In 2019, FaceMesh, a face 3D surface extraction model that can run in real time on the mobile terminal, is used by many mobile terminal AR applications as the underlying algorithm to realize face detection and face 3D point cloud generation. The relevant paper title is:
<Real-time Facial Surface Geometry from Monocular Video on Mobile GPUs>
The implementation address of github with pytorch version is as follows:
https://github.com/thepowerfuldeez/facemesh.pytorch
The pre training model file pth has been provided and can be opened and viewed with Netron. Its input and output display screenshots are as follows:
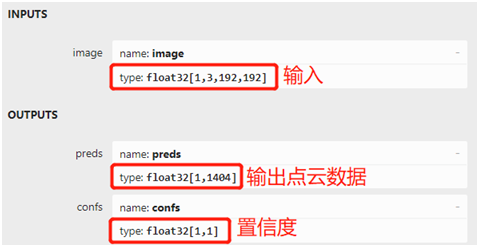
Figure-2
The final output point cloud data is 468 3D face point cloud coordinates, and the ROI area of the input face is 192x192. The model can be converted to ONNX format model by using the scripts supported by pytoch. The converted scripts and codes are as follows:
from facemesh import FaceMeshimport torch
net = FaceMesh()net.load_weights("facemesh.pth")torch.onnx.export(net, torch.randn(1, 3, 192, 192, device='cpu'), "facemesh.onnx", input_names=("image", ), output_names=("preds", "confs"), opset_version=9)In this way, we get the ONNX version of the model file.
OpenVINO calls the facemesh model
OpenVINO2020. After version x, it supports direct reading of ONNX format model files to realize model loading and reasoning call. Here, take openvino2021 Take version 2 as an example. Our basic idea is to realize face detection through openvino's own face detection model, then intercept the face ROI area and send it to the facemesh model to extract 468 points from the face 3D surface point cloud. For face detection, we have selected openvino's own face detection-0202 model file, which is based on MobileNet SSDv version, and the input format is as follows:
NCHW = 1x3x384x384
The output format is:
1x1xNx7
The order of channels is BGR
It can be seen from figure-2 that the input format of the face 3D point cloud extraction model facemesh is 1x3x192x192, and there are two output layers: preds and conf, where preds is the point cloud data, and conf represents the confidence. 1404 of preds represents the three-dimensional coordinates of 468 points, with a total of 468x3=1404. The steps and running results of the code demonstration part are explained in detail. Loading model and obtaining input and output information:
#Load face detection model net = ie.read_network(model=model_xml, weights=model_bin) input_blob = next(iter(net.input_info)) out_blob = next(iter(net.outputs)) #Input format of face detection n, c, h, w = net.input_info[input_blob].input_data.shape print(n, c, h, w) exec_net = ie.load_network(network=net, device_name="CPU") #Load face 3D point cloud prediction model face_mesh_onnx = "facemesh.onnx" mesh_face_net = ie.read_network(model=face_mesh_onnx) #Input format em_input_blob = next(iter(mesh_face_net.input_info)) en, ec, eh, ew = mesh_face_net.input_info[em_input_blob].input_data.shape print(en, ec, eh, ew) em_exec_net = ie.load_network(network=mesh_face_net, device_name="CPU")
Face detection and obtaining face ROI, then extracting face 3D point cloud data, and then displaying:
#Set the input image and face detection model for reasoning and prediction
image = cv.resize(frame, (w, h))
image = image.transpose(2, 0, 1)
inf_start = time.time()
res = exec_net.infer(inputs={input_blob: [image]})
ih, iw, ic = frame.shape
res = res[out_blob]
#Analyze face detection and obtain ROI
for obj in res[0][0]:
if obj[2] > 0.75:
xmin = int(obj[3] * iw)
ymin = int(obj[4] * ih)
xmax = int(obj[5] * iw)
ymax = int(obj[6] * ih)
if xmin < 0:
xmin = 0
if ymin < 0:
ymin = 0
if xmax >= iw:
xmax = iw - 1
if ymax >= ih:
ymax = ih - 1
#Intercept face ROI and extract 3D surface point cloud data
roi = frame[ymin:ymax, xmin:xmax, :]
roi_img = cv.resize(roi, (ew, eh))
roi_img = np.float32(roi_img) / 127.5
roi_img = roi_img.transpose(2, 0, 1)
em_res = em_exec_net.infer(inputs={em_input_blob: [roi_img]})
#Convert to 468 3D point cloud data and display
prob_mesh = em_res["preds"]
prob_mesh= np.reshape(prob_mesh, (-1, 3))
cv.rectangle(frame, (xmin, ymin), (xmax, ymax), (0, 255, 255), 2, 8)
sx, sy= ew / roi.shape[1], eh / roi.shape[0]
for i in range(prob_mesh.shape[0]):
x, y = int(prob_mesh[i, 0] / sx), int(prob_mesh[i, 1] / sy)
cv.circle(frame, (xmin + x, ymin + y), 1, (0, 0, 255), 1)
#Calculate frame rate and display point cloud results
inf_end = time.time() - inf_start
cv.putText(frame, "infer time(ms): %.3f, FPS: %.2f" % (inf_end * 1000, 1 / inf_end), (10, 50),
cv.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 255), 2, 8)
cv.imshow("Face Detection + 3D mesh", frame)The operation results are as follows:


