Introduction to Torrent
The seed file of BitTorrent protocol (English: Torrent file) can save the metadata of a group of files. Files in this format are defined by the BitTorrent protocol. The extension is usually ". Torrent".
The. torrent seed file is essentially a text file, including tracker information and file information. Tracker information mainly refers to the address of the tracker server and the settings for the tracker server used in BT download. The file information is generated according to the calculation of the target file, and the calculation results are encoded according to the Bencode rules in the BitTorrent protocol. Its main principle is to virtually divide the downloaded files into blocks of equal size. The block size must be an integer power of 2k (because it is a virtual block, each block file is not generated on the hard disk), and write the index information and Hash verification code of each block into the seed file; Therefore, the seed file is the "index" of the downloaded file.
Torrent structure
The contents of the Torrent file have been stored in the Bencoding encoding type. On the whole, it is a dictionary structure, as shown below:
Torrent overall structure
Key name | data type | Optional | Key value meaning |
|---|---|---|---|
announce | string | required | Tracker's Url |
info | dictionary | required | The entry is mapped to a dictionary whose key will depend on one or more shared files |
announce-list | array[] | optional | The Url of the standby Tracker, which exists in the form of a list |
comment | string | optional | remarks |
created by | string | optional | Information about the creator or creator |
Torrent single file Info structure
Key name | data type | Optional | Key value meaning |
|---|---|---|---|
name | string | required | Suggested file name to save to |
piceces | byte[] | required | SHA-1 integration Hash for each file block. |
piece length | long | required | Bytes per file block |
Torrent multi file Info structure
Key name | data type | Optional | Key value meaning |
|---|---|---|---|
name | string | required | Recommended directory name to save to |
piceces | byte[] | required | SHA-1 integration Hash for each file block. |
piece length | long | required | Bytes per file block |
files | array[] | required | File list. The contents stored in the list are dictionary structure |
files dictionary structure:
Key name | data type | Optional | Key value meaning |
|---|---|---|---|
path | array[] | required | A string list of corresponding subdirectory names, and the last item is the actual file name |
length | long | required | The size of the file in bytes |
Torrent actual structure Preview
After serializing the whole dictionary with JSON, the structure of single file and multi file is roughly as follows. Note: JSON omits most of the contents of the pieces summary and only shows the beginning part. In addition, due to the setting of my serialization tool, all integers will be serialized into string types.
{
"creation date": "1604347014",
"comment": "Torrent downloaded from https://YTS.MX",
"announce-list": [
[
"udp://tracker.coppersurfer.tk:6969/announce"
],
[
"udp://9.rarbg.com:2710/announce"
],
[
"udp://p4p.arenabg.com:1337"
],
[
"udp://tracker.internetwarriors.net:1337"
],
[
"udp://tracker.opentrackr.org:1337/announce"
]
],
"created by": "YTS.AG",
"announce": "udp://tracker.coppersurfer.tk:6969/announce",
"info": {
"pieces": "ᆲimᅬヒ\u000b*゚ᆲト... ...",
"name": "Love And Monsters (2020) [2160p] [4K] [WEB] [5.1] [YTS.MX]",
"files": [
{
"path": [
"Love.And.Monsters.2020.2160p.4K.WEB.x265.10bit.mkv"
],
"length": "5215702961"
},
{
"path": [
"www.YTS.MX.jpg"
],
"length": "53226"
}
],
"piece length": "524288"
}
}Torrent file code
According to the above, Torrent files are stored in Bencoding code, so we need to have a general understanding of Bencoding code.
Bencoding consists of four basic types of data:
- string: string
- intergers: integer type
- lists: list type
- Dictionary: dictionary type
String type
String type is represented by the following structure: string length: original text of string, for example: 42:udp://tracker.pirateparty.gr:6969/announce .
Shaping type
The integer type is represented by the following structure: I < shaping data > E. for example, i1234e indicates that the shaping data is 1234.
List type
The list type is represented by the following structure: l < list data > e, that is, the list starts with the letter L and ends with the letter e. the data in the middle is the data in the list, and the value in the middle can be one of any four types.
Dictionary type
The dictionary type is represented by the following structure: d < dictionary data > e, that is, the dictionary starts with the letter D and ends with the letter e. the data in the middle is the data in the dictionary, and the value in the middle can be one of any four types.
Actual combination analysis
Let's look at the actual content analysis according to the above description. Let's take the following data as an example:
d8:announce49:udp://tracker.leechers-paradise.org:6969/announce13:announce-listll49:udp://tracker.leechers-paradise.org:6969/announceel48:udp://tracker.internetwarriors.net:1337/announceeee
You can first try to analyze this string of contents according to the above contents. I split this string of data to facilitate you to understand and view. It can be clearly seen that it consists of a dictionary with two key values, one of which is announcement and the other is announcement list. The value of one of them is udp://tracker.leechers-paradise.org:6969/announce , one is a list, and a layer of list is nested in the list.
d
8:announce
49:udp://tracker.leechers-paradise.org:6969/announce
13:announce-list
l
l
49:udp://tracker.leechers-paradise.org:6969/announce
e
l
48:udp://tracker.internetwarriors.net:1337/announce
e
e
eTorrent file parsing
According to the above understanding of Torrent file coding, it is very simple for us to use code for Torrent file. We only need to read the seed byte stream, judge which type it is and convert it accordingly.
That is, read the file bytes and judge which type the bytes belong to: 0-9: string type, i: shaping data, l: list data, d: dictionary data
Then obtain the content of the data according to the specific type of each data, and then read the next file byte to obtain the next data type. According to this analysis, the pseudo code is as follows:
Get string value
// Enter this method when the content corresponding to the read byte is 0-9
String readString(byte[] info,int offset) {
// Read the data before ':', that is, the length of the string
int length = readLength(info,offset);
// Get the actual string content according to the string length
string data = readData(info,length,offset);
// Returns the read string content. The offset read in the whole reading process should be added to offset
return data;
}Get integer type
Here is a note. Considering the problem of data boundary, such as java and other languages, it is recommended to use Long type to prevent data from crossing the boundary.
// When the content corresponding to the read byte is i, enter the method
Long readInt(byte[] info,int offset) {
// Read data before the first 'e', including 'e'
string data = readInt(info,offset)
return Long.valueOf(data);
}Get list type
Because the list type can be mixed with any of the four types, the above two methods are needed.
// When the content corresponding to the read byte is l, enter the method
List readList(byte[] info,int offset){
List list = new List();
// Read until the first 'e'
while(info[offset] != 'e'){
swtich(info[offset]){
// If it is a list, read the list and add to it
case 'l':
list.add(readList(info,offset));
break;
// If it is a dictionary, read the dictionary and add to the list
case 'd':
list.add(readDictionary(info,offset));
break;
// If it is shaping data, read the data and add it to the list
case 'i':
list.add(readInt(info,offset));
break;
// If it is a string, read the string data and add it to the list
case '0-9':
list.add(readString(info,offset));
}
}
// offset moves forward one bit and moves the end character 'e' of the list to read
offset++;
return list;
}Read dictionary type
The type of reading dictionary is very similar to that of the list. The only difference is that the key value needs to be distinguished. The key of the dictionary can only be a string, so judge it in turn.
// When the content corresponding to the read byte is d, enter the method
Dictionary readDictionary(byte[] info,int offset){
Dictionary dic = new Dictionary();
// When the key is null, the string is the key, otherwise it is the value
String key = null;
// Read until the first 'e'
while(info[offset] != 'e'){
swtich(info[offset]){
// If it is a list, read the list and add it to the dictionary. There must be a key when adding the list. Add it directly and leave the key blank
case 'l':
dic.put(key,readList(info,offset));
key = null;
break;
// If it is a dictionary, read the dictionary and add it to the dictionary. There must be a key when adding the dictionary. Add it directly and leave the key blank
case 'd':
dic.put(key,readDictionary(info,offset));
key = null;
break;
// If it is shaping data, read the data and add it to the dictionary. There must be a key when adding shaping data. Directly add and empty the key
case 'i':
dic.put(key,readInt(info,offset));
key = null;
break;
// If it is a string
case '0-9':
string data = readString(info,offset);
// When the key is null, the string is the key, otherwise it is the value
if(key == null){
key = data;
}else{
dic.put(key,data);
key = null;
}
}
}
// offset moves forward one bit and moves the end character 'e' of the list to read
offset++;
return dic;
}Torrent files and Magnet
Magnetic link and Torrent file can be converted to each other. This paper only discusses how to convert Torrent file into Magnet magnetic link.
Magnet overview
Magnetic link is composed of a set of parameters. The order of parameters is not particular, and its format is the same as the query string at the end of HTTP link. The most common parameter is "xt", which is the abbreviation of "exact topic". It is usually the URN formed by the content hash function value of a specific file, for example:
magnet:?xt=urn:bith:YNCKHTQCWBTRNJIV4WNAE52SJUQCZO5C
Note that although this link points to a specific file, the client application must still search to determine where, and if so, can obtain that file (that is, search through DHT, which realizes the conversion from Magnet to Torrent, which is not discussed in this article).
Some field names are shown in the table below:
Field name | meaning |
|---|---|
magnet | Protocol name |
xt | The abbreviation of exact topic, which contains the uniform resource name of the file hash value. BTIH (BitTorrent Info Hash) represents the hash method name. ED2K, AICH, SHA1 and MD5 can also be used here. This value is the identifier of the file and is indispensable. |
dn | The abbreviation of display name, which indicates the file name displayed to the user. This item is optional. |
tr | An abbreviation for tracker, which represents the address of the tracker server. This item is also optional. |
bith | BitTorrent info hash, seed hash function |
Convert Torrent to Magnet
- dn: the file name displayed to the user
This is the value corresponding to the name key in the Info dictionary in the Torrent file
- tr: tracker server address
That is, the values corresponding to the announce and announce list keys in the Torrent file
- Pitch: seed hash value
That is, the SHA1 hash value (Hex) of the dictionary corresponding to info in the Torrent file According to the figure below, it is 4:infod. If the address of d is used as the starting index of the hash original text, it is Adress:00 01A3
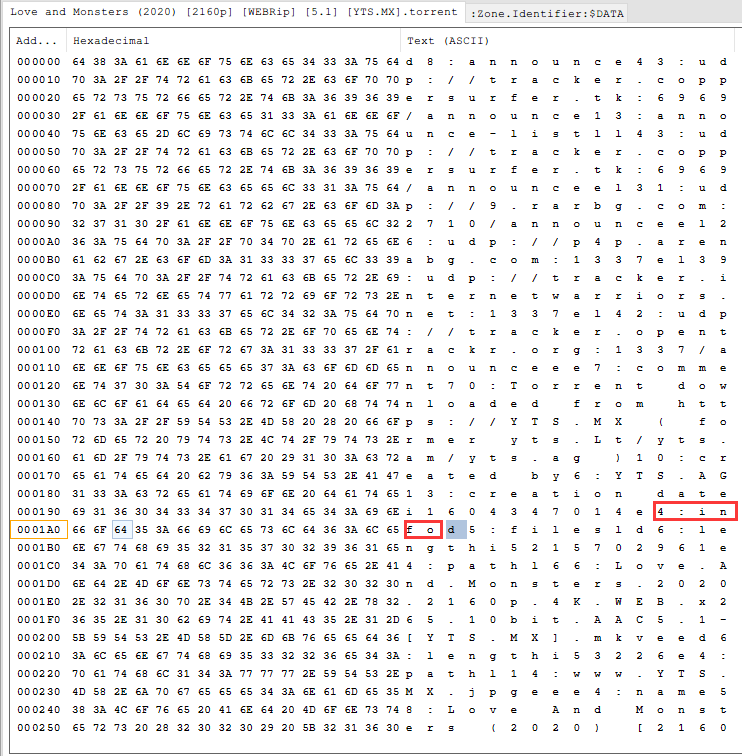
At the end of the whole info, if the address of e is used as the ending index address of the hash original text, it will be Adress:03 0BE7

As can be seen from the above:
magnet = 'magnet:?xt=urn:btih:'+Hex(Sha1(info))+'&dn='+encode(name)+'&tr='+encode(announce)
Combined with the implementation of the previous part, we can record startindex and endindex when reading info, that is:
Dictionary readDictionary(byte[] info,int offset){
//...
case 'd':
bool record = key == 'info';
if(record){
startindex = offset;
}
readDictoinary(info,offset);
if(record){
endindex = offset
}
}
string getBith(byte[] info,int start,int end){
// Get the byte array from start to end in info and summarize it
byte[] infoByte = new byte[infoEnd - infoStart + 1];
System.arraycopy(torrentBytes, infoStart, infoByte, 0, infoEnd - infoStart + 1);
return Hex.toHex(Sha1.toSha1(infoByte));
}Concrete implementation
I have realized some of the above logic through Java (Torrent file parsing and Magnet link generation). If you need reference, you can get relevant content at the following website:
Tool Catalog: https://github.com/Rekent/common-utils/tree/master/src/main/java/com/rekent/tools/utils/torrent
Source code of parsing class: https://github.com/Rekent/common-utils/blob/master/src/main/java/com/rekent/tools/utils/torrent/TorrentFileResovler.java
Dependent jar package: https://github.com/Rekent/common-utils/releases/tag/v0.0.3
Calling method:
public void testResolve() throws Exception {
String path = "C:\\Users\\Refkent\\Downloads\\Test.torrent";
TorrentFile torrentFile = TorrentFileUtils.resolve(path);
System.out.println(torrentFile.print());
System.out.println(torrentFile.getHash());
System.out.println(torrentFile.getMagnetUri());
}