background
- Read the fueling source code! - by Lu Xun
- A picture is worth a thousand words. --By Golgi
Explain:
- Kernel version: 4.14
- ARM64 processor, Contex-A53, dual core
- Using tool: Source Insight 3.5, Visio
1. overview
Starting with this article, I'll start a series of research on Linux scheduler.
This article will also start with some basic concepts and data structures, first to create a rough outline, and the following articles will gradually deepen.
2. concept
2.1 process
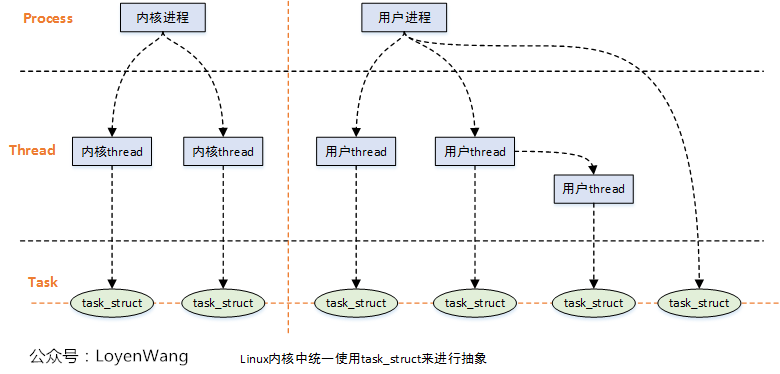
- From textbooks, we all know that: process is the smallest unit of resource allocation, and thread is the smallest unit of CPU scheduling.
- The process includes not only the code segment of executable program, but also a series of resources, such as: open file, memory, CPU time, semaphore, multiple execution thread flow, etc. Threads can share the resource space in the process.
- In the Linux kernel, both processes and threads use struct task struct structure for abstract description.
- The virtual address space of a process is divided into user virtual address space and kernel virtual address space. All processes share the kernel virtual address space. Processes without user virtual address space are called kernel threads.
Linux kernel uses task struct structure to abstract, which contains all kinds of process information and resources, such as process status, open files, address space information, signal resources and so on. The task struct structure is very complex, and only some fields related to scheduling are introduced below.
struct task_struct {
/* ... */
/* Process state */
volatile long state;
/* Scheduling priority related, policy related */
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
unsigned int policy;
/* Scheduling class, scheduling entity related, task group related, etc */
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
#ifdef CONFIG_CGROUP_SCHED
struct task_group *sched_task_group;
#endif
struct sched_dl_entity dl;
/* Relationship between processes */
/* Real parent process: */
struct task_struct __rcu *real_parent;
/* Recipient of SIGCHLD, wait4() reports: */
struct task_struct __rcu *parent;
/*
* Children/sibling form the list of natural children:
*/
struct list_head children;
struct list_head sibling;
struct task_struct *group_leader;
/* ... */
}2.2 process status

- In the figure above, the left side is the popular process three state model in the operating system, and the right side is the process state switch corresponding to Linux. Each flag describes the current state of the process, which are mutually exclusive;
- In Linux, the ready state and the running state correspond to the task "running" flag bit. The ready state indicates that the process is in the queue and has not been scheduled. The running state indicates that the process is running on the CPU;
The main status fields in the kernel are defined as follows
/* Used in tsk->state: */ #define TASK_RUNNING 0x0000 #define TASK_INTERRUPTIBLE 0x0001 #define TASK_UNINTERRUPTIBLE 0x0002 /* Used in tsk->exit_state: */ #define EXIT_DEAD 0x0010 #define EXIT_ZOMBIE 0x0020 #define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD) /* Used in tsk->state again: */ #define TASK_PARKED 0x0040 #define TASK_DEAD 0x0080 #define TASK_WAKEKILL 0x0100 #define TASK_WAKING 0x0200 #define TASK_NOLOAD 0x0400 #define TASK_NEW 0x0800 #define TASK_STATE_MAX 0x1000 /* Convenience macros for the sake of set_current_state: */ #define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE) #define TASK_STOPPED (TASK_WAKEKILL | __TASK_STOPPED) #define TASK_TRACED (TASK_WAKEKILL | __TASK_TRACED) #define TASK_IDLE (TASK_UNINTERRUPTIBLE | TASK_NOLOAD)
2.3 scheduler

- The so-called scheduling is to select a process from the process's ready queue to allocate CPU according to some scheduling algorithm, which is mainly to coordinate the use of CPU and other resources. The goal of process scheduling is to maximize CPU time.
The kernel provides five schedulers by default. The Linux kernel uses struct sched_class to abstract the schedulers:
- Stop sched class: the scheduling class with the highest priority can preempt all other processes and cannot be preempted by other processes;
- Deadline scheduler, DL ﹣ sched ﹣ class: use red black tree to sort the processes according to the absolute deadline, and select the smallest process for scheduling;
- RT sched class: real-time scheduler, which maintains a queue for each priority;
- CFS scheduler, CFS sched class: a completely fair scheduler, which adopts a completely fair scheduling algorithm and introduces the concept of virtual runtime;
- Idle task scheduler, idle ﹣ sched ﹣ class: idle scheduler, each CPU will have an idle thread, when there is no other process to schedule, schedule and run idle thread;
The Linux kernel provides some scheduling policies for the user program to select the scheduler, among which the Stop scheduler and the idle task scheduler are only used by the kernel, and the user cannot select:
- SCHED_DEADLINE: a Deadline process scheduling strategy, which enables task to select the Deadline scheduler to schedule the operation;
- SCHED_RR: real time process scheduling strategy, time slice rotation, adding the tail of the priority corresponding running queue after the process runs out of time slice, and giving the CPU to other processes with the same priority;
- SCHED_FIFO: a real-time process scheduling strategy. First in, first out scheduling has no time slice and can only wait for the CPU to be actively released when there is no higher priority;
- SCHED_NORMAL: a common process scheduling strategy, which makes the task choose CFS scheduler to schedule the operation;
- SCHED_BATCH: general process scheduling strategy, batch processing, so that the task chooses CFS scheduler to schedule the operation;
- SCHED_IDLE: a common process scheduling strategy, which enables task s to select CFS scheduler with the lowest priority to schedule operations;
2.4 runqueue

- Each CPU has a run queue, and each scheduler acts on the run queue;
- Tasks assigned to CPU are added to the running queue as scheduling entities;
- When the task runs for the first time, if possible, try to add it to the running queue of the parent task (if it is allocated to the same CPU, the cache affinity will be higher and the performance will be improved);
The Linux kernel uses struct rq structure to describe the running queue. The key fields are as follows:
/*
* This is the main, per-CPU runqueue data structure.
*
* Locking rule: those places that want to lock multiple runqueues
* (such as the load balancing or the thread migration code), lock
* acquire operations must be ordered by ascending &runqueue.
*/
struct rq {
/* runqueue lock: */
raw_spinlock_t lock;
/*
* nr_running and cpu_load should be in the same cacheline because
* remote CPUs use both these fields when doing load calculation.
*/
unsigned int nr_running;
/* Three scheduling queues: CFS scheduling, RT scheduling, DL scheduling */
struct cfs_rq cfs;
struct rt_rq rt;
struct dl_rq dl;
/* stop Point to migration kernel thread, idle point to idle kernel thread */
struct task_struct *curr, *idle, *stop;
/* ... */
} 2.5 task group
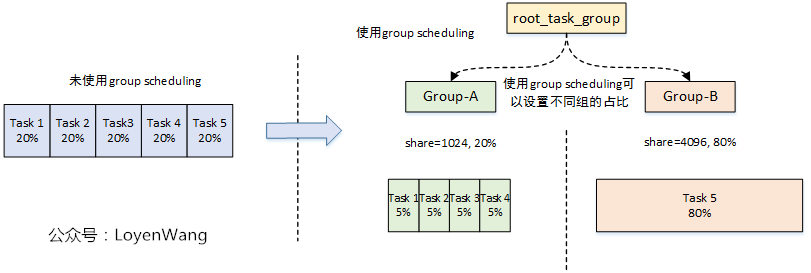
- By using the task grouping mechanism, you can set or limit the CPU utilization of task groups, such as limiting some tasks to a certain interval, so as not to affect the execution efficiency of other tasks;
- After the introduction of task group, the scheduling object of the scheduler is not only a process, but also a sched entity / sched RT entity / sched DL entity, which can be a process or task group;
- Use the data structure struct task group to describe the task group. The task group will maintain a CFS scheduling entity, CFS operation queue, RT scheduling entity and RT operation queue on each CPU;
The Linux kernel uses struct task group to describe task groups. The key fields are as follows:
/* task group related information */
struct task_group {
/* ... */
/* Each CPU is assigned a CFS scheduling entity and CFS running queue */
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each cpu */
struct sched_entity **se;
/* runqueue "owned" by this group on each cpu */
struct cfs_rq **cfs_rq;
unsigned long shares;
#endif
/* Each CPU is assigned an RT scheduling entity and an RT run queue */
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity **rt_se;
struct rt_rq **rt_rq;
struct rt_bandwidth rt_bandwidth;
#endif
/* task_group Organizational relationship between */
struct rcu_head rcu;
struct list_head list;
struct task_group *parent;
struct list_head siblings;
struct list_head children;
/* ... */
};3. Scheduler
The scheduler relies on several functions to complete the scheduling work. Next, we will introduce several key functions.
- Active scheduling - schedule()

- The schedule() function is the core function of process scheduling. The general process is shown in the figure above.
- Core logic: select another process to replace the currently running process. The process selection is realized by the pick ﹣ next ﹣ task function in the scheduler used by the process. Different schedulers implement different methods. The process replacement is completed by the context ﹣ switch(), and the specific details will be further analyzed in the following articles.
- Cycle schedule - Schedule u tick()
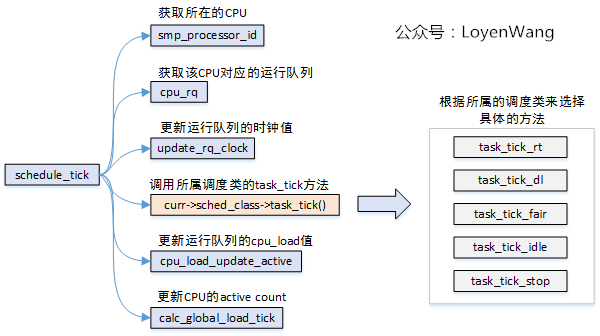
- In the clock interrupt handler, call the schedule "tick() function;
- Clock interrupt is the pulse of the scheduler, and the kernel relies on the periodic clock to control the CPU;
- The clock interrupt handler checks whether the execution time of the current process is excessive. If the execution time is excessive, set the rescheduling flag ("TIF" needed "reset);
- When the clock interrupt processing function returns, if the interrupted process is running in user mode, check whether there is a rescheduling flag. If it is set, call schedule() to schedule;
- High precision clock scheduling - hrtick()
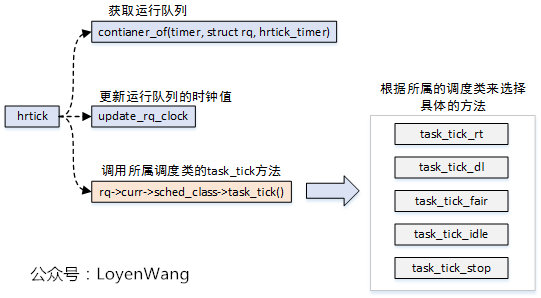
- High precision clock scheduling is similar to periodic scheduling, the difference is that the precision of periodic scheduling is ms level, while the precision of high precision scheduling is ns level;
- High precision clock scheduling requires corresponding hardware support;
- Schedule when process wakes up - wake up process()
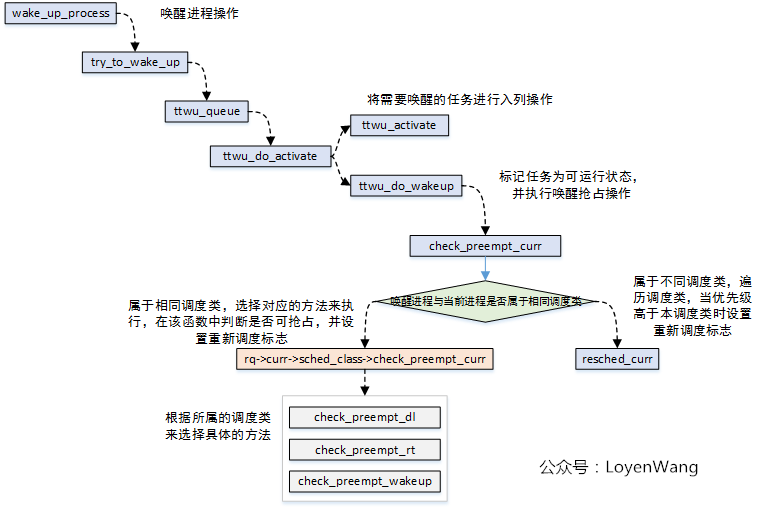
- The wake-up process() function is called when the wake-up process, and the wake-up process may seize the current process;
The functions mentioned above are commonly used for scheduling. In addition, when creating a new process, or when the kernel preempts, there are also some scheduling points.
This article is just a rough introduction, and some modules will be further analyzed in the future, please look forward to.
