Implementation of semi-automatic scheduling system with python language
0. Why do you want to make this software?
I believe that all dalaos engaged in personnel, especially store managers in store sales, should have experienced the pain of scheduling. It can be said that it is a mechanical, time-consuming and laborious work to collect the text shift information (such as wechat chat) on the Internet and sort it into a table. Although existing solutions such as sharing documents can be used, according to my understanding (as well as personal working experience), most stores still use wechat solitaire. Therefore, I designed a cross platform software that can assist store managers and personnel dalao in scheduling.
1. What functions does the software want to realize?
Overall goal: make the Solitaire text into a scheduling table
Steps:
- Identify the shift reporting time in various formats in the continuous text
- Summarize the shift reporting time, automatically obtain the shift reporting table, and summarize the working hours
- The user modifies the shift report form and finally makes a shift schedule
- Export table
The above functions require the use of third-party dependencies: pandas (data collation), wxpython (GUI)
2. Realization of specific functions
2.1 identify time expressions with different formats in the text
General employees without the concept of unified format use a variety of shift reporting formats when connecting. What I see in the software design includes but is not limited to: using the decimal point as the separator, writing only one month (2.1-3), out of order (2.3 nights, 2.1-2.2 calls), and many other formats that make programmers' blood pressure soar = =, therefore, If we want to implement a practical system, the first step is to solve these hypertension problems.
First of all, when we collect shift reports, we usually have a certain time period, such as 2.16-2.28. This can require users to enter information in the UI. So we can first use the date in pandas_ Range method.
def TimeTranser(StartTimeStr,EndTimeStr):
DatetimeIndex = pd.date_range(StartTimeStr,EndTimeStr,freq='D')
TidyedTimeBox = [DatetimeIndex[0],DatetimeIndex[-1]]
for DateTime in DatetimeIndex:
TidyedTime = "{}.{}".format(DateTime.month,DateTime.day)
TidyedTimeBox.append(TidyedTime)
return TidyedTimeBox
Now, we have obtained a "standard answer" TidyedTimeBox of time. With the judgment standard, it is very simple text processing ~
Since we have set the application scenario of this shift scheduling assistant software as wechat Solitaire, we can make full use of the characteristics of solitaire text: each line of solitaire content must be composed of numbers, decimal points and spaces. Then we can use this property to determine the starting position of valid text, which is represented by the FirstInt function.
def FirstInt(line):
LineMess = line.replace('\n','').split('. ')
if((len(LineMess)) == 1):
return False,114514
else:
number = int(LineMess[0])
PersonalMesses = LineMess[1].split(' ')
pre_dels = []
for n,mess in enumerate(PersonalMesses):
if(mess == ''):
pre_dels.append(n)
for i in pre_dels:
del PersonalMesses[i]
return True,number,PersonalMesses
After the identification is completed, it is natural to standardize the information of personnel (that is, the classification of shift registration is regulated to each individual date). This step is actually two steps, first classification (morning shift, evening shift, regular shift, etc.), and then regulation. The classification is completed by the first half of the WorkTimeTranslate method, and the regularization is realized by the TidyTimeStr method:
def WorkTimeTranslate(self):
UsefulData = []
for n in range(len(self.mess)):
if(n == 0):
name = self.mess[n]
else:
UsefulData.append(self.mess[n])
AllPass = self.IsAllPass(UsefulData)
if(AllPass):
ReturnMess = (name,True)
else:
Times = self.TidyTimeStr(UsefulData)
ReturnMess = (name, False, Times)
return ReturnMess
def TidyTimeStr(self,Datas):
TimeDict = {'through':[],'Good morning!':[],'night':[],'Evening':[],'morning':[]}
TimeString = ""
for data in Datas:
if(self.CheckDict(data) == -1):
if(TimeString == ""):
TimeString = data
else:
TimeString = "{}${}".format(TimeString,data)
else:
if (TimeString == ""):
TimeString = "{}*".format(data)
else:
TimeString = "{}${}*".format(TimeString, data)
OldData = (TimeString.split('*'))
NewGroup = []
for n_data in OldData:
if(n_data != ''):
n_data = self.RemoveSysmbol(n_data)
n_data = n_data.replace('Late insertion','Evening').replace('Early insertion','morning').replace('$through','through').replace('$Evening','Evening').replace('$morning','morning').replace('$Good morning!','Good morning!').replace('$night','night')
if(n_data[0] == '$'):
n_data = self.remove_char(n_data,0)
NewGroup.append(n_data)
KeyBox = self.FindWorkTimeKeyLocation(NewGroup)
for num, key in enumerate(KeyBox):
try:
WorkTimeKey = NewGroup[num][key[1]]
TimeContent = NewGroup[num].replace('Evening','').replace('morning','').replace('Good morning!','').replace('night','').replace('through','')
TimeContent = self.Point2Comma(TimeContent).replace('$',',')
TimeTotal = self.TimeTranser(TimeContent)
TimeDict[WorkTimeKey] += TimeTotal
except:
continue
return TimeDict
As you can see, the most important ideas in the code are actually three:
- In the operation, all the segmentation symbols of the text are unified into $symbol (based on this symbol is hardly considered to be used in this context) and * symbol. The former is time cutter and the latter is paragraph cutter. After unifying the symbol, it will be very easy to deal with.
- Using the Dict type feature in python, time strings are classified into preset categories (because the preset categories are simple and limited), so that we can uniquely process time information and do not need to sort out categories before writing the table.
- By judging the context before and after the time slicer, we can directly get whether it really needs segmentation or just the text is not standardized.
2.2 generate a shift report with man hours from the sorted contents
Through the above operations, we have put personal text classification into TimeDict. Next, we only need some simple operations to sort out a person's information (I won't write this part if the technical content is not high. See the end of the article for the complete code). This part is treated as a readmessenger method in the code as a whole:
def ReadMess(mess,timebox):
numbers = []
ReturnMesses = []
for line in mess:
line = line.replace('class','').replace('reach','-').replace('Late insertion','Evening').replace('Early insertion','morning')
ReturnMess = FirstInt(line)
# print(ReturnMess)
if(ReturnMess[0]):
numbers.append(ReturnMess[1])
UsefulMesses = ReturnMess[2]
ReturnMesses.append(MessTranser(UsefulMesses,timebox).forward())
TotalTable = GetTotalTable(ReturnMesses,timebox)
return len(numbers), TotalTable
After all the information is collected, the next step is to build a table! wxpython is used here, and wxFormBuilder is used as an auxiliary.
The creation of the form itself is not difficult. After all, we have obtained complete and regular shift registration information before. Just arrange the information into a table in order. Here I use the MakeTable method to solve the problem:
def MakeTable(self):
TimeDict = {}
for person in self.MemberTable:
name = person[0]
self.PeopleDict[name] = []
for num, time in enumerate(self.TimeData):
TimeDict[time] = num
for name in self.InputTableData:
WorkTimeGroup = []
for i in range(len(self.TimeData)):
WorkTimeGroup.append('')
for worktime in self.InputTableData[name]:
Times = self.InputTableData[name][worktime]
for time in Times:
WorkTimeGroup[TimeDict[time]] = worktime
for num,worktime in enumerate(WorkTimeGroup):
if(worktime == ''):
WorkTimeGroup[num] = '/'
else:
WorkTimeGroup[num] = "{}class".format(WorkTimeGroup[num])
self.PeopleDict[name] = WorkTimeGroup
for num, name in enumerate(self.PeopleDict):
RowNum = num
for ListNum, TimeWorktime in enumerate(self.PeopleDict[name]):
# print(RowNum,ListNum)
try:
self.DataTable.SetCellValue(RowNum,ListNum,TimeWorktime.replace('Evening','Late insertion').replace('morning','Early insertion'))
except:
continue
self.UpDateTable()
Careful friends may have found that there is an UpDateTable method at the end of the method. As the name suggests, this method is used to update the data table, but the problem is why the data table should be updated when the table has just been created? The reason is actually very simple. This method is not only to update the data table, but also to calculate the working hours:
def UpDateTable(self):
for num,name in enumerate(self.PeopleDict):
TotalGroup = []
try:
for cell in range(len(self.TimeData)):
CellData = self.DataTable.GetCellValue(num,cell).replace('Late insertion','Evening').replace('Early insertion','morning')
TotalGroup.append(CellData)
TotalWorkTime = 0
except:
continue
for Work in TotalGroup:
try:
TotalWorkTime += self.worktimetable[Work]
except:
continue
self.DataTable.SetCellValue(num,len(self.TimeData),str(TotalWorkTime).replace('Evening','Late insertion').replace('morning','Early insertion'))
Now we have got a beautiful form ~ (see the third part of the actual display for the effect)
2.3 help the user finally make the shift schedule
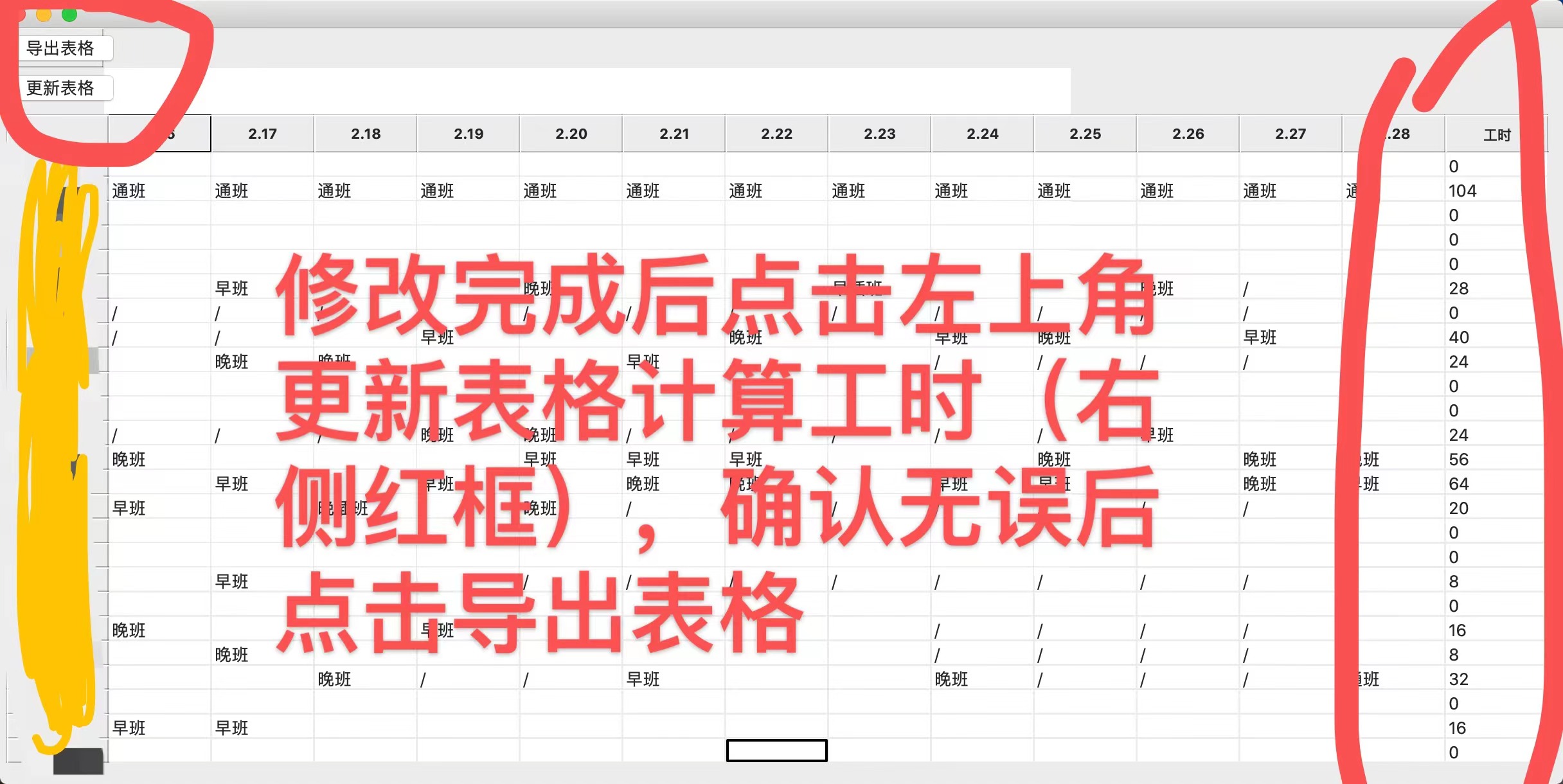
After the above steps are completed, we actually get a "shift report form". What is a shift report form? In fact, it is the working hours applied for by each employee, and generally, the demand of the store manager for on-the-job personnel is far less than the total application of the employees (this phenomenon is particularly common in retail or catering stores with part-time personnel). Therefore, the "shift report form" formed by summarizing the shift report also needs the store manager to screen, add and delete it into a "shift schedule". There are actually two methods in this step. The first is to modify it directly in this program, and the second is to output an Excel and then change it. Considering that the usage scenario of this program requires the realization of the function of man hour calculation, it is better to adopt the first method (in fact, the second method can also be realized. My idea is to output an Excel document with its own function, but it is more cumbersome and may involve cross language trouble), Because the UpDateTable method above already has the ability to scan the whole table and change the information (well, in fact, this function is written only at this step of the work. Of course, there will be ah = =), so I still use the UpDateTable method above to update the table and calculate the working hours, and I have specially set an update key to activate this function. Therefore, the operation logic now becomes:
Output the shift report - > change the cell information in the table - > click the update button to calculate the working hours
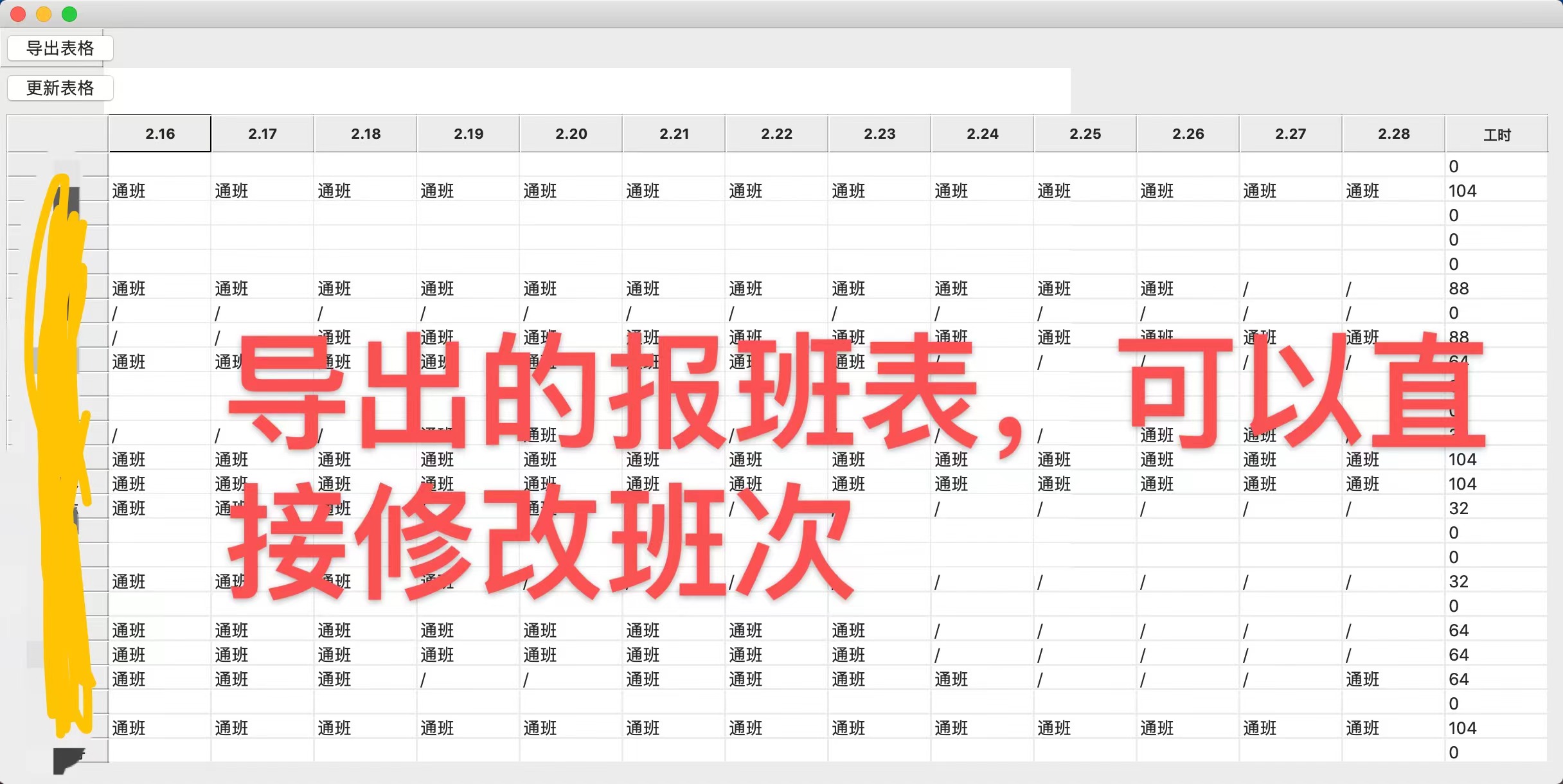
2.4 export table
After we complete the shift scheduling table, of course, we also need to export the table as a table file for printing or publishing. This is very simple. If it is in CSV format, it can be realized by using the built-in function of python. If it is exported as an Excel file, it can be easily realized only by Pandas dependency library. Because the store where I work has format tables, and the output tables need to be edited in the next step rather than published directly, so I chose a simpler CSV (after all, the less the code, the fewer the bug s. Although this seems not enough to show off the technology, the reliability of the software actually applied in the store must be the first). In the code, I wrote a WriteCsvTable method to realize it, In the GUI, this method is activated by the "export table" button:
def WriteCsvTable(self,DataTable):
SavePath = self.SavePath
NowTime = time.localtime()
filename = "{}-{}-{}-{}-{}Export table".format(NowTime.tm_year, NowTime.tm_mon, NowTime.tm_mday,NowTime.tm_hour, NowTime.tm_min)
CSVPath = "{}/{}.csv".format(SavePath,filename)
csv_str = []
for line in DataTable:
line_str = ""
for cell in line:
line_str += "{},".format(cell)
csv_str.append(line_str)
with open(CSVPath,'w',encoding='gbk') as csv:
for line in csv_str:
csv.writelines(line)
csv.write('\n')
Here, our software is finished! Next, pack it for the store manager
3. Practical demonstration
Next is the actual use ~ (the test data is randomly adapted according to the actual shift report text, which is only of test significance and has nothing to do with the actual shift arrangement of the store. Please don't overestimate the operation of the store)

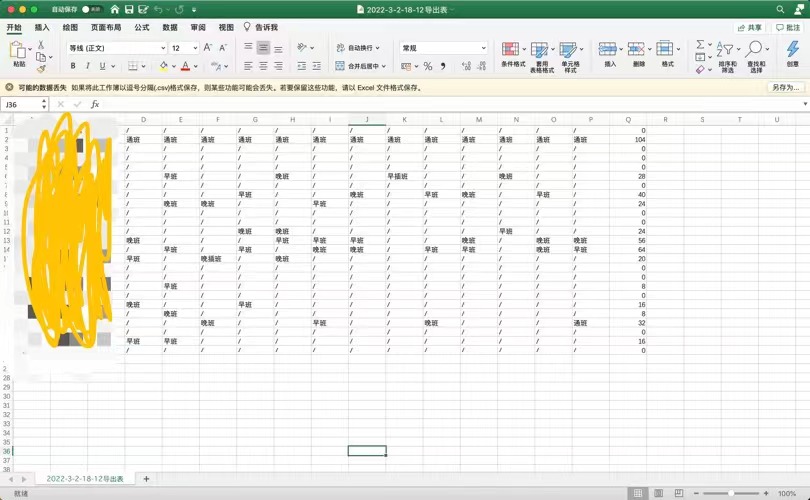
All the tasks and objectives have been completed ~ the store manager is also very satisfied! Success!
4. Summary and reflection
Lessons learned
- The importance of communicating with customers: what I feel most about this software design is the coordination between programmers and actual users. My initial program idea is very different from what I have done now. The real needs of users are determined after several communications with the store manager and Deputy store manager. As developers, we look at problems from a very different perspective from our users. It's easy to turn the cart when making software.
- The development system should be consistent with the user system as far as possible: in fact, there is a bug in this software, that is, the table cannot be modified on the Windows system. I haven't found out the reason so far. At present, I guess it may be because wxpython is different from Mac os in the Windows system. Although our store can overcome this problem by modifying the scheduling in the format table, as a developer, I am still very reluctant to see this situation. Therefore, when developing software in the future, we must try our best to keep the system consistency between the development platform and the application platform. This lesson is really big enough!!!
Areas that can be improved (look forward to the guidance of the great gods!!)
- At present, the software only supports Linux system and Mac os system. Tables cannot be edited in Windows system. Targeted optimization can be carried out here.
- After changing the table, you can directly modify the working hours without creating a button. This step is somewhat like adding icing on the cake (in fact, this is a compromise because I didn't find the trigger event for cell data update).
- The interface is too simple.
- Exporting only CSV tables is obviously not enough. You should increase the export ability of Excel and PDF
- The text format that can be handled is still limited. For example, the time division with decimal point cannot be solved (for example, 2.1 2.3.4.5 means February 1-5). I guess it may need to be applied to AI technology here (although I am also learning AI, my focus is CV, so I really can't do anything about it)
Complete code link: (failed to visit GitHub, trying, update the article or post it in the comment area after uploading)
Thank you for seeing here! If you are interested, you can also pay attention to my CSDN account and my WeChat official account "snow in the middle of the talk" contact me and read more articles! Let's grow together!