For a large website, the daily traffic is huge, especially at some specific time points, such as the shopping festival of e-commerce platform and the opening season of education platform. When excessive concurrency is encountered at a certain point in time, it will often crush the server and cause the website to crash. Therefore, the website is very important for high concurrency processing, in which cache plays an important role. For some infrequently changing or hot data, it can be stored in the cache. At this time, when users access, they will directly read the cache without querying the database, which greatly improves the throughput of the website.
Use of cache
First, build a simple test environment, create a SpringBoot application, and write a controller:
@RestController
public class TestController {
@Autowired
private UserService userService;
@GetMapping("/test")
public List<User> test(){
return userService.getUsers();
}
}visit http://localhost:8080/test All user information can be obtained:  We used jmeter to stress test the application and went to the official website: http://jmeter.apache.org/download_jmeter.cgi  Download the zip package locally, extract it, and double-click jmeter.exe in the bin directory Bat to start JMeter:  Here, we simulate the concurrency of 2000 requests in one second to see the throughput of the application:  It is found that the throughput is 421. It is conceivable that when the amount of data in the data table is very large, if all requests need to query the database once, the efficiency will be greatly reduced. Therefore, we can add cache to optimize:
@RestController
public class TestController {
// cache
Map<String, Object> cache = new HashMap<>();
@Autowired
private UserService userService;
@GetMapping("/test")
public List<User> test() {
// Get data from cache
List<User> users = (List<User>) cache.get("users");
if (StringUtils.isEmpty(users)) {
// Unnamed cache, query database
users = userService.getUsers();
// Store the queried data into the cache
cache.put("users",users);
}
// Named cache, direct return
return users;
}
}Here, a cache is simply simulated using HashMap, and the execution process of this interface is as follows:  When the request arrives, first read the data from the cache. If the data is read, it will be returned directly; If it is not read, query the database and store the obtained data in the cache, so that the data in the cache can be read in the next request. Now test the throughput of the application:  It is not difficult to find that the throughput has been significantly improved.
Local cache and distributed cache
Just now, we used the cache to improve the overall performance of the application, but the cache is defined inside the application. This kind of cache is called local cache. Local caching can indeed solve the problem for stand-alone applications, but in distributed applications, one application is often deployed in multiple copies to achieve high availability: 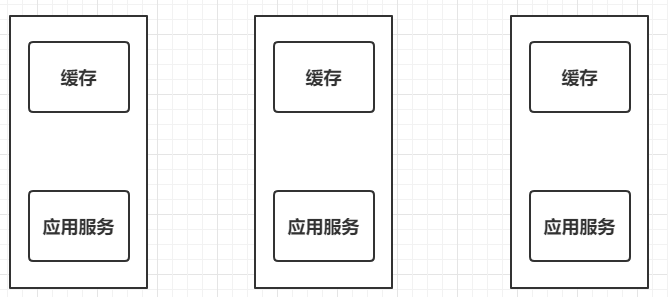 At this time, each application will save its own cache. When modifying data, it is necessary to modify the data in the cache accordingly. However, because there are multiple caches, other caches will not be modified, resulting in data disorder. Therefore, we need to extract the cache to form a cache middleware that is independent of all applications but related to all applications: 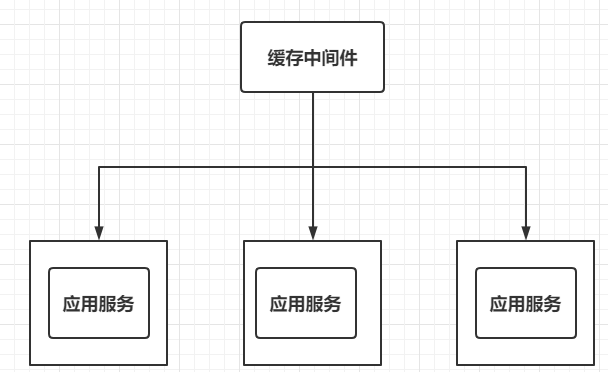 Redis is a popular caching middleware at present.
Spring boot integrates Redis
Next, modify the application just now to use redis cache. First download the redis image:
docker pull redis
Create directory structure:
mkdir -p /mydata/redis/conf touch /mydata/redis/conf/redis.conf
Go to / mydata/redis/conf directory and modify redis Conf file:
appendonly yes # Persistent configuration
Create an instance of redis and start:
docker run -p 6379:6379 --name redis\
-v /mydata/redis/data:/data\
-v /mydata/redis/conf/redis.conf:/etc/redis/redis.conf\
-d redis redis-server /etc/redis/redis.confConfigure the following to enable redis to start with the start of Docker:
docker update redis --restart=always
Here, redis is ready, and then redis dependency is introduced into the project:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>
In application Redis configured in YML:
spring: redis: host: 192.168.66.10
Modify controller code:
@RestControllerpublic class TestController { @Autowired private UserService userService; @Autowired private StringRedisTemplate redisTemplate; @GetMapping("/test") public String test() { // Get data from Redis string usersjson = redistemplate opsForValue(). get("users"); If (stringutils. Isempty (usersjson)) {/ / the cache is not hit. Query the database list < user > users = userservice. Getusers(); / / convert the query result to JSON string usersJson = JSON.toJSONString(users); / / put it into the cache redisTemplate.opsForValue().set("users",usersJson);}// Return result return usersJson;}}Some problems in cache
The use of Redis cache does not mean that you can rest easy. There are still many problems to be solved. The following are three problems that cache middleware often faces:
- Cache penetration
- Cache avalanche
- Buffer breakdown
Cache penetration
Cache penetration refers to querying a certain nonexistent data. Since the cache needs to be queried from the database when it misses, if the data cannot be found, it will not be written to the cache, which will cause the nonexistent data to be queried in the database every request, thus putting pressure on the database. Because caching helps the database share the pressure, but if some people know which data in the system must not exist, it can use this data to send a large number of requests constantly, so as to destroy our system. The solution is to store the data whether it exists or not. For example, if the data required by a request does not exist, the key of the data is still stored so that it can be obtained from the cache during the next request. However, if the key of each request is different, a large number of useless keys will be stored in Redis, Therefore, you should set a specified expiration time for these keys and delete them automatically when they expire.
Cache avalanche
Cache avalanche means that a large number of data in the cache expire at the same time, and the amount of query data is huge, resulting in excessive pressure or even downtime of the database. The solution is to add a random value to the original expiration time of the data, so that the expiration time between the data is inconsistent, and there will be no simultaneous expiration of large quantities of data.
Buffer breakdown
Cache breakdown means that when a hot key expires at a certain point in time, there are a large number of concurrent requests for the key at this point in time, so a large number of requests reach db. The solution is to lock. When a hot key expires, a large number of requests will compete for resources. When a request is successfully executed, other requests need to wait. At this time, the data will be put into the cache after the request is executed, so that other requests can directly obtain data from the cache.
Solve cache breakdown problem
We can easily solve cache penetration and cache avalanche. However, the cache breakdown problem needs to be solved by locking. Let's explore how to solve the cache breakdown problem by locking.
@GetMapping("/test")public String test() { String usersJson = redisTemplate.opsForValue().get("users"); if (StringUtils.isEmpty(usersJson)) { synchronized (this){ // Confirm again whether there is data in the cache string JSON = redistemplate opsForValue(). get("users"); If (stringutils. Isempty (JSON)) {list < user > users = userservice. Getusers(); system. Out. Println ("database queried...); usersJson = JSON.toJSONString(users); }else{ usersJson = json; } redisTemplate.opsForValue().set("users",usersJson); } } return usersJson;}First, you still need to get data from the cache. If the cache is not hit, execute the synchronization code block, and confirm the cached data in the synchronization code block. This is because when a large number of requests enter the outermost if statement at the same time, a request starts to execute and successfully queries the database. However, after the request puts the data into Redis, if it is not judged again, these requests will still query the database. The execution principle is as follows: 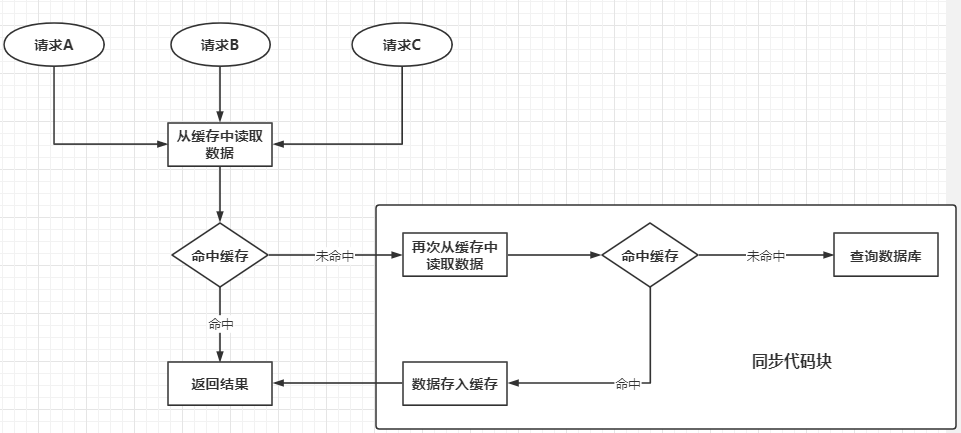 After using jmeter to simulate concurrency 2000 times a second, the results are as follows:
The database was queried......
The console only outputs one query database, It shows that only one of the 2000 requests queries the database, but the performance drops sharply:  This is no problem for stand-alone applications, because the default Bean in SpringBoot is a singleton, and there is no problem locking code blocks through this. However, in distributed applications, an application is often deployed in multiple copies, and this cannot lock the requests of each application. At this time, distributed locks need to be used.
Distributed lock
Like caching middleware, we can extract locks outside, independent of all services, but associated with each service, as shown below: 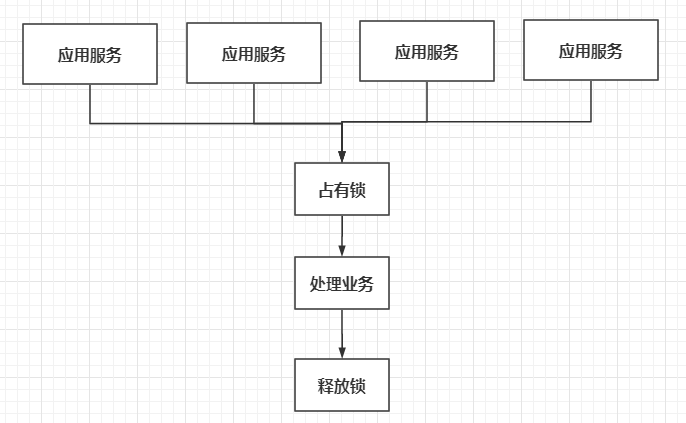
If each service wants to lock, it needs to go to a public place to occupy it. This ensures that even in a distributed environment, the lock of each service is still the same. There are many options in this public place. Redis can be used to implement distributed locks. One instruction in Redis is very suitable for implementing distributed locks. It is setnx. Let's see how it is introduced on the official website:  Setnx will set the value only when the key does not exist, otherwise nothing will be done. For each service, we can let it execute setnx lock 1, because this operation is atomic. Even if there are millions of concurrent requests, only one request can be set successfully, and other requests will fail because the key already exists. If the setting is successful, it indicates that the lock is occupied successfully; If the setting fails, the lock occupation fails.  The code is as follows:
@RestControllerpublic class TestController { @Autowired private UserService userService; @Autowired private StringRedisTemplate redisTemplate; @GetMapping("/test") public String test() throws InterruptedException { String usersJson = redisTemplate.opsForValue().get("users"); if (StringUtils.isEmpty(usersJson)) { usersJson = getUsersJson(); } return usersJson; } public String getUsersJson() throws InterruptedException { String usersJson = ""; // Preempt distributed lock Boolean lock = redistemplate opsForValue(). setIfAbsent("lock", "1"); If (lock) {/ / locking succeeds. / / reconfirm whether there is data in the cache string JSON = redistemplate. Opsforvalue(). Get ("users"); if (stringutils. Isempty (JSON)) {list < user > users = userservice. Getusers(); system. Out. Println ("query database...); usersJson = JSON.toJSONString(users); } else { usersJson = json; } redisTemplate.opsForValue().set("users", usersJson); // Release the lock redistemplate delete("lock"); } Else {/ / lock occupation fails, triggering the retry mechanism Thread.sleep(200); / / repeatedly calling its own getusersjson();} return usersJson; }}Of course, there is still a big problem here. If the program is abnormal before releasing the lock, resulting in code termination and the lock is not released in time, there will be a deadlock problem. The solution is to set the expiration time of the lock while occupying the lock. In this way, even if the program does not release the lock in time, Redis will automatically delete the lock after it expires.
Even if the lock expiration time is set, there will still be new problems. When the execution time of the business is greater than the lock expiration time, the business is not processed at this time, but the lock is deleted by Redis, so that other requests can re occupy the lock and execute the business method. The solution is to make the lock occupied by each request unique, A request cannot delete locks of other requests at will. The code is as follows:
public String getUsersJson() throws InterruptedException { String usersJson = ""; // Preempt distributed lock string UUID = UUID randomUUID(). toString(); Boolean lock = redisTemplate. opsForValue(). setIfAbsent("lock", uuid,300, TimeUnit.SECONDS); If (lock) {/ / locking succeeds. / / reconfirm whether there is data in the cache string JSON = redistemplate. Opsforvalue(). Get ("users"); if (stringutils. Isempty (JSON)) {list < user > users = userservice. Getusers(); system. Out. Println ("query database...); usersJson = JSON.toJSONString(users); } else { usersJson = json; } redisTemplate.opsForValue().set("users", usersJson); // Judge whether the current lock is its own string lockval = redistemplate opsForValue(). get("lock"); If (UUID. Equals (lockval)) {/ / the lock redistemplate. Delete ("lock") can only be released if it is your own lock;}} Else {/ / lock occupation fails. The retry mechanism thread.sleep (200); getusersjson();} return usersJson;}Think about it carefully. There is still a problem here, because when the lock is released, the Java program will send instructions to redis. Redis will return the results to the Java program after execution, which will consume time in the process of network transmission. Suppose that at this time, the Java program obtains the lock value from redis, and redis successfully returns the value, but the lock expires in the return process. At this time, other requests can occupy the lock. At this time, the Java program receives the lock value and finds that it is its own lock, so it performs the deletion operation, but the lock in redis is already the lock of other requests, In this way, there is still a problem that one request deletes the locks of other requests. For this reason, the official website of Redis also provides solutions:  The problem can be solved by executing such a Lua script. The code is as follows:
public String getUsersJson() throws InterruptedException { String usersJson = ""; // Preempt distributed lock string UUID = UUID randomUUID(). toString(); Boolean lock = redisTemplate. opsForValue(). setIfAbsent("lock", uuid,300, TimeUnit.SECONDS); If (lock) {/ / locking succeeds. / / reconfirm whether there is data in the cache string JSON = redistemplate. Opsforvalue(). Get ("users"); if (stringutils. Isempty (JSON)) {list < user > users = userservice. Getusers(); system. Out. Println ("query database...); usersJson = JSON.toJSONString(users); } else { usersJson = json; } redisTemplate.opsForValue().set("users", usersJson); String luaScript = "if redis.call(\"get\",KEYS[1]) == ARGV[1]\n" + "then\n" + " return redis.call(\"del\",KEYS[1])\n" + "else\n" + " return 0\n" + "end"; // Execute script defaultredisscript < long > redisscript = new defaultredisscript < > (luascript, long. Class); List<String> keyList = Arrays. asList("lock"); redisTemplate. execute(redisScript, keyList, uuid); } Else {/ / lock occupation fails. The retry mechanism thread.sleep (200); getusersjson();} return usersJson;}Redisson
Redisson is a Java in memory data grid implemented on the basis of Redis. We can use it to easily implement distributed locks. Firstly, Redisson dependency is introduced:
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.16.0</version></dependency>
Write configuration class:
@Configurationpublic class MyRedissonConfig { @Bean public RedissonClient redissonClient() { Config config = new Config(); config.useSingleServer().setAddress("redis://192.168.66.10:6379"); return Redisson.create(config); }}Write a controller to experience Redisson:
@RestControllerpublic class TestController { @Autowired private RedissonClient redissonClient; @GetMapping("/test") public String test() { // Lock occupied RLOCK lock = reissonclient getLock("my_lock"); // Lock lock(); Try {/ / simulate business processing thread.sleep (1000 * 10);} catch (Exception e) { e.printStackTrace(); } Finally {/ / release lock. Unlock();} return "test"; }}Simply declare the operations of adding and releasing locks. All the previous problems will be solved. Redisson will automatically set the expiration time for the lock, and provides a watchdog to monitor the lock. Its function is to continuously extend the expiration time of the lock before the redisson instance is closed, If the thread of the lock has not finished processing the business (by default, the watchdog renewal time is 30 seconds). You can also specify the expiration time of the lock:
lock.lock(15, TimeUnit.SECONDS);
Set the time when locking.
When the lock expiration time is set to 15 seconds, if the business execution takes more than 15 seconds, will Redis automatically delete the lock and request to preempt the lock? In fact, this situation still exists, so we should avoid setting too small expiration time, and make sure that the expiration time of the lock is greater than the execution time of the business.
Redisson can also easily implement read-write locks, such as:
@RestControllerpublic class TestController { @Autowired private StringRedisTemplate redisTemplate; @Autowired private RedissonClient redissonClient; @GetMapping("/write") public String write() { RReadWriteLock wrLock = redissonClient.getReadWriteLock("wr_lock"); // Get write lock RLOCK wlock = wrlock writeLock(); // Lock wlock lock(); String uuid = ""; Try {UUID = UUID. Randomuuid(). Tostring(); thread. Sleep (20 * 1000); / / store in redis redistemplate. Opsforvalue(). Set ("UUID", UUID);} catch (InterruptedException e) { e.printStackTrace(); } Finally {/ / release lock wlock. Unlock();} return uuid; } @ Getmapping ("/ read") public string read() {rreadwritelock wrlock = redissonclient.getreadwritelock ("wr_lock"); / / get read lock RLock rLock = wrLock.readLock(); / / lock RLOCK. Lock(); string UUID = ""; try {/ / read UUID UUID = redistemplate. Opsforvalue(). Get ("UUID") ; } Finally {/ / release lock RLOCK. Unlock();} return uuid; }}As long as the read-write lock uses the same lock, the read operation must wait during the write operation, and the write lock is a mutually exclusive lock. When a thread is writing, other threads must wait in line; Read / write is a shared lock. All threads can read directly, so that the latest data can be read every time.
Cache consistency
Although the use of cache improves the system throughput, it also brings a problem. When there is data in the cache, the data will be taken directly from the cache. However, if the data in the database is modified, the user still reads the data in the cache, which leads to the problem of data inconsistency, There are generally two solutions:
- Double write mode: modify the cache while modifying the database
- Failure mode: delete the cache directly after modifying the database
Double write mode can cause dirty data problems, as shown below: 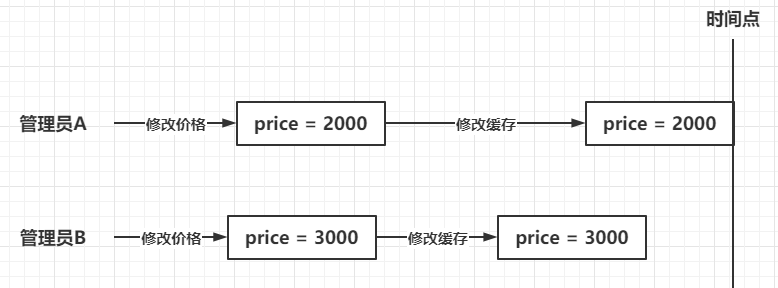 When administrators A and B modify the price of A commodity, administrator A submits it first and administrator B submits it later. It should be that administrator B's write cache operation takes effect. However, due to unknown conditions such as network fluctuations, administrator A's write cache operation takes effect, while administrator B's write cache operation takes effect, and finally the data in the cache becomes 2000, This leads to the generation of dirty data, but this kind of dirty data is only temporary, because the data in the database is correct, so after the cache expires, re query the database, and the data in the cache will be normal. The problem is how to ensure the data consistency in the double write mode. The solution is to lock the operation of modifying the database and modifying the cache, making it an atomic operation.
Failure modes can also lead to dirty data. Therefore, for frequently modified data, you should query the database directly instead of caching.
To sum up, the general solution is: set the expiration time for all cached data, so that when the cache expires, a database query can be triggered to update the cache; When reading and writing data, Redisson is used to add read-write locks to ensure the atomicity of write operations.