe_queue
{
private:
mutable std::mutex mut; // 1 mutex must be variable
std::queue<T> data_queue;
std::condition_variable data_cond;
public:
threadsafe_queue()
{}
threadsafe_queue(threadsafe_queue const& other)
{
std::lock_guard<std::mutex> lk(other.mut);
data_queue=other.data_queue;
}
void push(T new_value)
{
std::lock_guard<std::mutex> lk(mut);
data_queue.push(new_value);
data_cond.notify_one();
}
void wait_and_pop(T& value)
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk,[this]{return !data_queue.empty();});
value=data_queue.front();
data_queue.pop();
}
std::shared_ptr<T> wait_and_pop()
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk,[this]{return !data_queue.empty();});
std::shared_ptr<T> res(std::make_shared<T>(data_queue.front()));
data_queue.pop();
return res;
}
bool try_pop(T& value)
{
std::lock_guard<std::mutex> lk(mut);
if(data_queue.empty())
return false;
value=data_queue.front();
data_queue.pop();
return true;
}
std::shared_ptr<T> try_pop()
{
std::lock_guard<std::mutex> lk(mut);
if(data_queue.empty())
return std::shared_ptr<T>();
std::shared_ptr<T> res(std::make_shared<T>(data_queue.front()));
data_queue.pop();
return res;
}
bool empty() const
{
std::lock_guard<std::mutex> lk(mut);
return data_queue.empty();
}
};
4.2 use expectation waiting for one-time event
5 C + + memory model and atomic type operation
6 design of concurrent data structure based on lock
7 design of lockless concurrent data structure
8 concurrent code design
9 advanced thread management
10 testing and debugging of multithreaded programs
a key
Thread std::thread object must call join or detach
- thread destructor
- C++11 multithreading - Part 2: connecting and separating threads
- Starting thread causing abort()
Destroys the thread object. If *this has an associated thread (joinable() == true), std::terminate() is called.
The created std::thread object is destroyed at the end of the constructor because it is a local variable. If the destructor of std::thread is called and the thread is joinable, std::terminate is called. That is, the program will call Abort() without any cleanup, and then abnormal program termination.
shared_mutex is also based on the pthread of the read-write lock at the bottom of the operating system_ rwlock_ T packaging
reference resources
1. C++ Concurrency in Action [translated by Chen Xiaowei]
2,github translation address
3,gitbook online reading
4,Source code in the book
5,Learning C++11/14
6,CPP-Concurrency-In-Action-2ed
7,thread destructor
8,C++11 multithreading - Part 2: connecting and separating threads
9,Starting thread causing abort()
10,Detailed explanation of Boost Mutex