Tencent cloud database MongoDB naturally supports functions such as high availability, distribution, high performance, high compression, schema free and perfect client access balancing strategy. Based on the advantages of MongoDB, a key user in the cloud selects MongoDB as the primary storage service. The user's business scenario is as follows:
·Store core data of e-commerce business
·The query conditions are changeable, the query is not fixed, the query is complex, and there are many query combinations
·High performance requirements
·Requirements for storage costs
·Traffic proportion: less insert s, more update s, more find s and higher peak traffic
·Peak read / write traffic thousands / sec
After communicating with the business, understanding the business usage scenarios and business requirements, and through a series of index optimization, the read-write performance bottleneck problem is finally solved perfectly. This paper focuses on the analysis of the index optimization process of the core business. Through this paper, we can learn the following knowledge points:
·How to determine useless indexes?
·How to determine duplicate indexes?
·How to create an optimal index?
·Some misconceptions about index?
·Index optimization benefits (save more than 90% CPU resources, 85% disk IO resources and 20% storage costs)
Problem analysis process
After receiving the feedback of user cluster performance bottleneck, the following phenomena can be seen from the cluster monitoring information and server monitoring information:
·The CPU consumption of Mongod node is too high, and the CPU consumption is close to 90% or even 100% from time to time
·Disk IO consumption is too high, and single node IO resource consumption accounts for 60% of the whole server
·A large number of slow logs (mainly focused on find and update), with thousands of slow logs per second at the peak
·Slow logs have different types and many query conditions
·All slow queries have matching indexes
Log in to the background of the corresponding node of the server, get the slow log information and find mongod The log contains a large number of slow logs of different types of find and update. All slow logs have indexes. Any slow log can be extracted as follows:
Mon Aug 2 10:34:24.928 I COMMAND [conn10480929] command xxx.xxx command: find { find: "xxx", filter: { $and: [ { alxxxId: "xxx" }, { state: 0 }, { itemTagList: { $in: [ xx ] } }, { persxxal: 0 } ] }, limit: 3, maxTimeMS: 10000 } planSummary: IXSCAN { alxxxId: 1.0, itemTagList: 1.0 } keysExamined:1650 docsExamined:1650 hasSortStage:0 cursorExhausted:1 keyUpdates:0 writeConflicts:0 numYields:15 nreturned:3 reslen:8129 locks:{ Global: { acquireCount: { r: 32 } }, Database: { acquireCount: { r: 16 } }, Collection: { acquireCount: { r: 16 } } } protocol:op_command 227ms
Mon Aug 2 10:34:22.965 I COMMAND [conn10301893] command xx.txxx command: find { find: "txxitem", filter: { $and: [ { itxxxId: "xxxx" }, { state: 0 }, { itemTagList: { $in: [ xxx ] } }, { persxxal: 0 } ] }, limit: 3, maxTimeMS: 10000 } planSummary: IXSCAN { alxxxId: 1.0, itemTagList: 1.0 } keysExamined:1498 docsExamined:1498 hasSortStage:0 cursorExhausted:1 keyUpdates:0 writeConflicts:0 numYields:12 nreturned:3 reslen:8039 locks:{ Global: { acquireCount: { r: 26 } }, Database: { acquireCount: { r: 13 } }, Collection: { acquireCount: { r: 13 } } } protocol:op_command 158ms It can be seen from the above log printing that the query has a {alxxid: 1.0, itemtaglist: 1.0} index. The keysExamined scanned by the index is 1498 lines, and the docsExamined scanned is 1498 lines, but the number of doc documents returned is only nreturned=3 lines.
It can be seen from the above log core information that only 3 pieces of data meet the conditions, but 1498 rows of data and indexes are scanned, indicating that the query has indexes, but not all of them are optimal.
Get user SQL query model and existing index information
The above analysis can determine that the problem is that the index is not optimal, and a large number of queries find a lot of useless data.
3.1. Contact with users to understand the user SQL model
Through communication with users, the collected user queries and updates mainly involve the following SQL types:
·Common query and update SQL
Based on alxxid (user ID) + itxxid (single or multiple)
Query count based on alxid
Paging queries are performed through the time range (createTime) based on alxd, and some queries will splice state and other fields
Combined query based on alxxid, parentalxxid, parentitxxid and state
Query data based on itxxid (single or multiple)
Combined query based on alxid, state and Updatetime
Combined query based on alxd, state, createtime and totalstock
Based on alxxid (user ID) + itxxid (single or multiple) + any other field combination
Query based on alxxid, digitalxxrmarkid (watermark ID) and state
Query based on alxxid, itemtaglist (tag ID), state, etc
Query based on alxxid + itxxid (single or multiple) + any other field
Other queries
·Statistics class count query SQL
Alxxid, state, persxxal combination
Alxxid, state, itemType combination
Alxxid (user ID) + itxxid (single or multiple) + any other field combination
3.2. Get the existing index of the cluster
Pass dB xxx. Getindex ({}) obtains the index information of the table as follows, with a total of 30 indexes:
{ "alxxxId" : 1, "state" : -1, "updateTime" : -1, "itxxxId" : -1, "persxxal" : 1, "srcItxxxId" : -1 }
{ "alxxxId" : 1, "image" : 1 }
{ "itexxxList.vidxxCheck" : 1, "itemType" : 1, "state" : 1 }
{ "alxxxId" : 1, "state" : -1, "newsendTime" : -1, "itxxxId" : 1, "persxxal" : 1 }
{ "_id" : 1 }
{ "alxxxId" : 1, "createTime" : -1, "checkStatus" : 1 }
{ "alxxxId" : 1, "parentItxxxId" : -1, "state" : -1, "updateTime" : -1, "persxxal" : 1, "srcItxxxId" : -1 }
{ "alxxxId" : 1, "state" : -1, "parentItxxxId" : 1, "updateTime" : -1, "persxxal" : -1 }
{ "srcItxxxId" : 1 }
{ "createTime" : 1 }
{ "itexxxList.boyunState" : -1, "itexxxList.wozhituUploadServerId": -1, "itexxxList.photoQiniuUrl" : 1, "itexxxList.sourceType" : 1 }
{ "alxxxId" : 1, "state" : 1, "digitalxxxrmarkId" : 1, "updateTime" : -1 }
{ "itxxxId" : -1 }
{ "alxxxId" : 1, "parentItxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 }
{ "alxxxId" : 1, "videoCover" : 1 }
{ "alxxxId" : 1, "itemType" : 1 }
{ "alxxxId" : 1, "state" : -1, "itemType" : 1, "persxxal" : 1, "updateTime" : 1 }
{ "alxxxId" : 1, "itxxxId" : 1 }
{ "itxxxId" : 1, "alxxxId" : 1 }
{ "alxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 }
{ "alxxxId" : 1, "itemTagList" : 1 }
{ "itexxxList.photoQiniuUrl" : 1, "itexxxList.boyunState" : -1, "itexxxList.sourceType" : 1, "itexxxList.wozhituUploadServerId" : -1 }
{ "alxxxId" : 1, "parentItxxxId" : 1, "state" : 1 }
{ "alxxxId" : 1, "parentItxxxId" : 1, "updateTime" : 1 }
{ "updateTime" : 1 }
{ "itemPhoxxIdList" : -1 }
{ "alxxxId" : 1, "state" : -1, "isTop" : 1 }
{ "alxxxId" : 1, "state" : 1, "itemResxxxIdList" : 1, "updateTime" : -1 }
{ "alxxxId" : 1, "state" : -1, "itexxxList.photoQiniuUrl" : 1 }
{ "itexxxList.qiniuStatus" : 1, "itexxxList.photoNetUrl" : 1, "itexxxList.photoQiniuUrl" : 1 }
{ "itemResxxxIdList" : 1 }Index optimization process
As can be seen from the previous section, the cluster has complex queries and many indexes. By analyzing the existing indexes and user data model, the existing indexes are optimized as follows, and finally the number of effective indexes is reduced to 8.
4.1. The first round of Optimization: delete useless indexes
MongoDB provides an index statistics command by default to obtain the number of hits of each index. The command is as follows:
> db.xxxxx.aggregate({"$indexStats":{}})
{ "name" : "alxxxId_1_parentItxxxId_1_parentAlxxxId_1", "key" : { "alxxxId" : 1, "parentItxxxId" : 1, "parentAlxxxId" : 1 },"host" : "TENCENT64.site:7014", "accesses" : { "ops" : NumberLong(11236765),"since" : ISODate("2020-08-17T06:39:43.840Z") } }The information of several core indicators in the aggregate output is shown in the following table:
Field content
explain
name
The index name represents the statistics of that index.
ops
The number of index hits, that is, the number of times this index is used as the query index in all queries.
ops in the above table represents the number of hits. If the number of hits is 0 or very small, it means that the index is rarely selected as the best index. Therefore, the task can be a useless index and can be deleted directly.
Get the index statistics of the user's core table, as follows:
db.xxx.aggregate({"$indexStats":{}})
{ "alxxxId" : 1, "state" : -1, "updateTime" : -1, "itxxxId" : -1, "persxxal" : 1, "srcItxxxId" : -1 } "ops" : NumberLong(88518502)
{ "alxxxId" : 1, "image" : 1 } "ops" : NumberLong(293104)
{ "itexxxList.vidxxCheck" : 1, "itemType" : 1, "state" : 1 } "ops" : NumberLong(0)
{ "alxxxId" : 1, "state" : -1, "newsendTime" : -1, "itxxxId" : -1, "persxxal" : 1 } "ops" : NumberLong(33361216)
{ "_id" : 1 } "ops" : NumberLong(3987)
{ "alxxxId" : 1, "createTime" : 1, "checkStatus" : 1 } "ops" : NumberLong(20042796)
{ "alxxxId" : 1, "parentItxxxId" : -1, "state" : -1, "updateTime" : -1, "persxxal" : 1, "srcItxxxId" : -1 } "ops" : NumberLong(43042796)
{ "alxxxId" : 1, "state" : -1, "parentItxxxId" : 1, "updateTime" : -1, "persxxal" : -1 } "ops" : NumberLong(3042796)
{ "itxxxId" : -1 } "ops" : NumberLong(38854593)
{ "srcItxxxId" : -1 } "ops" : NumberLong(0)
{ "createTime" : 1 } "ops" : NumberLong(62)
{ "itexxxList.boyunState" : -1, "itexxxList.wozhituUploadServerId" : -1, "itexxxList.photoQiniuUrl" : 1, "itexxxList.sourceType" : 1 } "ops" : NumberLong(0)
{ "alxxxId" : 1, "state" : 1, "digitalxxxrmarkId" : 1, "updateTime" : -1 } "ops" : NumberLong(140238342)
{ "itxxxId" : -1 } "ops" : NumberLong(38854593)
{ "alxxxId" : 1, "parentItxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 } "ops" : NumberLong(132237254)
{ "alxxxId" : 1, "videoCover" : 1 } { "ops" : NumberLong(2921857)
{ "alxxxId" : 1, "itemType" : 1 } { "ops" : NumberLong(457)
{ "alxxxId" : 1, "state" : -1, "itemType" : 1, "persxxal" : 1, " itxxxId " : 1 } "ops" : NumberLong(68730734)
{ "alxxxId" : 1, "itxxxId" : 1 } "ops" : NumberLong(232360252)
{ "itxxxId" : 1, "alxxxId" : 1 } "ops" : NumberLong(145640252)
{ "alxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 } "ops" : NumberLong(689891)
{ "alxxxId" : 1, "itemTagList" : 1 } "ops" : NumberLong(2898693682)
{ "itexxxList.photoQiniuUrl" : 1, "itexxxList.boyunState" : 1, "itexxxList.sourceType" : 1, "itexxxList.wozhituUploadServerId" : 1 } "ops" : NumberLong(511303207)
{ "alxxxId" : 1, "parentItxxxId" : 1, "state" : 1 } "ops" : NumberLong(0)
{ "alxxxId" : 1, "parentItxxxId" : 1, "updateTime" : 1 } "ops" : NumberLong(0)
{ "updateTime" : 1 } "ops" : NumberLong(1397)
{ "itemPhoxxIdList" : -1 } "ops" : NumberLong(0)
{ "alxxxId" : 1, "state" : -1, "isTop" : 1 } "ops" : NumberLong(213305)
{ "alxxxId" : 1, "state" : 1, "itemResxxxIdList" : 1, "updateTime" : 1 } "ops" : NumberLong(2591780)
{ "alxxxId" : 1, "state" : 1, "itexxxList.photoQiniuUrl" : 1} "ops" : NumberLong(23505)
{ "itexxxList.qiniuStatus" : 1, "itexxxList.photoNetUrl" : 1, "itexxxList.photoQiniuUrl" : 1 } "ops" : NumberLong(0)
{ "itemResxxxIdList" : 1 } "ops" : NumberLong(7)
The service has been running for a period of time. First, delete the index with ops less than 10000. The index that meets this condition is like the index in the red part above.
After 11 useless indexes are deleted in this round, there are 30-11 = 19 useful indexes left.
4.2. The second round of Optimization: delete duplicate indexes
Duplicate indexes mainly include the following categories:
·Index duplication caused by query order
For example, the following two types of queries are written for different business development:
db.xxxx.find({{ "alxxxId" : xxx, "itxxxId" : xxx }})
db.xxxx.find({{ " itxxxId " : xxx, " alxxxId " : xxx }})To cope with these two SQL queries, DBA creates two indexes:
{ alxxxId :1, itxxxId:1 }and{ itxxxId :1, alxxxId:1}These two SQL can actually create any index without two indexes, so this is a useless index.
·Index duplication caused by leftmost principle matching
For example, the following three indexes have duplicate indexes:
{itxxid: 1, alxxid: 1} and {itxxid: 1} are two indexes, {itxxid: 1} is a duplicate index.
·Duplicate index caused by inclusion relationship
For example, the following two indexes above are duplicate indexes:
{ "alxxxId" : 1, "parentItxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 }
{ "alxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 }
{ "alxxxId" : 1, " state " : 1 }Confirm with the user that the user created these three indexes because of the following three queries:
Db.xxx.find({ "alxxxId" : xxx, "parentItxxxId" : xx, "parentAlxxxId" : xxx, "state" : xxx })
Db.xxx.find({ "alxxxId" : xxx, " parentAlxxxId " : xx, " state " : xxx })
Db.xxx.find({ "alxxxId" : xxx, " state " : xxx })These queries contain common fields, so they can be combined into one index to meet these two types of SQL queries. The combined index is as follows:
{ "alxxxId" : 1, " state " : 1, " parentAlxxxId " : 1, parentItxxxId :1}After optimization based on the above indexing principles, the following indexes can be optimized. The indexes before optimization:
{ itxxxId:1, alxxxId:1 }
{ alxxxId:1, itxxxId:1 }
{itxxxId:1 }
{ "alxxxId" : 1, "parentItxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 }
{ "alxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 }
{ "alxxxId" : 1, " state " : 1 }These six indexes can be combined and optimized into the following two indexes:
{ itxxxId:1, alxxxId:1 }
{ "alxxxId" : 1, "parentItxxxId" : 1, "parentAlxxxId" : 1, "state" : 1 }4.3. The third round of Optimization: obtain the data model and eliminate the useless indexes caused by the unique index
By analyzing the combination of each field module of the data in the table, it is found that alxxid and itxxid fields are high-frequency fields. By analyzing the field schema information and randomly extracting part of the data, it is found that the combination of these two fields is unique. So confirm with the user that any combination of these two fields represents a unique piece of data.
If the {alxxid: 1, itxxid: 1} index can determine uniqueness, the combination of these two fields and any field is unique. Therefore, the following indexes can be combined into one index:
{ "alxxxId" : 1, "state" : -1, "updateTime" : -1, "itxxxId" : 1, "persxxal" : 1, "srcItxxxId" : -1 }
{ "alxxxId" : 1, "state" : -1, "itemType" : 1, "persxxal" : 1, " itxxxId " : 1 }
{ "alxxxId" : 1, "state" : -1, "newsendTime" : -1, "itxxxId" : 1, "persxxal" : 1 }
{ "alxxxId" : 1, "state" : 1, "itxxxId" : 1, "updateTime" : -1 }
{ itxxxId:1, alxxxId:1 }The above five indexes can be de merged into the following index: {itxxid: 1, alxxid: 1}
4.4. The fourth round of Optimization: useless duplicate index optimization caused by non equivalent queries
From the previous 30 indexes, we can see that some of the indexes are time type fields, such as createTime and updateTime. These fields are generally used for range queries. After confirming with the user, these fields are indeed used for various range queries. Because the range query is a non equivalent query, if the range query field appears in front of the index field, the following fields cannot be indexed, such as the following query and index:
db.collection.find({{ "alxxxId" : xx, "parentItxxxId" : xx, "state" : xx, "updateTime" : {$gt: xxxxx}, "persxxal" : xxx, "srcItxxxId" : xxx } })
db.collection.find({{ "alxxxId" : xx, "state" : xx, "parentItxxxId" : xx, "updateTime" : {$lt: xxxxx}, "persxxal" : xxx} })The user added the following two indexes to these two queries:
The first index is as follows:
{ "alxxxId" : 1, "parentItxxxId" : -1, "state" : -1, "updateTime" : -1, "persxxal" : 1, "srcItxxxId" : -1 }
The second index is as follows:
{ "alxxxId" : 1, "state" : -1, "parentItxxxId" : 1, "updateTime" : -1, "persxxal" : -1 }Since both queries contain the updateTime field, a range query is performed. Since all fields except the updateTime field are equivalent queries, the fields on the right of updateTime in the above two queries cannot be indexed. That is, the persxxal and srcitxxid fields of the first index above cannot match the index, and the persxxal field of the second index cannot match the index.
At the same time, since the two index fields are basically the same, in order to better ensure that more fields go through the index, it can be combined and optimized into the following index to ensure that more fields can go through the index:
{ "alxxxId" : 1, "state" : -1, "parentItxxxId" : 1, "persxxal" : -1, "updateTime" : -1 }4.5. The fifth round of Optimization: remove the corresponding indexes of fields with low query frequency
When deleting useless indexes in the first round of optimization, indexes with a hit rate of less than 10000 times are filtered out. However, compared with the high frequency hits (billions of hits), some indexes also have relatively low hits (only hundreds of thousands of hits). The indexes of low frequency hits are as follows:
{ "alxxxId" : 1, "image" : 1 } "ops" : NumberLong(293104)
{ "alxxxId" : 1, "videoCover" : 1 } "ops" : NumberLong(292857) Lower the delay threshold of slow logs and analyze the logs corresponding to these two queries, as follows:
Mon Aug 2 10:56:46.533 I COMMAND [conn5491176] command xxxx.tbxxxxx command: count { count: "xxxxx", query: { alxxxId: "xxxxxx", itxxxId: "xxxxx", image: "http:/xxxxxxxxxxx/xxxxx.jpg" }, limit: 1 } planSummary: IXSCAN { itxxxId: 1.0,alxxxId:1.0 } keyUpdates:0 writeConflicts:0 numYields:1 reslen:62 locks:{ Global: { acquireCount: { r: 4 } }, Database: { acquireCount: { r: 2 } }, Collection: { acquireCount: { r: 2 } } } protocol:op_query 4ms
Mon Aug 2 10:47:53.262 I COMMAND [conn10428265] command xxxx.tbxxxxx command: find { find: "xxxxx", filter: { $and: [ { alxxxId: "xxxxxxx" }, { state: 0 }, { itemTagList: { $size: 0 } } ] }, limit: 1, singleBatch: true } planSummary: IXSCAN { alxxxId: 1, videoCover: 1 } keysExamined:128 docsExamined:128 cursorExhausted:1 keyUpdates:0 writeConflicts:0 numYields:22 nreturned:0 reslen:108 locks:{ Global:{ acquireCount: { r: 46 } }, Database: { acquireCount: { r: 23 } }, Collection: { acquireCount: { r: 23 } } } protocol:op_command 148ms Analyzing the log, it is found that the image in the user request is queried in combination with alxxid and itxxid. As mentioned earlier, alxxid and itxxid are unique. It can also be seen from the query plan that the image field is not indexed at all. Therefore, the {"alxd": 1, "ixxge": 1} index can be deleted.
Similarly, by analyzing the log, it is found that the user query criteria do not carry videoCover, but some queries go through the {alxxid: 1, videoCover: 1} index, and keysExamined and docsExamined are different from nreturned, so it can be confirmed that only the alxxid index field is actually matched. Therefore, the index {alxxid: 1, videoCover: 1} can be deleted.
4.6. The sixth round of Optimization: analyze the log high-frequency query and add the optimal index of high-frequency query
Lower the log threshold, analyze the query for a period of time through mtools tool, and obtain the following hot spot query information:
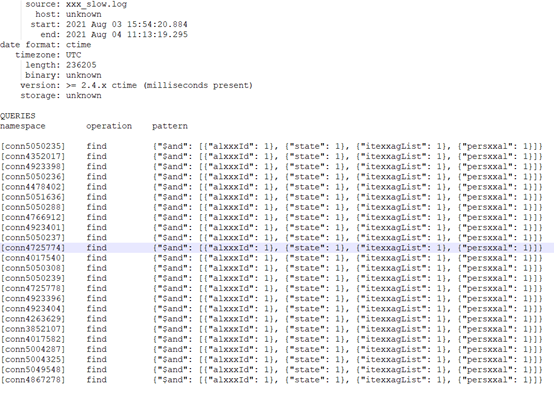
Make sure that this part of the query takes up almost 99% of the hot spots. Analyze the corresponding logs of such queries and get the following information:
Mon Aug 2 10:47:58.015 I COMMAND [conn4352017] command xxxx.xxx command: find { find: "xxxxx", filter: { $and: [ { alxxxId:"xxxxx" }, { state: 0 }, { itemTagList: { $in: [ xxxxx ] } }, { persxxal: 0 } ] }, projection: { $sortKey: { $meta: "sortKey" } }, sort: { updateTime: 1 }, limit: 3, maxTimeMS: 10000 } planSummary: IXSCAN { alxxxId: 1.0, itexxagList: 1.0 } keysExamined:1327 docsExamined:1327 hasSortStage:1 cursorExhausted:1 keyUpdates:0 writeConflicts:0 numYields:23 nreturned:3 reslen:12036 locks:{ Global: { acquireCount: { r: 48 } }, Database: { acquireCount: { r: 24 } }, Collection: { acquireCount: { r: 24 } } } protocol:op_command 151ms As can be seen from the above log, there is a big gap between the number of data rows scanned by the high-frequency query and the number of data rows finally returned. 1327 rows were scanned, and finally only 3 pieces of data were obtained. The path is {alxxid: 1.0, itexxaglist: 1.0}
Index, which is not the optimal index. The index of the query is 1.xl: xlist. The index of the query is 1.xl: xlist. The index of the query is 1.xl: 0, and the index of the query is 1.xlist: 0. The index of the query is 1.xlist: 0
In addition, it can be seen from the log that the high-frequency query actually has a sort sort and limit limit limit. The original SQL of the whole query is as follows:
db.xxx.find({ $and: [ { alxxxId:"xxxx" }, { state: 0 }, { itexxagList: { $in: [ xxxx ] } },{ persxxal: 0 } ] }).sort({updateTime:1}).limit(3) The query model is ordinary multi field equivalent query + sort sort query + limit limit limit. The optimal index of this kind of query may be one of the following two indexes:
·Index 1: corresponding index of common multi field equivalent query
The following SQL query criteria in the corresponding query:
{ $and: [ { alxxxId:"xxx" }, { state: 0 }, { itexxagList: { $in: [ xxxx ] } }, { persxxal: 0 } ] }The four fields of the SQL are equivalent queries, and the optimal index is created according to the hash degree. The more the hash value is placed on the far left, the following optimal index can be obtained:
{ alxxxId: 1.0, itexxagList: 1.0 , persxxal:1.0, stat:1.0}If this index is selected as the optimal index, the execution process of the whole ordinary multi field equivalent query + sort sort sort query + limit limit query is as follows:
- Find all data that meet the conditions of {and: [{alxxxid: "XXXX"}, {state: 0}, {itexxaglist: {in: [XXXX]}}, {persxxal: 0}}} through the {alxxxid: 1.0, itexxaglist: 1.0, persxxal: 1.0, stat: 1.0} index.
- Sort these qualified data in memory
- Take the first three sorted data
·Index 2: Sort sort corresponds to the optimal index
Since the query contains limit, it is possible to directly use the {updateTime:1} sorting index to find three pieces of data that meet the following query conditions:
{ $and: [ { alxxxId:"xxxx" }, { state: 0 }, { itexxagList: { $in: [ xxxx ] } },
{ persxxal: 0 } ] }The whole ordinary multi field equivalent query + sort sort sort query + limit limit query corresponds to the index. The selection of index 1 and index 2 has a great relationship with the data distribution. Since the query is an ultra-high frequency query, it is recommended to add two indexes to this kind of SQL. The MongoDB kernel decides which index to choose as the optimal index according to the actual query conditions and data distribution, The corresponding indexes of the high-frequency query are as follows:
{ alxxxId: 1.0, itexxagList: 1.0 , persxxal:1.0, stat:1.0}
{updateTime:1}4.7. Summary
After the first six rounds of optimization, only the following 8 indexes are retained:
{ "itxxxId" : 1, "alxxxId" : 1 }
{ "alxxxId" : 1, "state" : 1, "digitalxxxrmarkId" : 1, "updateTime" : 1 }
{ "alxxxId" : 1, "state" : -1, "parentItxxxId" : 1, "persxxal" : -1, "updateTime" : 1 }
{ "alxxxId" : 1, "itexxxList.photoQiniuUrl" : 1, }
{ "alxxxId" : 1, "parentAlxxxId" : 1, "state" : 1"parentItxxxId" : 1}
{ alxxxId: 1.0, itexxagList: 1.0 , persxxal:1.0, stat:1.0}
{updateTime:1}
{ "alxxxId" : 1,"createTime" : -1}Index optimization benefits
After a series of index optimization, the final index is reduced to 8, and the overall income is very detailed. The main income is as follows:
·Save more than 90% CPU resources
The peak CPU consumption decreased from more than 90% before to less than 10% after optimization
·Save about 85% of disk IO resources
Disk IO consumption is reduced from 60% - 70% to less than 10%
·Save 20% disk storage costs
Since each index corresponds to a disk index file, the number of indexes is reduced from 30 to 8, and the final real disk consumption of data + index is reduced by about 20%.
·Slow logs reduced by 99%
Before index optimization, there are thousands of slow logs per second, and after optimization, the number of slow logs is reduced to dozens. Optimization is mainly caused by the count requirement of slow logs. It is normal that there are too many data that meet the conditions.
Finally, the index plays a vital role in the query performance of MongoDB database. Meeting the query needs of users with the least index will greatly improve the database performance and reduce the storage cost. Tencent cloud DBbrain for MongoDB perfectly realizes index intelligent recommendation based on SQL classification + index rules + cost calculation. In the next issue, we will share Tencent cloud index recommendation scheme and implementation details.
Author: Tencent cloud MongoDB team
Tencent cloud mongodb currently serves many industries such as games, e-commerce, social networking, education, news and information, finance, Internet of things, software services and so on; Mongodb team (cmongo for short) is committed to in-depth research and continuous optimization of the open source mongodb kernel (such as millions of database tables, physical backup, confidentiality free, audit, etc.), so as to provide users with secure database storage services with high performance, low cost and high availability. In the follow-up, we will continue to share the typical application scenarios, pit stepping cases, performance optimization and kernel modularization analysis of mongodb inside and outside Tencent.