catalogue
1, Basic process of text generation and Translation
Training and decoding of translation models
Training and decoding of generation class model (GPT Series)
4. Top-K Sampling and Top-p (nucleus) sampling
The effect of text generation and text translation lies not only in the quality of the model level, but also in the decoding strategy in the prediction stage. Different decoding strategies have different effects. After years of research by scholars, as far as I know, the decoding strategies related to text generation mainly include greedy search and beam_search cluster search, random sampling, top-k sampling and Top-p Sampling. Today we mainly talk about these text decoding strategies and algorithms.
1, Basic process of text generation and Translation
Training and decoding of translation models
Training process
The process of translation task is that one src input corresponds to one tag input. Generally speaking, the length of src is different from that of tag; A simple flow chart is shown in the figure below:
The result of model training is a vector with the same length as tag. output[T,B,D] passes through a classification full connection layer to obtain the probability distribution of [T,B], which is calculated as the loss of tag input [T,B];
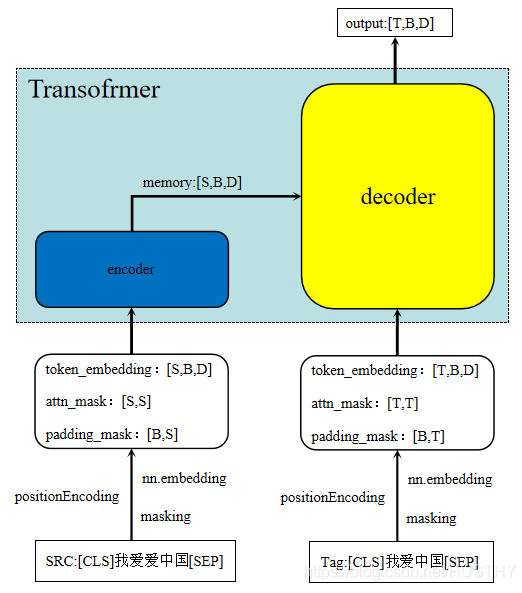
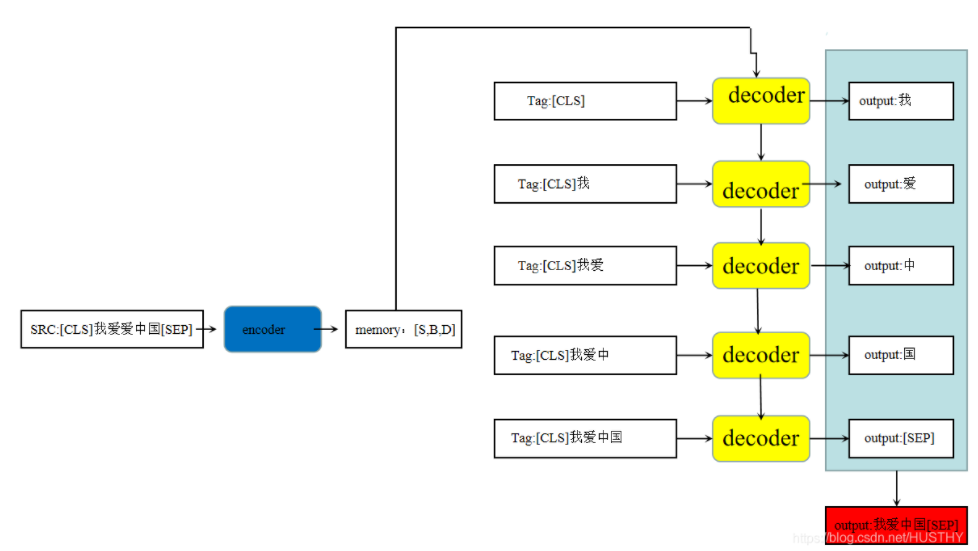
Decoding process
As shown in the figure below, after the model is trained, the initial decoding is the embedding of src plus the starting character < CLS > and other special characters at the tag end. The decoding output obtains the first character token, and then add this token to the tag end input, and continue decoding to obtain the second token Repeated decoding, each decoding requires a model reasoning, so it is time-consuming; Only the end character or the maximum length is encountered.
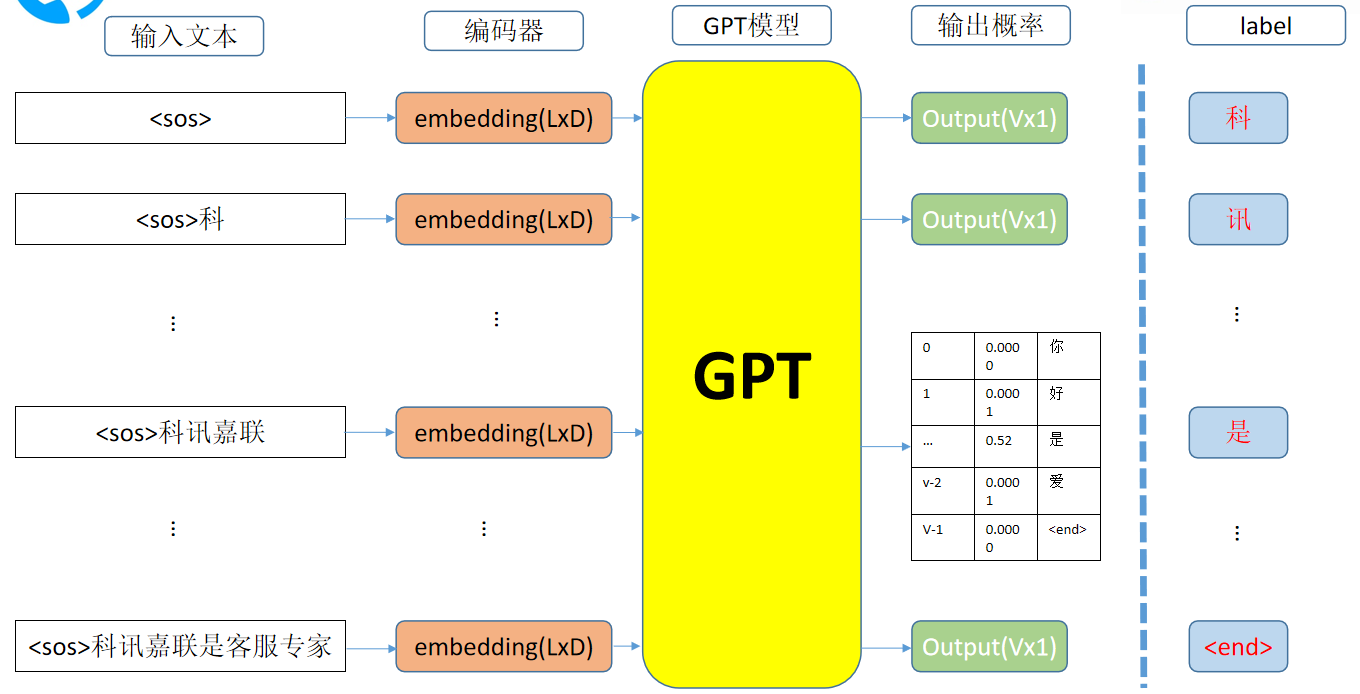
Training and decoding of generation class model (GPT Series)
Training process
The training process of GPT model directly inputs a natural text, then outputs its embedding, and then passes through a classifier to get logits[B,L,V]; At the same time, the input text is used as a label to calculate the cross entropy loss. The input of the model is inputs [b, l] ---- > embedding [b, l, D] ---- > logits[B,L,V].
Decoding process
Similar to the above, the current decoding result token and the previous tokens are combined as input to decode the next token.
2, Decoding strategy
The above schematic diagram briefly explains the model training and decoding process of generation tasks and the changes of vector dimensions in the middle. The final decoding result is related to the model itself and what decoding strategy is adopted.
1. Greedy search
The probability distribution obtained in the prediction stage, after connecting the whole connection layer, can obtain a sequence of probability distribution [(B*S),vocab_size] - meaning the probability distribution of each word on the thesaurus, with a total of B*S words. How to get the most reasonable sequence through this probability distribution. A very intuitive approach is to take the possibility of its maximum probability from the probability distribution of each word until the whole sequence is completed or the terminator [SEP] is found. Simple implementation, the code is as follows:
def gen_nopeek_mask(length):
"""
Returns the nopeek mask
Parameters:
length (int): Number of tokens in each sentence in the target batch
Returns:
mask (arr): tgt_mask, looks like [[0., -inf, -inf],
[0., 0., -inf],
[0., 0., 0.]]
"""
mask = torch.triu(torch.ones(length, length))
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def greedy_search_decode(model, src,src_key_padding_mask, max_len:int = 64, start_symbol:int = 1):
"""
:param model: Transformer model
:param src: the encoder input
:param max_len: Maximum length of sequence
:return:ys This is the specific sequence of prediction
When decoding, these mask It can't be less
"""
src_mask = gen_nopeek_mask(src.shape[1]).to(device)
memory_key_padding_mask = src_key_padding_mask
#The first character [CLS] is 1 in the thesaurus
ys = torch.ones(1, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len-1):
tar_mask = gen_nopeek_mask(ys.shape[1]).to(device)
out = model.forward(src, ys, src_key_padding_mask=src_key_padding_mask, tgt_key_padding_mask=None,src_mask=src_mask,tar_mask=tar_mask,memory_key_padding_mask=memory_key_padding_mask)
#The prediction result is out, and the last probability distribution is selected
out = out[:,-1,:]
#The index that gets the maximum probability is the index of the predicted word in the thesaurus
_, next_word = torch.max(out, dim=1)
next_word = next_word.data[0]
if next_word != 2:
#If the terminator [SEP] is not predicted
#Combine the results of this prediction with the previous results cat, and repeat the cyclic iterative prediction again
ys = torch.cat([ys, torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1)
else:
break
return ysThe defect of the above implementation is that it cannot decode batch > 1 in parallel. It can be appropriately modified to adapt to parallel processing. After each decoding of the data in each batch, make a decision whether there is an end character in each line of data in the batch. The decision code is:
(ys == 2).sum(1).bool().all()
Determine whether the element 2 (ending symbol) appears in each line of ys
The decoded complete code is shown in the figure below
def greedy_search_decode(model, src, src_key_padding_mask, max_len: int = 64, start_symbol: int = 1, bs:int=32):
"""
:param model: Transformer model
:param src: the encoder input
:param max_len: Maximum length of sequence
:return:ys This is the specific sequence of prediction
When decoding, these mask It can't be less
"""
src_mask = gen_nopeek_mask(src.shape[1]).to(device)
memory_key_padding_mask = src_key_padding_mask
# The first character [CLS] is 1 in the thesaurus
ys = torch.ones(bs, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len - 1):
tar_mask = gen_nopeek_mask(ys.shape[1]).to(device)
out = model.forward(src, ys, src_key_padding_mask=src_key_padding_mask, tgt_key_padding_mask=None,
src_mask=src_mask, tar_mask=tar_mask, memory_key_padding_mask=memory_key_padding_mask)
# The prediction result is out, and the last probability distribution is selected
out = out[:, -1, :]
# The index that gets the maximum probability is the index of the predicted word in the thesaurus
_, next_word = torch.max(out, dim=1)
next_word = next_word.data[0]
ys = torch.cat([ys, next_word], dim=1)
#Determine whether all decoding is completed in a batch
if (ys == 2).sum(1).bool().all():
break
return ysDecoding examples are as follows
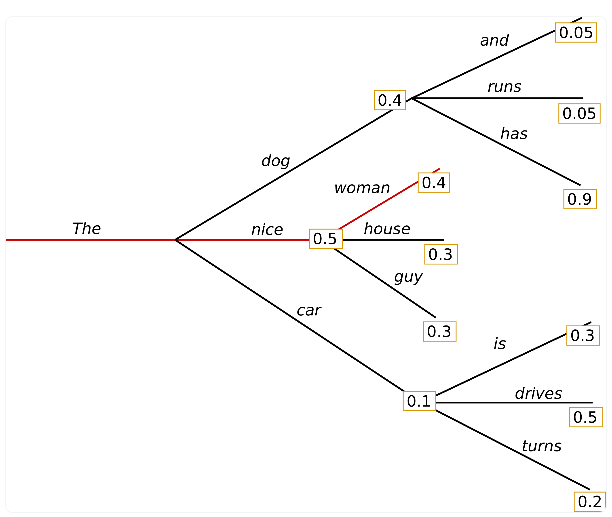
the nice woman is the current best choice probability of each time step, which is 0.5 * 0.4 = 0.2, but from the diagram, the result with the greatest probability is not that the dog has the largest probability of the whole sentence, which is 0.4 * 0.9 = 0.36; The obvious disadvantage of greedy search is that the sequence obtained does not necessarily have the maximum probability of the whole sentence. It is likely to miss a very high probability sequence behind a relatively small current probability. In order to avoid this situation, scholars put forward beam_search algorithm.
2,beam_search cluster search
In order to avoid the above greedy search missing the sequence with high probability, the beam search algorithm proposes to retain the current maximum beam every time_ Num results. Put the current beam_num results are input into the model for decoding, and each sequence generates v new results, a total of beam_num*v results, sort and select the best beam_num results; Then repeat the above process until the decoding is completed, and finally start from beam_num results select the sequence with the largest probability product—— That is, the front beam is reserved in each decoding process_ Num is the largest result, and finally the one with the greatest probability is obtained.
With beam_num is 2. The picture is from -( Learn more about Beam Search 1)
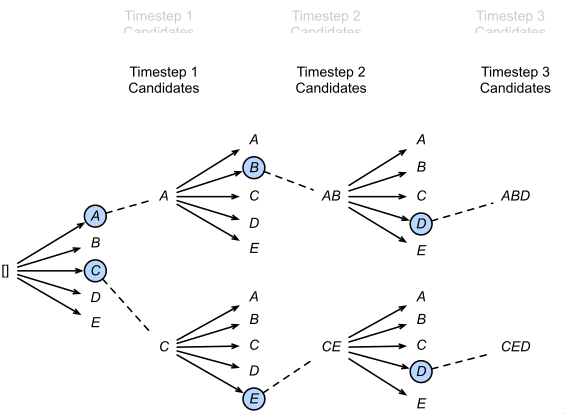
In the first step of decoding, we select the two words [A, C] with the highest probability, and then carry them into the second step of decoding respectively to obtain 10 cases [AA, AB, AC, ad, AE, CA, CB, CC, CD, CE]. Here, only the two optimal cases [AB, CE] are retained, and then continue to carry them into the third step of decoding, and so on Finally, the sequence with the largest overall probability is obtained.
When bs=1, the implementation of beam search is relatively simple. Directly modify the greedy search code and record the current best beam_num sequences and scores, and then each step results from beam_ Sort the results of num * V to get a new beam_num results.
When BS > 1, it is troublesome to implement an efficient beam search. Please refer to Learn more about Beam Search 1 and transformers of huggingface, the world's first NLP implementation library Modify the following beam search code:
import torch
import torch.nn.functional as F
from einops import rearrange
"""
batch_size by n Such treatment
"""
class BeamHypotheses(object):
def __init__(self,num_beams,max_length,length_penalty):
self.max_length=max_length-1 # ignoringbos_token
self.length_penalty=length_penalty # Exponential coefficient of length penalty
self.num_beams=num_beams # beamsize
self.beams=[] # Log storing the optimal sequence and its accumulation_ probscore
self.worst_score=1e9 # Will worst_ The initial score is infinity.
def __len__(self):
return len(self.beams)
def add(self,hyp,sum_logprobs):
score=sum_logprobs / len(hyp) ** self.length_penalty # score after penalty calculation
if len(self) < self.num_beams or score > self.worst_score:
# If the class is not full of num_beams sequences
# Or after it is full, but the score value of the sequence to be added is greater than the minimum value in the class
# Update the sequence into the class and eliminate the worst sequence in the previous class
self.beams.append((score, hyp))
if len(self) > self.num_beams:
sorted_scores=sorted([(s,idx)for idx, (s, _) in enumerate(self.beams)])
del self.beams[sorted_scores[0][1]]
self.worst_score = sorted_scores[1][0]
else:
# If not, update worst only_ score
self.worst_score = min(score, self.worst_score)
def is_done(self,best_sum_logprobs,cur_len):
# After decoding to a certain layer, the score of each node in this layer represents the log from the root node to here_ Sum of prob
# At this time, the highest log is taken_ Prob, if the highest score of the candidate sequence is lower than the lowest score in the class
# Then there's no need to continue decoding. At this time, the decoding of the sentence is completed. There is num in the class_ Beams is an optimal sequence.
if len(self) < self.num_beams:
return False
else:
cur_score = best_sum_logprobs / cur_len ** self.length_penalty
ret = self.worst_score >= cur_score
return ret
def gen_nopeek_mask(length):
"""
Returns the nopeek mask
Parameters:
length (int): Number of tokens in each sentence in the target batch
Returns:
mask (arr): tgt_mask, looks like [[0., -inf, -inf],
[0., 0., -inf],
[0., 0., 0.]]
"""
mask = rearrange(torch.triu(torch.ones(length, length)) == 1, 'h w -> w h')
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def beam_sizing(num_beams,src,src_key_padding_mask):
#To meet beam_ The use of search algorithm in decoding requires data replication - copy by line and copy num_ Beats
temp1 = src
temp2 = src_key_padding_mask
for i in range(num_beams-1):
temp1 = torch.cat([temp1,src],dim=0)
temp2 = torch.cat([temp2,src_key_padding_mask],dim=0)
index = 0
for i in range(src.shape[0]):
for _ in range(num_beams):
temp1[index,...] = src[i,...]
temp2[index,...] = src_key_padding_mask[i,...]
index += 1
src = temp1
src_key_padding_mask = temp2
return src,src_key_padding_mask
def beam_search(device,model,src,src_key_padding_mask,sos_token_id:int=1,pad_token_id:int=0,eos_token_id:int = 2,max_length:int = 20,num_beams:int =6,vocab_size:int=5993):
batch_size = src.shape[0]
src_mask = gen_nopeek_mask(src.shape[1]).to(device)
src,src_key_padding_mask = beam_sizing(num_beams,src,src_key_padding_mask)
memory_key_padding_mask = src_key_padding_mask
beam_scores = torch.zeros((batch_size, num_beams)).to(device) # Define the scores vector and save the accumulated log_probs
beam_scores[:, 1:] = -1e9 # Need to initialize to - inf
beam_scores = beam_scores.view(-1) # Expand to (batch_size * num_beams)
done = [False for _ in range(batch_size)] # Mark whether the beam search of each input sentence is completed
generated_hyps = [
BeamHypotheses(num_beams, max_length, length_penalty=0.7)
for _ in range(batch_size)
] # Define a class instance for each input sentence that maintains its beam search sequence
# Initial input: (batch_size * num_beams, 1) sos token
input_ids = torch.full((batch_size * num_beams, 1), sos_token_id, dtype=torch.long).to(device)
cur_len = 1
while cur_len < max_length:
tar_mask = gen_nopeek_mask(input_ids.shape[1]).to(device)
memory_key_padding_mask = src_key_padding_mask
outputs,_= model.forward(src, input_ids, src_key_padding_mask=src_key_padding_mask, tgt_key_padding_mask=None,src_mask=src_mask,tar_mask=tar_mask,memory_key_padding_mask=memory_key_padding_mask)
# Take the output of the last timestep (batch_size*num_beams, vocab_size)
next_token_logits = outputs[:, -1, :]
scores = F.log_softmax(next_token_logits, dim=-1) # log_softmax
next_scores = scores + beam_scores[:, None].expand_as(scores) # Add up previous scores
next_scores = next_scores.view(
batch_size, num_beams * vocab_size
) # Convert to (batch_size, num_beams * vocab_size), as shown in the above figure
# Take topk, and here you must take 2*num_beams must be a maximum value to ensure that there will be num in each batch of the next batch_ Beams is a problem that needs to be handled
next_scores, next_tokens = torch.topk(next_scores, 2*num_beams, dim=1, largest=True, sorted=True)
# beam list of the whole batch in the next time step
# Each element in the list is a triple
# (score, token_id, beam_id)
next_batch_beam = []
for batch_idx in range(batch_size):
if done[batch_idx]:
# If all the sentences of the current batch have been decoded, the corresponding num_ Continue to pad every sentence
next_batch_beam.extend([(0, pad_token_id, 0)] * num_beams) # pad the batch
continue
next_sent_beam = [] # Save triple (beam_token_score, token_id, effective_beam_id)
for beam_token_rank, (beam_token_id, beam_token_score) in enumerate(
zip(next_tokens[batch_idx], next_scores[batch_idx])
):
beam_id = beam_token_id // vocab_size # 1
token_id = beam_token_id % vocab_size # 1
# The above formula calculates beam_id can only output 0 and num_beams-1, unable to output the real id in (batch_size, num_beams)
# As shown in the figure above, batch_ When IDX = 0, the real beam_id = 0 or 1; batch_ When IDX = 1, the real beam_ The ID is calculated as 2 or 3 as follows:
# batch_ When IDX = 1, the real beam_ The ID is calculated as 4 or 5 as follows:
effective_beam_id = batch_idx * num_beams + beam_id
# If eos is encountered, the sentence of the current beam (excluding the current eos) is saved in generated_hyp
if (eos_token_id is not None) and (token_id.item() == eos_token_id):
is_beam_token_worse_than_top_num_beams = beam_token_rank >= num_beams
if is_beam_token_worse_than_top_num_beams:
continue
generated_hyps[batch_idx].add(
input_ids[effective_beam_id].clone(), beam_token_score.item(),
)
else:
# Save second beam_id sentences are added to the current log_prob and current token_id
next_sent_beam.append((beam_token_score, token_id, effective_beam_id))
if len(next_sent_beam) == num_beams:
break
# Whether the current batch has decoded all sentences
done[batch_idx] = done[batch_idx] or generated_hyps[batch_idx].is_done(
next_scores[batch_idx].max().item(), cur_len
) # Note that all logs of the current batch are taken here_ Maximum value of prob
# Each batch_ idx, next_ sent_ Num in beam_ Beams triples (assuming no EOS are encountered)
# batch_ After IDX loop, the result after extend is num_beams * batch_size triples
next_batch_beam.extend(next_sent_beam)
# If the beam search of each sentence in batch is completed, stop
if all(done):
break
# Prepare for the next cycle (decoding of the next layer)
# beam_scores: (num_beams * batch_size)
# beam_tokens: (num_beams * batch_size)
# beam_idx: (num_beams * batch_size)
# Here, beam idx shape is not necessarily num_beams * batch_size, generally less than or equal to
# Because some sentences corresponding to beam id have been decoded (the following assumptions are not decoded)
# print('next_batch_beam',len(next_batch_beam))
beam_scores = beam_scores.new([x[0] for x in next_batch_beam])
beam_tokens = input_ids.new([x[1] for x in next_batch_beam])
beam_idx = input_ids.new([x[2] for x in next_batch_beam])
# Fetch valid input_ids, because some beams_ Id not in beam_ Inside IDX,
# Because some sentences corresponding to beam id have been decoded
# print('beam_idx',beam_idx)
# print('next_scores.shape',next_scores.shape)
#The following code is the core and must be added
input_ids = input_ids[beam_idx, :] # (num_beams * batch_size, seq_len)
src = src[beam_idx,...]
src_key_padding_mask = src_key_padding_mask[beam_idx,...]
# (num_beams * batch_size, seq_len) ==> (num_beams * batch_size, seq_len + 1)
input_ids = torch.cat([input_ids, beam_tokens.unsqueeze(1)], dim=-1)
cur_len = cur_len + 1
# Note that after the maximum length is reached, some sentences still do not encounter eos token. At this time, done[batch_idx] is false
for batch_idx in range(batch_size):
if done[batch_idx]:
continue
for beam_id in range(num_beams):
# For each batch_ add is executed for every beam of IDX
# Notice that Max has been decoded here_ Length is too long, but eos is not encountered, so we should try to add it all here
effective_beam_id = batch_idx * num_beams + beam_id
final_score = beam_scores[effective_beam_id].item()
final_tokens = input_ids[effective_beam_id]
generated_hyps[batch_idx].add(final_tokens, final_score)
# After the above steps, Num is saved in the class of each input sentence_ Beams is an optimal sequence
# Here are some of the best sequence outputs
# Each sample returns several sentences
output_num_return_sequences_per_batch = num_beams #Must be less than num_beams
output_batch_size = output_num_return_sequences_per_batch * batch_size
# Record the length of each returned sentence for the following pad
sent_lengths = input_ids.new(output_batch_size)
best = []
best_score = []
# retrieve best hypotheses
for i, hypotheses in enumerate(generated_hyps):
# x: (score, hyp), x[0]: score
sorted_hyps = sorted(hypotheses.beams, key=lambda x: x[0])
for j in range(output_num_return_sequences_per_batch):
effective_batch_idx = output_num_return_sequences_per_batch * i + j
temp = sorted_hyps.pop()
best_hyp = temp[1]
best_s = temp[0]
sent_lengths[effective_batch_idx] = len(best_hyp)
best.append(best_hyp)
best_score.append(best_s)
if sent_lengths.min().item() != sent_lengths.max().item():
sent_max_len = min(sent_lengths.max().item() + 1, max_length)
# fill pad
decoded = input_ids.new(output_batch_size, sent_max_len).fill_(pad_token_id)
# Fill content
for i, hypo in enumerate(best):
decoded[i, : sent_lengths[i]] = hypo
if sent_lengths[i] < max_length:
decoded[i, sent_lengths[i]] = eos_token_id
else:
# Otherwise, stack it directly
decoded = torch.stack(best).type(torch.long)
# (output_batch_size, sent_max_len) ==> (batch_size*output_num_return_sequences_per_batch, sent_max_len)
best_score = torch.tensor(best_score).type_as(next_scores)
return decoded,best_score
Although it solves the defect of greedy search, the beam search decoding strategy also has its defects. From the actual use effect, beam search is easy to repeat the previous characters, especially in the task of text generation and machine translation.
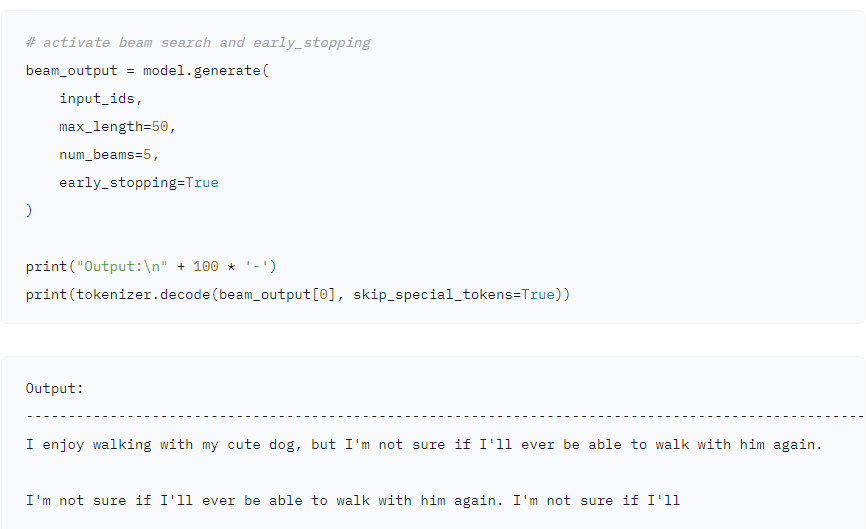
How to generate text: using different decoding methods for language generation with Transformers The example given in shows that after generating a very short sentence, it begins to repeat. In order to solve this problem, scholars have proposed the algorithm of random sampling
3. Random sampling
Random sampling, as the name suggests, is to sample directly and randomly during decoding and the generation of the next token. The advantage of the greedy method is that the text we generate begins to have some randomness and will not always generate very mechanical replies. The problem is obvious - the generated script context is incoherent, semantically contradictory, and prone to some strange words.
4. Top-K Sampling and Top-p (nucleus) sampling
paper The Curious Case of Neural Text Degeneration An interesting language phenomenon is put forward in——
Human language is always unexpected, not like choosing the sequence with the highest probability in the language model in beam search. This is the result of the beam search decoding strategy! Therefore, the paper improves the Top-p (nucleus) sampling based on the Top-K Sampling. Let's talk about Top-K Sampling and Top-p (nucleus) sampling.
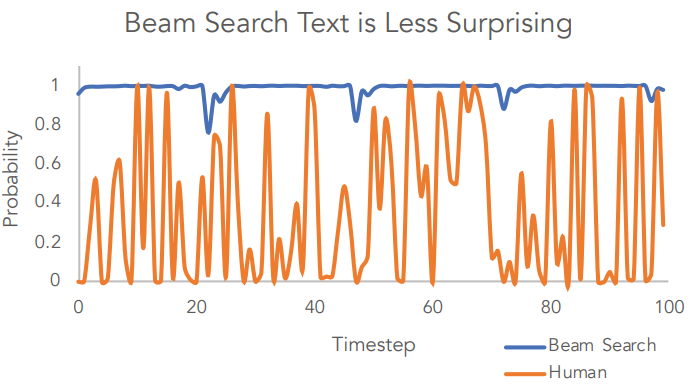
Top-K Sampling
This is an improvement on the basis of random sampling. Since random sampling on the whole loghits probability distribution will lead to incoherent context, semantic contradictions, strange words and other problems, can we select the K tokens with the highest probability to re form the probability distribution, and then do polynomial distribution sampling. The idea is very simple, and torch is not difficult to implement. The actual use effect has been highly improved on the GPT2 model. The sentences generated by GPT2 are very smooth and fluent, and the repeated tokens are greatly reduced.
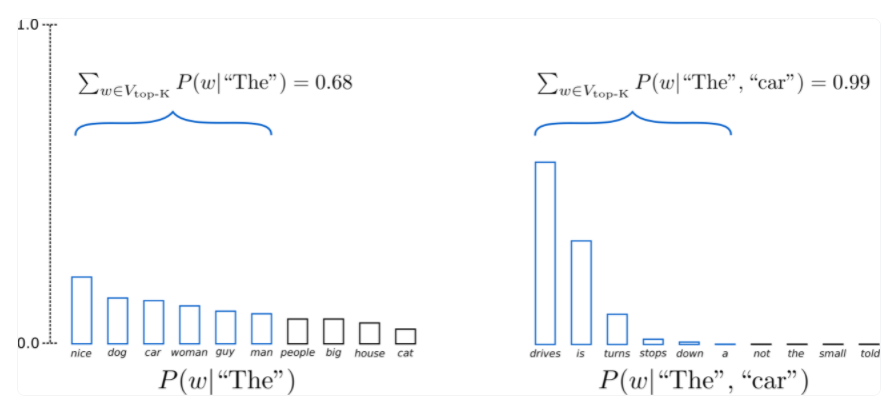
As shown in the figure, when K=6, in the first step of decoding, the six tokens account for two-thirds of the total tokens, while in the second step, they account for 99%, and these tokens are reasonable. At the same time, polynomial random sampling is also used in sampling - in this way, a more smooth and fluent discourse will be obtained, and there are no repeated words and strange words.
The difficulty of this method is how to select the K value
In each decoding step, the probability distribution of logits is different. In dynamic change, the fixed k value may cause the obtained token to be an unreasonable token with low probability; In addition, if the value of K is too large, the script context generated will be inconsistent like the previous random sampling, which may be semantically contradictory and prone to some strange words; If K is too small, the diversity of generated statements will become worse. less surprising! It is best that K can dynamically adapt to the logits of each decoding step! For this reason, some scholars have proposed Top-p (nucleus) sampling
Top-p (nucleus) sampling
Different from Top-K Sampling, Top-p (nucleus) sampling accumulates the probability of the whole logits from large to small. As long as the cumulative probability is greater than a threshold, these selected tokens form a new distribution, and then take polynomial sampling to obtain the decoded next token!
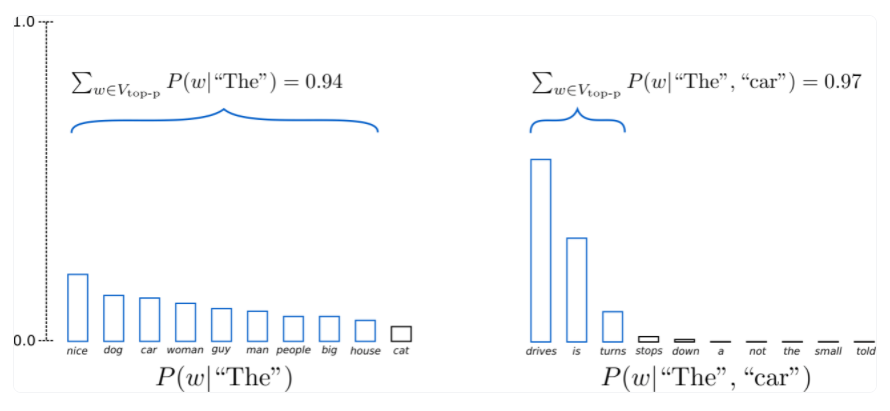
In the example, the cumulative probability threshold p = 0.92, and the sampling in the first step of decoding is carried out from 9 tokens; The second step is decoding from three tokens; In this way, we can dynamically adapt to logtis and adopt different K values. However, one point is that the cumulative probability threshold P is also insoluble in determination, and empirical values are mostly used.
Of course, in terms of use effect, Top-K Sampling and Top-p (nucleus) sampling are relatively good; Of course, in actual use, Top-p (nucleus) sampling and Top-K Sampling can also be combined to avoid token with low probability as a candidate, and maintain dynamic at the same time.
top-k and top-p filter codes:
def top_k_top_p_filtering_batch(logits, top_k=0, top_p=0.0, filter_value=-float('Inf')):
""" Filter a distribution of logits using top-k and/or nucleus (top-p) filtering
Args:
logits: logits distribution shape (vocabulary size)
top_k > 0: keep only top k tokens with highest probability (top-k filtering).
top_p > 0.0: keep the top tokens with cumulative probability >= top_p (nucleus filtering).
Nucleus filtering is described in Holtzman et al. (http://arxiv.org/abs/1904.09751)
From: https://gist.github.com/thomwolf/1a5a29f6962089e871b94cbd09daf317
"""
top_k = min(top_k, logits.size(-1)) # Safety check
if top_k > 0:
# Remove all tokens with a probability less than the last token of the top-k
# torch.topk() returns the largest top in the last dimension_ K elements, and the return value is two-dimensional (values,indices)
# ... Indicates that other dimensions are inferred by the computer itself
for i in range(logits.shape[0]):
indices_to_remove = logits[i] < torch.topk(logits[i], top_k)[0][..., -1, None]
logits[i][indices_to_remove] = filter_value # For elements other than topk, the logits value is set to negative infinity
if top_p > 0.0:
for i in range(logits.shape[0]):
sorted_logits, sorted_indices = torch.sort(logits[i], descending=True) # Sort logits in descending order
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
# Remove tokens with cumulative probability above the threshold
sorted_indices_to_remove = cumulative_probs > top_p
# Shift the indices to the right to keep also the first token above the threshold
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
sorted_indices_to_remove[..., 0] = 0
indices_to_remove = sorted_indices[sorted_indices_to_remove]
logits[i][indices_to_remove] = filter_value
return logitsThen directly call the filtering algorithm for decoding
curr_input_tensor = input_ids.to(device)
generated = []
for index in range(args.max_len):
outputs = model(input_ids=curr_input_tensor)
next_token_logits = outputs[0][:,-1:]
# For each token in the generated result, add a duplicate penalty item to reduce its generation probability
if index>=1:
for i in range(gen_finall.shape[0]):
gen_token_ids = gen_finall[i].clone()
gen_token_ids = list(set(gen_token_ids.detach().cpu().tolist()))
for id in gen_token_ids:
next_token_logits[i:i+1,:,id:id+1] /= args.repetition_penalty
next_token_logits = next_token_logits / args.temperature
# The probability of [UNK] is set to infinity, which means that the prediction result of the model cannot be the token of [UNK]
token_unk_id = tokenizer.convert_tokens_to_ids('[UNK]')
next_token_logits[:,:,token_unk_id:token_unk_id+1] = -float('Inf')
#top-k and top-p filtering
filtered_logits = top_k_top_p_filtering_batch(next_token_logits, top_k=args.topk, top_p=args.topp)
# torch.multinomial means extracting num from the candidate set without putting it back_ Samples are elements. The higher the weight, the higher the probability of drawing. The subscript of the element is returned
next_token = curr_input_tensor[:,-1:].clone()
for i in range(next_token.shape[0]):
next_token[i] = torch.multinomial(F.softmax(filtered_logits[i].squeeze(0), dim=-1), num_samples=1)
generated.append(next_token)
gen_finall = torch.cat(generated,dim=1)
# print('gen_finall',gen_finall)
# print('tokenizer.sep_token_id',tokenizer.sep_token_id)
# print((gen_finall==tokenizer.sep_token_id))
# print((gen_finall==tokenizer.sep_token_id).sum(1))
# print((gen_finall==tokenizer.sep_token_id).sum(1).bool())
# print((gen_finall==tokenizer.sep_token_id).sum(1).bool().all())
#All in batch are decoded
if (gen_finall==tokenizer.sep_token_id).sum(1).bool().all():
break
curr_input_tensor = torch.cat((curr_input_tensor, next_token), dim=1)III. decoding in transformer
The previous article talked about the basic process of text generation and translation, some basic principles and ideas of decoding strategy and the implementation of decoding strategy. Of course, the more elegant usage is direct call transformers of huggingface, the world's first NLP implementation library Decoding function of text translation class or generation class in. generation_utils.py Various decoding methods are provided, such as green search, beam search, sampling (direct random sampling, top-K and Top-P), beam_sample(beam_search+top-K and Top-P) and group_beam. As for some other functions, readers need to read the source code themselves.
Decoding is very simple. The code is as follows: load the model, feed the data, decode and get the result.
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
from tqdm import tqdm
from torch.utils.data import DataLoader
import torch
from data_reader.dataReader_zh2en import DataReader
if __name__ == '__main__':
tokenizer = AutoTokenizer.from_pretrained("./pretrained_models/MarianMTModel_zh2en")
model = AutoModelForSeq2SeqLM.from_pretrained("./pretrained_models/MarianMTModel_zh2en")
dataset = DataReader(tokenizer, filepath='data/test_sample.csv')
test_dataloader = DataLoader(dataset=dataset,batch_size=4)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(device)
finanl_result = []
for batch in tqdm(test_dataloader,desc='translation prediction'):
for k, v in batch.items():
batch[k] = v.to(device)
batch = {'input_ids': batch['input_ids'], 'attention_mask': batch['attention_mask']}
# Perform the translation and decode the output
translation = model.generate(**batch, top_k=5, num_return_sequences=1,num_beams=1)
batch_result = tokenizer.batch_decode(translation, skip_special_tokens=True)
finanl_result.extend(batch_result)
print(len(finanl_result))
for res in finanl_result:
print(res.replace('[','').replace(']',''))Taking translation tasks as an example, MarianMT model based on transformer architecture is adopted_ Zh2en Chinese to English model parameters.
The complete code is as follows
import pandas as pd
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
from tqdm import tqdm
from torch.utils.data import DataLoader
import torch
from data_reader.dataReader_zh2en import DataReader
if __name__ == '__main__':
tokenizer = AutoTokenizer.from_pretrained("./pretrained_models/MarianMTModel_zh2en")
model = AutoModelForSeq2SeqLM.from_pretrained("./pretrained_models/MarianMTModel_zh2en")
dataset = DataReader(tokenizer, filepath='data/test_sample.csv')
test_dataloader = DataLoader(dataset=dataset,batch_size=4)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(device)
finanl_result = []
for batch in tqdm(test_dataloader,desc='translation prediction'):
for k, v in batch.items():
batch[k] = v.to(device)
batch = {'input_ids': batch['input_ids'], 'attention_mask': batch['attention_mask']}
# Perform the translation and decode the output
#greedy
greedy_translation = model.generate(**batch,num_return_sequences = 1)
greedy_batch_result = tokenizer.batch_decode(greedy_translation, skip_special_tokens=True)
finanl_result.append(greedy_batch_result)
#beam_search
beam_translation = model.generate(**batch, num_return_sequences=1, num_beams=5)
beam_batch_result = tokenizer.batch_decode(beam_translation, skip_special_tokens=True)
finanl_result.append(beam_batch_result)
#sampling
sample_translation = model.generate(**batch, do_sample=True, num_return_sequences=1)
sample_batch_result = tokenizer.batch_decode(sample_translation, skip_special_tokens=True)
finanl_result.append(sample_batch_result)
#top-k
topk_translation = model.generate(**batch, top_k=5, num_return_sequences=1)
topk_batch_result = tokenizer.batch_decode(topk_translation, skip_special_tokens=True)
finanl_result.append(topk_batch_result)
# top-p
topp_translation = model.generate(**batch, top_p=0.92, num_return_sequences=1)
topp_batch_result = tokenizer.batch_decode(topp_translation, skip_special_tokens=True)
finanl_result.append(topp_batch_result)
# top-k and top-p
topktopp_translation = model.generate(**batch, top_k=5, top_p=0.92, num_return_sequences=1)
topktopp_batch_result = tokenizer.batch_decode(topktopp_translation, skip_special_tokens=True)
finanl_result.append(topktopp_batch_result)
# top-k and top-p+beam_search
beamtopktopp_translation = model.generate(**batch, top_k=5, top_p=0.92, num_return_sequences=1, num_beams=5)
beamtopktopp_batch_result = tokenizer.batch_decode(beamtopktopp_translation, skip_special_tokens=True)
finanl_result.append(beamtopktopp_batch_result)
decodes_policys = ['greedy search','beam_search','sampling','top-k','top-p','top-k and top-p','top-k and top-p+beam_search']
test_sample = ['[Dermatomycosis caused by Cryptosporidium fulminatum].','[Bariatric surgery in duodenal conversion surgery: weight changes and associated nutritional deficiencies]. ','[Interobserver diagnostic protocol for hysteroscopic study of digital images]. ']
print(len(finanl_result))
for i in range(3):
print(test_sample[i])
for ele,de_ty in zip(finanl_result,decodes_policys):
print(ele[i].replace('[','').replace(']',''))
print('*'*100)
Translate src text
[Dermatomycosis caused by Cryptosporidium fulminatum]. [Bariatric surgery in duodenal conversion surgery: weight changes and associated nutritional deficiencies]. [Interobserver diagnostic protocol for hysteroscopic study of digital images].
Comparison of results obtained by different decoding strategies
[Dermatomycosis caused by Cryptosporidium fulminatum]. Skin fungi caused by Fung's Invisible Spores. Skin fungus disease caused by Fung's Invisible Spores. Skin fungi caused by Fung's spores. Skin fungi caused by Fung's Invisible Spores. Skin fungi caused by Fung's Invisible Spores. Skin fungi caused by Fung's Invisible Spores. Skin fungus disease caused by Fung's Invisible Spores. **************************************************************************************************** [Bariatric surgery in duodenal conversion surgery: weight changes and associated nutritional deficiencies]. Twelve reference to fertility reduction in intestinal conversion operations: changes in body weight and associated nutritional deficiencies. Twelve reference to fertility reduction in intestinal conversion operations: changes in body weight and associated nutritional deficiencies. Liith finger intestinal conversion operations with dietary loss: weight changes and associated nutritional deficiencies. Twelve reference to fertility reduction in intestinal conversion operations: changes in body weight and associated nutritional deficiencies. Twelve reference to fertility reduction in intestinal conversion operations: changes in body weight and associated nutritional deficiencies. Twelve reference to fertility reduction in intestinal conversion operations: changes in body weight and associated nutritional deficiencies. Twelve reference to fertility reduction in intestinal conversion operations: changes in body weight and associated nutritional deficiencies. **************************************************************************************************** [Interobserver diagnostic protocol for hysteroscopic study of digital images]. Observer-to-observer protocol for the study of digital images in the court cavity mirrors. Observer-to-observer protocol for the study of digital images in the court cavity mirrors. Observatorial protocol for the study of digital images in the uterine cavity mirror. Observer-to-observer protocol for the study of digital images in the court cavity mirrors. Observer-to-observer protocol for the study of digital images in the court cavity mirrors. Observer-to-observer protocol for the study of digital images in the court cavity mirrors. Observer-to-observer protocol for the study of digital images in the court cavity mirrors.
In terms of translation tasks, the results are not very different, but there are some differences.
reference
How to generate text: using different decoding methods for language generation with Transformers
Comparison between Nucleus Sampling and different decoding strategies in text generation