1. Introduction to Orch
Orchestrator (orch): MySQL high availability and replication topology management tool written by go, which supports the adjustment of replication topology, automatic failover and manual master-slave switching. The back-end database uses MySQL or SQLite to store metadata, and provides a Web interface to display the topology relationship and status of MySQL replication. The replication relationship and some configuration information of MySQL instances can be changed through the Web. At the same time, it also provides command line and api interfaces to facilitate operation and maintenance management. Compared with MHA, the most important thing is to solve the single point problem of the management node, which ensures its high availability through the raft protocol. Part of GitHub is also managed with this tool.
function
① Automatically discover the replication topology of MySQL and display it on the web.
② To reconstruct the replication relationship, you can drag the graph on the web to change the replication relationship.
③ Detect the main exception and recover it automatically or manually. Customize the script through Hooks.
④ Support command line and web interface to manage replication.
2. ORCH deployment planning
Node planning table (3306 is the ORCH back-end database and 8026 is the mysql master-slave architecture)
| IP address | host name | Install software | Database port |
|---|---|---|---|
| 172.31.0.101 | Wl01 | orchestrator,mysql | 3306,8026 |
| 172.31.0.102 | Wl02 | orchestrator,mysql | 3306,8026 |
| 172.31.0.103 | Wl03 | orchestrator,mysql | 3306,8026 |
Each software version
| Software name | edition | Download address |
|---|---|---|
| MySQL | 8.0.26 | https://downloads.mysql.com/archives/community/ |
| Orchestrator | version: 3.2.6 | https://github.com/openark/orchestrator |
mysql database directory planning
| MySQL directory function | route |
|---|---|
| basedir | /usr/loca/mysql-8026 |
| datadir | /mysql-8026/8026/data/ |
| errorlog | /mysql-8026/8026/log/error.log |
| binlogdir | /mysql-8026/8026/binlog/ |
| relaylogdir | /mysql-8026/8026/relaylog/ |
| Tmpdir | /mysql-8026/8026/tmp |
| pid | /mysql-8026/8026/run/mysql-8026.pid |
| socket | /mysql-8026/8026/run/mysql-8026.sock |
orchestrator database directory planning
| orchestrator directory role | route |
|---|---|
| basedir | /usr/loca/mysql-8026 |
| datadir | /mysql-8026/3306/data/ |
| errorlog | /mysql-8026/3306/log/error.log |
| binlogdir | /mysql-8026/3306/binlog/ |
| relaylogdir | /mysql-8026/3306/relaylog/ |
| Tmpdir | /mysql-8026/3306/tmp |
| pid | /mysql-8026/3306/run/mysql-8026.pid |
| socket | /mysql-8026/3306/run/mysql-8026.sock |
3. Environmental preparation
3.1 environmental preparation (all nodes)
#Install dependent software
[root@wl01 ~]# yum install -y gcc gcc-c++ ncurses-devel.x86_64 libaio bison gcc-c++.x86_64 perl perl-devel libssl-dev autoconf openssl-devel openssl numactl wget *libncurses.so.5*
#Configure environment variables
#Upload the prepared mysql-8.0.26 binary compressed package to the / opt directory
[root@wl01 ~]# cd /opt/
[root@wl01 opt]# tar xf mysql-8.0.26-linux-glibc2.12-x86_64.tar.xz
[root@wl01 opt]# ln -s /opt/mysql-8.0.26-linux-glibc2.12-x86_64 /usr/local/mysql-8026
[root@wl01 opt]# ll /usr/local/mysql-8026
lrwxrwxrwx 1 root root 40 Jan 14 16:59 /usr/local/mysql-8026 -> /opt/mysql-8.0.26-linux-glibc2.12-x86_64
[root@wl01 opt]# echo "export PATH=/usr/local/mysql-8026/bin:$PATH">> /etc/profile
[root@wl01 opt]# source /etc/profile
[root@wl01 opt]# mysql -V
mysql Ver 8.0.26 for Linux on x86_64 (MySQL Community Server - GPL)
#Configure domain name resolution
[root@wl01 opt]# vim /etc/hosts
172.31.0.101 wl01
172.31.0.102 wl02
172.31.0.103 wl03
#Configure mutual trust
rm -rf /root/.ssh #Clean up old ssh keys
ssh-keygen #Generate a new key and press enter all the way
ssh-copy-id root@wl01 #input root@wl01 Password for
ssh-copy-id root@wl02 #input root@wl02 Password for
ssh-copy-id root@wl03 #input root@wl03 Password for
#Mutual trust verification of each node
ssh root@wl01 date
ssh root@wl02 date
ssh root@wl03 date
#Disable firewall
systemctl stop firewalld.service
systemctl disable firewalld.service
#Create user and directory
useradd mysql -M -s /sbin/nologin
mkdir -p /mysql-8026/8026/{binlog,relaylog,data,log,run,tmp}
mkdir -p /mysql-8026/3306/{binlog,relaylog,data,log,run,tmp}
chown -R mysql.mysql /mysql-8026
3.2 create all instances
`Note that different nodes modify the corresponding server_id,report_host,report_port` #Edit configuration file (taking orch library as an example) #When configuring the MySQL library, replace the port number in the configuration file in batches sed - I's / 3306 / 8026 / g '/ mysql-8026 / 8026 / my cnf vim /mysql-8026/3306/my.cnf [mysql] no-auto-rehash max_allowed_packet=128M prompt="\u@\h \R:\m:\s[\d]> " default_character_set=utf8mb4 socket=/mysql-8026/3306/run/mysql.sock [mysqldump] quick max_allowed_packet=128M socket=/mysql-8026/3306/run/mysql.sock [mysqladmin] socket=/mysql-8026/3306/run/mysql.sock [mysqld] user=mysql port=3306 report_host='172.31.0.101' report_host=3306 server-id=1013306 # ip end + port number default-time_zone='+8:00' log_timestamps=SYSTEM datadir=/mysql-8026/3306/data basedir=/usr/local/mysql-8026 tmpdir=/mysql-8026/3306/tmp socket=/mysql-8026/3306/run/mysql.sock pid-file=/mysql-8026/3306/run/mysql.pid character-set-server=utf8mb4 ##redolog innodb_log_file_size=2G innodb_log_buffer_size=16M innodb_log_files_in_group=2 innodb_log_group_home_dir=/mysql-8026/3306/data ##undolog innodb_undo_directory=/mysql-8026/3306/data innodb_max_undo_log_size=2G innodb_undo_log_truncate=on #innodb_undo_tablespaces=4 #8.0.14 deleted, additional undo tablespaces can be created using SQL ##binlog binlog_format=row log-bin=/mysql-8026/3306/binlog/mysql-bin max_binlog_size=1G binlog_cache_size=1M sync_binlog=1 ##relaylog relay-log=/mysql-8026/3306/relaylog/mysql-relay relay-log-purge=on relay-log-recovery=on ##general log #general_log=on #general_log_file=/mysql-8026/3306/log/general.log ##error log log-error=/mysql-8026/3306/log/error.log ##slow log long_query_time=1 slow-query-log=on slow-query-log-file=/mysql-8026/3306/log/slow.log ##connection skip-external-locking skip-name-resolve max_connections=4000 max_user_connections=2500 max_connect_errors=10000 wait_timeout=7200 interactive_timeout=7200 connect_timeout=20 max_allowed_packet=512M ##gtid gtid_mode=on enforce_gtid_consistency=1 #log_slave_updates=1 log_replica_updates=1 #8.0 ##parallel replication mysql>5.7.22 # master loose-binlog_transaction_dependency_tracking=WRITESET #loose-transaction_write_set_extraction=XXHASH64 #Before 8.0 binlog_transaction_dependency_history_size=25000 #default # slave #slave-parallel-type=LOGICAL_CLOCK replica_parallel_type=LOGICAL_CLOCK #8.0 #slave-parallel-workers=4 #Before 8.0 replica_parallel_workers=4 #8.0 #master_info_repository=TABLE #Before 8.0 #relay_log_info_repository=TABLE #Before 8.0 ##memory size key_buffer_size=2M table_open_cache=2048 table_definition_cache=4096 sort_buffer_size=2M read_buffer_size=2M read_rnd_buffer_size=2M join_buffer_size=2M myisam_sort_buffer_size=2M tmp_table_size=64M max_heap_table_size=64M ##lock and transaction transaction_isolation=READ-COMMITTED innodb_lock_wait_timeout=30 lock_wait_timeout=3600 ##InnoDB innodb_data_home_dir=/mysql-8026/3306/data innodb_data_file_path=ibdata1:1G:autoextend innodb_buffer_pool_size=1G innodb_buffer_pool_instances=2 innodb_flush_log_at_trx_commit=1 innodb_max_dirty_pages_pct=75 innodb_flush_method=O_DIRECT innodb_file_per_table=1 innodb_read_io_threads=16 innodb_write_io_threads=16 innodb_io_capacity=2000 innodb_io_capacity_max=4000 innodb_purge_threads=2 #Initialization start mysqld --defaults-file=/mysql-8026/3306/my.cnf --initialize-insecure mysqld_safe --defaults-file=/mysql-8026/3306/my.cnf & mysql -S /mysql-8026/3306/run/mysql.sock mysqld --defaults-file=/mysql-8026/8026/my.cnf --initialize-insecure mysqld_safe --defaults-file=/mysql-8026/8026/my.cnf & mysql -S /mysql-8026/8026/run/mysql.sock
3.3 configure all instances
`(1)Get software(All nodes) wget https://github.com/openark/orchestrator/releases/download/v3.2.6/orchestrator-3.2.6-1.x86_64.rpm wget https://github.com/openark/orchestrator/releases/download/v3.2.6/orchestrator-cli-3.2.6-1.x86_64.rpm `(2)Install software(All nodes) ll /opt/orch* -rw-r--r-- 1 root root 10970627 May 11 13:37 /opt/orchestrator-3.2.6-1.x86_64.rpm -rw-r--r-- 1 root root 10543813 May 11 13:39 /opt/orchestrator-cli-3.2.6-1.x86_64.rpm yum localinstall -y orchestrator-* #If you encounter an error (error: package: Requirements: * * * * JQ > = 1.5 * *), please solve it as follows wget http://www6.atomicorp.com/channels/atomic/centos/7/x86_64/RPMS/oniguruma-5.9.5-3.el7.art.x86_64.rpm yum install -y oniguruma-5.9.5-3.el7.art.x86_64.rpm wget http://www6.atomicorp.com/channels/atomic/centos/7/x86_64/RPMS/jq-1.5-1.el7.art.x86_64.rpm yum install -y jq-1.5-1.el7.art.x86_64.rpm `(3)to configure orch Database and users(All 3306 instances) mysql -S /mysql-8026/3306/run/mysql.sock CREATE DATABASE IF NOT EXISTS orchdb; CREATE USER 'orchuser'@'127.0.0.1' IDENTIFIED BY '123456'; GRANT ALL ON orchdb.* TO 'orchuser'@'127.0.0.1'; `(4)The managed node configures the master-slave relationship(All 8026 instances) # Create replication dedicated user from master library mysql -S /mysql-8026/8026/run/mysql.sock create user 'repl'@'172.31.0.%' IDENTIFIED WITH mysql_native_password BY '123456'; GRANT replication slave on *.* TO 'repl'@'172.31.0.%'; flush privileges; # From library #It should be noted here that orch's detection of the downtime of the master library depends on the IO thread of the slave Library (after it cannot connect to the master library, it will also detect whether the master library is abnormal through the slave Library). Therefore, the waiting time for the master and slave to perceive the downtime of the master library built by default change is too long, which needs to be slightly changed: mysql -S /mysql-8026/8026/run/mysql.sock reset master; change master to master_host='172.31.0.102', master_port=8026, master_user='repl', master_password='123456', master_auto_position=1, MASTER_HEARTBEAT_PERIOD=2, MASTER_CONNECT_RETRY=1, MASTER_RETRY_COUNT=86400; start slave; set global slave_net_timeout=8; set global read_only=1; set global super_read_only=1; #explain: slave_net_timeout(Global variable: MySQL5.7.7 After that, the default is changed to 60 seconds. This parameter defines the number of seconds to wait for the slave library to obtain data from the master library. After this time, the slave library will actively quit reading, interrupt the connection, and try to reconnect. master_heartbeat_period: Copy the cycle of the heartbeat. The default is slave_net_timeout Half. Master When there is no data, every master_heartbeat_period Send a heartbeat packet in seconds, so Slave You can know Master Is it normal. slave_net_timeout:Is to set how long the network timeout is considered after the data is not received, and then Slave of IO The thread reconnects Master . Combining these two settings can avoid replication delays caused by network problems. master_heartbeat_period The unit is seconds, which can be a number with decimals, such as 10.5,The maximum accuracy is 1 millisecond. `(5)Managed MySQL User permissions for the database(Main library 172.31.0.101 8026 node) CREATE USER 'orchctl'@'%' IDENTIFIED WITH mysql_native_password BY '123456'; GRANT SUPER, PROCESS, REPLICATION SLAVE,REPLICATION CLIENT, RELOAD ON *.* TO 'orchctl'@'%'; GRANT SELECT ON mysql.slave_master_info TO 'orchctl'@'%';
4. Prepare configuration files and scripts
4.1 modify the ORCH configuration file
cp /usr/local/orchestrator/orchestrator-sample.conf.json /etc/orchestrator.conf.json
vim /etc/orchestrator.conf.json
{
"Debug": true,
"EnableSyslog": false,
"ListenAddress": ":3000",
"MySQLTopologyUser": "orchctl",
"MySQLTopologyPassword": "123456",
"MySQLTopologyCredentialsConfigFile": "",
"MySQLTopologySSLPrivateKeyFile": "",
"MySQLTopologySSLCertFile": "",
"MySQLTopologySSLCAFile": "",
"MySQLTopologySSLSkipVerify": true,
"MySQLTopologyUseMutualTLS": false,
"BackendDB": "mysql",
"MySQLOrchestratorHost": "127.0.0.1",
"MySQLOrchestratorPort": 3306,
"MySQLOrchestratorDatabase": "orchdb",
"MySQLOrchestratorUser": "orchuser",
"MySQLOrchestratorPassword": "123456",
"MySQLConnectTimeoutSeconds": 1,
"DefaultInstancePort": 3306,
"DiscoverByShowSlaveHosts": true,
"InstancePollSeconds": 5,
"DiscoveryIgnoreReplicaHostnameFilters": [
"a_host_i_want_to_ignore[.]example[.]com",
".*[.]ignore_all_hosts_from_this_domain[.]example[.]com",
"a_host_with_extra_port_i_want_to_ignore[.]example[.]com:3307"
],
"UnseenInstanceForgetHours": 240,
"SnapshotTopologiesIntervalHours": 0,
"InstanceBulkOperationsWaitTimeoutSeconds": 10,
"HostnameResolveMethod": "default",
"MySQLHostnameResolveMethod": "@@hostname",
"SkipBinlogServerUnresolveCheck": true,
"ExpiryHostnameResolvesMinutes": 60,
"RejectHostnameResolvePattern": "",
"ReasonableReplicationLagSeconds": 10,
"ProblemIgnoreHostnameFilters": [],
"VerifyReplicationFilters": false,
"ReasonableMaintenanceReplicationLagSeconds": 20,
"CandidateInstanceExpireMinutes": 60,
"AuditLogFile": "",
"AuditToSyslog": false,
"RemoveTextFromHostnameDisplay": ".mydomain.com:3306",
"ReadOnly": false,
"AuthenticationMethod": "",
"HTTPAuthUser": "",
"HTTPAuthPassword": "",
"AuthUserHeader": "",
"PowerAuthUsers": [
"*"
],
"ClusterNameToAlias": {
"127.0.0.1": "test suite"
},
"ReplicationLagQuery": "",
"DetectClusterAliasQuery": "SELECT SUBSTRING_INDEX(@@hostname, '.', 1)",
"DetectClusterDomainQuery": "",
"DetectInstanceAliasQuery": "",
"DetectPromotionRuleQuery": "",
"DataCenterPattern": "[.]([^.]+)[.][^.]+[.]mydomain[.]com",
"PhysicalEnvironmentPattern": "[.]([^.]+[.][^.]+)[.]mydomain[.]com",
"PromotionIgnoreHostnameFilters": [],
"DetectSemiSyncEnforcedQuery": "",
"ServeAgentsHttp": false,
"AgentsServerPort": ":3001",
"AgentsUseSSL": false,
"AgentsUseMutualTLS": false,
"AgentSSLSkipVerify": false,
"AgentSSLPrivateKeyFile": "",
"AgentSSLCertFile": "",
"AgentSSLCAFile": "",
"AgentSSLValidOUs": [],
"UseSSL": false,
"UseMutualTLS": false,
"SSLSkipVerify": false,
"SSLPrivateKeyFile": "",
"SSLCertFile": "",
"SSLCAFile": "",
"SSLValidOUs": [],
"URLPrefix": "",
"StatusEndpoint": "/api/status",
"StatusSimpleHealth": true,
"StatusOUVerify": false,
"AgentPollMinutes": 60,
"UnseenAgentForgetHours": 6,
"StaleSeedFailMinutes": 60,
"SeedAcceptableBytesDiff": 8192,
"PseudoGTIDPattern": "",
"PseudoGTIDPatternIsFixedSubstring": false,
"PseudoGTIDMonotonicHint": "asc:",
"DetectPseudoGTIDQuery": "",
"BinlogEventsChunkSize": 10000,
"SkipBinlogEventsContaining": [],
"ReduceReplicationAnalysisCount": true,
"FailureDetectionPeriodBlockMinutes": 5,
"RecoveryPeriodBlockSeconds": 30,
"RecoveryIgnoreHostnameFilters": [],
"RecoverMasterClusterFilters": [
"*"
],
"RecoverIntermediateMasterClusterFilters": [
"*"
],
"OnFailureDetectionProcesses": [
"echo '`date +'%Y-%m-%d %T'` Detected {failureType} on {failureCluster}. Affected replicas: {countSlaves}' >> /tmp/recovery.log"
],
"PreGracefulTakeoverProcesses": [
"echo '`date +'%Y-%m-%d %T'` Planned takeover about to take place on {failureCluster}. Master will switch to read_only' >> /tmp/recovery.log"
],
"PreFailoverProcesses": [
"echo '`date +'%Y-%m-%d %T'` Will recover from {failureType} on {failureCluster}' >> /tmp/recovery.log"
],
"PostFailoverProcesses": [
"echo '`date +'%Y-%m-%d %T'` (for all types) Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}; failureClusterAlias:{failureClusterAlias}' >> /tmp/recovery.log",
"/usr/local/orchestrator/orch_hook.sh {failureType} {failureClusterAlias} {failedHost} {successorHost} >> /tmp/orch.log"
],
"PostUnsuccessfulFailoverProcesses": [ "echo '`date +'%Y-%m-%d %T'` Unsuccessful Failover ' >> /tmp/recovery.log"],
"PostMasterFailoverProcesses": [
"echo '`date +'%Y-%m-%d %T'` Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Promoted: {successorHost}:{successorPort}' >> /tmp/recovery.log"
],
"PostIntermediateMasterFailoverProcesses": [
"echo '`date +'%Y-%m-%d %T'` Recovered from {failureType} on {failureCluster}. Failed: {failedHost}:{failedPort}; Successor: {successorHost}:{successorPort}' >> /tmp/recovery.log"
],
"PostGracefulTakeoverProcesses": [
"echo '`date +'%Y-%m-%d %T'` Planned takeover complete' >> /tmp/recovery.log"
],
"CoMasterRecoveryMustPromoteOtherCoMaster": true,
"DetachLostSlavesAfterMasterFailover": true,
"ApplyMySQLPromotionAfterMasterFailover": true,
"PreventCrossDataCenterMasterFailover": false,
"PreventCrossRegionMasterFailover": false,
"MasterFailoverDetachReplicaMasterHost": false,
"MasterFailoverLostInstancesDowntimeMinutes": 0,
"PostponeReplicaRecoveryOnLagMinutes": 0,
"OSCIgnoreHostnameFilters": [],
"GraphiteAddr": "",
"GraphitePath": "",
"GraphiteConvertHostnameDotsToUnderscores": true,
"ConsulAddress": "",
"ConsulAclToken": "",
"RaftEnabled":true,
"RaftDataDir":"/usr/local/orchestrator",
"RaftBind":"172.31.0.101",
"DefaultRaftPort":10008,
"RaftNodes":[
"172.31.0.101",
"172.31.0.102",
"172.31.0.103"
]
}
4.2 modify orch_hook.sh
vi /usr/local/orchestrator/orch_hook.sh
#!/bin/bash
isitdead=$1
cluster=$2
oldmaster=$3
newmaster=$4
mysqluser="orchctl"
logfile="/usr/local/orchestrator/orch_hook.log"
# list of clusternames
#clusternames=(rep blea lajos)
# clustername=( interface IP user Inter_IP)
#rep=( ens32 "192.168.56.121" root "192.168.56.125")
if [[ $isitdead == "DeadMaster" ]]; then
array=( eth0 "172.31.0.188" root "172.31.0.101")
interface=${array[0]}
IP=${array[1]}
user=${array[2]}
if [ ! -z ${IP} ] ; then
echo $(date)
echo "Revocering from: $isitdead"
echo "New master is: $newmaster"
echo "/usr/local/orchestrator/orch_vip.sh -d 1 -n $newmaster -i ${interface} -I ${IP} -u ${user} -o $oldmaster" | tee $logfile
/usr/local/orchestrator/orch_vip.sh -d 1 -n $newmaster -i ${interface} -I ${IP} -u ${user} -o $oldmaster
#mysql -h$newmaster -u$mysqluser < /usr/local/bin/orch_event.sql
else
echo "Cluster does not exist!" | tee $logfile
fi
elif [[ $isitdead == "DeadIntermediateMasterWithSingleSlaveFailingToConnect" ]]; then
array=( eth0 "172.31.0.188" root "172.31.0.101")
interface=${array[0]}
IP=${array[3]}
user=${array[2]}
slavehost=`echo $5 | cut -d":" -f1`
echo $(date)
echo "Revocering from: $isitdead"
echo "New intermediate master is: $slavehost"
echo "/usr/local/orchestrator/orch_vip.sh -d 1 -n $slavehost -i ${interface} -I ${IP} -u ${user} -o $oldmaster" | tee $logfile
/usr/local/orchestrator/orch_vip.sh -d 1 -n $slavehost -i ${interface} -I ${IP} -u ${user} -o $oldmaster
elif [[ $isitdead == "DeadIntermediateMaster" ]]; then
array=( eth0 "172.31.0.188" root "172.31.0.101")
interface=${array[0]}
IP=${array[3]}
user=${array[2]}
slavehost=`echo $5 | sed -E "s/:[0-9]+//g" | sed -E "s/,/ /g"`
showslave=`mysql -h$newmaster -u$mysqluser -sN -e "SHOW SLAVE HOSTS;" | awk '{print $2}'`
newintermediatemaster=`echo $slavehost $showslave | tr ' ' '\n' | sort | uniq -d`
echo $(date)
echo "Revocering from: $isitdead"
echo "New intermediate master is: $newintermediatemaster"
echo "/usr/local/orchestrator/orch_vip.sh -d 1 -n $newintermediatemaster -i ${interface} -I ${IP} -u ${user} -o $oldmaster" | tee $logfile
/usr/local/orchestrator/orch_vip.sh -d 1 -n $newintermediatemaster -i ${interface} -I ${IP} -u ${user} -o $oldmaster
fi
4.3 modify vip script
vi /usr/local/orchestrator/orch_vip.sh
#!/bin/bash
emailaddress="1103290832@qq.com"
sendmail=1
function usage {
cat << EOF
usage: $0 [-h] [-d master is dead] [-o old master ] [-s ssh options] [-n new master] [-i interface] [-I] [-u SSH user]
OPTIONS:
-h Show this message
-o string Old master hostname or IP address
-d int If master is dead should be 1 otherweise it is 0
-s string SSH options
-n string New master hostname or IP address
-i string Interface exmple eth0:1
-I string Virtual IP
-u string SSH user
EOF
}
while getopts ho:d:s:n:i:I:u: flag; do
case $flag in
o)
orig_master="$OPTARG";
;;
d)
isitdead="${OPTARG}";
;;
s)
ssh_options="${OPTARG}";
;;
n)
new_master="$OPTARG";
;;
i)
interface="$OPTARG";
;;
I)
vip="$OPTARG";
;;
u)
ssh_user="$OPTARG";
;;
h)
usage;
exit 0;
;;
*)
usage;
exit 1;
;;
esac
done
if [ $OPTIND -eq 1 ]; then
echo "No options were passed";
usage;
fi
shift $(( OPTIND - 1 ));
# discover commands from our path
ssh=$(which ssh)
arping=$(which arping)
ip2util=$(which ip)
# command for adding our vip
cmd_vip_add="sudo -n $ip2util address add ${vip} dev ${interface}"
# command for deleting our vip
cmd_vip_del="sudo -n $ip2util address del ${vip}/32 dev ${interface}"
# command for discovering if our vip is enabled
cmd_vip_chk="sudo -n $ip2util address show dev ${interface} to ${vip%/*}/32"
# command for sending gratuitous arp to announce ip move
cmd_arp_fix="sudo -n $arping -c 1 -I ${interface} ${vip%/*} "
# command for sending gratuitous arp to announce ip move on current server
cmd_local_arp_fix="sudo -n $arping -c 1 -I ${interface} ${vip%/*} "
vip_stop() {
rc=0
# ensure the vip is removed
$ssh ${ssh_options} -tt ${ssh_user}@${orig_master} \
"[ -n \"\$(${cmd_vip_chk})\" ] && ${cmd_vip_del} && sudo ${ip2util} route flush cache || [ -z \"\$(${cmd_vip_chk})\" ]"
rc=$?
return $rc
}
vip_start() {
rc=0
# ensure the vip is added
# this command should exit with failure if we are unable to add the vip
# if the vip already exists always exit 0 (whether or not we added it)
$ssh ${ssh_options} -tt ${ssh_user}@${new_master} \
"[ -z \"\$(${cmd_vip_chk})\" ] && ${cmd_vip_add} && ${cmd_arp_fix} || [ -n \"\$(${cmd_vip_chk})\" ]"
rc=$?
$cmd_local_arp_fix
return $rc
}
vip_status() {
$arping -c 1 -I ${interface} ${vip%/*}
if ping -c 1 -W 1 "$vip"; then
return 0
else
return 1
fi
}
if [[ $isitdead == 0 ]]; then
echo "Online failover"
if vip_stop; then
if vip_start; then
echo "$vip is moved to $new_master."
if [ $sendmail -eq 1 ]; then mail -s "$vip is moved to $new_master." "$emailaddress" < /dev/null &> /dev/null ; fi
else
echo "Can't add $vip on $new_master!"
if [ $sendmail -eq 1 ]; then mail -s "Can't add $vip on $new_master!" "$emailaddress" < /dev/null &> /dev/null ; fi
exit 1
fi
else
echo $rc
echo "Can't remove the $vip from orig_master!"
if [ $sendmail -eq 1 ]; then mail -s "Can't remove the $vip from orig_master!" "$emailaddress" < /dev/null &> /dev/null ; fi
exit 1
fi
elif [[ $isitdead == 1 ]]; then
echo "Master is dead, failover"
# make sure the vip is not available
if vip_status; then
if vip_stop; then
if [ $sendmail -eq 1 ]; then mail -s "$vip is removed from orig_master." "$emailaddress" < /dev/null &> /dev/null ; fi
else
if [ $sendmail -eq 1 ]; then mail -s "Couldn't remove $vip from orig_master." "$emailaddress" < /dev/null &> /dev/null ; fi
exit 1
fi
fi
if vip_start; then
echo "$vip is moved to $new_master."
if [ $sendmail -eq 1 ]; then mail -s "$vip is moved to $new_master." "$emailaddress" < /dev/null &> /dev/null ; fi
else
echo "Can't add $vip on $new_master!"
if [ $sendmail -eq 1 ]; then mail -s "Can't add $vip on $new_master!" "$emailaddress" < /dev/null &> /dev/null ; fi
exit 1
fi
else
echo "Wrong argument, the master is dead or live?"
fi
#Send the modified configuration file and script to wl02 and dwl03 scp /etc/orchestrator.conf.json wl02:/etc/ Modify the configuration file as db02 of ip address "RaftBind": "172.31.0.102", scp /etc/orchestrator.conf.json wl03:/etc/ Modify the configuration file as db03 of ip address "RaftBind": "172.31.0.103", scp /usr/local/orchestrator/orch_hook.sh wl02:/usr/local/orchestrator/ scp /usr/local/orchestrator/orch_hook.sh wl03:/usr/local/orchestrator/ scp /usr/local/orchestrator/orch_vip.sh wl02:/usr/local/orchestrator/ scp /usr/local/orchestrator/orch_vip.sh wl03:/usr/local/orchestrator/ chmod 777 /usr/local/orchestrator/orch_hook.sh chmod 777 /usr/local/orchestrator/orch_vip.sh
4.4 create vip in master node
Only in master Create on node VIP # Add VIP ip addr add 172.31.0.188 dev eth0 # Delete VIP ip addr del 172.31.0.188 dev eth0
5. Startup and operation
5.1 start ORCH
#All nodes start ORCH cd /usr/local/orchestrator && nohup ./orchestrator --config=/etc/orchestrator.conf.json http &
5.2 command line control operation
#List all clusters /usr/local/orchestrator/resources/bin/orchestrator-client -c clusters #Prints the topology relationship of the specified cluster /usr/local/orchestrator/resources/bin/orchestrator-client -c topology -i wl01:8026 wl01:8026 (wl01) [0s,ok,8.0.26,rw,ROW,>>,GTID] + wl02:8026 (wl02) [0s,ok,8.0.26,ro,ROW,>>,GTID] + wl03:8026 (wl03) [0s,ok,8.0.26,ro,ROW,>>,GTID] #See which API to use #Because Raft is configured and there are multiple orchestrators, Orchestrator is required_ In the environment variable of API, Orchestrator client will automatically select the leader export ORCHESTRATOR_API="wl01:3000/api wl02:3000/api wl03:3000/api" /usr/local/orchestrator/resources/bin/orchestrator-client -c which-api wl02:3000/api #Forget to specify instance /usr/local/orchestrator/resources/bin/orchestrator-client -c forget -i wl01:8026 #Forget to specify cluster /usr/local/orchestrator/resources/bin/orchestrator-client -c forget-cluster -i wl01:8026 #Prints the master library for the specified instance /usr/local/orchestrator/resources/bin/orchestrator-client -c which-master -i wl01:8026 #Prints the slave library for the specified instance /usr/local/orchestrator/resources/bin/orchestrator-client -c which-replicas -i wl01:8026
6. Graphical interface management operation
Log in to the web management interface
IP address of any node in the cluster: 3000
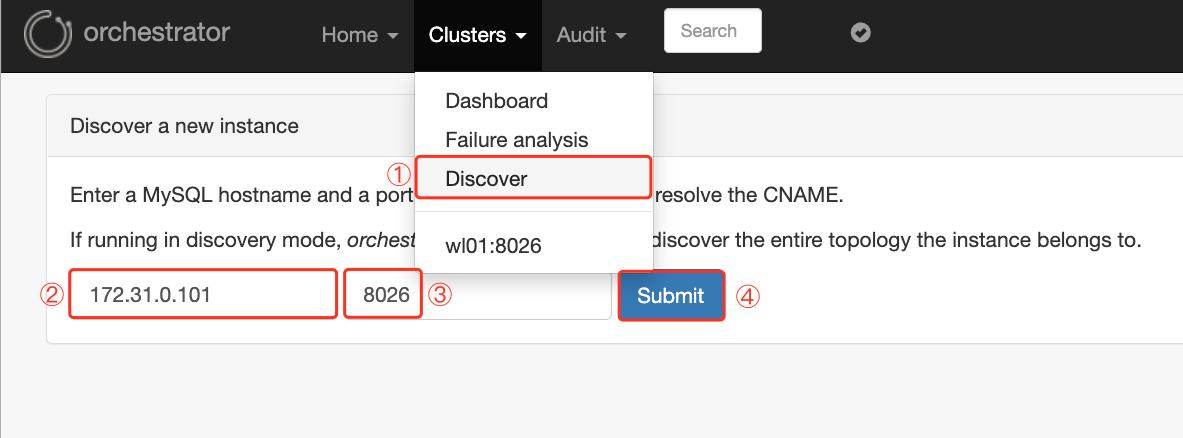
(1) Click Discover in cluster and enter the ip and port numbers of all managed mysql databases
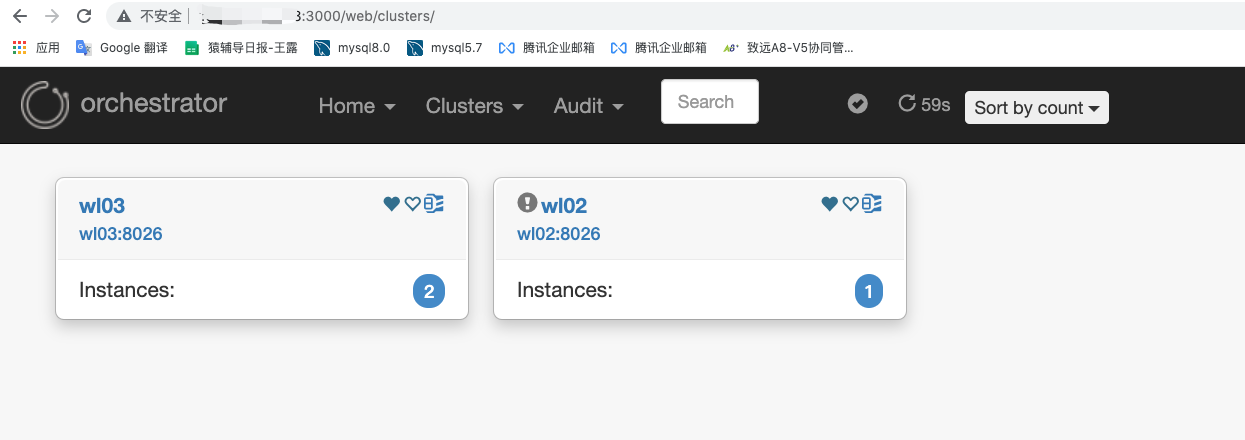
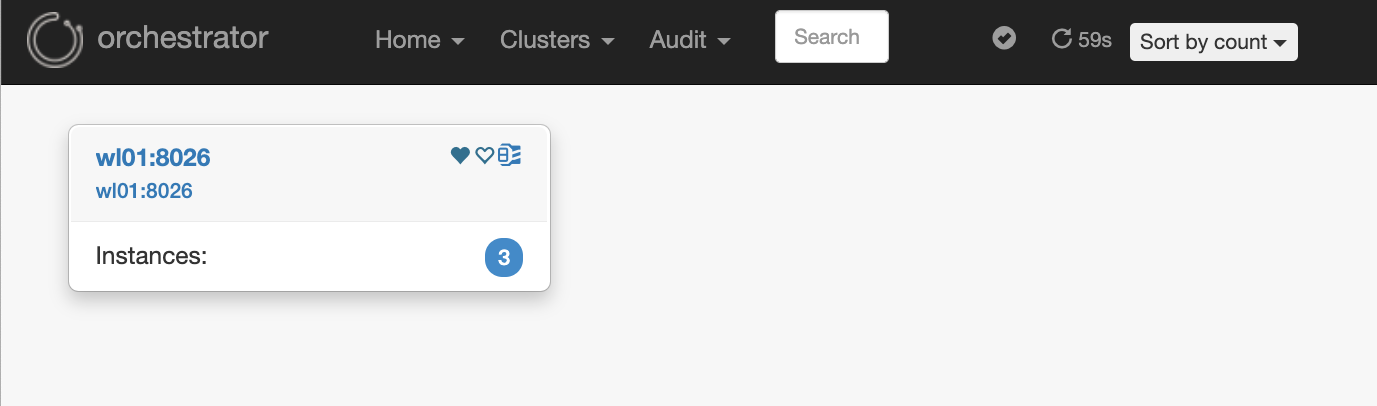
(2) Click Dashboard in cluster to view the discovered clusters
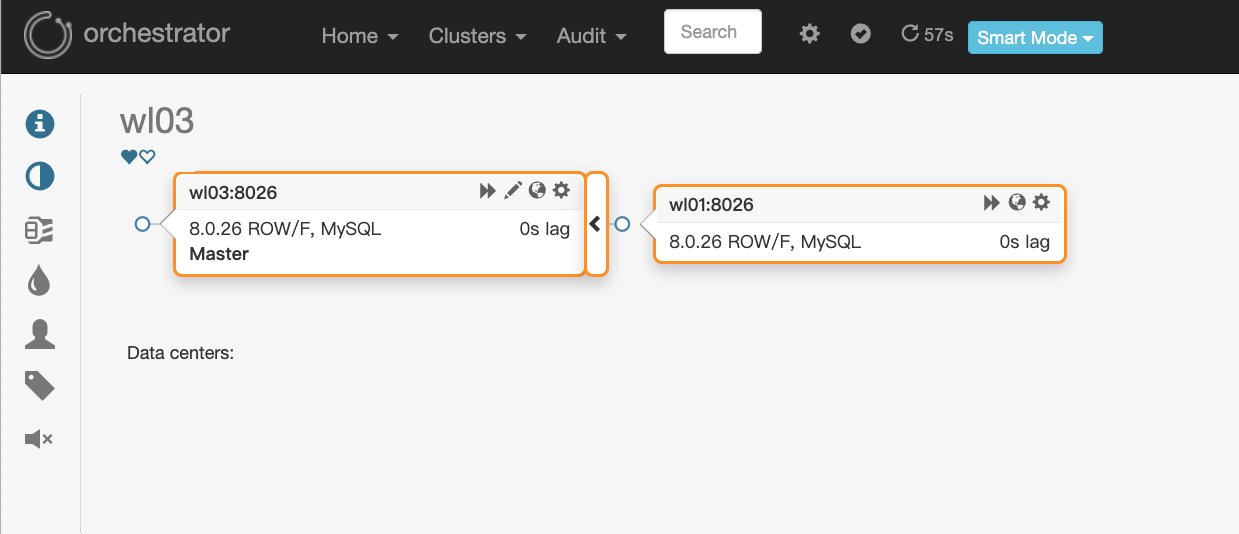
(3) Click the cluster name to view the cluster topology
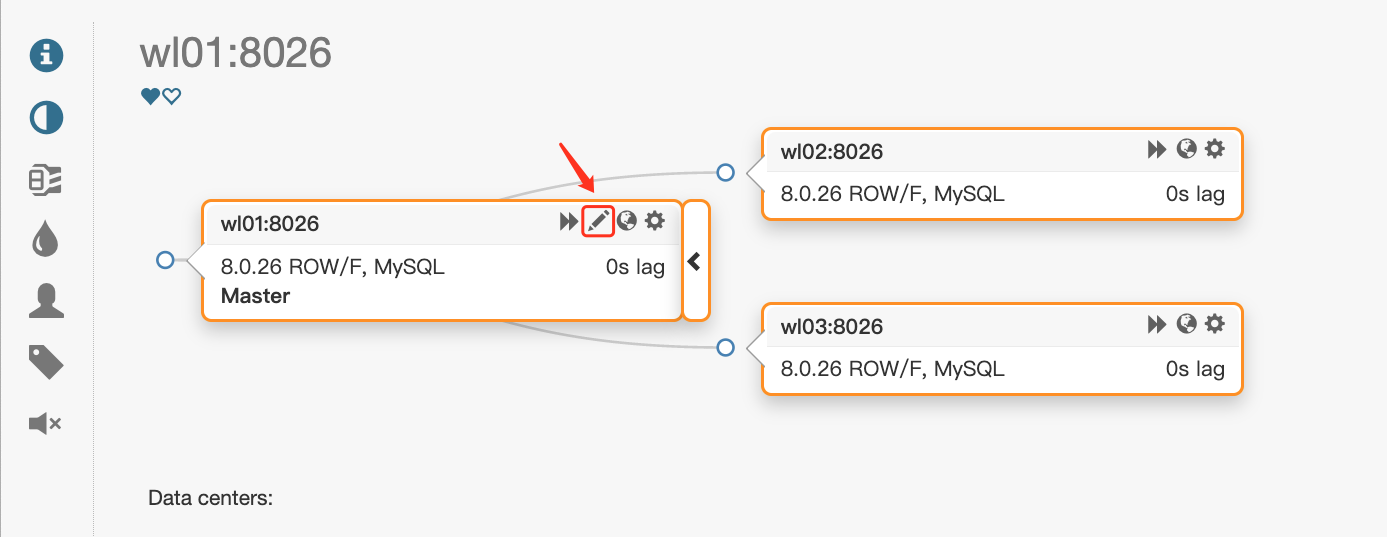
(4) Click the red box icon in (3) to view the specific information of the node
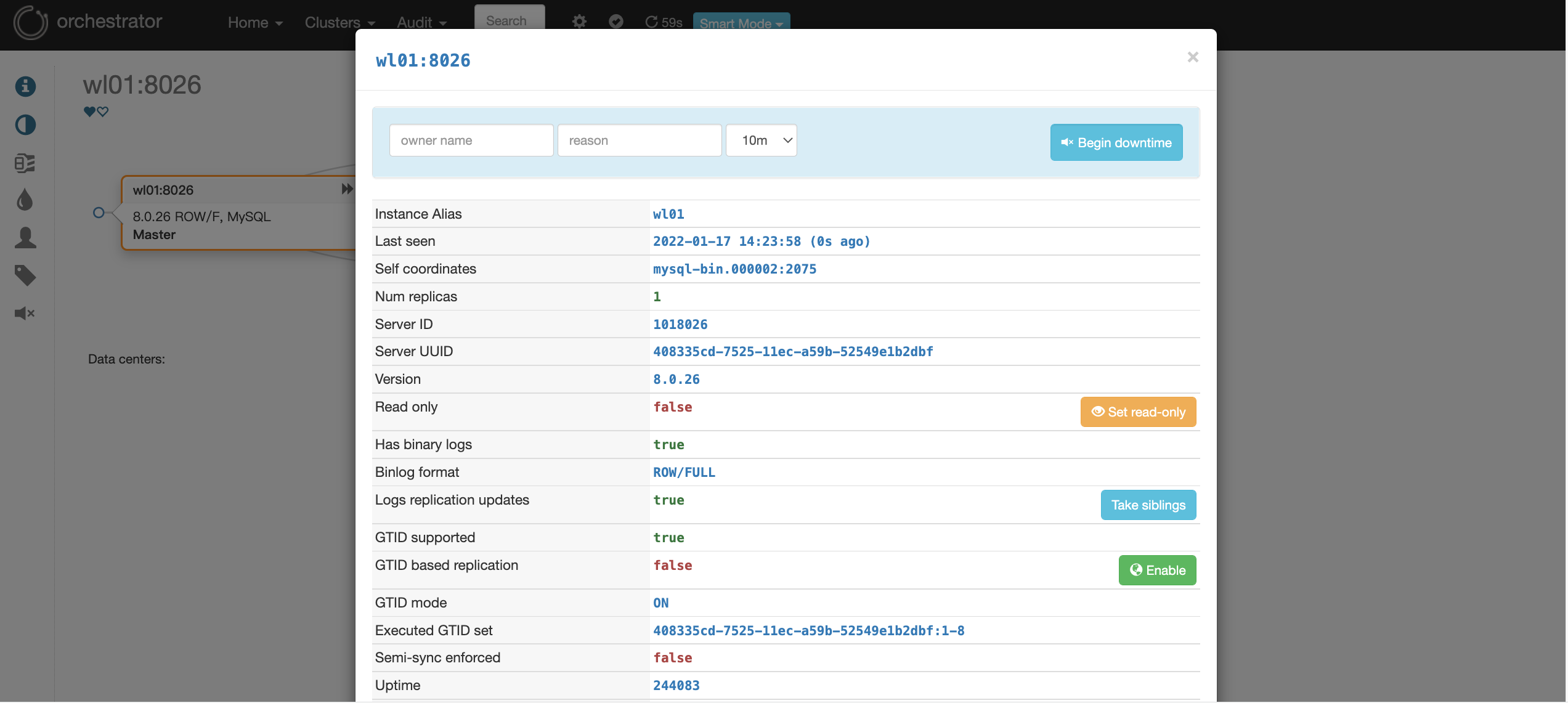
7. Verify failover
#Shut down the main warehouse and observe the phenomenon [root@wl01 orchestrator]# mysql -S /mysql-8026/8026/run/mysql.sock mysql> shutdown; #View the current leader node and the fault drift log in the leader node [root@wl01 orchestrator]# /usr/local/orchestrator/resources/bin/orchestrator-client -c which-api wl03:3000/api [root@wl03 orchestrator]# tail -f orch_hook.log /usr/local/orchestrator/orch_vip.sh -d 1 -n wl02 -i eth0 -I 172.31.0.188 -u root -o wl01 #vip drifts from wl01 to wl02 #vip successfully drifted to wl02 node [root@wl01 orchestrator]# ip a | grep "172.31.0.188" [root@wl02 orchestrator]# ip a | grep "172.31.0.188" inet 172.31.0.188/32 scope global eth0
View the topology relationship through the web interface. wl01 node has been separated from the cluster, and wl02 and wl03 have rebuilt the master-slave relationship
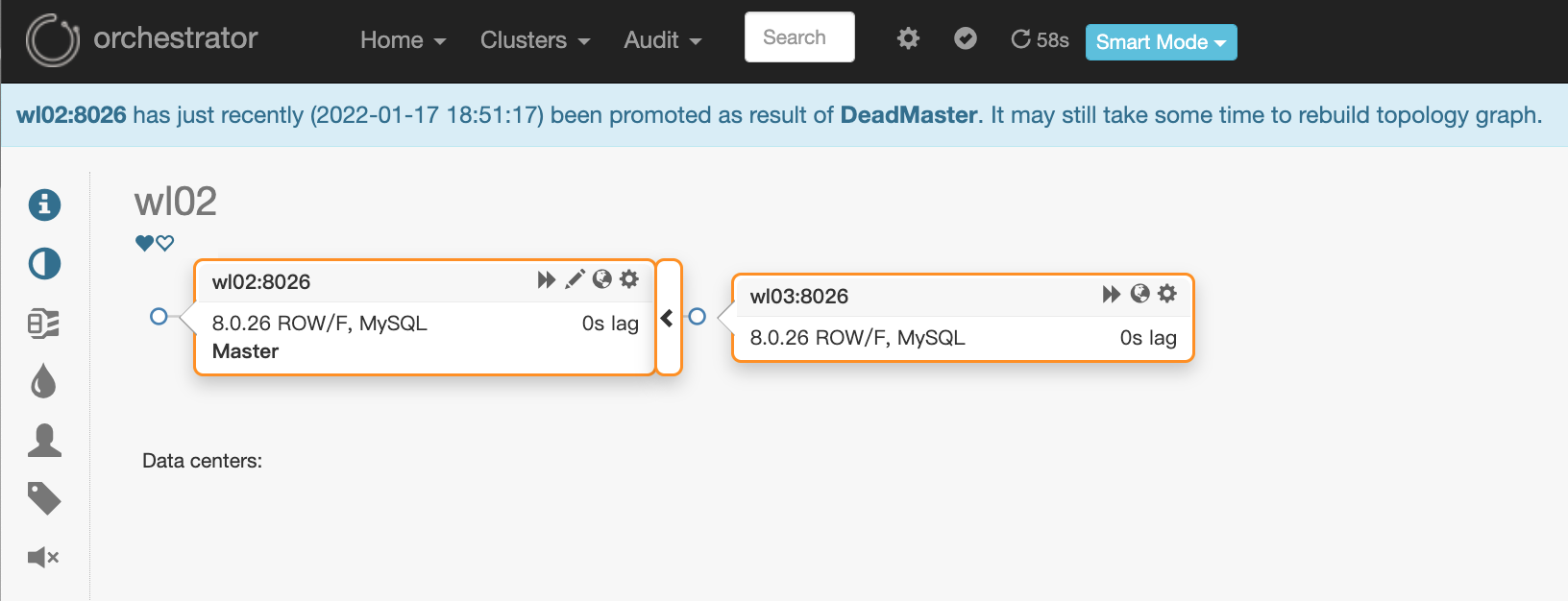
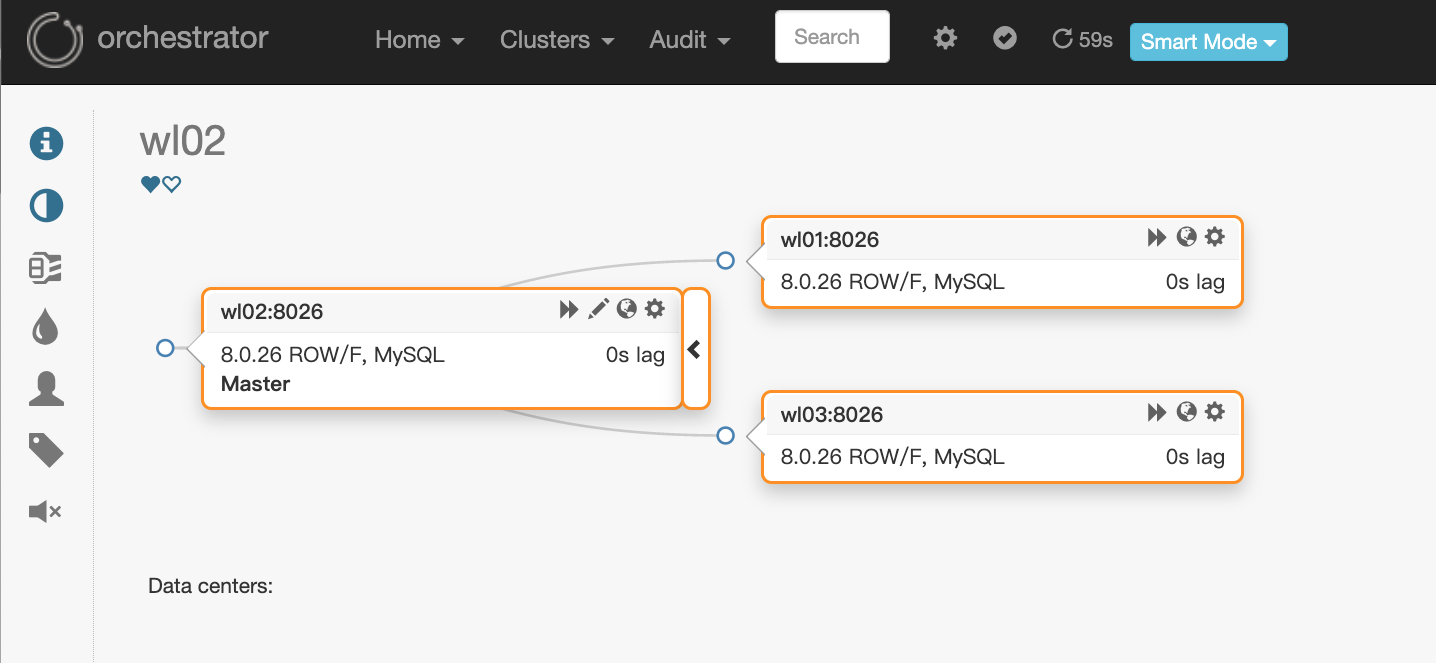
8. Verify the high availability of raft
#(1) Repair high availability of mysql database cluster #(2) View the leader node of the current raft [root@wl02 orchestrator]# /usr/local/orchestrator/resources/bin/orchestrator-client -c which-api wl01:3000/api
#(3) Close the orch back-end database of wl01 node, and the orch service will stop [root@wl01 orchestrator]# mysql -S /mysql-8026/3306/run/mysql.sock mysql> shutdown; Query OK, 0 rows affected (0.00 sec) mysql> exit Bye [1] Done mysqld_safe --defaults-file=/mysql-8026/3306/my.cnf [5]- Exit 1 cd /usr/local/orchestrator && nohup ./orchestrator --config=/etc/orchestrator.conf.json http [root@wl01 orchestrator]# ps -ef | grep orch root 23134 14495 0 10:28 pts/2 00:00:00 grep --color=auto orch #(4) Check the orch logs of other nodes. You can see that wl02 is selected as the new leader [root@wl03 orchestrator]# tail -f /usr/local/orchestrator/nohup.out 2022-01-18 10:27:38 DEBUG raft leader is 172.31.0.101:10008; state: Follower 2022/01/18 10:27:39 [WARN] raft: Rejecting vote request from 172.31.0.102:10008 since we have a leader: 172.31.0.101:10008 2022/01/18 10:27:39 [DEBUG] raft: Node 172.31.0.103:10008 updated peer set (2): [172.31.0.102:10008 172.31.0.101:10008 172.31.0.103:10008] 2022-01-18 10:27:39 DEBUG orchestrator/raft: applying command 6871: leader-uri 2022/01/18 10:27:39 [DEBUG] raft-net: 172.31.0.103:10008 accepted connection from: 172.31.0.102:38934 2022-01-18 10:27:43 DEBUG raft leader is 172.31.0.102:10008; state: Follower 2022-01-18 10:27:46 DEBUG orchestrator/raft: applying command 6872: request-health-report 2022-01-18 10:27:48 DEBUG raft leader is 172.31.0.102:10008; state: Follower 2022-01-18 10:27:53 INFO auditType:forget-clustr-aliases instance::0 cluster: message:Forgotten aliases: 0 2022-01-18 10:27:53 INFO auditType:review-unseen-instances instance::0 cluster: message:Operations: 0 2022-01-18 10:27:53 INFO auditType:forget-unseen instance::0 cluster: message:Forgotten instances: 0 2022-01-18 10:27:53 INFO auditType:resolve-unknown-masters instance::0 cluster: message:Num resolved hostnames: 0 2022-01-18 10:27:53 INFO auditType:inject-unseen-masters instance::0 cluster: message:Operations: 0 2022-01-18 10:27:53 INFO auditType:forget-unseen-differently-resolved instance::0 cluster: message:Forgotten instances: 0 2022-01-18 10:27:53 DEBUG raft leader is 172.31.0.102:10008; state: Follower #(5) Close the mysql database service of wl02 and verify the fault drift again [root@wl02 orchestrator]# mysql -S /mysql-8026/8026/run/mysql.sock mysql> shutdown; Query OK, 0 rows affected (0.00 sec) mysql> exit Bye [4] Done mysqld_safe --defaults-file=/mysql-8026/8026/my.cnf #(6) Check the phenomenon. vip drifts to wl03 [root@wl02 orchestrator]# ip a | grep "172.31.0.188" [root@wl03 orchestrator]# ip a | grep "172.31.0.188" inet 172.31.0.188/32 scope global eth0 #(7) The web interface logged in through the ip address of wl01 is lost
#(8) Use the ip of wl02 to log in to the web interface again Can see wl02 The node has left the cluster, wl03 And wl01 Rebuilt the master-slave relationship