I preface
Java streaming has been a feature for a long time, which can greatly reduce our code, and parallel processing can use multiple processor cores in some scenarios, which can greatly improve the performance
However, it will be difficult for novices to use Stream syntax. Take a look at this feature from shallow to deep in this document
This is the beginning, only record the usage combed before. Next, look at the source code, remember to collect!!!
Characteristics of Stream
- Stream is neither a collection nor a data structure and cannot save data
- Stream is somewhat similar to the advanced Iterator and can be used for algorithms and calculations
- Unlike iterators, streams can operate in parallel. Data is divided into many segments and processed in different threads
- Data source, zero or more intermediate operations, and zero or one terminal operation
- All intermediate operations are inert and will not have any effect until the pipeline starts working
- The terminal operation is a bit like a faucet. When the faucet is turned on, the water will flow and the intermediate operation will be executed

II Basic knowledge
2.1 structure operation
2.1.1 double colon operation
Double colon operation is to pass the method as a parameter to the required method (Stream), that is, the method reference
Case 1: basic usage
x -> System.out.println(x) // ------------ System.out::println
Case 2: complex usage
for (String item: list) {
AcceptMethod.printValur(item);
}
//------------------
list.faorEach(AcceptMethod::printValur);
2.2 creation of flow
2.2.1 set and array tools
Basic case
// Collection tool
Collection.stream () : list.stream();
Stream.<String>builder().add("a").add("b").add("c").build();
Stream.of("a", "b", "c")
Stream.generate(() -> "element").limit(10);
Stream.iterate(40, n -> n + 2).limit(20);
Create an integer stream
IntStream.rangeClosed(1, 100).reduce(0, Integer::sum); IntStream.rangeClosed(1, 100).parallel().reduce(0, Integer::sum); // Other basic types of cases LongStream.rangeClosed(1, 3);
Create a parallel stream
// API :
Stream<E> parallelStream()
// Case:
Collection.parallelStream ()
listOfNumbers.parallelStream().reduce(5, Integer::sum);
listOfNumbers.parallelStream().forEach(number ->
System.out.println(number + " " + Thread.currentThread().getName())
);
Array create stream
Arrays.stream(intArray).reduce(0, Integer::sum); Arrays.stream(intArray).parallel().reduce(0, Integer::sum); Arrays.stream(integerArray).reduce(0, Integer::sum); Arrays.stream(integerArray).parallel().reduce(0, Integer::sum);
Merge flow
// API: combine 2 Streams
<T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)
// case
Stream<Integer> stream1 = Stream.of(1, 3, 5);
Stream<Integer> stream2 = Stream.of(2, 4, 6);
Stream<Integer> resultingStream = Stream.concat(stream1, stream2);
// Case: merging three
Stream.concat(Stream.concat(stream1, stream2), stream3);
// Case: stream of merged streams
Stream.of(stream1, stream2, stream3, stream4)
Other cases
// Static factory
1. Java.util.stream.IntStream.range ( )
2. Java.nio.file.Files.walk ( )
// Create manually
1. java.util.Spliterator
2. Random.ints()
3. BitSet.stream()
4. Pattern.splitAsStream(java.lang.CharSequence)
5. JarFile.stream()
// java.io.BufferedReader.lines()
Files.lines(path, Charset.forName("UTF-8"));
Files.lines(path);
supplement
Split flow case
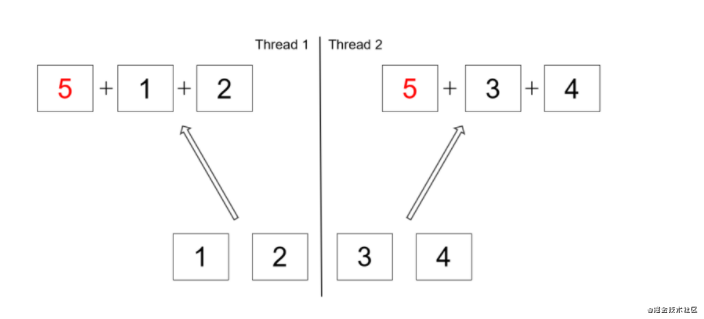
2.3 flow operation
A flow can have multiple intermediate operations and a Terminal operation. When the Terminal execution is completed, the flow ends
2.3.1 Intermediate operation of stream
map: element mapping
// API :
<R> Stream<R> map(Function<? super T, ? extends R> mapper)
// Map passes in the method function, and map returns an object
books.stream().filter(e -> "Effective Java".equals(e.getValue())).map(Map.Entry::getKey).findFirst();
wordList.stream().map(String::toUpperCase).collect(Collectors.toList());
Stream.of(1, 2, 3).map(n -> n + 1).collect(Collectors.toList());
nums.stream().map( n -> n * n ).collect (Collectors.toList());
flatMap
// flatMap returns a Stream
Stream<List<String>> namesOriginalList = Stream.of(
Arrays.asList("Pankaj"),
Arrays.asList("David", "Lisa"),
Arrays.asList("Amit"));
//flat the stream from List<String> to String stream
Stream<String> flatStream = namesOriginalList
.flatMap(strList -> strList.stream());
flatStream.forEach(System.out::println);
mapToXXX
// API : IntStream mapToInt(ToIntFunction<? super T> mapper) // Function: mapToXXX is mainly used to convert to doubleNumbers.stream().mapToDouble(Double::doubleValue).sum(); customers.stream().mapToInt(Customer::getAge).filter(c -> c > 65).count(); intStream1.mapToObj(c -> (char) c);
Filter: filter. The filtered elements are streamed down to generate a new stream
// Predicate is a functional interface
Stream<T> filter(Predicate<? super T> predicate)
// Use arrow expressions in filter
- tream<Integer> oddIntegers = ints.stream().filter(i -> i.intValue() % 2 != 0);
- list.stream().filter(p -> p.startsWith("j")).count()
// Use:: Double colon in Filter
customers.stream().filter(Customer::hasOverHundredPoints).collect(Collectors.toList());
// Code block used in Filter
customers.stream().filter(c -> {
try {
return c.hasValidProfilePhoto();
} catch (IOException e) {
//handle exception
}
return false;
}).collect(Collectors.toList());
distinct: de duplication
nums.stream().filter(num -> num % 2 == 0).distinct().collect(Collectors.toList()); list.stream().distinct().collect(Collectors.toList())
Sorted: sorted
// Custom sort method persons.stream().limit(2).sorted((p1, p2) -> p1.getName().compareTo(p2.getName())).collect(Collectors.toList()); // Use the sorter provided by the specified Comparator List<String> reverseSorted = names2.sorted(Comparator.reverseOrder()).collect(Collectors.toList()); // The default sort method is not used for incoming parameters List<String> naturalSorted = names3.sorted().collect(Collectors.toList());
peek
// API: it can be used for debugging, mainly intercepting the flow when it passes through a point in the pipeline
Stream<T> peek(Consumer<? super T> action)
// Case:
IntStream.range(1, 10).peek(System.out::println).sum();
// Intercept at multiple intercept points
Stream.of("one", "two", "three", "four")
.filter(e -> e.length() > 3)
.peek(e -> System.out.println("Filtered value: " + e))
.map(String::toUpperCase)
.peek(e -> System.out.println("Mapped value: " + e))
.collect(Collectors.toList());
Limit: limit
// API: the number of truncated streams. You can see or return a stream Stream<T> limit(long maxSize); // Case: nums.stream().filter(n-> n>2).limit(2).collect(Collectors.toList ())
Skip: skip
// API : Stream<T> skip(long n); // Case: nums. stream() .filter(n-> n>2 ).skip (2) . collect( Collectors . toList () );
Parallel parallel flow
// API: returns a parallel equivalent stream. If it is already parallel, it returns itself S parallel() boolean isParallel() // Case: Object[] listOutput = list.stream().parallel().toArray();
sequential: serial stream
// API : S sequential(); // Case: Arrays.asList(1, 2, 3, 4).stream().sequential();
Unordered: unordered
// Parallel performance can be committed by eliminating the encounter order IntStream.range(1, 1_000_000).unordered().parallel().distinct().toArray();
2.3.2 aggregation of Terminal operations of streams
foreach: loop traversal
// API: as you can see, a Consumer function is accepted here void forEach(Consumer<? super T> action); // Using arrow functions in foreach roster.stream().forEach(p -> System.out.println(p.getName()));
forEachOrdered: ordered circular flow
list.stream().parallel().forEachOrdered(e -> logger.info(e));
Array
stream.toArray(String[]::new);
//reduce: combine Stream elements
Stream.of("A", "B", "C", "D").reduce("", String::concat);
// reduce sum
Stream.of(5, 6, 7, 8).reduce(0, (accumulator, element) -> accumulator + element);
?--- reduce Subsequent parameters : First default , Followed by the incoming method
// min: maximizes the string array
Stream.of(testStrings).max((p1, p2) -> Integer.compare(p1.length(), p2.length()));
// max: get the maximum length
br.lines().mapToInt(String::length).max().getAsInt();
collection
- stream. Collect (collectors. Tolist()): tolist collects all elements in the stream into a List
- stream.collect(Collectors.toCollection(ArrayList::new)): collect the elements in the stream into the collection created by the given supply source
- stream.collect(Collectors.toSet()): save all elements in the stream to the Set set, and delete duplicate locks
- stream.collect(Collectors.toCollection(Stack::new))
// API
<R> R collect(Supplier<R> supplier,BiConsumer<R, ? super T> accumulator,BiConsumer<R, R> combiner);
<R, A> R collect(Collector<? super T, A, R> collector);
Map<String, Integer> hashMap = list.stream().collect(Collectors
.toMap(Function.identity(), String::length));
Map<String, Integer> linkedHashMap = list.stream().collect(Collectors.toMap(
Function.identity(),
String::length,
(u, v) -> u,
LinkedHashMap::new
));
// Create Collection object
Stream<Integer> intStream = Stream.of(1,2,3,4);
List<Integer> intList = intStream.collect(Collectors.toList());
System.out.println(intList); //prints [1, 2, 3, 4]
intStream = Stream.of(1,2,3,4); //stream is closed, so we need to create it again
Map<Integer,Integer> intMap = intStream.collect(Collectors.toMap(i -> i, i -> i+10));
System.out.println(intMap); //prints {1=11, 2=12, 3=13, 4=14}
// Create an Array object
Stream<Integer> intStream = Stream.of(1,2,3,4);
Integer[] intArray = intStream.toArray(Integer[]::new);
System.out.println(Arrays.toString(intArray)); //prints [1, 2, 3, 4]
// String operation
stream.collect(Collectors.joining()).toString();
list.stream().collect(Collectors.joining(" | ")) : Interspersed between connectors
list.stream().collect(Collectors.joining(" || ", "Start--", "--End")) : Middle and front and back of connector
// Create as Map
books.stream().collect(Collectors.toMap(Book::getIsbn, Book::getName));
// ps : Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,Function<? super T, ? extends U> valueMapper)
2.3.3 operation of Terminal operation of stream
min: returns the smallest element of this stream
// API
Optional<T> min(Comparator<? super T> comparator)
Collector<T, ?, Optional<T>> minBy(Comparator<? super T> comparator)
// Case:
list.stream().min(Comparator.comparing(String::valueOf)).ifPresent(e -> System.out.println("Min: " + e));
max: returns the maximum element of this stream
// API
Optional<T> max(Comparator<? super T> comparator);
Collector<T, ?, Optional<T>> maxBy(Comparator<? super T> comparator)
// Case:
list.stream().max(Comparator.comparing(String::valueOf)).ifPresent(e -> System.out.println("Max: " + e));
Count: count the number of items in the flow
// API : <T> Collector<T, ?, Long>javacounting() // Case: Stream.of(1,2,3,4,5).count();
reduce
// API: reduce is used for calculation and processing in Stream
Optional<T> reduce(BinaryOperator<T> accumulator);
Collector<T, ?, T> reducing(T identity, BinaryOperator<T> op)
U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner);
Collector<T, ?, U> reducing(U identity,Function<? super T, ? extends U> mapper,BinaryOperator<U> op)
// Parameter meaning:
identity : Reduced identification value(It is also the value returned when there is no input element)
accumulator : Actions performed
// Use case
numbers.reduce((i,j) -> {return i*j;});
numbers.stream().reduce(0, (subtotal, element) -> subtotal + element);
numbers.stream().reduce(0, Integer::sum);
// Association string
letters.stream().reduce("", (partialString, element) -> partialString + element);
// Associated case
letters.stream().reduce("", (partialString, element) -> partialString.toUpperCase() + element.toUpperCase());
ages.parallelStream().reduce(0, a, b -> a + b, Integer::sum);
// Key points of parallel operation: parallel processing operations must comply with the following operations
1. The result is not affected by the order of operands
2. Mutual non-interference: The operation does not affect the data source
3. Stateless and deterministic: The operation has no state and generates the same output for the given input
userList.parallelStream().reduce(0, (partialAgeResult, user) -> partialAgeResult + user.getAge(), Integer::sum);
2.4 search of Terminal operation of stream
anyMatch: any element meets the matching condition
// API: as long as one element in the stream matches the incoming predicate, it returns true boolean anyMatch(Predicate<? super T> predicate); // Case: persons.stream(). anyMatch(p -> p.getAge() < 12);
allMatch: all elements meet the matching conditions
// API: all elements in the stream conform to the passed in predicate and return true boolean allMatch(Predicate<? super T> predicate); // Case: persons.stream(). allMatch(p -> p.getAge() > 18);
findFirst: returns the first element in the Stream
// API: returns the first element of an Optional identifier Optional<T> findFirst(); // Case: students.stream().filter(student ->student .getage()>20 ).findFirst();
findAny: returns any element in the Stream
// API: findany does not necessarily return the first one, but any one. If the stream is empty, it returns an empty option Optional<T> findAny();
noneMatch: all elements do not meet the matching condition
// API: returns true when none of the elements in the Stream matches the incoming predicate boolean noneMatch(Predicate<? super T> predicate); // Case: numbers5.noneMatch(i -> i==10)
2.5 stream protocol
// reduce: perform further operations on the set after parameterization
students.stream().filter(student -> "computer science".equals(student.getMajor())).map(Student::getAge).reduce(0, (a, b) -> a + b);
students.stream().filter(student -> "computer science".equals(student.getMajor())).map(Student::getAge).reduce(0, Integer::sum);
students.stream().filter(student -> "computer science".equals(student.getMajor())).map(Student::getAge).reduce(Integer::sum);
2.6 flow grouping (Group By)
Single level grouping
// API : public static <T, K> Collector<T, ?, Map<K, List<T>>>groupingBy(Function<? super T, ? extends K> classifier) students.stream().collect(Collectors.groupingBy(Student::getSchool))
Multilevel grouping
// effect:
// Case:
students.stream().collect(
Collectors.groupingBy(Student::getSchool,
Collectors.groupingBy(Student::getMajor)));
partitioningBy: partition. It is different from groupBy. There are only true and false in the partition
// API: you can see that the Predicate function is mainly used here
Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate)
Collector<T, ?, Map<Boolean, D>> partitioningBy(Predicate<? super T> predicate,Collector<? super T, A, D> downstream)
// Case:
students.stream().collect(Collectors.partitioningBy(student -> "WuHan University".equals(student.getSchool())));
III Use depth
3.1 extended thread pool
// Set thread pool globally
-D java.util.concurrent.ForkJoinPool.common.parallelism=4
// Manually set this thread
ForkJoinPool customThreadPool = new ForkJoinPool(4);
int sum = customThreadPool.submit(
() -> listOfNumbers.parallelStream().reduce(0, Integer::sum)).get();
customThreadPool.shutdown();
3.2 Debug handling
IV Common cases
Case 1: after the operation conversion of each element in list list list, another type C is generated and put into List BList
List<JSONObject> itemjson = new LinkedList<JSONObject>();
List<A> aList = ...
itemCW.stream().map(c -> {
JSONObject nodeitem = new JSONObject();
nodeitem.put("whtype", 0);
return nodeitem;
}).forEach(c -> itemjson.add(c));
Case 2: circular operation on Map
realmTO.getTemplates().forEach((key, template) -> {
AnyType type = anyTypeDAO.find(key);
anyTemplate.set(template);
});
// For each, you can pass in key s and objects, which can be used later
Case 3: get a small set from a large set
// Gets the collection of IDS List<Long> idList = stockList.stream().map(Stock::getId).collect(Collectors.toList()); // Get the skuid set and remove the duplicate List<Long> skuIdList = stockList.stream().map(Stock::getSkuId).distinct().collect(Collectors.toList()); // Get the supplierId set (the type of supplierId is int, return list < integer >, and use the boxed method to pack) Set<Integer> supplierIdSet = stockList.stream().mapToInt(Stock::getSupplierId).boxed().collect(Collectors.toSet());
Case 4: grouping and slicing
// Group by skuid Map<Long, List<Stock>> skuIdStockMap = stockList.stream().collect(Collectors.groupingBy(Stock::getSkuId)); // Filter supplierId=1 and group by skuId Map<Long, List<Stock>> filterSkuIdStockMap = stockList.stream().filter(s -> s.getSupplierId() == 1).collect(Collectors.groupingBy(Stock::getSkuId)); // It is divided into unavailable and other two pieces by status Map<Boolean, List<Stock>> partitionStockMap = stockList.stream().collect(Collectors.partitioningBy(s -> s.getStatus() == 0));
Case 5: counting and summation
// Count the number of records with skuId=1 long skuIdRecordNum = stockList.stream().filter(s -> s.getSkuId() == 1).count(); // Statistics of total stock of skuId=1 BigDecimal skuIdAmountSum = stockList.stream().filter(s -> s.getSkuId() == 1).map(Stock::getAmount).reduce(BigDecimal.ZERO, BigDecimal::add);
Case 6: specific usage
// Multiple grouping and sorting: first group by supplierId, and then group by skuId. Sorting rules: supplierId first, then skuId
Map<Integer, Map<Long, List<Stock>>> supplierSkuStockMap = stockList.stream().collect(Collectors.groupingBy(Stock::getSupplierId, TreeMap::new,
Collectors.groupingBy(Stock::getSkuId, TreeMap::new, Collectors.toList())));
// Multi condition sorting, first in positive order by supplierId, and then in reverse order by skuId
// (not the stream method, but the sort method of the collection. Directly change the elements of the original collection and use the Function parameter)
stockList.sort(Comparator.comparing(Stock::getSupplierId)
.thenComparing(Stock::getSkuId, Comparator.reverseOrder()));
Case 7: sorting by convection
Collections.sort(literals, (final String t, final String t1) -> {
if (t == null && t1 == null) {
return 0;
} else if (t != null && t1 == null) {
return -1;
}
});
// T1 and T2 are the two objects in which the comparison is made. The relevant sorting methods are defined in them, and the sorting rules are returned by returning true / false
Case 8: after the convection filter, the first one is obtained
correlationRules.stream().filter(rule -> anyType != null && anyType.equals(rule.getAnyType())).findFirst()
// The key is filter and findFirst
Case 9: converting a type set to another type set
List<String> strings = Lists.transform(list, new Function<Integer, String>() {
@Override
public String apply(@Nullable Integer integer) {
return integer.toString();
}
});
Case 10: traverse the set and return the set
return Stream.of(resources).map(resource -> preserveSubpackageName(baseUrlString, resource, path)).collect(Collectors.toList());
private String preserveSubpackageName(final String baseUrlString, final Resource resource, final String rootPath) {
try {
return rootPath + (rootPath.endsWith("/") ? "" : "/")
+ resource.getURL().toString().substring(baseUrlString.length());
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
// Note that the following method is invoked, and the direct anonymous method can not be written for the time being.
Case 11: simple splicing
// Spliced into [x, y, z] form
String result1 = stream1.collect(Collectors.joining(", ", "[", "]"));
// Spliced into x | y | z form
String result2 = stream2.collect(Collectors.joining(" | ", "", ""));
// Spliced into X - > y - > Z] form
String result3 = stream3.collect(Collectors.joining(" -> ", "", ""));
(String)value.stream().map((i) -> {
return this.formatSql("{0}", i);
}).collect(Collectors.joining(",", "(", ")"));
Case 12: complex use
buzChanlList.stream()
.map(item -> {
return null;
})
.filter(item -> {
return isok;
})
.forEach(c -> contentsList.add(c));
Case 13: segmentation set
List<List<Integer>> splitList = Stream.iterate(0, n -> n + 1).limit(limit).parallel().map(a -> list.stream().skip(a * MAX_NUMBER).limit(MAX_NUMBER).parallel().collect(Collectors.toList())).collect(Collectors.toList());
Case 14: filter operation
collection.stream().filter(person -> "1".equals(person.getGender())).collect(Collectors.toList())
summary
The parallelism of streams can greatly increase efficiency when used properly
Some time ago, when chatting with group friends, I sorted out some different types of interview questions they saw this year, so I have the following interview question set and share it with you~
If you think these contents are helpful to you, you can join csdn advanced AC group , get data

Basic chapter


JVM chapter


MySQL



Redis



Due to space constraints, the detailed information is too comprehensive and there are too many details, so only the screenshots of some knowledge points are roughly introduced. There are more detailed contents in each small node!
If you think these contents are helpful to you, you can join csdn advanced AC group , get data