Regular season: Chinese News Text Title Classification Baseline(PaddleNLP)
1, Scheme introduction
1.1 introduction to the competition:
Text classification is to automatically classify and mark the text set (or other entities or objects) according to a certain classification system or standard with the help of computer. This competition is for news title text classification. Players need to train a news classification model according to the news title text and category label provided, and then classify the news title text of the test set. Accuracy = correct number of classification / total number of required classification is used in the evaluation index. At the same time, the contestants need to use the propeller frame and the propeller text field core development library PaddleNLP. PaddleNLP has a concise and easy-to-use full process API in the text field, multi scene application examples, very rich pre training models, and is deeply suitable for the version 2.x of the propeller frame.
Game portal: Regular season: Chinese News Text Title Classification
1.2 data introduction:
THUCNews is generated based on the historical data of Sina News RSS subscription channel from 2005 to 2011. It contains 740000 news documents (2.19 GB), all in UTF-8 plain text format. Based on the original Sina News classification system, the competition data set is re integrated and divided into 14 candidate classification categories: finance, lottery, real estate, stock, home, education, science and technology, society, fashion, current politics, sports, constellation, games and entertainment. A total of 832471 training data were provided.
Format of data set provided by the competition: training set and verification set format: original title + \ t + label, test set format: original title.
1.3 Baseline idea:
The title of the competition is a more conventional short text multi classification task. This project is mainly based on paddelnlp. Through the pre training model Robert, fine tune the training data provided to complete the training and optimization of the news 14 classification model. Finally, the trained model is used to predict the test data and generate the Submission result file.
Note that the operation of this project needs to select the premium version of GPU environment! If the video memory is insufficient, please reduce the batchsize appropriately!
BERT pre knowledge supplement: [principle] classic pre training model - BERT
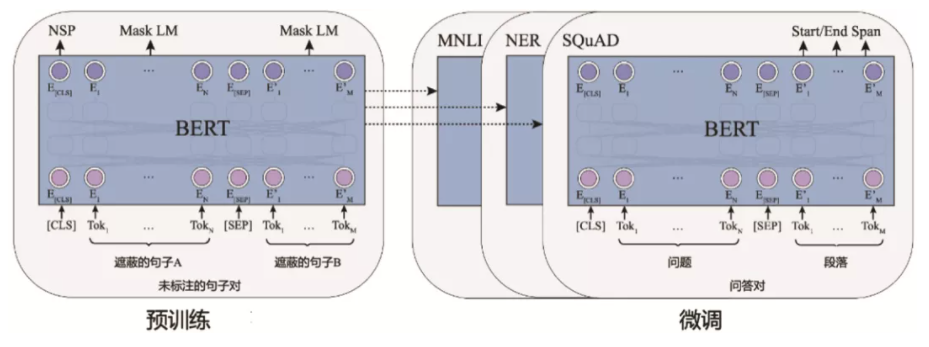
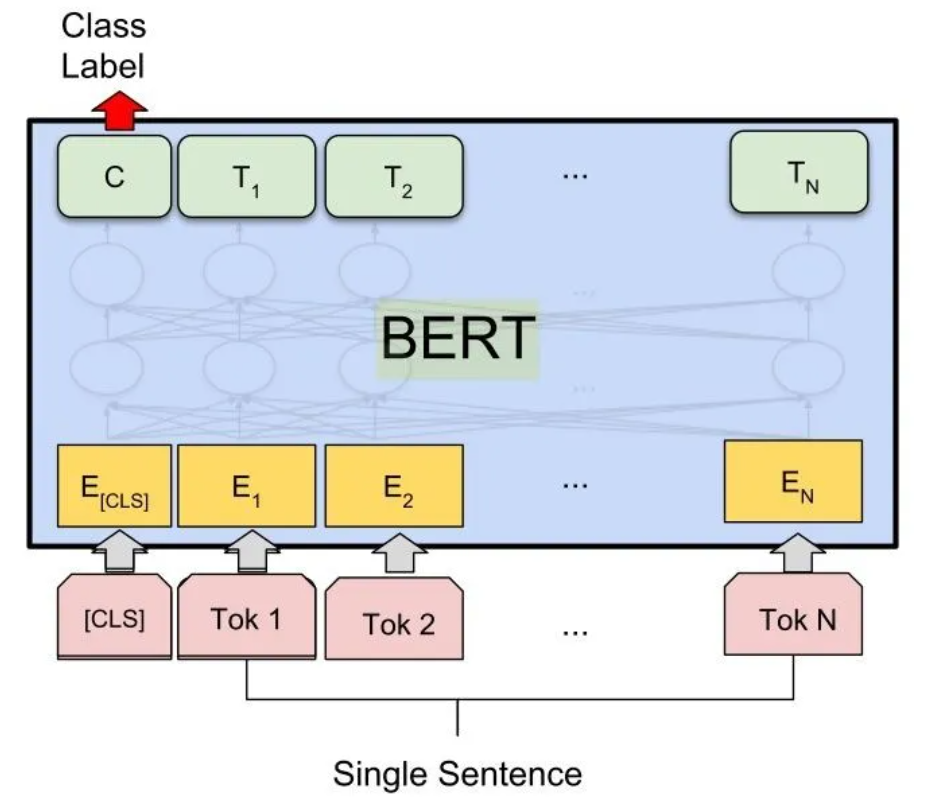
2, Data reading and analysis
# Enter the game data set storage directory %cd /home/aistudio/data/data103654/
/home/aistudio/data/data103654
# Reading datasets using pandas
import pandas as pd
train = pd.read_table('train.txt', sep='\t',header=None) # Training set
dev = pd.read_table('dev.txt', sep='\t',header=None) # Validation set
test = pd.read_table('test.txt', sep='\t',header=None) # Test set
# Adding column names facilitates better processing of data train.columns = ["text_a",'label'] dev.columns = ["text_a",'label'] test.columns = ["text_a"]
# View 752471 training sets in total train
| text_a | label | |
|---|---|---|
| 0 | Netease's third quarter results were lower than analysts' expectations | science and technology |
| 1 | Barcelona's hell reappeared a year ago, but this time it is heaven. It will turn over when they go to the devil's away game again | Sports |
| 2 | The United States says it supports emergency humanitarian assistance to North Korea | Current politics |
| 3 | Capital increase bank of communications Kanglian Bank of communications won the first order of participating insurers | shares |
| 4 | Midday: the raw materials sector led the market | shares |
| ... | ... | ... |
| 752466 | The source of the miracle of Tianjin Women's volleyball team is on the sidelines. He is the real core of the five champions | Sports |
| 752467 | Nortel network patent auction postponed: 6 parts may be split for auction | science and technology |
| 752468 | Determination of issuance price of Spirit AeroSystems bonds | shares |
| 752469 | Lu Huiming must start: Frankfurt has no victory over Manchester United and Inter have passed smoothly | lottery |
| 752470 | Sony 46 inch new LED LCD special price promotion | science and technology |
752471 rows × 2 columns
# View 80000 verification sets in total dev
| text_a | label | |
|---|---|---|
| 0 | What if you win 90 million after the netizens and citizens collectively fantasize about winning the prize | lottery |
| 1 | PVC futures are expected to be listed in May | Finance and Economics |
| 2 | A new work at the third quarter of the afternoon: the record of magic God - fatalistic love | game |
| 3 | OSRAM LLFY network provides one-stop lighting solutions | Home Furnishing |
| 4 | On where the Beijing property market is going: the endless queue is not enough to raise the price | house property |
| ... | ... | ... |
| 79995 | Wang Dalei looked at the predicted score of the national football match. I think it's 2-0 or 3-1 | Sports |
| 79996 | Crazza's return to the Raptors was overwhelming. Hill was expelled and the Suns were defeated by 51 points | Sports |
| 79997 | Wang Jianzhou will create 4G network business opportunities with Taiwan businessmen | science and technology |
| 79998 | Putin made a surprise visit to the food supermarket to investigate his dissatisfaction with the high price of pork (picture) | Current politics |
| 79999 | High altitude overlooking female star sexy cleavage (Group pictures) (7) | fashion |
80000 rows × 2 columns
# View the test set, 83599 in total test
| text_a | |
|---|---|
| 0 | Beijing Juntai department store is full of bright autumn, saving 353020 yuan |
| 1 | Ministry of Education: learning sexual knowledge will begin in the upper grade of primary school |
| 2 | Professional SLR Camera Canon 7D unit price 9280 yuan |
| 3 | DBS Bank sued mainland customers, but the bank's tough customers were helpless |
| 4 | Divorced from China's actual pressure, a sharp appreciation of the RMB can only be a dream |
| ... | ... |
| 83594 | Razer cup DotA elite challenge came out in August |
| 83595 | The improvement of economic data dispelled the expectation of RMB devaluation |
| 83596 | Mortgage rate and collateral dual control policy Liu Mingkang supports real estate loans |
| 83597 | 80 megapixel Rito releases Aptus-II 12 digital back |
| 83598 | The Ministry of Education announced the list of more than 10000 regular schools in 33 countries |
83599 rows × 1 columns
# Splice training and verification sets for statistical analysis total = pd.concat([train,dev],axis=0)
# Total category label distribution statistics total['label'].value_counts()
science and technology one hundred and sixty-two thousand two hundred and forty-five shares one hundred and fifty-three thousand nine hundred and forty-nine Sports one hundred and thirty thousand nine hundred and eighty-two entertainment ninety-two thousand two hundred and twenty-eight Current politics sixty-two thousand eight hundred and sixty-seven Sociology fifty thousand five hundred and forty-one education forty-one thousand six hundred and eighty Finance and Economics thirty-six thousand nine hundred and sixty-three Home Furnishing thirty-two thousand three hundred and sixty-three game twenty-four thousand two hundred and eighty-three house property nineteen thousand nine hundred and twenty-two fashion thirteen thousand three hundred and thirty-five lottery seven thousand five hundred and ninety-eight constellation three thousand five hundred and fifteen Name: label, dtype: int64
# Statistical analysis of text length shows that the text is short, with a maximum length of 48 total['text_a'].map(len).describe()
count 832471.000000 mean 19.388112 std 4.097139 min 2.000000 25% 17.000000 50% 20.000000 75% 23.000000 max 48.000000 Name: text_a, dtype: float64
# Through the statistical analysis of the length of the test set, it can be seen that the length distribution is similar to the training data test['text_a'].map(len).describe()
count 83599.000000 mean 19.815022 std 3.883845 min 3.000000 25% 17.000000 50% 20.000000 75% 23.000000 max 84.000000 Name: text_a, dtype: float64
# Save the processed dataset file
train.to_csv('train.csv', sep='\t', index=False) # Save the training set in the format of text_a,label
dev.to_csv('dev.csv', sep='\t', index=False) # Save the validation set in the format text_a,label
test.to_csv('test.csv', sep='\t', index=False) # Save the test set in the format text_a
3, Constructing baseline model based on PaddleNLP

3.1 pre environment preparation
# Import the required third-party libraries import math import numpy as np import os import collections from functools import partial import random import time import inspect import importlib from tqdm import tqdm import paddle import paddle.nn as nn import paddle.nn.functional as F from paddle.io import IterableDataset from paddle.utils.download import get_path_from_url
# Download the latest version of paddlenlp !pip install --upgrade paddlenlp
# Import the related packages required for paddlenlp import paddlenlp as ppnlp from paddlenlp.data import JiebaTokenizer, Pad, Stack, Tuple, Vocab from paddlenlp.datasets import MapDataset from paddle.dataset.common import md5file from paddlenlp.datasets import DatasetBuilder
3.2 define the pre training model to be fine tuned
# This time, the Roberta WwM ext large model with better effect in the Chinese field is used. The pre training model is generally "miraculous". Selecting a large pre training model can achieve better effect than the base model MODEL_NAME = "roberta-wwm-ext-large" # Just specify the name of the model you want to use and the number of categories of text classification to complete the fine tune network definition, which is classified by splicing a Full Connected network after pre training the model model = ppnlp.transformers.RobertaForSequenceClassification.from_pretrained(MODEL_NAME, num_classes=14) # The classification task is 14, so num_classes is set to 14 # Define the tokenizer corresponding to the model. The tokenizer can convert the original input text into the input data format acceptable to the model. Note that the tokenizer class should correspond to the selected model. For details, see the PaddleNLP related documents tokenizer = ppnlp.transformers.RobertaTokenizer.from_pretrained(MODEL_NAME)
[2021-09-06 23:36:10,711] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/roberta_large/roberta_chn_large.pdparams and saved to /home/aistudio/.paddlenlp/models/roberta-wwm-ext-large [2021-09-06 23:36:10,767] [ INFO] - Downloading roberta_chn_large.pdparams from https://paddlenlp.bj.bcebos.com/models/transformers/roberta_large/roberta_chn_large.pdparams 100%|██████████| 1271615/1271615 [00:18<00:00, 69830.07it/s] [2021-09-06 23:36:41,190] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/roberta_large/vocab.txt and saved to /home/aistudio/.paddlenlp/models/roberta-wwm-ext-large [2021-09-06 23:36:41,193] [ INFO] - Downloading vocab.txt from https://paddlenlp.bj.bcebos.com/models/transformers/roberta_large/vocab.txt 100%|██████████| 107/107 [00:00<00:00, 3538.63it/s]
PaddleNLP supports not only RoBERTa pre training model, but also ERNIE, BERT, Electra and other pre training models. For details: PaddleNLP model
The following table summarizes the various pre training models currently supported by PaddleNLP. Users can use the model provided by PaddleNLP to complete Q & A, sequence classification, token classification and other tasks. At the same time, 22 kinds of pre training parameter weights are provided for users, including the pre training weights of 11 Chinese language models.
| Model | Tokenizer | Supported Task | Model Name |
|---|---|---|---|
| BERT | BertTokenizer | BertModel BertForQuestionAnswering BertForSequenceClassification BertForTokenClassification | bert-base-uncased bert-large-uncased bert-base-multilingual-uncased bert-base-cased bert-base-chinese bert-base-multilingual-cased bert-large-cased bert-wwm-chinese bert-wwm-ext-chinese |
| ERNIE | ErnieTokenizer ErnieTinyTokenizer | ErnieModel ErnieForQuestionAnswering ErnieForSequenceClassification ErnieForTokenClassification | ernie-1.0 ernie-tiny ernie-2.0-en ernie-2.0-large-en |
| RoBERTa | RobertaTokenizer | RobertaModel RobertaForQuestionAnswering RobertaForSequenceClassification RobertaForTokenClassification | roberta-wwm-ext roberta-wwm-ext-large rbt3 rbtl3 |
| ELECTRA | ElectraTokenizer | ElectraModel ElectraForSequenceClassification ElectraForTokenClassification | electra-small electra-base electra-large chinese-electra-small chinese-electra-base |
Note: the Chinese pre training models include Bert base Chinese, Bert WwM Chinese, Bert WwM ext Chinese, ernie-1.0, Ernie tiny, Roberta WwM ext, Roberta WwM ext large, rbt3, rbtl3, China electric base, China Electric small, etc.
3.3 data reading and processing
# Define 14 categories to classify label_list=list(train.label.unique()) print(label_list)
['science and technology', 'Sports', 'Current politics', 'shares', 'entertainment', 'education', 'Home Furnishing', 'Finance and Economics', 'house property', 'Sociology', 'game', 'lottery', 'constellation', 'fashion']
# Define the file corresponding to the dataset and its file storage format
class NewsData(DatasetBuilder):
SPLITS = {
'train': 'train.csv', # Training set
'dev': 'dev.csv', # Validation set
}
def _get_data(self, mode, **kwargs):
filename = self.SPLITS[mode]
return filename
def _read(self, filename):
"""Read data"""
with open(filename, 'r', encoding='utf-8') as f:
head = None
for line in f:
data = line.strip().split("\t") # Separate columns with '\ t'
if not head:
head = data
else:
text_a, label = data
yield {"text_a": text_a, "label": label} # The format of the data set this time is: text_ a. Label, which can be modified according to the specific situation
def get_labels(self):
return label_list # Category label
# Define dataset loading functions
def load_dataset(name=None,
data_files=None,
splits=None,
lazy=None,
**kwargs):
reader_cls = NewsData # Load defined dataset format
print(reader_cls)
if not name:
reader_instance = reader_cls(lazy=lazy, **kwargs)
else:
reader_instance = reader_cls(lazy=lazy, name=name, **kwargs)
datasets = reader_instance.read_datasets(data_files=data_files, splits=splits)
return datasets
# Load training and validation sets train_ds, dev_ds = load_dataset(splits=["train", "dev"])
<class '__main__.NewsData'>
# Define data loading and processing functions
def convert_example(example, tokenizer, max_seq_length=128, is_test=False):
qtconcat = example["text_a"]
encoded_inputs = tokenizer(text=qtconcat, max_seq_len=max_seq_length) # tokenizer is processed in a format acceptable to the model
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
return input_ids, token_type_ids
# Define the data loading function dataloader
def create_dataloader(dataset,
mode='train',
batch_size=1,
batchify_fn=None,
trans_fn=None):
if trans_fn:
dataset = dataset.map(trans_fn)
shuffle = True if mode == 'train' else False
# The training data set is randomly disrupted, and the test data set is not disrupted
if mode == 'train':
batch_sampler = paddle.io.DistributedBatchSampler(
dataset, batch_size=batch_size, shuffle=shuffle)
else:
batch_sampler = paddle.io.BatchSampler(
dataset, batch_size=batch_size, shuffle=shuffle)
return paddle.io.DataLoader(
dataset=dataset,
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)
# Parameter setting: # Batch processing size. If the video memory is insufficient, this value can be appropriately reduced batch_size = 300 # The maximum truncation length of the text sequence shall be determined according to the specific length of the text, and the maximum length shall not exceed 512. It can be seen from the text length analysis that the maximum text length is 48, so it is set to 48 here max_seq_length = 48
# Process the data into a data format that the model can read in
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack() # labels
): [data for data in fn(samples)]
# Training set iterator
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
# Validation set iterator
dev_data_loader = create_dataloader(
dev_ds,
mode='dev',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
3.4 set fine tune optimization strategy and access evaluation index
The learning rate applicable to Transformer models such as BERT is the dynamic learning rate of warmup.
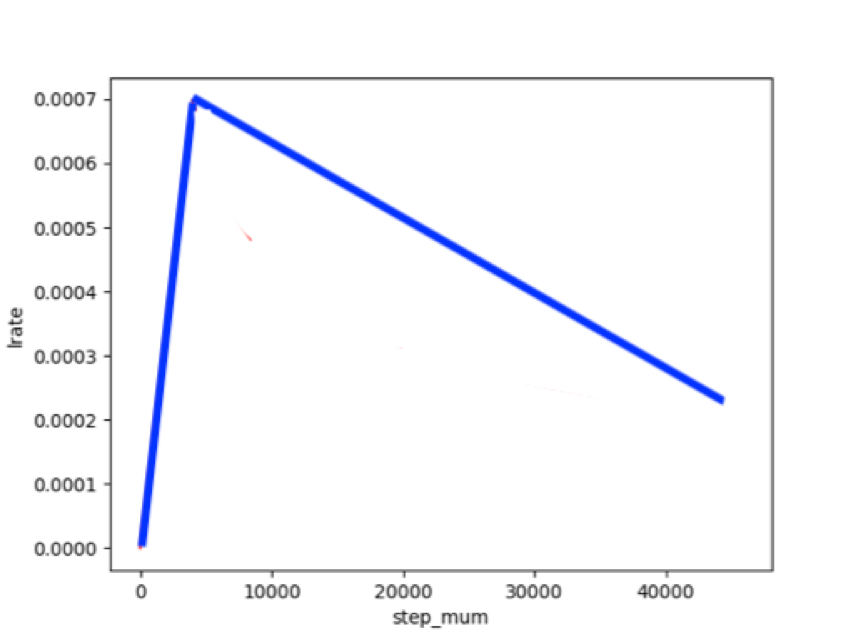
# Define hyperparameters, loss, optimizers, etc
from paddlenlp.transformers import LinearDecayWithWarmup
# Define training configuration parameters:
# Define the maximum learning rate during training
learning_rate = 4e-5
# Training rounds
epochs = 4
# Learning rate preheating ratio
warmup_proportion = 0.1
# The weight attenuation coefficient is similar to the regular term strategy of the model to avoid over fitting of the model
weight_decay = 0.01
num_training_steps = len(train_data_loader) * epochs
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
# AdamW optimizer
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
])
criterion = paddle.nn.loss.CrossEntropyLoss() # Cross entropy loss function
metric = paddle.metric.Accuracy() # accuracy evaluation index
3.5 model training and evaluation
ps: during model training, you can enter NVIDIA SMI command at the terminal or click the "performance monitoring" option at the bottom to view the occupation of video memory, and properly adjust the batch size to prevent accidental suspension due to insufficient video memory.
# Define model training validation evaluation function
@paddle.no_grad()
def evaluate(model, criterion, metric, data_loader):
model.eval()
metric.reset()
losses = []
for batch in data_loader:
input_ids, token_type_ids, labels = batch
logits = model(input_ids, token_type_ids)
loss = criterion(logits, labels)
losses.append(loss.numpy())
correct = metric.compute(logits, labels)
metric.update(correct)
accu = metric.accumulate()
print("eval loss: %.5f, accu: %.5f" % (np.mean(losses), accu)) # Evaluate effect on output validation set
model.train()
metric.reset()
return accu # Return accuracy
# Fixed random seeds facilitate the reproduction of results seed = 1024 random.seed(seed) np.random.seed(seed) paddle.seed(seed)
<paddle.fluid.core_avx.Generator at 0x7f7c85b26a30>
ps: during model training, you can check the occupation of video memory by entering NVIDIA SMI command at the terminal or through the performance monitoring option at the bottom right. If the video memory is insufficient, you should properly adjust the value of batchsize.
# Model training:
import paddle.nn.functional as F
save_dir = "checkpoint"
if not os.path.exists(save_dir):
os.makedirs(save_dir)
pre_accu=0
accu=0
global_step = 0
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, segment_ids, labels = batch
logits = model(input_ids, segment_ids)
loss = criterion(logits, labels)
probs = F.softmax(logits, axis=1)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 10 == 0 :
print("global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f" % (global_step, epoch, step, loss, acc))
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
# The validation set is evaluated at the end of each round
accu = evaluate(model, criterion, metric, dev_data_loader)
print(accu)
if accu > pre_accu:
# Save better model parameters than the previous round
save_param_path = os.path.join(save_dir, 'model_state.pdparams') # Save model parameters
paddle.save(model.state_dict(), save_param_path)
pre_accu=accu
tokenizer.save_pretrained(save_dir)
# Load the model parameters of the round with the best effect on the verification set
import os
import paddle
params_path = 'checkpoint/model_state.pdparams'
if params_path and os.path.isfile(params_path):
# Load model parameters
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
print("Loaded parameters from %s" % params_path)
Loaded parameters from checkpoint/model_state.pdparams
# Test the score of the optimal model parameters on the verification set evaluate(model, criterion, metric, dev_data_loader)
eval loss: 0.01434, accu: 0.99598 0.995975
3.6 model prediction
# Define model prediction function
def predict(model, data, tokenizer, label_map, batch_size=1):
examples = []
# Process the input data (list format) into a format acceptable to the model
for text in data:
input_ids, segment_ids = convert_example(
text,
tokenizer,
max_seq_length=128,
is_test=True)
examples.append((input_ids, segment_ids))
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input id
Pad(axis=0, pad_val=tokenizer.pad_token_id), # segment id
): fn(samples)
# Seperates data into some batches.
batches = []
one_batch = []
for example in examples:
one_batch.append(example)
if len(one_batch) == batch_size:
batches.append(one_batch)
one_batch = []
if one_batch:
# The last batch whose size is less than the config batch_size setting.
batches.append(one_batch)
results = []
model.eval()
for batch in batches:
input_ids, segment_ids = batchify_fn(batch)
input_ids = paddle.to_tensor(input_ids)
segment_ids = paddle.to_tensor(segment_ids)
logits = model(input_ids, segment_ids)
probs = F.softmax(logits, axis=1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [label_map[i] for i in idx]
results.extend(labels)
return results # Return forecast results
# Define categories to classify
label_list=list(train.label.unique())
label_map = {
idx: label_text for idx, label_text in enumerate(label_list)
}
print(label_map)
{0: 'science and technology', 1: 'Sports', 2: 'Current politics', 3: 'shares', 4: 'entertainment', 5: 'education', 6: 'Home Furnishing', 7: 'Finance and Economics', 8: 'house property', 9: 'Sociology', 10: 'game', 11: 'lottery', 12: 'constellation', 13: 'fashion'}
# Read the test set file to predict
test = pd.read_csv('./test.csv',sep='\t')
# Define the data preprocessing function to specify the list format for model input
def preprocess_prediction_data(data):
examples = []
for text_a in data:
examples.append({"text_a": text_a})
return examples
# Format test set data
data1 = list(test.text_a)
examples = preprocess_prediction_data(data1)
# Predict the test set results = predict(model, examples, tokenizer, label_map, batch_size=16)
# Store the prediction results in list format as txt file, and submit the format requirements: one category per line
def write_results(labels, file_path):
with open(file_path, "w", encoding="utf8") as f:
f.writelines("\n".join(labels))
write_results(results, "./result.txt")
# Since the format is required to be zip, the result file needs to be compressed into submission.zip submission file !zip 'submission.zip' 'result.txt'
adding: result.txt (deflated 89%)
# Move the data directory to submit the result file to the main directory for saving the result file
(file_path, "w", encoding="utf8") as f:
f.writelines("\n".join(labels))
write_results(results, "./result.txt")
# Since the format is required to be zip, the result file needs to be compressed into submission.zip submission file !zip 'submission.zip' 'result.txt'
adding: result.txt (deflated 89%)
# Move the data directory to submit the result file to the main directory for saving the result file !cp -r /home/aistudio/data/data103654/submission.zip /home/aistudio/
It should be noted that the submission format is zip. Find the generated submission.zip file in the main directory, download it locally and submit it on the competition page!

4, Lifting direction:
1. The training data can be enhanced to increase the amount of training data to improve the generalization ability of the model. NLP Chinese Data Augmentation one click Chinese data enhancement tool
2. Based on the baseline model, the effect can be further improved by adjusting the participation and model optimization. Practice of fine tuning skills in text classification
3. Try to use different pre training models, such as ERNIE and NEZHA, and vote and fuse the results of multiple models. Competition score Trick result fusion
4. After the training and verification sets are spliced, the division of the training and verification sets can be customized, and the difference results can be used for fusion or 5folds cross verification.
5. Take the same part of the prediction results of multiple models as a pseudo tag for model training. Pseudo label technique is generally used when the model accuracy is high, and beginners should use it with caution.
6. Those who are capable can try to re pre train under the training corpus and modify the model network structure to further improve the effect.
7. For more skills, you can try more by learning the Top sharing of other short text classification competitions. Zero basic introduction NLP - News Text Classification
About the use of PaddleNLP: it is recommended to read the latest official documents PaddleNLP document
github address of PaddleNLP: https://github.com/PaddlePaddle/PaddleNLP If you have questions, you can raise the issue on github and someone will answer them.
5, Personal introduction
Nickname? Alchemist 233
Current main direction: development, mainly focusing on NLP and data mining related competitions or projects
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/330406 Pay attention to me and bring more wonderful projects to share next time!
