Chat robot
Chat robots can be used for practical purposes, such as customer service or information acquisition. Some chat robots will be equipped with natural language processing systems, but most simple systems will only retrieve the input keywords and find the most appropriate response sentences from the database. Chat robots are part of virtual assistants (such as Google smart assistant) and can connect with many organizations' applications, websites and instant messaging platform (Facebook Messenger). Non assistant applications include chat rooms for entertainment purposes, research and product specific promotions, and social robots.
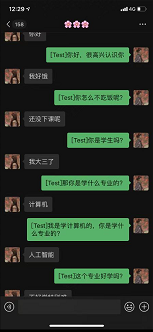
Interested students can refer to this demo to implement an emotion recognition robot on their wechat
demo link: https://github.com/mawenjie8731/paddlenlp-wechaty-demo
Build a chat robot using paddelnlp generative API
In recent years, man-machine dialogue system has been widely concerned by academia and industry, and has achieved good development. Open domain dialogue system aims to establish an open domain multi round dialogue system, so that the machine can interact with people smoothly and naturally. It can not only chat with daily greetings, but also complete specific functions, so that the open domain dialogue system has practical application value.
This example will focus on the functions and usage of the built-in generative API of PaddleNLP, and use the built-in Plato mini model of PaddleNLP and the supporting generative API to implement a simple chat robot.
Environmental requirements
-
PaddlePaddle
This project relies on PaddlePaddle 2 and above. Please refer to Installation guide Install
-
PaddleNLP
pip install --upgrade paddlenlp -i https://pypi.org/simple
-
sentencepiece
pip install --upgrade sentencepiece -i https://pypi.org/simple
-
Python
Python version requires 3.6+
The AI Studio platform has Paddle and PaddleNLP installed by default, and the version is updated regularly. To manually update the pad, refer to Propeller installation instructions , install the latest version of the propeller frame in the corresponding environment.
Ensure that the latest version of PaddleNLP is installed using the following command:
!pip install --upgrade paddlenlp -i https://pypi.org/simple
!pip install --upgrade pip !pip install --upgrade sentencepiece
Generative API
PaddleNLP provides generate() function for generative tasks, which is embedded in all generative models of PaddleNLP. Green search, Beam Search and Sampling decoding strategies are supported. Users only need to specify the decoding strategy and corresponding parameters to complete prediction decoding and obtain the token ids and probability score of the generated sequence.
Here is an example of GPT model using generation API:
1. Load paddlenlp transformers. Gptchinesetokenizer for data processing
Before text data is input into the pre training model, it needs to be transformed into features through data processing. This process usually includes word segmentation, token to id, add special token and other steps.
PaddleNLP has built-in corresponding tokenizer for various pre training models. You can load the corresponding tokenizer by specifying the model name you want to use.
Calling GPTChineseTokenizer__ call__ Method turns what we say into input acceptable to the model.
from paddlenlp.transformers import GPTChineseTokenizer # Set the name of the model you want to use model_name = 'gpt-cpm-small-cn-distill' tokenizer = GPTChineseTokenizer.from_pretrained(model_name)
import paddle user_input = "Weeding day at noon, sweat drops under the soil, who knows Chinese food" # Convert text to ids input_ids = tokenizer(user_input)['input_ids'] print(input_ids) # Convert the converted id to tensor input_ids = paddle.to_tensor(input_ids, dtype='int64').unsqueeze(0) print(input_ids)
2. Use PaddleNLP to load the pre training model with one click
PaddleNLP provides Chinese pre training models such as GPT and unifiedtransformer, which can be loaded with one click through the name of the pre training model.
GPT takes the encoder of Transformer Decoder as the basic component of the network and adopts one-way attention mechanism, which is suitable for long text generation tasks.
PaddleNLP currently provides a variety of Chinese and English GPT pre training models. This time, we use a small Chinese GPT pre training model. Please refer to other pre training models Model List.
from paddlenlp.transformers import GPTLMHeadModel # One click loading Chinese GPT model model = GPTLMHeadModel.from_pretrained(model_name)
# Call generate API to text
ids, scores = model.generate(
input_ids=input_ids,
max_length=16,
min_length=1,
decode_strategy='greedy_search')
print(ids)
print(scores)
generated_ids = ids[0].numpy().tolist() # Use tokenizer to convert the generated id to text generated_text = tokenizer.convert_ids_to_string(generated_ids) print(generated_text)
You can see that the generated effect is good, and the usage of the generated API is also very simple.
Let's show how to use the unified transformer model and generative API to complete the chat conversation.
1. Load paddlenlp transformers. Unifiedtransformertokenizer for data processing
UnifiedTransformerTokenizer is called in the same way as GPT, but the API for data processing is slightly different.
Call the dialog of UnifiedTransformerTokenizer_ The encode method turns what we say into input acceptable to the model.
from paddlenlp.transformers import UnifiedTransformerTokenizer # Set the name of the model you want to use model_name = 'plato-mini' tokenizer = UnifiedTransformerTokenizer.from_pretrained(model_name)
user_input = ['Hello, how old are you this year']
# Call dialogue_ The encode method generates input
encoded_input = tokenizer.dialogue_encode(
user_input,
add_start_token_as_response=True,
return_tensors=True,
is_split_into_words=False)
print(encoded_input.keys())
dialogue_ For detailed usage of encode, please refer to dialogue_encode.
2. Use PaddleNLP to load the pre training model with one click
Like GPT, we can call the UnifiedTransformer pre training model with one click.
UnifiedTransformer Taking Transformer's encoder as the basic component of the network and adopting flexible attention mechanism, it is very suitable for text generation tasks. Special tokens identifying different dialogue skills are added to the model input, so that the model can support chat dialogue, recommended dialogue and knowledge dialogue at the same time.
PaddleNLP currently provides three Chinese pre training models for UnifiedTransformer:
- unified_transformer-12L-cn the pre training model is trained on a large-scale Chinese conversation data set
- unified_transformer-12L-cn-luge the pre training model is unified_transformer-12L-cn is obtained by fine tuning the thousand word dialogue data set.
- The proto mini model uses a billion levels of Chinese chat conversation data for pre training.
from paddlenlp.transformers import UnifiedTransformerLMHeadModel model = UnifiedTransformerLMHeadModel.from_pretrained(model_name)
Next, we will pass the processed input into the generate function and configure the decoding strategy.
Here we use the decoding strategy of TopK and sampling. That is, sampling according to probability from the k results with the largest probability.
ids, scores = model.generate(
input_ids=encoded_input['input_ids'],
token_type_ids=encoded_input['token_type_ids'],
position_ids=encoded_input['position_ids'],
attention_mask=encoded_input['attention_mask'],
max_length=64,
min_length=1,
decode_strategy='sampling',
top_k=5,
num_return_sequences=20)
print(ids)
print(scores)
from utils import select_response # Simply select the best response according to probability result = select_response(ids, scores, tokenizer, keep_space=False, num_return_sequences=20) print(result)
For more detailed usage of the generative API, refer to generate.
Now let's try multiple rounds of dialogue in the terminal!
The example of PaddleNLP provides the code to build a complete dialogue system( human-computer interaction ). We can try it in the terminal. Copy the following code block on the terminal to use
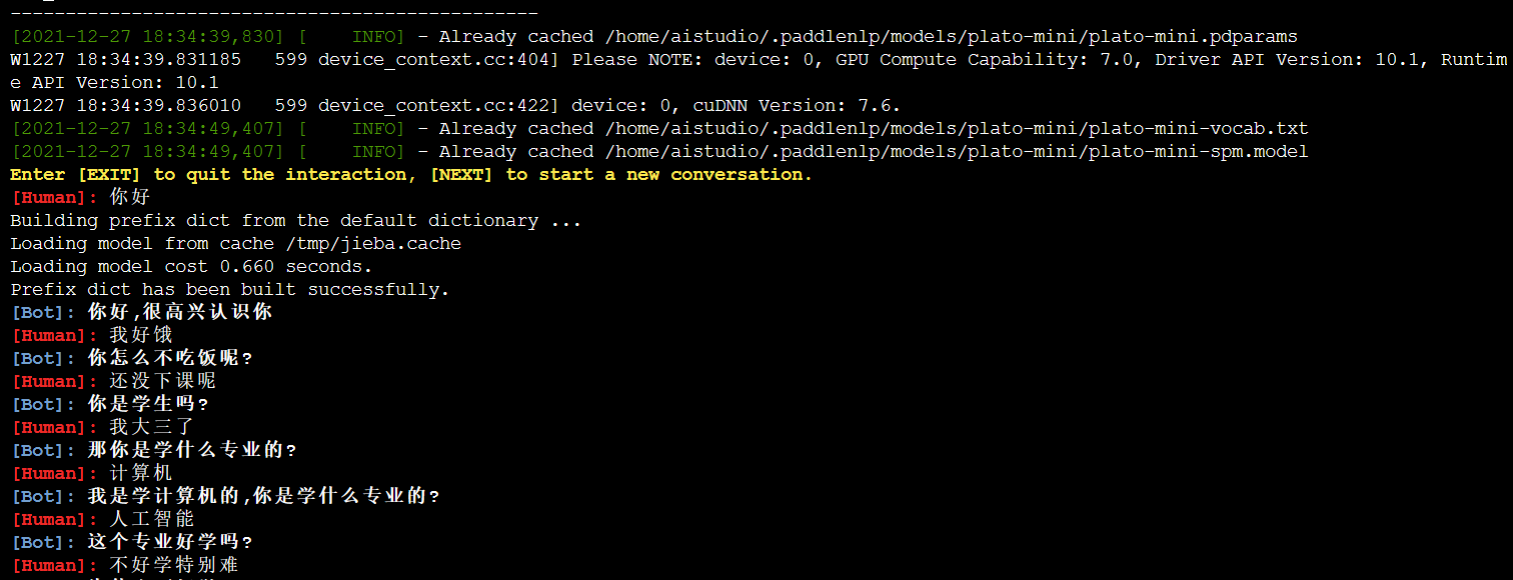
# GPU starts, only single card is supported #Just enter it in the background # export CUDA_VISIBLE_DEVICES=0 # python interaction.py \ # --model_name_or_path=plato-mini \ # --min_dec_len=1 \ # --max_dec_len=64 \ # --num_return_sequences=20 \ # --decode_strategy=sampling \ # --top_k=5 \ # --device=gpu
wecheaty bot
Below is a chat robot that can be used on its own wechat, but users need to bear the risk from wechat officials. First clone the paddlehub wechaty demo
!git clone https://github.com/KPatr1ck/paddlehub-wechaty-demo.git
puppet-wechat
Then apply for a short-term token, and then configure the environment variable to use it. The short-term token only lasts for 7 days, and apply for a link https://wechaty.js.org/docs/puppet-services/
Copy the application to the export wechaty below_ PUPPET_ SERVICE_ Token is enough
%cd paddlehub-wechaty-demo
Copy the code block at the terminal and log in to wechat
# export WECHATY_PUPPET="wechaty-puppet-wechat" # export WECHATY_PUPPET_SERVICE_TOKEN="your_token" # export WECHATY_PUPPET_SERVICE_ENDPOINT="your_SERVICE_ENDPOINT" # python examples/paddlehub-chatbot.py
7, Summary and sublimation
- This project is my first attempt on NLP. I hope you can encourage me
- We will try to apply for a long-term token in the future. Please look forward to it
Personal profile
I'm a third year undergraduate from Jiangsu University of science and technology. I've just come into contact with in-depth learning. I hope you will pay more attention
Interests: target detection, reinforcement learning, natural language processing
Personal link:
Ma Junxiao
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/824948