Feeling after class
The course is getting more and more difficult. It's a little difficult to keep up. However, thanks to the leaders in the group and various documents of the propeller platform, many difficulties were solved
Job completion record
Make dataset
The data set I made before was too small and the training effect was very poor, so I made a new data set. Recently, I was watching the Dragon maid of the Kobayashi family and wanted to make a relevant data set, so I cut 100 pictures to complete the data set.
For the production of data set, please refer to my second note
Training model
Reference case
At first, I didn't know how to start, so I searched the tutorial on the propeller platform, and I found this:
Smoking recognition and prediction using custom data sets
Code interpretation
The code in the above reference case will be explained in detail below
unzip
!unzip -oq data/data94796/pp_smoke.zip -d work/
unzip is a decompression command. The following "- oq" and "- d" are the parameters of the command. For example, - d means to extract to a certain place. In the above code, followed by work / is to extract to the work folder. For other parameters, please refer to here:
Parameter interpretation
git
! git clone https://gitee.com/paddlepaddle/PaddleDetection.git
git is a command to download things from the Internet.
If the network speed is slow, you can directly download the paddedetection to your computer and upload it to the project when you need it.
Installation code:
!unzip -oq /home/aistudio/PaddleDetection-release-2.1.zip !pip install -r /home/aistudio/PaddleDetection-release-2.1/requirements.txt
There are many tools in paddedetection, which is very convenient
Interpretation of data set division
import random
import os
#Generate train Txt and val.txt
#train.txt and val.txt are the division of data sets. See the following ratio=0.9, which means that it is divided into training set and verification set according to 9:1
random.seed(2020)
xml_dir = '/home/aistudio/work/Annotations'#Label file address
#The xml suffix file is a label file. Open the Annotations folder and you can see that the file inside is an xml suffix
img_dir = '/home/aistudio/work/images'#Image file address
#The file address is for storing pictures, which corresponds to the above file
path_list = list()
for img in os.listdir(img_dir):
#os.listdir will return the files in the specified path
img_path = os.path.join(img_dir,img)
#os.path.join is to put two or more together
xml_path = os.path.join(xml_dir,img.replace('jpg', 'xml'))
path_list.append((img_path, xml_path))#Map labels to pictures
#Maybe some students still don't know what it means. For example, it may be easier to understand
#Known img_dir='/home/aistudio/work/images' path is full of pictures
#Suppose these pictures are jpg with names of 1 ~ 20
#So OS Listdir (img_dir) returns 1 jpg,2.jpg……20.jpg
#for img in os.listdir(img_dir) is each jpg above
#img_path = os.path.join(img_dir,img) is spliced as follows:
#/home/aistudio/work/images/1.jpg
#/home/aistudio/work/images/2.jpg
#......
#xml_path gets / home / aistudio / work / images / 2 xml
#The only difference between the two is to replace the last jpg with xml
#path_list is to put img on it_ Path and XML_ Connect the path
random.shuffle(path_list)#Shuffle means shuffle, which means to disrupt the data set
ratio = 0.9
train_f = open('/home/aistudio/work/train.txt','w') #Generate training files
#Open means open, and the following 'w' is the write command, that is, write
val_f = open('/home/aistudio/work/val.txt' ,'w')#Generate validation file
for i ,content in enumerate(path_list):
#enumerate(path_list) is an enumeration
#i. Content is the index and value respectively
#It can be understood as follows: path_list is an array in C language
#i is the sequence number of the array, which means the ith; Content is the content of the ith
img, xml = content
text = img + ' ' + xml + '\n'
if i < len(path_list) * ratio:
train_f.write(text)#write in
else:
val_f.write(text)
train_f.close()
val_f.close()
#Generate label document
label = ['smoke']#Set the category you want to detect
with open('/home/aistudio/work/label_list.txt', 'w') as f:
for text in label:
f.write(text+'\n')
File selection
In the case, paddedetection-release-2.1/configs/ppyolo/ppyolov2 is used_ r50vd_ dcn_ voc. YML, you can also choose other
Open paddedetection-release-2.1/configurations/ppyolo/ppyolov2_ r50vd_ dcn_ voc. YML path, you will see:
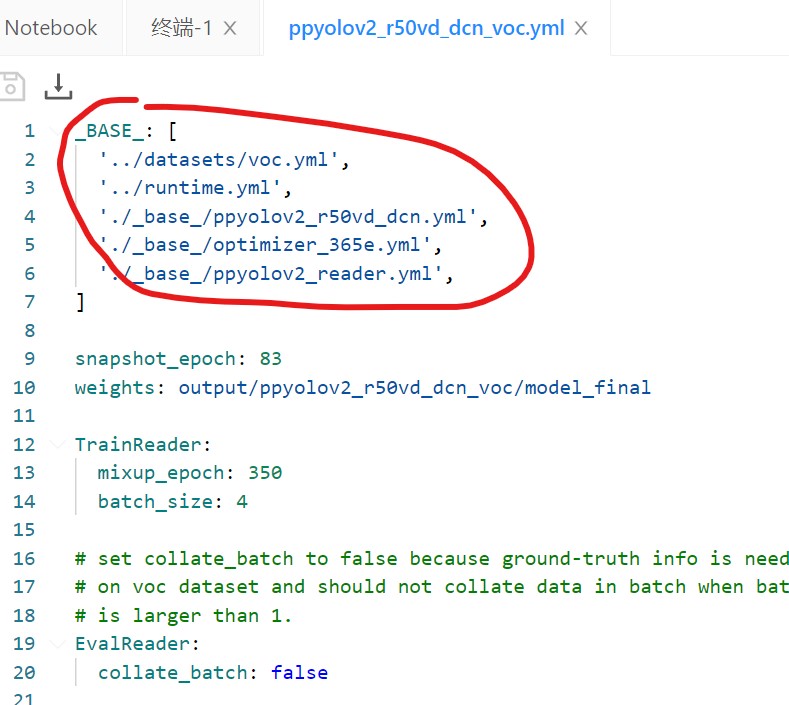
The red circle in the figure above should be noted. Modify the first VOC The YML file is ready to use, but other parameters can be modified for better use
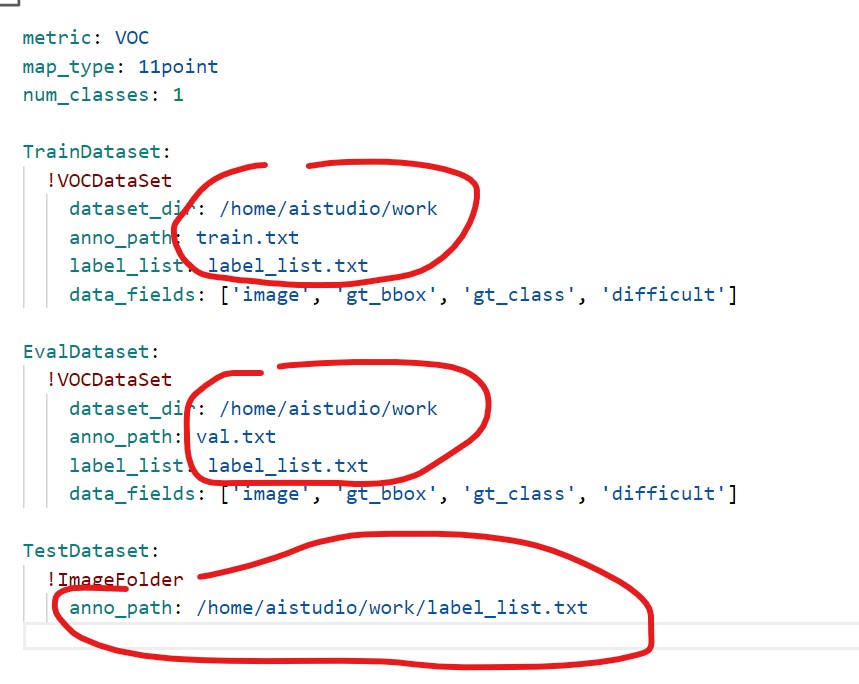
The above paths are train Txt, val.txt and label_list.txt file path
After modifying the parameters, you can train. There should be basically no problem
Problem solving
- Wrong ValueError:The device should not be "gpu", since PaddlePaddle is not compiled compiled, replace to advanced or Extreme Edition.
- If the decompressed dataset is running all the time, there may be problems with some pictures. Delete them