1.to_ Basic syntax of dict() function
DataFrame.to_dict (self, orient='dict' , into= )--- official documentsFor each function, you only need to fill in one parameter: orient , but the dictionary is constructed in different ways for different functions. The official website gives a total of six types, and one of them is the list type:
- orient ='dict', which is the default of the function, is the converted dictionary form: {column (column name): {index (row name): value))}};
- orient ='list', dictionary form after conversion: {column (column name): {[values] (value)}};
- orient ='series', dictionary form after conversion: {column (column name): Series (values)};
- orient ='split', converted dictionary form: {'index': [index], 'columns': [columns],' data ': [values]};
- orient ='records', converted to list form: [{column:value}... {column:value}];
- orient ='index', dictionary form after conversion: {index (value): {column (column name): value}};
remarks:
1. In the above, value represents the value in the data table, column represents the column name, and index represents the row name, as shown in the following figure:
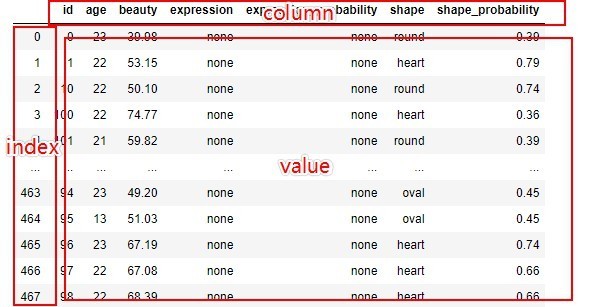
2, {} indicates the dictionary data type. The data in the dictionary is displayed in the form of {key: value}, which is formed by one-to-one correspondence between key name and key value.
2. Code examples of six construction methods
The DataFrame data processed by the six construction methods are unified, as follows:
>>> import pandas as pd
>>> df =pd.DataFrame({'col_1':[1,2],'col_2':[0.5,0.75]},index =['row1','row2'])
>>> df
col_1 col_2
row1 1 0.50
row2 2 0.752.1, orientation = 'dict' - {column (column name): {index (row name): value))}}
to_dict('list '), the constructed dictionary form: {column name of the first column: {row name of the first row: value value, row name of the second row, value},...};
>>> df
col_1 col_2
row1 1 0.50
row2 2 0.75
>>> df.to_dict('dict')
{'col_1': {'row1': 1, 'row2': 2}, 'col_2': {'row1': 0.5, 'row2': 0.75}}orient = 'dict' can easily get the dictionary data type between the row name corresponding to a column and each value. For example, on the source data, I want to get col_1 the dictionary between the row name of this column and each value is directly queried in the generated dictionary. The column name is col_1:
>>> df
col_1 col_2
row1 1 0.50
row2 2 0.75
>>> df.to_dict('dict')['col_1']
{'row1': 1, 'row2': 2}2.2, orientation = 'list' - {column (column name): {[values] (value)}};
In the generated dictionary, key is the name of each column and value is the list of corresponding values of each column
>>> df
col_1 col_2
row1 1 0.50
row2 2 0.75
>>> df.to_dict('list')
{'col_1': [1, 2], 'col_2': [0.5, 0.75]}When orient = 'list', you can easily get the list set generated by each value in a column. For example, I want to get col_2. List of corresponding values:
>>> df
col_1 col_2
row1 1 0.50
row2 2 0.75
>>> df.to_dict('list')['col_2']
[0.5, 0.75]2.3, orientation = 'series' - {column: Series (values)};
The only difference between orient ='series' and orient =' list 'is that the {value} here is the} Series data type, while the former is the list type
>>> df
col_1 col_2
row1 1 0.50
row2 2 0.75
>>> df.to_dict('series')
{'col_1': row1 1
row2 2
Name: col_1, dtype: int64, 'col_2': row1 0.50
row2 0.75
Name: col_2, dtype: float64}2.4,orient ='split' — {'index' : [index],'columns' :[columns],'data' : [values]};
orient ='split' gets three key value pairs, one for column name, one for row name and one for value. All values are in list form;
>>> df
col_1 col_2
row1 1 0.50
row2 2 0.75
>>> df.to_dict('split')
{'index': ['row1', 'row2'], 'columns': ['col_1', 'col_2'], 'data': [[1, 0.5], [2, 0.75]]}orient = 'split' can easily get} DataFrame data sheet List form of all column names or row names in. For example, I want to get all column names:
>>> df
col_1 col_2
row1 1 0.50
row2 2 0.75
>>> df.to_dict('split')['columns']
['col_1', 'col_2']2.5, orientation = 'records' - [{column: value}, {column: value}... {column: value}];
Note that the data type returned by orient ='records' is not {dict; Instead, it is in the form of a list, which forms a one-to-one mapping relationship between all column names and the values of each row:
>>> df
col_1 col_2
row1 1 0.50
row2 2 0.75
>>> df.to_dict('records')
[{'col_1': 1, 'col_2': 0.5}, {'col_1': 2, 'col_2': 0.75}]The advantage of this construction method is that it is easy to get the dictionary data formed by the column name and a row value; For example, I want line 2{ column:value }Data obtained:
>>> df
col_1 col_2
row1 1 0.50
row2 2 0.75
>>> df.to_dict('records')[1]
{'col_1': 2, 'col_2': 0.75}2.6,orient ='index' — {index:{culumn:value}};
The usage of orient ='index' is just opposite to that of 2.1. Find the one-to-one correspondence between column names and values in a row (the query effect is similar to that of 2.5):
>>> df
col_1 col_2
row1 1 0.50
row2 2 0.75
>>> df.to_dict('index')
{'row1': {'col_1': 1, 'col_2': 0.5}, 'row2': {'col_1': 2, 'col_2': 0.75}}
#The query row name is row2, and the column name and value correspond to the dictionary data type one by one
>>> df.to_dict('index')['row2']
{'col_1': 2, 'col_2': 0.75}