background
Of course, the background of snowflake algorithm is the demand for unique ID generation in the high concurrency environment of twitter. Thanks to the awesome technology inside twitter, snowflake algorithm has been spread and widely used. It has at least the following characteristics:
It can meet the requirement of no duplicate ID in high concurrency distributed system environment
Based on timestamp, it can ensure basic orderly increment (which is required in some business scenarios)
Do not rely on third-party libraries or middleware
High generation efficiency
Principle of snowflake algorithm
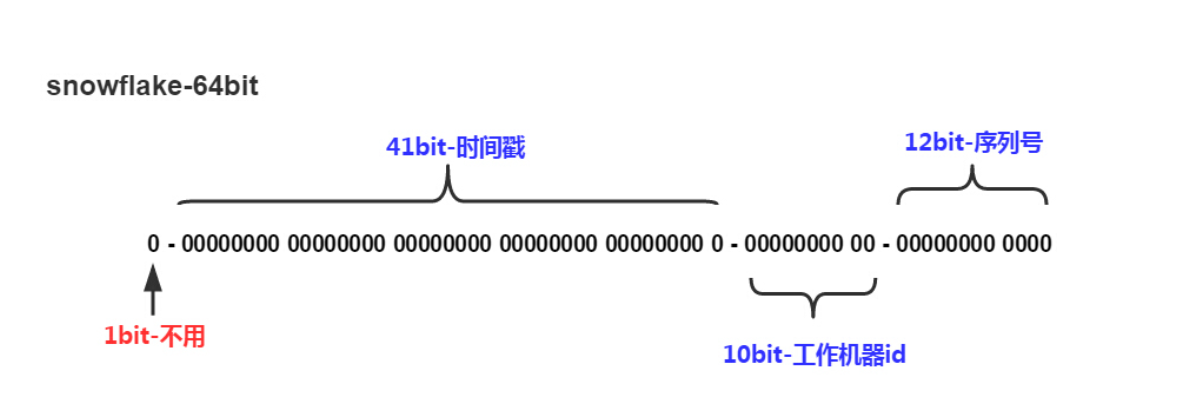
The principle of snowflake algorithm is actually very simple. I think this is one of the reasons why the algorithm can be widely spread.
The algorithm generates a long 64 bit value, and the first bit is not used. Next is the 41 bit millisecond timestamp. We can calculate the following:
2^41/1000*60*60*24*365 = 69
That is, the timestamp can be used for 69 years without repetition, which is enough for most systems.
Many people will get the concept wrong here. This timestamp is relative to the time specified in our business (generally the system online time), not 1970. We must pay attention here.
10 bit data machine bits, so it can be deployed in 1024 nodes.
A sequence of 12 bits, counted in a timestamp of milliseconds. Each node can generate 4096 ID serial numbers per millisecond, so it can support almost 4 million concurrency of a single node. This is enough.
Implementation of snowflake algorithm in java
Because the principle of snowflake algorithm is simple and clear, the implementation is basically the same. The following version is not much different from many on the Internet. The only thing is that I added some notes for you to understand.
public class SnowflakeIdWorker {
/** Start time cut-off (use the time when your business system is online) */
private final long twepoch = 1575365018000L;
/** Number of digits occupied by machine id */
private final long workerIdBits = 10L;
/** The maximum machine id supported is 31 (this shift algorithm can quickly calculate the maximum decimal number represented by several binary numbers) */
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/** The number of bits the sequence occupies in the id */
private final long sequenceBits = 12L;
/** The machine ID shifts 12 bits to the left */
private final long workerIdShift = sequenceBits;
/** Shift the time cut to the left by 22 bits (10 + 12) */
private final long timestampLeftShift = sequenceBits + workerIdBits;
/** The mask of the generated sequence is 4095 (0b111111 = 0xfff = 4095) */
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/** Working machine ID(0~1024) */
private long workerId;
/** Sequence in milliseconds (0 ~ 4095) */
private long sequence = 0L;
/** Last generated ID */
private long lastTimestamp = -1L;
//==============================Constructors=====================================
/**
* Constructor
* @param workerId Work ID (0~1024)
*/
public SnowflakeIdWorker(long workerId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("workerId can't be greater than %d or less than 0", maxWorkerId));
}
this.workerId = workerId;
}
// ==============================Methods==========================================
/**
* Get the next ID (the method is thread safe)
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
//If the current time is less than the timestamp generated by the last ID, it indicates that the system clock has fallback, and an exception should be thrown at this time
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//If it is generated at the same time, the sequence within milliseconds is performed
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//Sequence overflow in milliseconds
if (sequence == 0) {
//Block to the next millisecond and get a new timestamp
timestamp = tilNextMillis(lastTimestamp);
}
}
//Timestamp change, sequence reset in milliseconds
else {
sequence = 0L;
}
//Last generated ID
lastTimestamp = timestamp;
//Shift and put together by or operation to form a 64 bit ID
return ((timestamp - twepoch) << timestampLeftShift) //
| (workerId << workerIdShift) //
| sequence;
}
/**
* Block to the next millisecond until a new timestamp is obtained
* @param lastTimestamp Last generated ID
* @return Current timestamp
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* Returns the current time in milliseconds
* @return Current time (MS)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
}
Some people may not understand the following method of generating maximum value. Let me explain here,
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
First of all, we should know that negative numbers are expressed in the form of complement in the computer, and complement is the original code of the absolute value of negative numbers, and then obtain the inverse code, and then add 1.
It seems a little messy, right? For example.
-1 Take the binary representation with absolute value of 1 and 1, that is, the original code is: 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001 1 Then reverse the operation, that is, 1 becomes 0; 0 Change 1 to obtain: 11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111110 1 Then add 1 to get: 11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111 1 OK,This is it.-1 The representation in the computer, and then let's take a look(-1L << sequenceBits),This is very simple. Just shift 12 bits to the left to get: 11111111 11111111 11111111 11111111 11111111 11111111 11110000 00000000 1 The above two XORs get: 00000000 00000000 00000000 00000000 00000000 00000000 00001111 11111111 1 That's 4095.
The first part mentioned that the snowflake algorithm has high performance. Next, let's test the performance:
public static void main(String[] args) {
SnowflakeIdWorker idWorker = new SnowflakeIdWorker(1);
long start = System.currentTimeMillis();
int count = 0;
for (int i = 0; System.currentTimeMillis()-start<1000; i++,count=i) {
idWorker.nextId();
}
long end = System.currentTimeMillis()-start;
System.out.println(end);
System.out.println(count);
}
Using the above code, I can generate 400w + IDS per second in my own evaluation notebook. The efficiency is still quite high.
Some details are discussed
Adjust bit distribution
Many companies will make secondary transformation according to their own business according to the snowflake algorithm. for instance. Your company's business evaluation does not need to run for 69 years, maybe 10 years is enough. However, there may be more than 1024 nodes in the cluster. In this case, you can adjust the timestamp to 39 bits, and then adjust the workerid to 12 bits. At the same time, the workerid can also be split, for example, according to the business or according to the computer room.
How to generate workerid in general
There are many options. For example, our company has used the method of transmitting the startup parameters through the jvm before. When the application is started, we can obtain a startup parameter to ensure that different startup parameters are passed in when each node is started. Startup parameters are generally passed in through the - D option, for example:
-Dname=value
Then we can pass it in the code
System.getProperty("name");
Get it, or you can get it through the @ value annotation.
Also, many deployments are based on k8s container deployment. This scheme often deploys multiple containers with one click based on the same yaml file. Therefore, it is impossible to pass in different startup parameters for each node through the above method.
This problem can be solved by calculating the workerid according to some rules in the code, such as the IP address of the node. A scheme is given below:
private static long makeWorkerId() {
try {
String hostAddress = Inet4Address.getLocalHost().getHostAddress();
int[] ips = StringUtils.toCodePoints(hostAddress);
int sums = 0;
for (int ip: ips) {
sums += ip;
}
return (sums % 1024);
} catch (UnknownHostException e) {
return RandomUtils.nextLong(0, 1024);
}
}
In fact, this is to obtain the IP address of the node, add the ascii code value of each byte in the IP address, and then modulus the maximum value. Of course, this method may produce duplicate IDs.
There are other schemes on the Internet, such as taking the last 10 bits of IP.
In short, no matter what scheme is used, try to ensure that the workerid is not repeated. Otherwise, even in the case of low concurrency, id duplication is easy to occur.
Time callback problem
The most common problem is the ID duplication caused by time callback. There is no effective solution in the snowflake algorithm, only throwing exceptions
Time callback involves two situations
Instance downtime → time callback → instance restart → calculate id
Instance running → clock callback → calculate id
Algorithm optimization
The snowflake algorithm strongly depends on the timestamp. The algorithm records the last timestamp or id each time and compares it with the current one. If it is abnormal, it will wait or throw an exception