Today's content
- UDP protocol
- History of operating system
- process
- Process scheduling in the case of single core
- Process three state diagram
- Synchronous asynchronous
- Blocking non blocking
Detailed content
1, UDP protocol
1. What is UDP protocol
UDP is a transport layer protocol. Its function is to add the most basic services on the datagram service of IP: multiplexing and sharing and error detection.
UDP provides unreliable services and has the advantages that TCP does not have:
-
UDP has no connection, and there is no time delay required to establish a connection.
-
UDP has no congestion control. The application layer can better control the data to be sent and the sending time. The congestion control in the network will not affect the sending rate of the host.
2. Case
import socket
udp_sk = socket.socket(type=socket.SOCK_DGRAM) # UDP protocol
udp_sk.bind(('127.0.0.1',9000)) # Binding address
msg,addr = udp_sk.recvfrom(1024)
udp_sk.sendto(b'hi',addr)
udp_sk.close()
import socket
ip_port=('127.0.0.1',9000)
udp_sk=socket.socket(type=socket.SOCK_DGRAM)
udp_sk.sendto(b'hello',ip_port)
back_msg,addr=udp_sk.recvfrom(1024)
print(back_msg.decode('utf-8'),addr)
"""
Implementation principle of time server
1.Internal small capacitor power supply
2.Remote time synchronization
"""
Example: simple qq program
2, History of operating system
The history of operating system development is centered on improving CPU utilization. With each technological progress, CPU utilization is greatly improved
"" "learning concurrent programming is actually learning the history of the operating system (underlying logic)" ""
1. Punch card Era
Extremely low CPU utilization
People who use computers have to wait outside the door with their own programs (punched cards). The input time is very long, and the CPU utilization time is less
2. Online batch processing system
The programs of multiple programmers are input into the tape at one time, and then input by the input machine and executed by the CPU
3. Offline batch processing system
Prototype of modern computer (remote input high-speed tape host)
Staff only need to buy an input device at home, they can transfer the program to high-speed tape (memory), and then execute it with CPU
Multichannel technology
The premise is a single core CPU
- Switch + save state
Switching: when the CPU executes process code, if it encounters IO operation, it will immediately stop the execution of the current process and switch to the execution of other processes
Save status: before switching, the execution status of the current process will be retained so that it can continue at the disconnected position when switching back
'''
CPU Working mechanism:
1,When a program enters IO In the operating state, the operating system will forcibly deprive the program CPU Execution Authority
2,When a program is occupied for a long time CPU When, the operating system will forcibly deprive the program CPU Execution Authority
'''
Parallelism and Concurrency:
Parallelism: multiple programs run at the same time (one is required for each program execution) CPU)
Concurrency: multiple programs can run as long as they look like they are running at the same time
# Q: can a single core CPU achieve parallelism
Certainly not, but concurrency can be achieved
# Q: 12306 can support hundreds of millions of users to buy tickets at the same time. Is it parallel or concurrent
It must be concurrent(High concurrency)
Satellite orbit:Microblog can support eight satellite orbits
3, Process
1. What is a process
Program: the programming code to realize the function, which is stored in the hard disk (dead)
Process: a running application that exists in memory (is alive)
2. Process scheduling in the case of single core
- FCFS first come first served
Unfriendly to short assignments
- Short start-up time, start first
Unfriendly to long homework
- Time slice rotation method + multi-level feedback queue
1. First assign the same time slice (CPU execution time) to all processes to be executed
2. Then, it is graded according to the time slice consumed by each process, and those with long execution time need to enter the next level
3. Give priority to the first level processes that require less time slices
Three state diagram of process
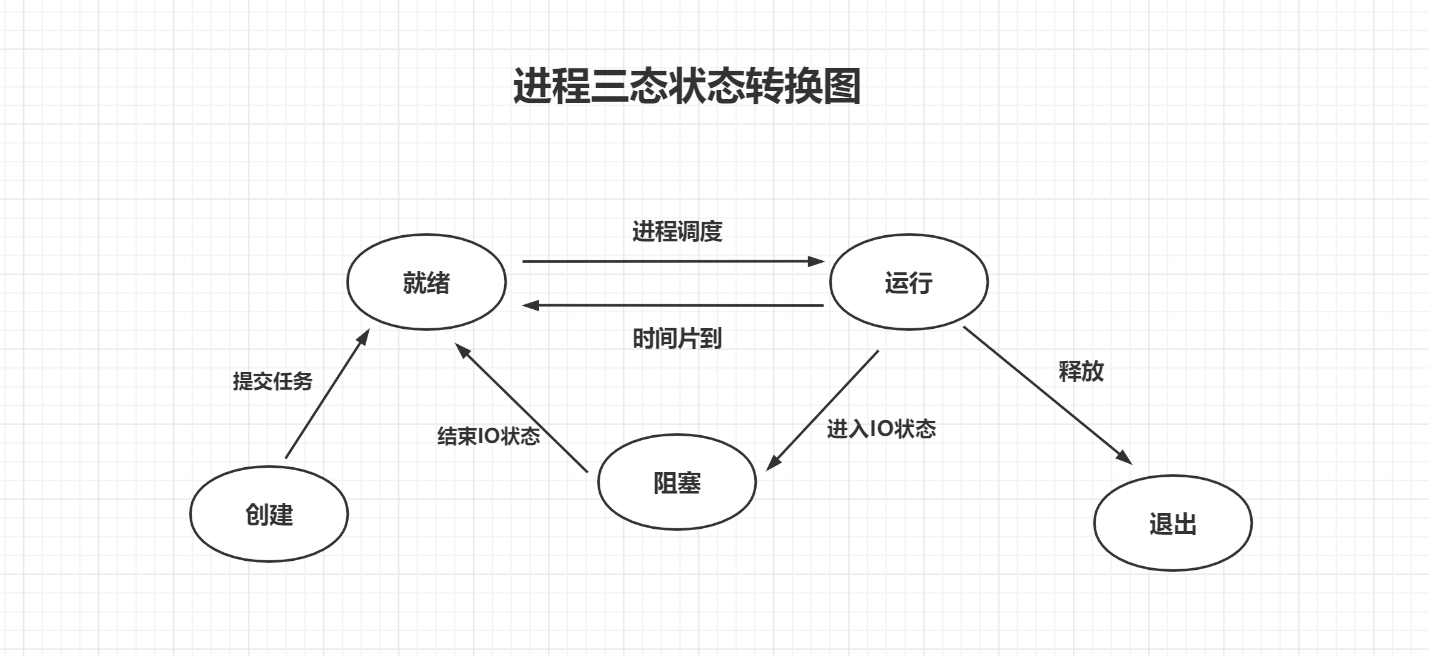
3. Synchronous asynchronous
synchronization
After submitting the task, the CPU waits in place for the returned information before executing other tasks
asynchronous
After submitting a task, you will not wait. You will perform other tasks first, and then come back for execution after receiving the returned information. There is a feedback mechanism
4. Blocking non blocking
block
Blocking status: IO operation, abnormal disconnection
Non blocking
Ready status and execution status
4, Code level creation process
1. There are two ways to create a process
Create process objects directly (primary)
from multiprocessing import Process
import time
import os
def run(name):
print(os.getpid()) # Get process number
print(os.getppid()) # Get parent process number
print('%s is running ' % name)
time.sleep(3)
print('%s is over' % name)
if __name__ == '__main__':
p = Process(target=run, arg=('elijah', )) # Generate a process object
p.start() # Tell the operating system to start the child process and then continue the asynchronous commit of the main process
print(os.getpid())
print('Main process')
'''
stay windows The setup process in is similar to the import module
Code execution from top to bottom
Be sure to__main__The code that executes the process in the judgment statement
Otherwise, the imported module will also execute the code to set up the process, which will fall into an endless loop
'''
'''
stay linux In, the code is directly copied and executed
No__main__Execute in judgment statement
'''
Creating process objects with classes
class MyProcess(Process):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
print('%s Running' % self.name)
time.sleep(3)
print('%s It's already over.' % self.name)
if __name__ == '__main__':
p = MyProcess('jason')
p.start()
print('main')
2. join method of process
After the main process sets up a sub process, it waits for the execution of the sub process to complete before proceeding
from multiprocessing import Process
import time
def run(name, n):
print('%s is running' % name)
time.sleep(n)
print('%s is over' % name)
if __name__ == '__main__':
start_time = time.time()
process_list = []
for i in range(1, 4):
p = Process(target=run, args=(i, i))
p.start()
process_list.append(p)
for p in process_list:
p.join()
print(time.time() - start_time)
print('Main process')
# Operation results
1 is running
2 is running
3 is running
1 is over
2 is over
3 is over
3.309438943862915 # execution time
Main process
'''
When the first p.join() When executing, only the main process waits in place for its execution to end
The other two subprocesses are not affected and will continue to execute
Therefore, the total time is the longest execution time of the sub process
'''
3. Processes cannot interact by default
Setting up a subroutine in the main program is equivalent to opening up another piece of memory and re executing the code (executed by the imported module, _main_ judging that the code in the statement will not be executed), then its data modification operation will not affect the data of the main process, because the processes cannot interact by default
from multiprocessing import Process
money = 100
def test():
global money
money = 90
if __name__ == '__main__':
p = Process(target=test)
p.start()
p.join()
print(money)
# results of enforcement
100
4. Process object method
1.current_process View process number 2.os.getpid() View process number os.getppid() View parent process number 3.The name of the process, p.name There is a direct default, or it can be passed in the form of keywords when instantiating the process object name='' 3.p.terminate() Kill child process 4.p.is_alive() Determine whether the process is alive 3,4 No results can be seen in combination, because the operating system needs reaction time. Main process 0.1 You can see the effect