1. Basic information
| subject | Author and unit | source | particular year |
|---|---|---|---|
| A Unified Generative Framework for Various NER Subtasks | Qiu Xipeng group, Fudan University | ACL | 2021 |
13 Citations, 70 References
Paper link: https://arxiv.org/pdf/2106.01223.pdf
Thesis Code: https://github.com/yhcc/BARTNER
2. Key points
| Research topics | Problem background | Core method process | Highlights | data set | conclusion | Paper type | keyword |
|---|---|---|---|---|---|---|---|
| The first mock exam model of three entities extraction | Three NER tasks (usually solved separately): a. flat NER (simple, flat entity extraction); b. nested NER (nested entity extraction); c. discontinuous NER (discontinuous entity extraction) | The pointer method is used to transform the annotation task into a sequence generation task (the main contribution of this paper is also here), and the normal form of seq2seq is used for generation. The generation process uses the pre training model BART, which uses the task of returning the original text from the destroyed text as the pre training target. | Convert the annotation task into a sequence generation task | CoNLL-2003,OntoNotes dataset;ACE 2004,ACE 2005,Genia corpus;CADEC,ShARe13,ShARe14; | The three variant tasks of NER can be solved uniformly through brat's generation model. | NER,Seq2Seq,BART |
3. Model
3.1 three typical NER
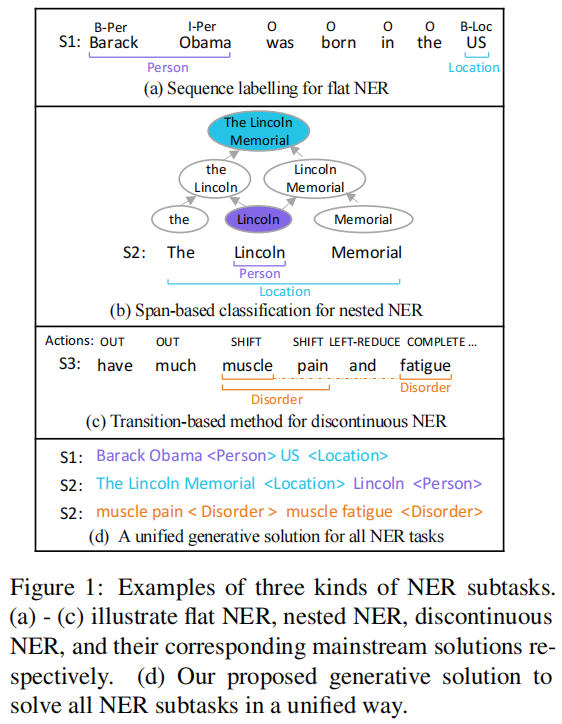
flat NER: it is a classic method. A character is marked with a label;
Enumerating all possible spans: 1; Method 2: using the method of n. hypergraph;
It can be seen that it is impossible to solve the two cases of needed and discontinuous based on classical methods, and it is difficult to solve the case of discontinuous in terms of the span of enumeration; The algorithm of this method is complex and high.
Although hypergraph can be well expressed, so span is possible, but decoding is still difficult.
discontinuous: transition-discontinuous-ner
[12]An Effective Transition-based Model for Discontinuous NER.md
https://github.com/daixiangau/acl2020-transition-discontinuous-ner
3.2 proposed contents
The pointer mode is used, the annotation task is transformed into a sequence generation task (the main contribution of this paper is also here), and the normal form of seq2seq is used for generation. The generation process uses the pre training model BART, which uses the task of restoring text from destroyed text as the pre training target.
- Seq2Seq mode
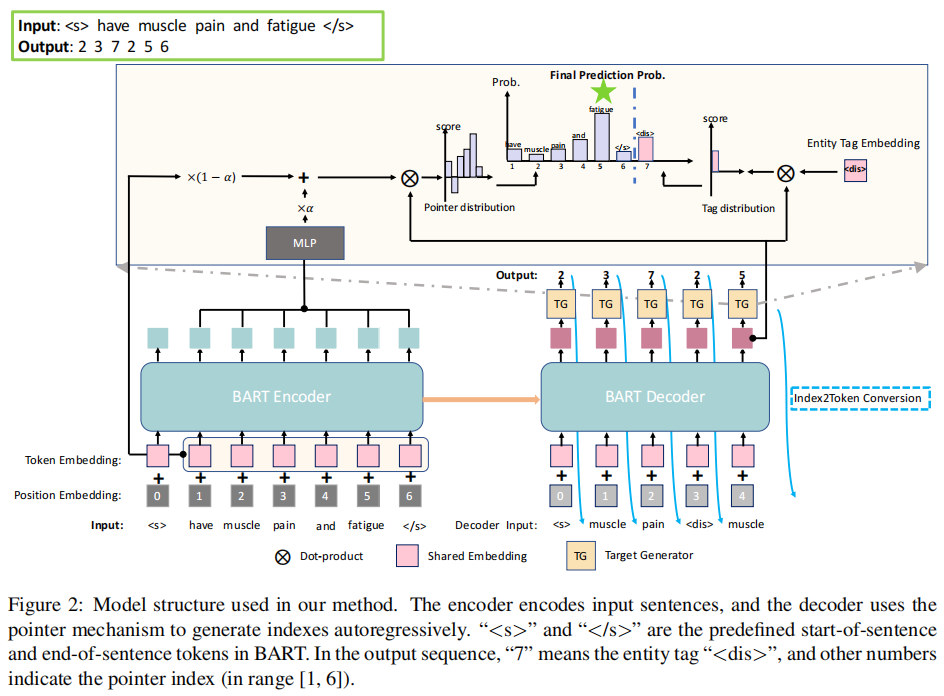
- code:
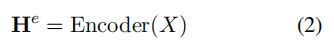
Turn the sentence into a vector.
- decode:
Obtain the subscript probability distribution in each step:
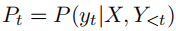
Among them,
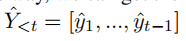
Index2Token:
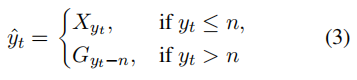
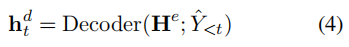
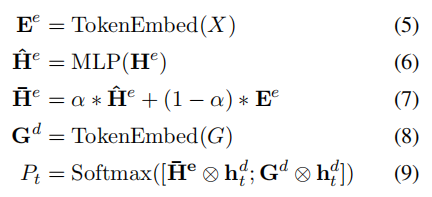
TokenEmbed: the token is embedded, and the encoder is shared with the decoder;
a: Indicates a super parameter;
[****· ; **·****] 😗* Represents and joins in the first dimension;
**⊗: * * indicates dot multiplication;
**G_d: * * indicates tag vector;
As can be seen from the above figure, the last Softmax is the combination of two distributions. One is the token part, i.e. H_e. One is the tag part, that is, G_d.
-
Training stage: negative log likelihood loss, the teacher forcing method
-
Prediction stage: an autoregressive method to generate target sequence;
-
The decoding algorithm converts the index sequence into entity span.

-
bart based entity representation:
The original representation is based on byte pair encoding (BPE) tokenization
BEP algorithm is very simple. It is mainly used to find the high-frequency substring in the string. These substrings are the contents of subword between word and char. Here, English is generally spoken.
Three pointer based entity representations are proposed to locate the entities in the original sentence: Span, BPE and Word
- Span: each start point and end point of the entity. If it is discontinuous, it will be written continuously
- BPE: all Token locations
- Word: record start position only

4. Experiment and analysis
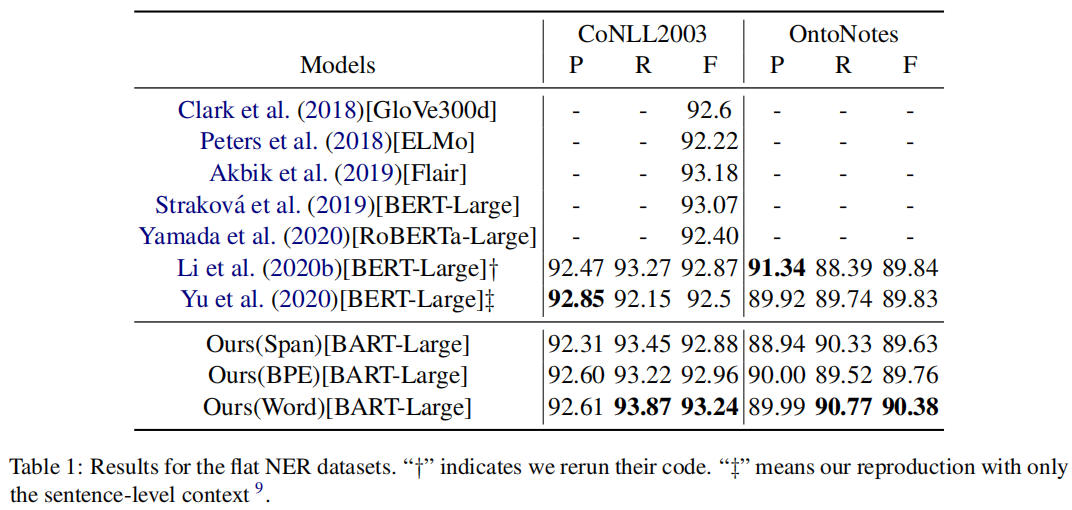
4.1 result of flat
Flat NER: CoNLL-2003,OntoNotes dataset;
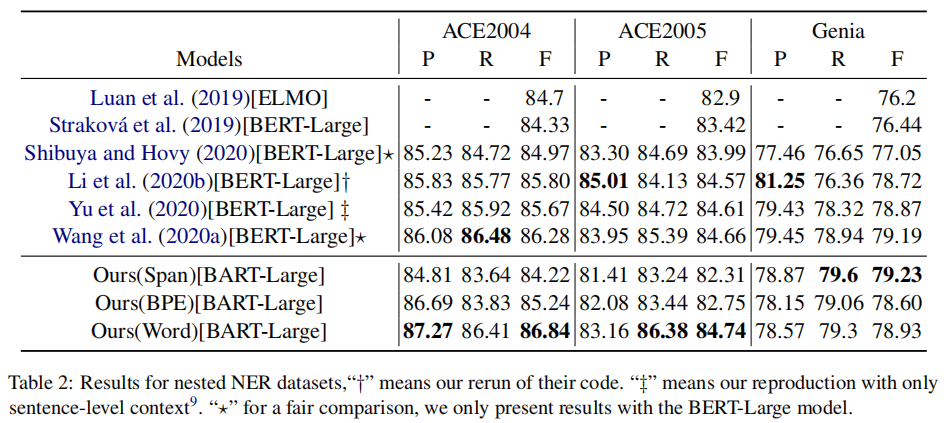
4.2 results of nested case
Nested NER: ACE 2004,ACE 2005,Genia corpus;
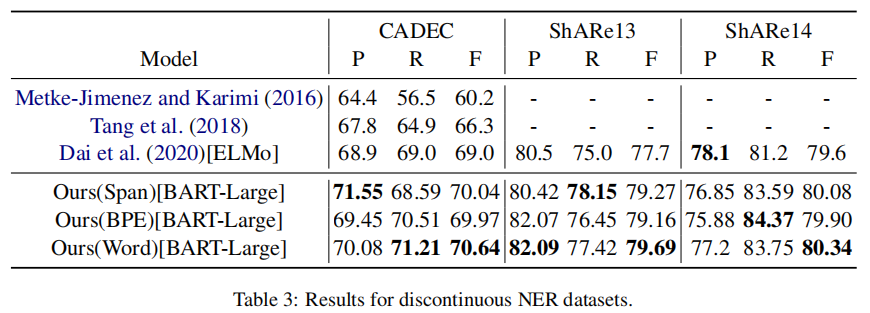
4.3 Discontinuous situation
Discontinuous NER: CADEC,ShARe13,ShARe14;
4.4 the three entity representations proposed in the paper are compared
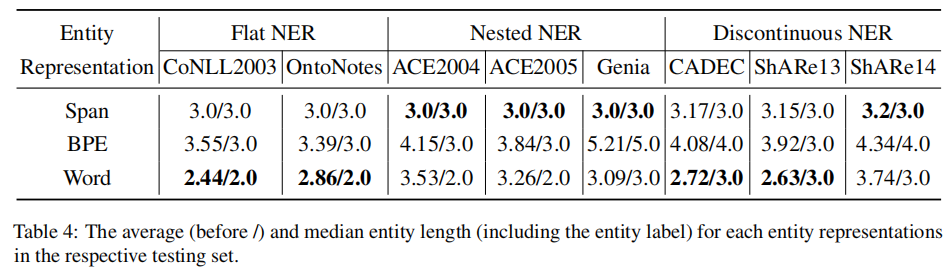
4.5 comparison of different entity representations and prediction results
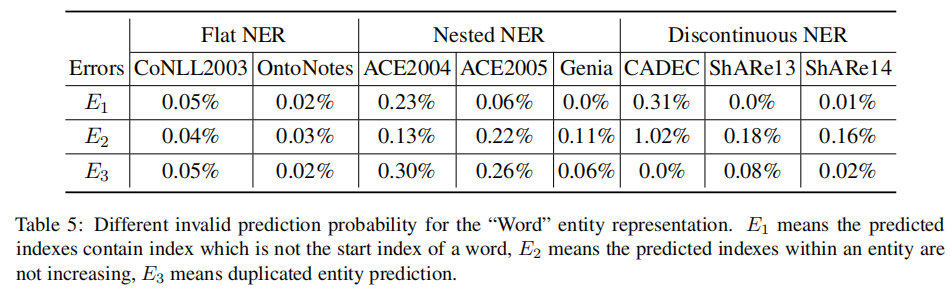
4.6 separate comparison of discontinuities
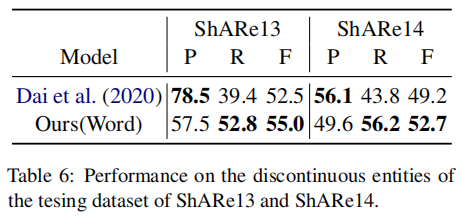
5. Code
Based on fastNLP, fitlog toolkit is borrowed. Here is a record of the inconsistencies with github during the operation, which have not been mentioned.
Learning documents about fastnlp: http://www.fastnlp.top/docs/fastNLP/index.html
5.1 environment
python 3.6 was not available, and later python-3.7.11 was used;
For fitlog, it is required to install git. Do you want to report an error? git cannot be found;
5.2 data (take conll2003 as an example)
For conll2003, the specific path does not need to be found in the parent directory, but in the current directory. If it cannot be found.
The DataBundle is displayed as:
In total 3 datasets:
test has 3453 instances.
train has 14041 instances.
dev has 3250 instances.
5.3 training
The first run will be slower. You need to process the data and download the pre training model
Data caches: 'caches / data'_ facebook/bart-large_ conll2003_ word. pt’
Predictive training model: 1.02G, bart_name = 'Facebook / Bart large', the download speed is OK.
batch_size = 16, resulting in insufficient video memory (one GeForce RTX 2080 Ti); Later, batch was set_ size = 8;
result
max_len_a:0.6, max_len:10
In total 3 datasets:
test has 3453 instances.
train has 14041 instances.
dev has 3250 instances.
The number of tokens in tokenizer 50265
50269 50274
input fields after batch(if batch size is 2):
tgt_tokens: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2, 8])
src_tokens: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2, 11])
first: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2, 11])
src_seq_len: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2])
tgt_seq_len: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2])
target fields after batch(if batch size is 2):
entities: (1)type:numpy.ndarray (2)dtype:object, (3)shape:(2,)
tgt_tokens: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2, 8])
target_span: (1)type:numpy.ndarray (2)dtype:object, (3)shape:(2,)
tgt_seq_len: (1)type:torch.Tensor (2)dtype:torch.int64, (3)shape:torch.Size([2])
......
Epoch 16/30: 53%|█████▎ | 34592/64860 [2:50:07<2:13:58, 3.77it/s, loss:0.00078]
Epoch 17/30: 53%|█████▎ | 34592/64860 [2:50:07<2:13:58, 3.77it/s, loss:0.00078]Evaluate data in 58.98 seconds!
Evaluation on dev at Epoch 16/30. Step:34592/64860:
Seq2SeqSpanMetric: f=92.80000000000001, rec=93.28999999999999, pre=92.33, em=0.8784
......
......
......
Epoch 23/30: 77%|███████▋ | 49726/64860 [4:08:28<50:44, 4.97it/s, loss:0.00012]
Epoch 23/30: 77%|███████▋ | 49726/64860 [4:08:28<50:44, 4.97it/s, loss:0.00012]
......
......
......
Epoch 23/30: 77%|███████▋ | 49726/64860 [4:08:28<50:44, 4.97it/s, loss:0.00012]
Epoch 24/30: 77%|███████▋ | 49726/64860 [4:08:28<50:44, 4.97it/s, loss:0.00012]Evaluate data in 58.7 seconds!
Evaluation on dev at Epoch 23/30. Step:49726/64860:
Seq2SeqSpanMetric: f=92.84, rec=93.4, pre=92.28, em=0.8769
......
......
.......
Evaluate data in 56.74 seconds!
Evaluation on dev at Epoch 30/30. Step:64860/64860:
Seq2SeqSpanMetric: f=93.07, rec=93.58999999999999, pre=92.56, em=0.8798
In Epoch:25/Step:54050, got best dev performance:
Seq2SeqSpanMetric: f=93.13, rec=93.57, pre=92.69, em=0.881
After running for more than 5 hours, the result is r:93.57,p:92.69,f=93.13, which is similar to that of the paper, r=93.87,p=92.62,f=93.24.
About CADEC corpus reproduction experiment:
First, refer to a previous paper: An Effective Transition-based Model for Discontinuous NER.pdf
code: https://github.com/daixiangau/acl2020-transition-discontinuous-ner
Prediction processing code found:
View build_data_for_transition_discontinuous_ner.sh file. Modify the directory according to this script to generate data. After completing the operation, the data output looks like (the same as the requirements of the paper):
During this time I experienced extreme pain in both shoulders , sometimes in the neck also , causing me to wake several times each night . 5,7,14,14 ADR|5,9 ADR Pain was worse in the morning but rarely went away completely during the day . 0,2 ADR Most mornings it was impossible to wash my hair in the shower as I was unable to reach the top of my head with my hands . 15,25 ADR Pain and restricted movement often prevented me from putting on shoes and socks without assistance . 0,0 ADR|2,3 ADR In January this year I started experiencing discomfort in my left hand for the first time . 7,11 ADR
Back to the bartenr project, just find a directory and put it. When running in the back * * pay attention to whether the path * * is correct.
During the training, it is found that the display will increase. Later, it is set to 4 directions and the training is completed smoothly. The running results are shown as follows:
The results of the operation are:
Evaluate data in 128.07 seconds! s:0.00010]
Evaluation on dev at Epoch 30/30. Step:40050/40050: 3.05it/s]
Seq2SeqSpanMetric: f=68.44, rec=68.93, pre=67.95, em=0.7885
Best test performance(may not correspond to the best dev performance):{'Seq2SeqSpanMetric': {'f': 70.72, 'rec': 69.39, 'pre': 72.09, 'em': 0.7784}} achieved at Epoch:12.
Best test performance(correspond to the best dev performance):{'Seq2SeqSpanMetric': {'f': 68.60000000000001, 'rec': 66.97, 'pre': 70.30999999999999, 'em': 0.7681}} achieved at Epoch:17.
In Epoch:17/Step:22695, got best dev performance:
Seq2SeqSpanMetric: f=69.97, rec=70.04, pre=69.89, em=0.8013
f=69.97, rec=70.04, pre=69.89, which is also very similar to that reported in the paper.
6. Summary
After reading, I found a good article, and recently I was thinking about how to realize non connected entities by generating models. Fortunately, I met it occasionally.
The solution goal is relatively clear, and a set of unified methods to solve three typical NER tasks are proposed.
7. Knowledge sorting (knowledge points, document classification, extract the original text)
8. References
made by happyprince