The following is taken from Mo fan Python;
If Numpy stores data in rectangular form, Pandas stores data in dictionary form;
Two main data structures of Pandas: Series and DataFrame;
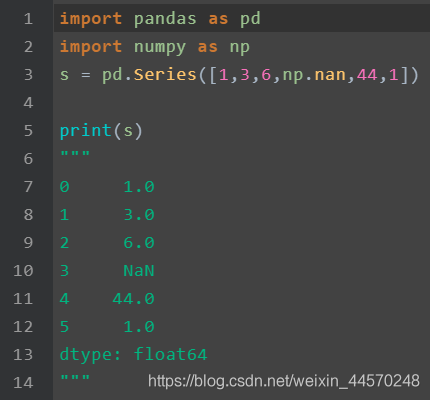
Series: the index is on the left and the value is on the right. If no index is specified for the data, an integer index of 0~N-1 (N is the length) will be automatically created
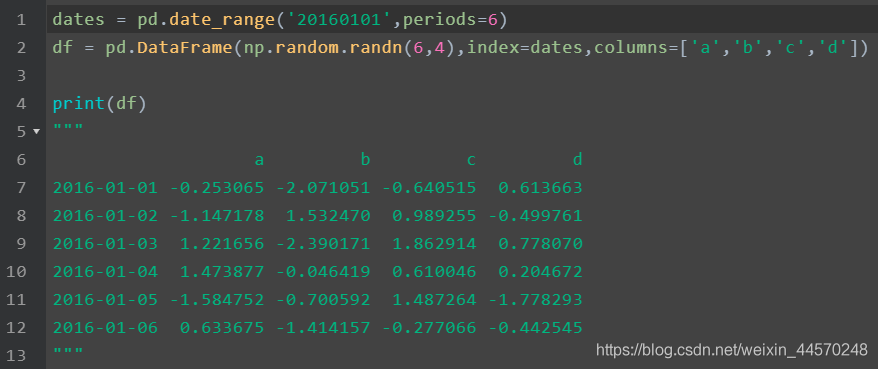
DataFrame: it is a tabular data structure. It contains a group of ordered columns. Each column can be of different value types (such as numeric value, string, etc.), with both row index and column index
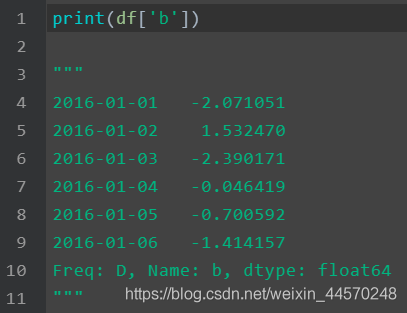
Selected b elements:
If no index value is given, it is also sorted from 0 to n-1 by default;
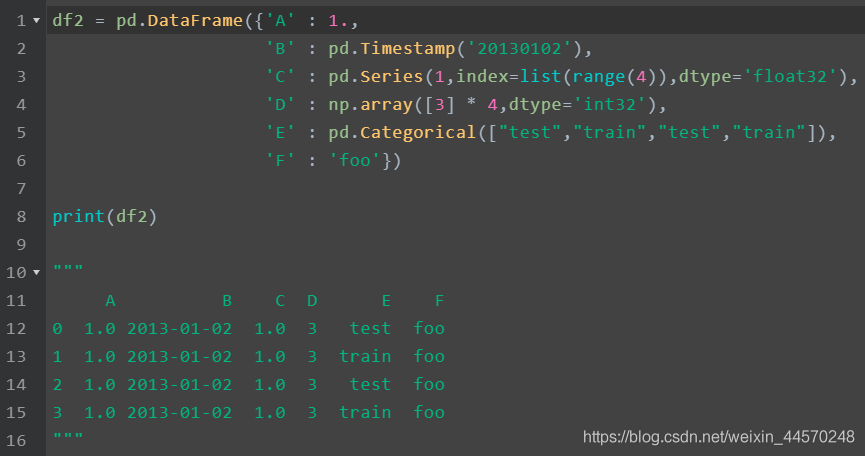
Here is a method to generate dataframe:
View types in data:
print(df2.dtypes)
See the sequence number of the column:
print(df2.index) # It's the index on the left
Look at the index name of the row:
print(df2.columns)
Only look at the value of df2, not the index:
print(df2.value)
Data summary:
df2.describe()
Flip data:
print(df2.T)
Sort and output the index of data:
print(df2.sort_index(axis = 1, ascending = False)) # Sort row index
Sort and output the values of data:
print(df2.sort_values(by = 'B'))
Select the value corresponding to a row index:
print(df2['A']) # Or print(df2.A)
Multi row or multi column index:
print(df2[a:b]) # a. b is the corresponding row index name or column index name or the corresponding sequence number, starting from 0
Index with label loc:
print(df2.loc[2]) #Returns the index value of line 3 print(df2.loc[:,['A','B']]) #Returns the values of columns A and B, and its row index and column index are returned together print(df2.loc[2,['A']]) #Return the index value of column A in row 3. For A specific value, there may be more than one value in front
According to the sequence iloc index:
print(df2.iloc[3,1]) #Return the data of the fourth row and the second column. You can only see one data print(df2.iloc[3:5,1:3]) #Return the data in rows 4 ~ 5 and columns 2 ~ 3. You can see the index on the left and the index on the top print(df2.iloc[[1,3],1:3]) #Return the data of rows 2 and 4 and columns 2 ~ 3. You can see the same index on the left and the index on the top
Mix selection:
print(df2.ix[:3,['A']]) #Return the data of the first three rows and column A
Filter by judgment:
print(df2[df2.A>0.5]) #First pass df2 A> 0.5 find all row indexes x that meet the conditions, and then return all column data of these row indexes x
It is the same to set a specific value for the data in the dataframe, which can be indexed, and then enter the value to be set to the right of the equal sign;
Add a Series sequence to the dataframe (the length must be consistent):
df2['G'] = pd.Series([1,2,3,4], index = pd.date_range(0, 4)) #The preceding [1,2,3,4] is the data of column G in column 7 to be added, and index is the corresponding row index name
Remove the rows or columns with NaN in the dataframe:
df2.dropna(axis = 0, how = 'any') #axis = 0 is row operation and 1 is column operation; # 'any' is to delete this row or column as long as NaN exists, but the row index or column index name remains unchanged; # If how = 'all', the row or column must be all NaN before deletion
Substitute other values for NaN:
df2.fillna(value = 0) #Replace NaN with a value of 0
Check whether NaN exists in the data. If so, return True:
np.any(df2.isnull()) == True
File read:
pd.read_csv('xxx') # xxx is the file name
file store:
df2.to_pickle('xxx') # xxx is the file name
Merge concat:
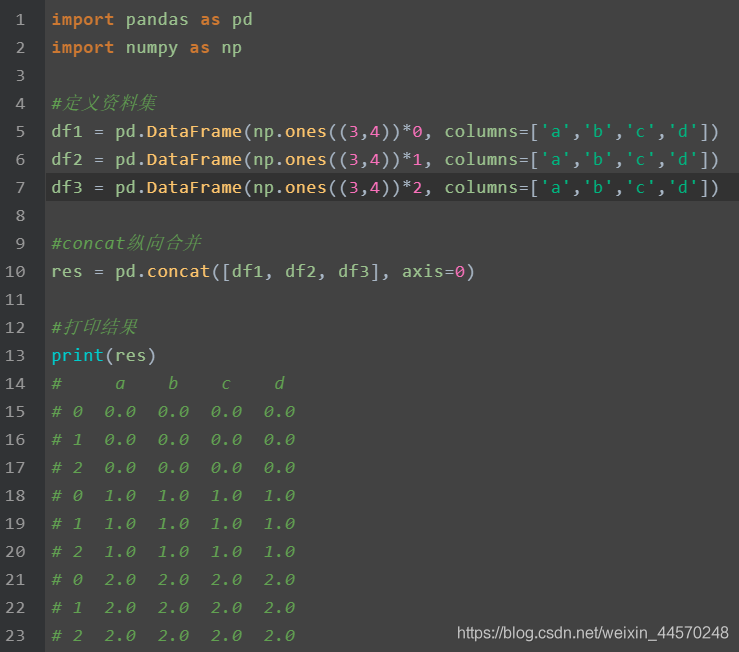
If you want to reset the index on the left, concat([df1,df2,df3], axis = 0, ignore_index = True)
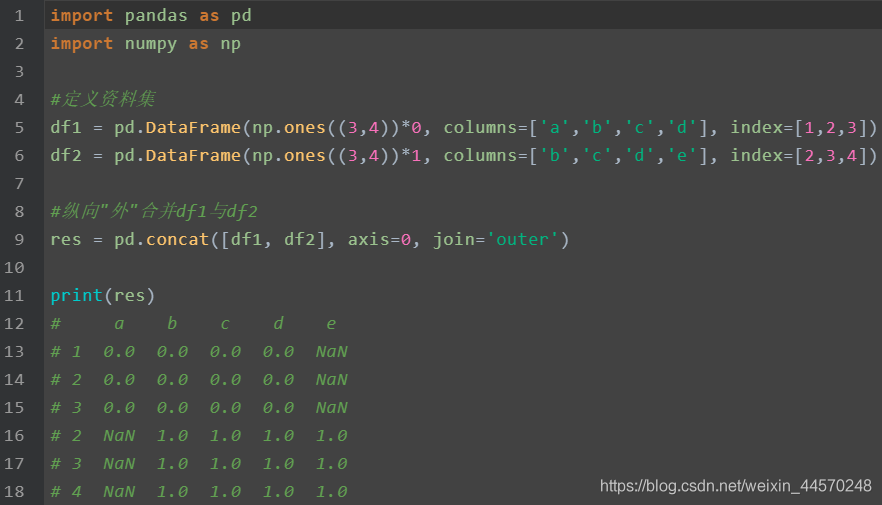
join:
When no parameters are set, the function defaults to join = 'outer'. This method is to perform vertical consolidation according to columns. The same columns are merged up and down, and other independent columns form their own columns. The positions without values are filled with NaN:
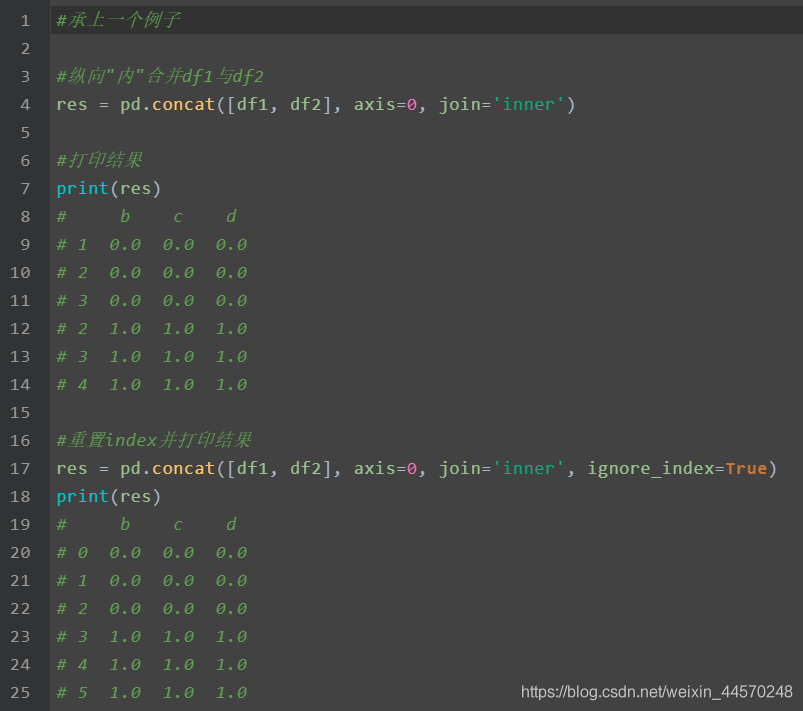
The following is join = 'inner':
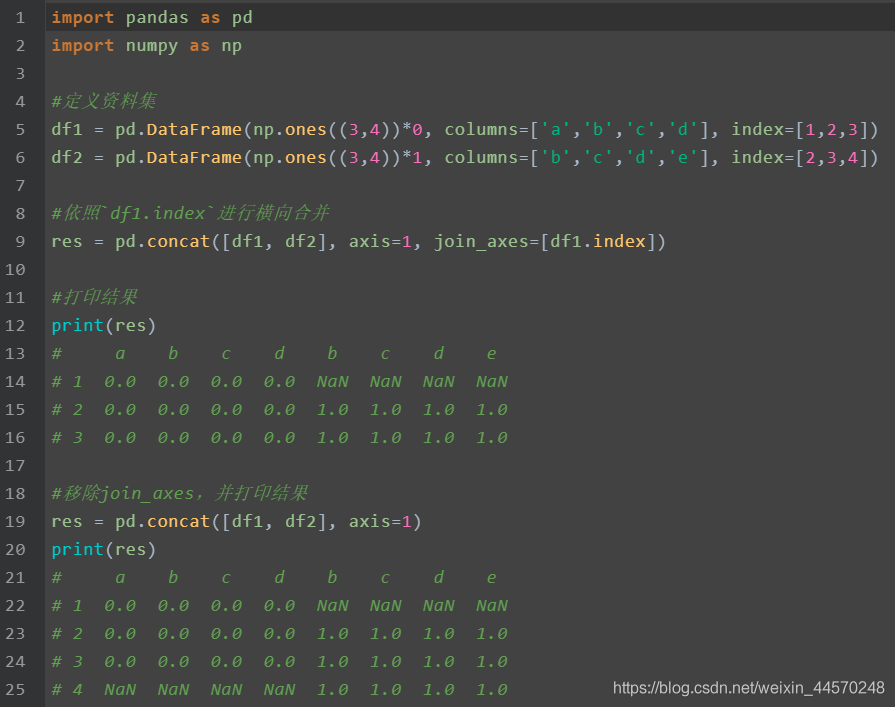
Merge according to the index of a dataframe:
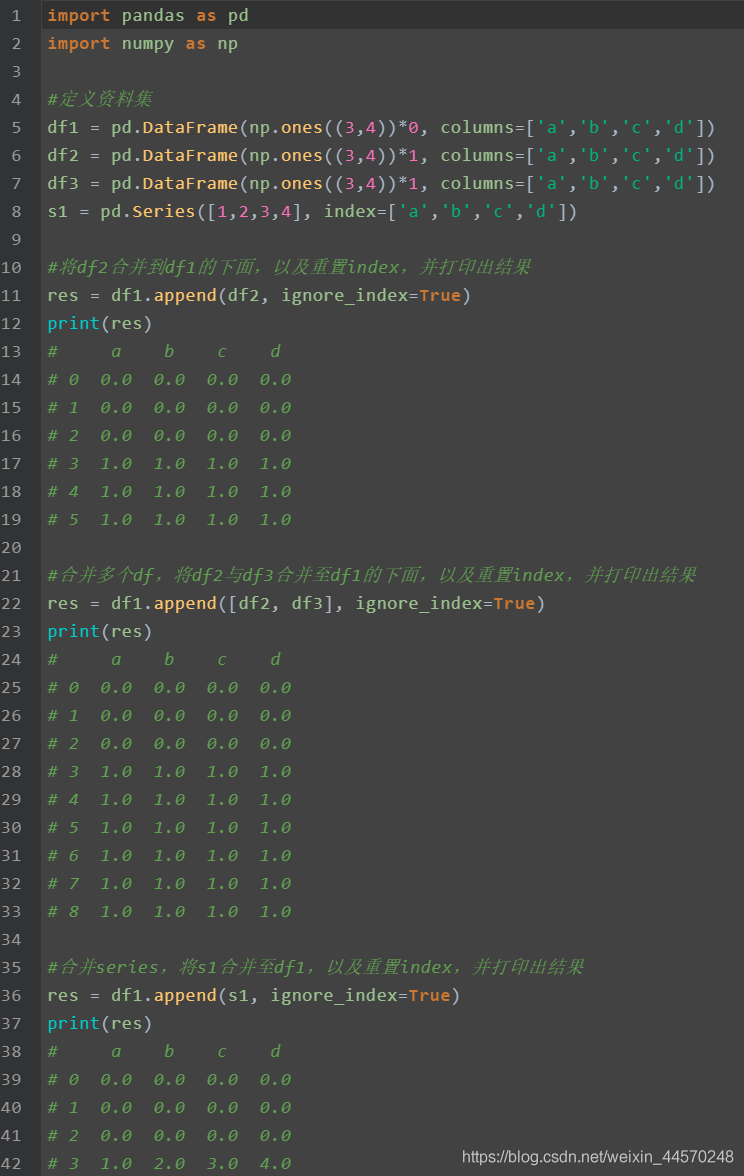
append: can only merge vertically:
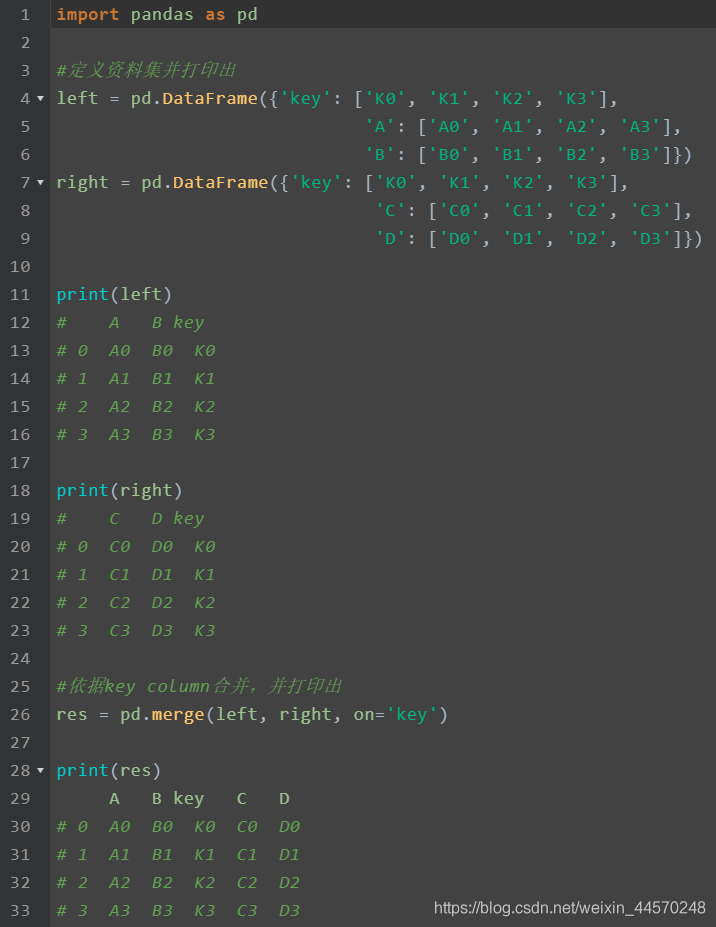
Merge according to key:
When merging, you can also merge according to how = 'inner' and how = 'outer', and NaN is not;
If the parameter indicator = True or 'indicator' is added_ Column ', then the last column will have a_ merge or 'indicator_ The column index name of column ', and the corresponding value below it indicates which dataframe is merged according to;