Reprint: http://book.odoomommy.com/chapter5/README14.html
Chapter 14 startup of Odoo
Startup script
Let's take a look at the startup script of Odoo first:
__import__('os').environ['TZ'] = 'UTC'
import odoo
if __name__ == "__main__":
odoo.cli.main()
It can be seen that the startup of odoo has done two things:
- Set the time zone of the environment variable to UTC
- Call the main method of cli module to start the program.
Cli module
Cli module contains a series of support functions of odoo startup and command line. The command line commands supported natively are as follows:
- Help: help
- cloc: a tool used to count the number of lines and words of code
- deploy: tool for publishing modules
- Scaffold: scaffold program for creating third-party modules
- populate: a tool for automatically generating test data
- server: the default method to start the main program
- Shell: shell environment of odoo
- Start: command to quickly start the odoo server
The core module related to startup is command Py file. After the odoo script is started, command.exe will be called Py file, execute the startup program of odoo.
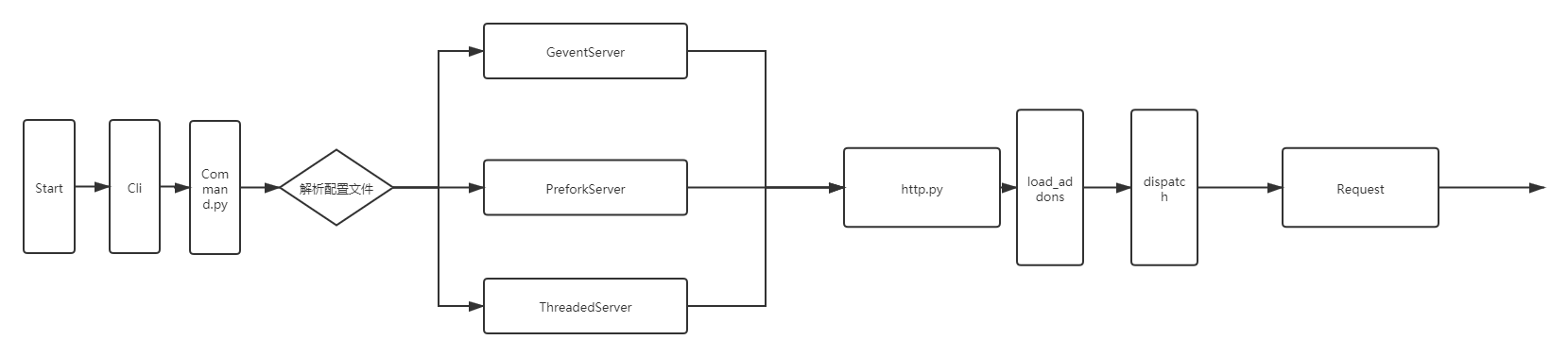
The main method is used to analyze the parameters in the command line, match the correct command and execute the corresponding operation. Because the default command is server, we start the main service process of odoo by default.
Condition check of main process
Before starting the odoo process, the system will also check the environment of the process, including the following conditions:
- Root user: using root user in Linux environment is a potential risk factor, so the system does not allow root user to start
- postgres: similarly, postgres accounts are also not allowed for database users.
There are also restrictions on the size of csv files in the system, and the maximum acceptable size is 500M.
After the condition check is completed, the system will create a process file and really start the process.
Main process
The startup type of the main process varies depending on whether the multi process option is configured. Specifically, it can be divided into the following types:
- GeventServer: the Server that uses Gevent collaboration.
- Preforkserver: multi process instance driven by gunicorn.
- ThreadedServer: a process driven by multithreading mode.
That is, if multiple workers are used in the configuration file, the multi process instance driven by Gunicorn will be used for running, otherwise, the single process will be used for running. By default, the single process will be driven in multi-threaded mode. If the gevent parameter is specified in the startup parameter, the single process driven by gevent will be used for driving.
In addition, unit tests can only be run in single process mode.
Startup in thread mode
Starting in thread mode will start HttpServer and timed task thread CronThread at the same time. Thread mode uses multithreading to call http_thread method:
def http_thread(self):
def app(e, s):
return self.app(e, s)
self.httpd = ThreadedWSGIServerReloadable(self.interface, self.port, app)
self.httpd.serve_forever()
WSGIServer is used internally to start as a Web server.
Startup in Gevent mode
In gevent mode, WSGISever is also used, but the difference is that gevent co process mode is used for startup.
self.httpd = WSGIServer(
(self.interface, self.port), self.app,
log=logging.getLogger('longpolling'),
error_log=logging.getLogger('longpolling'),
handler_class=ProxyHandler,
)
_logger.info('Evented Service (longpolling) running on %s:%s', self.interface, self.port)
Gevent mode works on port 8072 by default, that is, the long connection port. As the name suggests, gevent server is a service used to process long connection requests. This mode is generally not used in single process mode.
Startup in PreforkServer mode
PreforkServer mode, the process will fork out multiple processes, then the parent process of multiple processes is designated as the first process, and then invoke the run method of worker to start.
PreforkServer uses gunicorn driver. After startup, it will perform the following four tasks:
- self.process_signals()
- self.process_zombie()
- self.process_timeout()
- self.process_spawn()
After processing the incoming process signal, dead process and timeout process, start incubating new processes. In the process of incubating a new process, a GeventServer will be created to handle long connection tasks. This can be confirmed by looking at the process list:

TIP
If we don't configure the reverse agent in the test environment, we start multiple times workder Mode, then we will encounter the following errors:
```python
Traceback (most recent call last):
File "/mnt/hgfs/Code/odoo/odoo14/odoo/http.py", line 639, in _handle_exception
return super(JsonRequest, self)._handle_exception(exception)
File "/mnt/hgfs/Code/odoo/odoo14/odoo/http.py", line 315, in _handle_exception
raise exception.with_traceback(None) from new_cause
Exception: bus.Bus unavailable
```
The reason for this error is because IM The message bus mechanism of the module uses the long connection mechanism. Although the long connection process is started in the background, we web The end does not longpolling The request is forwarded to the long connection process listening on port 8072. The distributor of the message bus only supports in a single worker perhaps gevent Run in mode, for ordinary multi workder Process, unable to get dispatch Object, so the above error will be raised.
The method to solve this problem is also very simple. Configuring the front-end reverse proxy server will longpolling Your request reached gevent Process.
```sh
location /longpolling {
proxy_pass http://127.0.0.1:8072;
}
location / {
proxy_pass http://127.0.0.1:8069;
}
```
After the main process starts, odoo enters the listening mode. The entry of odoo to process HTTP requests is http Py file.
def application_unproxied(environ, start_response):
""" WSGI entry point."""
# cleanup db/uid trackers - they're set at HTTP dispatch in
# web.session.OpenERPSession.send() and at RPC dispatch in
# odoo.service.web_services.objects_proxy.dispatch().
# /!\ The cleanup cannot be done at the end of this `application`
# method because werkzeug still produces relevant logging afterwards
if hasattr(threading.current_thread(), 'uid'):
del threading.current_thread().uid
if hasattr(threading.current_thread(), 'dbname'):
del threading.current_thread().dbname
if hasattr(threading.current_thread(), 'url'):
del threading.current_thread().url
with odoo.api.Environment.manage():
result = odoo.http.root(environ, start_response)
if result is not None:
return result
Let's take a look at the core method of Root:
def __call__(self, environ, start_response):
""" Handle a WSGI request
"""
if not self._loaded:
self._loaded = True
self.load_addons()
return self.dispatch(environ, start_response)
From this, we can see that odoo will judge whether the addons module of the current process is loaded. If it is not loaded, start the loader, and finally enter the listening mode.
The core of the Root class is the dispatch method, which is responsible for mounting the session, binding the database, setting the locale, and handling some exceptions in the request.
The next part is the content of the Request part we are very familiar with.
summary
We can summarize this process into a more intuitive diagram: