Okio article reading and writing timeout detection mechanism. Firstly, it will introduce several important classes in okio, and then provide a code for reading and writing files with Okio api. According to this code, it will analyze the overall reading and writing process, and analyze why okio is more efficient than using Java io directly. Finally, it introduces how okio performs timeout detection during reading and writing.
1.OKio introduction
Okio, as the underlying io Library of Okhttp, complements Java io and Java NiO makes it easier to access, store and process data.
Introduction to several important classes in Okio
- < font color ='Red '> ByteString < / font > is an immutable sequence of bytes. For character data, the most basic is String. ByteString is like the brother of String, which makes it easy to treat binary data as a variable value. This class is smart: it knows how to encode and decode itself into hex, base64, and utf-8.
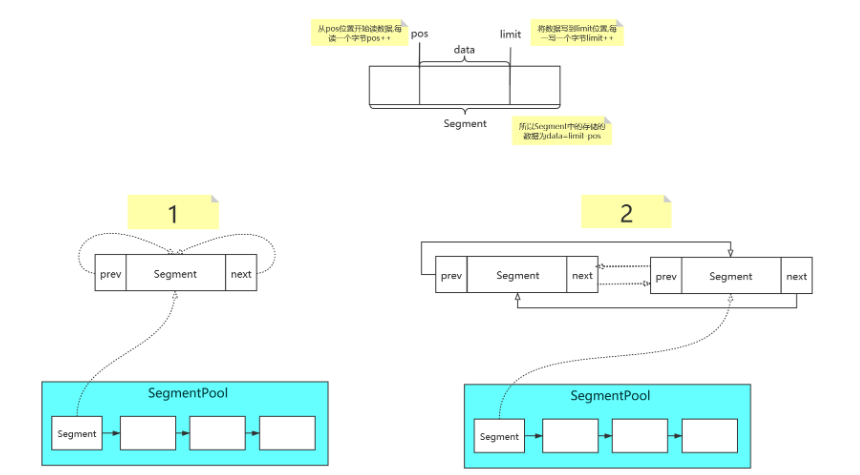
- < font color ='Red '> Segment < / font > Segment is used as the carrier of data buffer in okio. The data buffer size of a Segment is 8192, i.e. 8k. Each Segment has its predecessor and successor nodes. That is to say, a Segment is a two-way linked list. To be exact, it is a two-way circular linked list. Read data is read from the Segment head node and write data is written from the Segment tail node. Okio introduces the concept of pool, that is, the implementation of SegmentPool in the source code. The SegmentPool is responsible for creating and destroying segments. The SegmentPool can cache up to 8 segments.
- < font color ='Red '> buffer < / font > is a variable byte sequence. Like Arraylist. Because its bottom layer is implemented by Segment, you don't need to preset the size of the buffer,
When you move data from one buffer to another, it will reallocate the holding relationship of segments instead of copying data across segments. Buffer implements BufferedSource and BufferedSink, and has read-write function at the same time. < font color ='Red '> sources < / font > is similar to InputStream in java. As the top-level interface for reading data in Okio, Source only provides a simple api
long read(Buffer sink, long byteCount) throws IOException; Timeout timeout(); void close() throws IOException;
More reading APIs are provided by its sub interface BufferedSource. The implementation class is RealBufferdSource. The underlying InputStream - > Buffer, and then read based on Buffer.
< font color ='Red '> Sink < / font > is similar to OutPutStream in java. As the top-level interface for writing data in Okio, Sink only provides a simple api
void write(Buffer source, long byteCount) throws IOException; void flush() throws IOException; Timeout timeout(); void close() throws IOException;
More write APIs are provided by its sub interface BufferedSink,
The implementation class is RealBufferedSink. The bottom layer writes the data to the Buffer, and then the Buffer writes it to the OutPutStream.
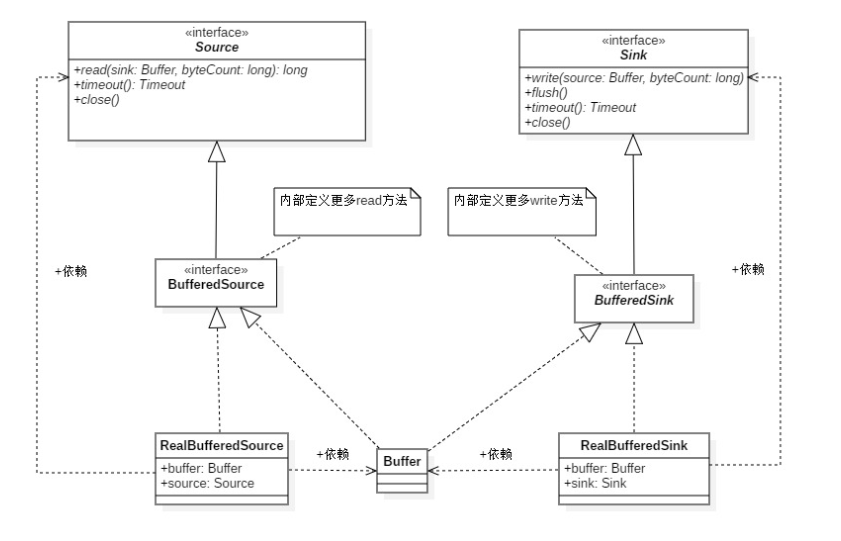
GzipSource, GzipSink, HashingSink, HashingSource are omitted here Other classes that implement Source and Sink only focus on the main process.
According to the previous introduction and UML diagram, data reading and writing are implemented in RealBufferedSource and RealBufferedSink
2.Okio reading and writing process
As a simple entry point, here is a code to write the input stream of Okio implementation to the specified file.
/***
* Writes the byte input stream to the specified file
* @return true Write succeeded, false write failed
*/
fun copy(inputStream: InputStream, dest: File): Boolean {
val source = Okio.buffer(Okio.source(inputStream))
val sink = Okio.buffer(Okio.sink(dest))
val buffer = Buffer()
return try {
var length = source.read(buffer, 8192L)
while (-1L != length) {
sink.write(buffer, length)
sink.flush()
length = source.read(buffer, 8192L)
}
true
} catch (e: Exception) {
e.printStackTrace()
false
} finally {
source.close()
sink.close()
}
}Okio.source(inputStream) implements the packaging of InputStream, which is wrapped in the source object and returned.
private static Source source(final InputStream in, final Timeout timeout) {
...
return new Source() {
@Override public long read(Buffer sink, long byteCount) throws IOException {
...
if (byteCount == 0) return 0;
try {
//Timeout check
timeout.throwIfReached();
//Get Segment from SegmentPool
Segment tail = sink.writableSegment(1);
//Calculate the maximum number of bytes that can be written to the Segment according to the available size in the Segment
int maxToCopy = (int)
Math.min(byteCount, Segment.SIZE - tail.limit);
//Write data from inputStream to Segment
int bytesRead = in.read(tail.data, tail.limit, maxToCopy);
//Return if finished reading
if (bytesRead == -1) return -1;
//Append the amount of data that has been written, which is used to write the data from the limit position next time, that is, the data written before the limit
tail.limit += bytesRead;
//Correct the number of bytes stored in the buffer
sink.size += bytesRead;
return bytesRead;
} catch (AssertionError e) {
if (isAndroidGetsocknameError(e)) throw new IOException(e);
throw e;
}
}
@Override public void close() throws IOException {
in.close();
}
@Override public Timeout timeout() {
return timeout;
}
@Override public String toString() {
return "source(" + in + ")";
}
};
}
//Buffer#writableSegment
Segment writableSegment(int minimumCapacity) {
...
//1
if (head == null) {
head = SegmentPool.take();
return head.next = head.prev = head;
}
//2
Segment tail = head.prev;
if (tail.limit + minimumCapacity > Segment.SIZE || !tail.owner) {
tail = tail.push(SegmentPool.take());
}
return tail;
}- If the chain header is empty, get a new node from the SegmentPool and point to the head node to return.
- Because it is a two-way circular list, head Prev always obtains the tail node (point to itself when the length of the linked list is 1). If the capacity of the tail node to store data is full or the tail If the owner is false (that is, the sement cannot be written additionally), a new node is obtained from the SementPool, inserted into the tail of the node, and a new node is returned.
Okio.buffer(Okio.source(src)) is equivalent to okio Buffer (source), wrap the source in RealBufferedSource(source) and return it.
val source = Okio.buffer(Okio.source(src)) source.read(buffer,8192L)
Execute read((buffer,8192L)), which is actually the called realbufferedsource read(buffer,byteCount). And realbufferedsource Read (buffer, ByteCount) will call the read(buffer,length) of the wrapped Source. That is, the read data code we analyzed above.
//RealBufferedSource#read(buffer,8192L)
public long read(Buffer sink, long byteCount) throws IOException {
if (buffer.size == 0) {
//Call the wrapped Source.
//That is, read segment from InputStream Size bytes are written into the buffer
long read =
source.read(buffer,Segment.SIZE);
//Returns if no data is read
if (read == -1) return -1;
}
//When the data is read, the data is saved in the buffer, and then the buffer is written to sink. Write one buffer to another.
long toRead = Math.min(byteCount, buffer.size);
return buffer.read(sink, toRead);
}
//Buffer#read(sink,toRead)
public long read(Buffer sink, long byteCount) {
if (size == 0) return -1L;
if (byteCount > size) byteCount = size;
//The efficient part of Okio is the implementation of buffer#write(), which will be analyzed in detail later. It is understood here that the data in the buffer is written into the sink passed in externally
sink.write(this, byteCount);
return byteCount;
}Okio.sink(dest) converts a File to an OutPutStream and wraps it in a sink object.
public static Sink sink(OutputStream out) {
return sink(out, new Timeout());
}
private static Sink sink(final OutputStream out, final Timeout timeout) {
...
return new Sink() {
@Override public void write(Buffer source, long byteCount) throws IOException {
checkOffsetAndCount(source.size, 0, byteCount);
while (byteCount > 0) {
//Timeout detection
timeout.throwIfReached();
//Get chain header node
Segment head = source.head;
//Calculate how many bytes can be read at a time
int toCopy = (int) Math.min(byteCount, head.limit - head.pos);
//Read data from head and write it to OutPutStream
out.write(head.data, head.pos, toCopy);
//Correct the position where the head reads, and continue reading from the pos position next time
head.pos += toCopy;
//Decreasing until byteCount=0 exits the loop, which indicates that the writing is completed this time
byteCount -= toCopy;
//Fix the size of bytes stored in buffer
source.size -= toCopy;
//If the Segment has been read
if (head.pos == head.limit) {
//Delete head from the linked list and assign the next node of head to head
source.head = head.pop();
//Recycle head node
SegmentPool.recycle(head);
}
}
}
@Override public void flush() throws IOException {
out.flush();
}
@Override public void close() throws IOException {
out.close();
}
@Override public Timeout timeout() {
return timeout;
}
@Override public String toString() {
return "sink(" + out + ")";
}
};
}Okio.buffer(Okio.sink(dest)) is equivalent to okio Buffer (sink), wrap the sink in RealBufferedSink(Sink) and return it.
val sink = Okio.buffer(Okio.sink(dest)) sink.write(buffer, length) sink.flush()
write(buffer,length) and flush() actually call write(buffer,length) and flush() of RealBufferedSink. The write(buffer,length) and flush() of RealBufferedSink will eventually call the write(buffer,length) and flush() of the wrapped Sink.
//RealBufferedSink#write(Buffer source, long byteCount)
public void write(Buffer source, long byteCount)
throws IOException {
//Write the data from the source to the buffer. The efficient part of Okio is the implementation of buffer#write
buffer.write(source, byteCount);
emitCompleteSegments();
}
public BufferedSink emitCompleteSegments() throws IOException {
long byteCount = buffer.completeSegmentByteCount();
//Check whether the buffer is full. If it is full, write the data to the OutPutStream. If it is not full, wait until the next time it is full or flush or close is called to write the data to the OutPutStream, which plays a buffer role.
if (byteCount > 0) {
//Call wrapped Sink#write(buffer, byteCount)
//Write data in buffer to OutPutStream
sink.write(buffer, byteCount);
}
return this;
}
public long completeSegmentByteCount() {
long result = size;
if (result == 0) return 0;
Segment tail = head.prev;
if (tail.limit < Segment.SIZE && tail.owner) {
result -= tail.limit - tail.pos;
}
return result;
}
So far, the basic input-output process of Okio has been analyzed. According to the source code analysis, Okio is a encapsulation and optimization of Java IO, and the bottom layer still uses InputStream and OutputStream. Since it reads and writes in the same way as the underlying Java IO, what are its advantages? Some people may say that it is embodied in the simplicity of api, clear structure, chain programming and convenient call. You're right. This is its advantage, which doesn't convince me to abandon Java IO and use it. In fact, you can also encapsulate a set of chain programming based on Java io. Its biggest advantage over the direct use of Java IO is not the simplicity of the api, but the efficiency of IO stream copying and memory reuse, which will be described in detail in the next section.
3. Why does okio have more advantages than using Java io directly
In the previous section, we mentioned that the biggest advantage of Okio and using Java io directly is not the simplicity of api, but the efficiency of io stream copy and memory reuse. Before talking about these two advantages, let's take a look at the steps from input to output using Java io and Okio directly.
- Java io
InputStream -- > bufferedinputstream -- > temporary byte array -- > bufferedoutputstream -- > OutputStream
This shows that a temporary byte array appears in the Java io process from input to output. It means copying data from bufferedinputstream - > temporary byte array once, and copying data from temporary byte array - > bufferedoutputstream again.
- Okio
InputStream -- > inbuffer -- > temporary buffer -- > outbuffer -- > OutputStream
It looks like the middle part is the same as the Java io steps. In fact, it's not the case. We just said that Java io goes through two copies, while the middle part of Okio inbuffer - > temporary buffer - > overbuffer is not exactly a copy of data. When analyzing buffer - > buffer, we will describe in detail why it is not completely a data copy. Buffer - > buffer is defined in the Buffer#write(Buffer source, long byteCount) method. According to the wirte method annotation, Okio has two indicators in implementing buffer - > buffer.
The blogger's translation of notes is introduced here
- Don't waste CPU
Don't waste CPU, that is, don't copy data everywhere and reallocate the whole Segments from one buffer to another.
- Don't waste memory
Segment is an immutable variable. In addition to the segments of the head node and tail node, the adjacent segments in the buffer should ensure at least 50% of the data load (referring to the data data in the segment. Okio believes that the data can be effectively used only when the data volume is more than 50%). Because the head node needs to read the consumed byte data and the tail node needs to write the generated byte data, the head node and tail node cannot maintain invariance.
Move clips between buffers
When writing one buffer to another, we prefer to reallocate the entire segment and copy the bytes to the most compact form. Suppose we have a buffer in which the fragment load is [91%, 61%]. If we want to add a single fragment with a load of [72%], the result will be [91%, 61%, 72%]. No byte copy operation will be performed during this period. (i.e. space for time, sacrificing memory and providing speed)
Suppose again that we have a buffer with a load of [100%, 2%], and we want to attach it to a buffer with a load of [99%, 3%]. This operation will produce the following parts: [100%, 2%, 99%, 3%], that is, we will not spend time copying bytes to improve memory efficiency, such as [100%, 100%, 4%]. (that is, in this case, Okio will not adopt the strategy of time for space, because it wastes too much CPU)
When the adjacent buffer is not compressed by more than 100%, we merge the adjacent buffers. For example, when we add [30%, 80%] to [100%, 40%], the result will be [100%, 70%, 80%]. (that is, two segments with 40% and 30% load in the middle will be combined into one Segment with 70% load)
Split segment
Sometimes we only want to write part of the source buffer into the sink buffer. For example, given a sink of [51%, 91%], now we want to write the first 30% of a source of [92%, 82%] into the sink buffer. To simplify, we first convert the source buffer into an equivalent buffer [30%, 62%, 82%] (i.e. split Segment), and then move the head node Segment of the source to generate sink[51%, 91%, 30%] and source[62%, 82%].
According to the definitions in the notes above, we can see that during buffer data transfer, different operations are performed according to different strategies to achieve the balance between CPU and memory. Let's look at the code implementation of buffer transfer.
//Buffer#write
public void write(Buffer source, long byteCount) {
while (byteCount > 0) {
//If the amount of data copied is smaller than the existing amount of data in the original buffer
if (byteCount < (source.head.limit - source.head.pos)) {
//Get destination buffer tail node
Segment tail = head != null ? head.prev : null;
//If the tail node of the target buffer is not empty and is the data owner, the data can be appended and the target buffer can store the data
if (tail != null && tail.owner
&& (byteCount + tail.limit - (tail.shared ? 0 : tail.pos) <= Segment.SIZE)) {
//If [10%] is added to [20%], copy directly. Final result [30%]
//Copy the original buffer to the destination buffer
source.head.writeTo(tail, (int) byteCount);
source.size -= byteCount;
size += byteCount;
return;
} else {
//If the tail node of the target buffer is empty, that is, the target buffer is empty, the buffer is not empty, but the space is insufficient, or it is not the holder, then the head node of the original buffer needs to be divided into two segments,
//Then update the header pointer of the original buffer to the first Segment after segmentation, such as [92%, 82%] to [30%, 62%, 82%]
source.head = source.head.split((int) byteCount);
}
}
// Remove the head node from the linked list of the original buffer and add it to the tail node of the target buffer
Segment segmentToMove = source.head;
long movedByteCount = segmentToMove.limit - segmentToMove.pos;
source.head = segmentToMove.pop();
//If the target buffer is empty, create a linked list and assign the chain header node of the original buffer to the header node of the target buffer node
if (head == null) {
head = segmentToMove;
head.next = head.prev = head;
} else {
//If the target buffer is not empty, the head node of the original buffer node is appended to the target buffer linked list. And try to merge, such as [60%, 20%] add [10%]. Then the target buffer node is [60%, 20%, 10%]. Then [60%, 30%] after combination.
//Merge successfully reclaims redundant nodes to save space
Segment tail = head.prev;
tail = tail.push(segmentToMove);
tail.compact();
}
source.size -= movedByteCount;
size += movedByteCount;
byteCount -= movedByteCount;
}
}According to the above source code analysis and comments, answer why Okio is more efficient than Java io.
In order to efficiently read and write data in Java, we introduce BufferedInputStream and BufferedOutPutStream. Here, take BufferedInputStream reading and writing disk files as an example. In BufferedInputStream, when the number of bytes read at a time is greater than the size of the buffer, the buffer will be discarded and read directly from the disk.
If the number of bytes read at a time is less than the buffer size, the buffer size bytes will be read from the disk first (8K is defined by default in BufferedInputStream). Then read the set number of reads from the buffer each time. Until the buffer is read. Then read from disk Until the entire disk data is read
When Okio reads, whether the byte length you read is greater than the buffer size or not. Directly read 8k data into the buffer, and then compare the read size you set with the existing data size in the current buffer to get the minimum value for data transfer.
for instance
For example, the data 16K is read to the temporary variable once:
The read size is set to 4k
- Okio experiences 0 copies, inBuffer - > temporary buffer. It only splits the inBuffer data and assigns the split data to the temporary buffer, which is only the modification of the pointer
- Java io reads the temporary variable once and experiences one copy, that is, buffer - > temporary byte array.
The read size is set to 8k
- Okio has undergone 0 copies, inbuffer - > temporary buffer, which is only the modification of the pointer
- Java io reads the temporary variable once and experiences 0 copies. Because it is greater than or equal to the buffer size, it reads it directly from the disk, that is, InputStream - > temporary byte array.
The read size is set to 16k
- Okio experiences 0 copies, inbuffer - > temporary buffer, which is only the pointer
Modification. But going through two read s means going through two pointer modifications. - Java io reads the temporary variable once and experiences 0 copies. Because it is greater than or equal to the buffer size, it reads it directly from the disk, that is, InputStream - > temporary byte array. Go through a read, but waste memory.
From the above examples, we can see that Okio has made a good trade-off between CPU and memory. If it exceeds 8k, it will read only 8k, reducing the data loaded into memory at one time.
No more than 8k, the data replication is only to modify the linked list pointer.
Summary:
Okio is more efficient than using Java io directly because of its underlying buffer implementation structure. Defining the data buffer as a linked list structure is to better move the data from the buffer to the buffer, that is, it does not waste CPU (do not copy data everywhere). In terms of memory, it introduces SegmentPool to reuse segments. After all, it's a waste to open up an 8k byte [] directly. And compress the data of buffer linked list nodes to reduce unnecessary memory overhead.
4.Okio timeout detection
The timeout mechanism is divided into synchronous detection and asynchronous detection, starting with a simple one.
Take the data reading timeout detection as an example.
4.1 synchronous detection
Through the previous analysis, RealBufferedSource#read() is actually called when read() is called. And RealBufferedSource#read() will call the wrapped Source, that is, read() of the Source created by Okio#source().
//Source returned by Okio#source()
private static Source source(final InputStream in, final Timeout timeout) {
...
return new Source() {
public long read(Buffer sink, long byteCount) throws IOException {
...
try {
//Timeout detection
timeout.throwIfReached();
...
int bytesRead = in.read(tail.data, tail.limit, maxToCopy);
...
return bytesRead;
} catch (AssertionError e) {
if (isAndroidGetsocknameError(e)) throw new IOException(e);
throw e;
}
}
...
};
}
//Timeout
public class Timeout {
private boolean hasDeadline;
private long deadlineNanoTime;
private long timeoutNanos;
public Timeout() {
}
public Timeout deadlineNanoTime(long deadlineNanoTime) {
this.hasDeadline = true;
this.deadlineNanoTime = deadlineNanoTime;
return this;
}
public void throwIfReached() throws IOException {
if (Thread.interrupted()) {
throw new InterruptedIOException("thread interrupted");
}
if (hasDeadline && deadlineNanoTime - System.nanoTime() <= 0) {
throw new InterruptedIOException("deadline reached");
}
}
}According to code analysis, timeout#throwIfReached() will be called every time read() is called. Combined with the definition in Timeout class, hasdeadline and deadlinenanotime will be assigned when deadlineNanoTime() is called to set the deadline. That is, the call of throwIfReached() will play the role of checking Timeout, that is, the synchronous detection Timeout mechanism is to judge whether to Timeout according to the passage of time.
4.2 asynchronous detection
Asynchronous detection Okio is used to detect the reading of Socket input stream and the writing of output stream. Here, only input stream detection is taken as an example. First, the overall design of asynchronous detection is described. Let's have an overview of the whole
Macro understanding; Not to lose focus when analyzing the source code, and finally analyze the code implementation in detail.
The overall design of asynchronous detection is as follows:
- The structure uses the single linked list as the structure of detecting timeout, encapsulates the timeout time into the node, and inserts it into the linked list according to the ascending order of timeout time. That is, the node that will expire soon is the next node of the head node. The head node acts as a watchdog here. So the head node remains unchanged.
- When starting to read from socket#inputStream, start a monitoring thread (Watchdog). Continuously obtain the next node of the head node, that is, the monitored node, and judge whether it is empty. If it is empty, wait for 60S. If it is still empty after 60S, exit the monitor; If it is not empty, the timeout time stored in the node will be taken to judge whether it is timeout. If there is no timeout, wait for the timeout time stored in the node. When the time expires or is awakened by the linked list insertion operation, the process will go through again; If the timeout expires, delete the node and close the socket.
- If there is no timeout in the whole process, delete the monitored node after reading. Until the monitoring thread wait() finds that there is no node to monitor after waiting for the set time, and then exits the whole monitoring thread. Or when you are still in wait(), read() again, that is, a new monitored node is added to the linked list. At this time, the wait is awakened. After waking up, it starts to monitor the new node.
Let's analyze the code, starting from creating Source with Socket
//Okio.source(socket)
public static Source source(Socket socket) throws IOException {
//The first step is to create AsyncTimeout and wrap the socket. The wrapping is to call timedOut() to close the socket when the Timeout occurs. AsyncTimeout is a subclass of Timeout
AsyncTimeout timeout = timeout(socket);
//Step 2: create the source and wrap the socket getInputStream()
Source source = source(socket.getInputStream(), timeout);
//The third step is to create a source and wrap the source of the second step, that is, when the source is called externally When reading, you actually call the second step of read,
The third step of packaging is for the second step read Add one more layer of monitoring when
return timeout.source(source);
}
//Create AsyncTimeout and wrap the socket. AsyncTimeout is a subclass of Timeout
private static AsyncTimeout timeout(final Socket socket) {
return new AsyncTimeout() {
@Override protected IOException newTimeoutException(@Nullable IOException cause) {
...
}
@Override protected void timedOut() {
try {
socket.close();
} catch (Exception e) {
...
}
}
};
}
//Step 2: create the source and wrap the socket getInputStream()
private static Source source(final InputStream in, final Timeout timeout) {
...
return new Source() {
@Override public long read(Buffer sink, long byteCount) throws IOException {
...
try {
...
int bytesRead = in.read(tail.data, tail.limit, maxToCopy);
...
return bytesRead;
} catch (AssertionError e) {
if (isAndroidGetsocknameError(e)) throw new IOException(e);
throw e;
}
}
...
};
}
//The third step is to create a source and wrap the source of the second step, that is, when the source is called externally When read,
//In fact, the second step of read is called,
//The third step of packaging is to add a layer of timeout detection during read
public final Source source(final Source source) {
return new Source() {
@Override public long read(Buffer sink, long byteCount) throws IOException {
boolean throwOnTimeout = false;
//Start timeout detection inside the enter method
enter();
try {
long result = source.read(sink, byteCount);
throwOnTimeout = true;
return result;
} catch (IOException e) {
throw exit(e);
} finally {
//Delete the monitored node after read is completed
exit(throwOnTimeout);
}
}
@Override public void close() throws IOException {
boolean throwOnTimeout = false;
try {
source.close();
throwOnTimeout = true;
} catch (IOException e) {
throw exit(e);
} finally {
exit(throwOnTimeout);
}
}
@Override public Timeout timeout() {
return AsyncTimeout.this;
}
...
};
}
public final void enter() {
if (inQueue) throw new IllegalStateException("Unbalanced enter/exit");
long timeoutNanos = timeoutNanos();
boolean hasDeadline = hasDeadline();
if (timeoutNanos == 0 && !hasDeadline) {
return;
}
inQueue = true;
scheduleTimeout(this, timeoutNanos, hasDeadline);
}
private static synchronized void scheduleTimeout(
AsyncTimeout node, long timeoutNanos, boolean hasDeadline) {
if (head == null) {
head = new AsyncTimeout();
//start monitor
new Watchdog().start();
}
long now = System.nanoTime();
...
node.timeoutAt = now + timeoutNanos;
//It is inserted into the linked list in ascending order of timeout time. The node after the head node is the node about to timeout
//How long will it take to time out
long remainingNanos = node.remainingNanos(now);
for (AsyncTimeout prev = head; true; prev = prev.next) {
if (prev.next == null || remainingNanos < prev.next.remainingNanos(now)) {
node.next = prev.next;
prev.next = node;
if (prev == head) {
//If it is inserted into the head node, wake up the monitor
AsyncTimeout.class.notify();
}
break;
}
}
}
private static final class Watchdog extends Thread {
Watchdog() {
super("Okio Watchdog");
setDaemon(true);
}
public void run() {
while (true) {
try {
AsyncTimeout timedOut;
synchronized (AsyncTimeout.class) {
timedOut = awaitTimeout();
if (timedOut == null) continue;
if (timedOut == head) {
head = null;
return;
}
}
//Indicates that the read timeout closes the socket
timedOut.timedOut();
} catch (InterruptedException ignored) {
}
}
}
}
static @Nullable AsyncTimeout awaitTimeout() throws InterruptedException {
//Obtain the monitored node according to the head node (watchdog)
AsyncTimeout node = head.next;
//If there is no monitored node, wait for IDLE_TIMEOUT_MILLIS seconds (60s).
//If it still does not exist after waiting and the time has exceeded 60s, return to the back node (watchdog) and exit the monitor.
//If it is not empty after waiting, that is, there is a monitored node, null will be returned to continue the next cycle, and the node after the cycle= null.
if (node == null) {
long startNanos = System.nanoTime();
AsyncTimeout.class.wait(IDLE_TIMEOUT_MILLIS);
return head.next == null && (System.nanoTime() - startNanos) >= IDLE_TIMEOUT_NANOS
? head // The idle timeout elapsed.
: null; // The situation has changed.
}
//How long will it expire
long waitNanos = node.remainingNanos(System.nanoTime());
//No timeout yet, wait
if (waitNanos > 0) {
long waitMillis = waitNanos / 1000000L;
waitNanos -= (waitMillis * 1000000L);
AsyncTimeout.class.wait(waitMillis, (int) waitNanos);
//If it is after waiting, it indicates that it has timed out. The next cycle waitnanos < = 0. Follow the code below
//If it is notifyAll, it indicates that a new node has been inserted, and it needs to be judged again
return null;
}
//The monitored node has timed out. Delete the monitored node and return the timedOut() used to call the node externally to close the data flow.
head.next = node.next;
node.next = null;
return node;
}