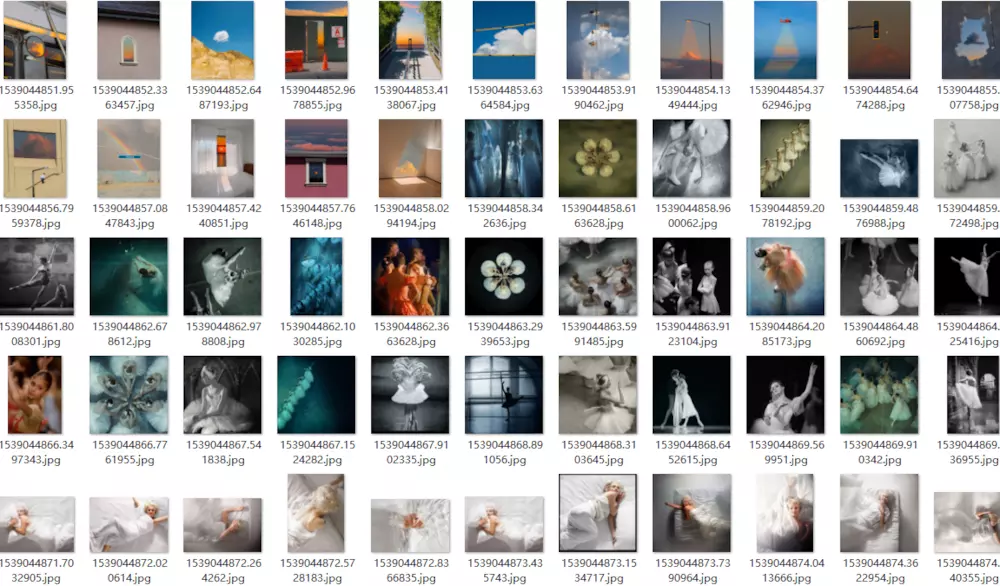
1. Pictures of Hummingbird Net - Introduction
Today we continue to crawl a website for http://image.fengniao.com/. Hummingbird is a place where photographic bulls gather. This tutorial is for learning, not for commercial purposes. It is no surprise that hummingbirds are copyright-protected websites.

2. Pictures of Hummingbird Network - Website Analysis
The first step is to analyze whether there is a way to crawl a website, open a page, and find pages.
http://image.fengniao.com/index.php?action=getList&class_id=192&sub_classid=0&page=1¬_in_id=5352384,5352410 http://image.fengniao.com/index.php?action=getList&class_id=192&sub_classid=0&page=2¬_in_id=5352384,5352410 http://image.fengniao.com/index.php?action=getList&class_id=192&sub_classid=0&page=3¬_in_id=5352384,5352410 http://image.fengniao.com/index.php?action=getList&class_id=192&sub_classid=0&page=4¬_in_id=5352384,5352410
The key parameter page=1 found on the page above is the page number, but another headache is that he does not have the final page number, so we can not determine the number of iterations, so in the later coding, we can only use while.
This address returns data in JSON format, which is very friendly to crawlers! In our province, we use regular expressions to analyze.
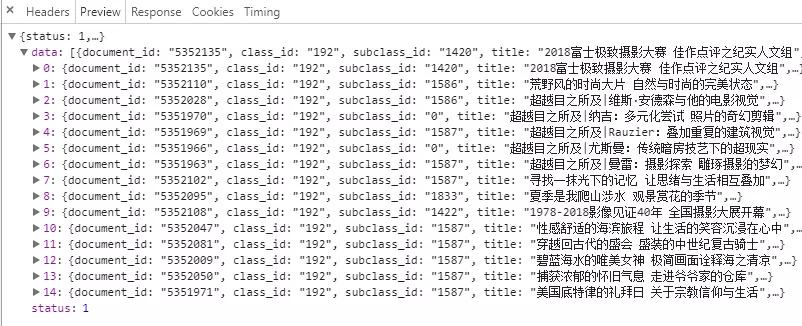
Analyse the header file of this page to see if there are anti-crawling measures
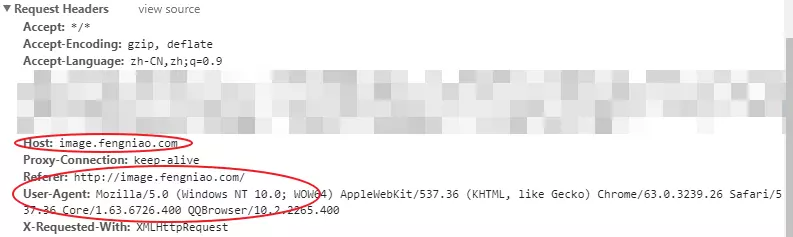
It is found that there is no special point except HOST and User-Agent. Big websites are wayward and have nothing to climb back. Maybe they don't care about it at all.
The second step is to analyze the picture details page and find the key address in the JSON we got above.
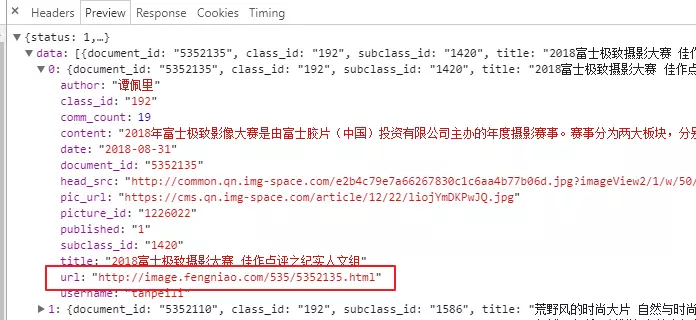
When the key address is opened, there is a more saucy operation in this place. The bad selection of URL s in the picture above happens to be an article. What we need is a group diagram, which provides a new link http://image.fengniao.com/slide/535/5352130_1.html#p=1.
Open the page, you may go directly to find the rules, find the following bunch of links, but this operation is a little complicated, let's look at the source code of the above page.
http://image.fengniao.com/slide/535/5352130_1.html#p=1 http://image.fengniao.com/slide/535/5352130_1.html#p=2 http://image.fengniao.com/slide/535/5352130_1.html#p=3 .... Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
This area is found in the source code of the web page.

Bold guess, this should be the JSON of the picture, but it's printed in HTML. We just need to match it with regular expressions, and then download it.
The third step is to start coding.

3. Pictures of Hummingbird Network - Coding
from http_help import R # This file can be found on your last blog, or on github.
import threading
import time
import json
import re
img_list = []
imgs_lock = threading.Lock() #Picture Operation Lock
# Producers
class Product(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
self.__headers = {"Referer":"http://image.fengniao.com/",
"Host": "image.fengniao.com",
"X-Requested-With":"XMLHttpRequest"
}
#Link Template
self.__start = "http://image.fengniao.com/index.php?action=getList&class_id=192&sub_classid=0&page={}¬_in_id={}"
self.__res = R(headers=self.__headers)
def run(self):
# Because you don't know the number of cycles, all use while cycles
index = 2 #Start page number set to 1
not_in = "5352384,5352410"
while True:
url = self.__start.format(index,not_in)
print("Start operation:{}".format(url))
index += 1
content = self.__res.get_content(url,charset="gbk")
if content is None:
print("The data may be gone.====")
continue
time.sleep(3) # Sleep for 3 seconds
json_content = json.loads(content)
if json_content["status"] == 1:
for item in json_content["data"]:
title = item["title"]
child_url = item["url"] # After getting the link
img_content = self.__res.get_content(child_url,charset="gbk")
pattern = re.compile('"pic_url_1920_b":"(.*?)"')
imgs_json = pattern.findall(img_content)
if len(imgs_json) > 0:
if imgs_lock.acquire():
img_list.append({"title":title,"urls":imgs_json}) # This place, I use the dictionary + list way, mainly want to generate folders later, you can change it.
imgs_lock.release()
The link above has been generated, and the following is to download the picture, which is very simple.
# Consumer
class Consumer(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
self.__res = R()
def run(self):
while True:
if len(img_list) <= 0:
continue # Enter the next cycle
if imgs_lock.acquire():
data = img_list[0]
del img_list[0] # Delete the first item
imgs_lock.release()
urls =[url.replace("\\","") for url in data["urls"]]
# Create a file directory
for item_url in urls:
try:
file = self.__res.get_file(item_url)
# Remember to create the fengniaos folder in the project root directory first
with open("./fengniaos/{}".format(str(time.time())+".jpg"), "wb+") as f:
f.write(file)
except Exception as e:
print(e)
Python Resource sharing qun 784758214 ,Installation packages are included. PDF,Learning videos, here is Python The gathering place of learners, zero foundation and advanced level are all welcomed.
Code comes up, result