Part of speech prediction by Python note42 LSTM
Summary of all notes: Pytoch note Happy Planet
Model introduction
For a word, there will be different parts of speech. First, we can make a preliminary judgment according to the suffix of a word. For example, the suffix - ly is very likely to be an adverb. In addition, a same word can represent two different parts of speech. For example, book can represent both nouns and verbs, Therefore, what part of speech this word is needs to be judged in combination with the context.
According to this problem, we can use the lstm model to predict. First, a word can be regarded as a sequence. For example, apple is composed of five words a p l e, which forms a sequence of five. We can build word embedding for these characters, and then input lstm, just like lstm for image classification, Taking only the last output as the prediction result, the whole word string can form a memory feature to help us better predict the part of speech.
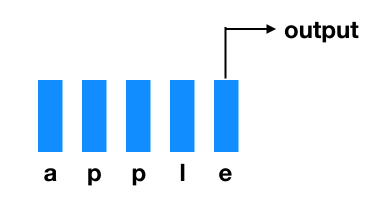
Then we form a sequence of this word and its previous words, which can be embedded into new words. Finally, the output result is the part of speech of the word, that is, the part of speech of the word is classified according to the information of the previous words.
Let's use an example to illustrate
Let's use the following simple training set
training_data = [("The dog ate the apple".split(),
["DET", "NN", "V", "DET", "NN"]),
("Everybody read that book".split(),
["NN", "V", "DET", "NN"])]
code
Next, we need to encode words and tags
word_to_idx = {}
tag_to_idx = {}
for context, tag in training_data:
for word in context:
if word.lower() not in word_to_idx:
word_to_idx[word.lower()] = len(word_to_idx)
for label in tag:
if label.lower() not in tag_to_idx:
tag_to_idx[label.lower()] = len(tag_to_idx)
word_to_idx
{'the': 0,
'dog': 1,
'ate': 2,
'apple': 3,
'everybody': 4,
'read': 5,
'that': 6,
'book': 7}
tag_to_idx
{'det': 0, 'nn': 1, 'v': 2}
Then we code the letters
alphabet = 'abcdefghijklmnopqrstuvwxyz'
char_to_idx = {}
for i in range(len(alphabet)):
char_to_idx[alphabet[i]] = i
Then we can build training data
def make_sequence(x, dic): # Character encoding
idx = [dic[i.lower()] for i in x]
idx = torch.LongTensor(idx)
return idx
make_sequence('apple', char_to_idx)
tensor([ 0, 15, 15, 11, 4])
training_data[1][0]
['Everybody', 'read', 'that', 'book']
make_sequence(training_data[1][0], word_to_idx)
tensor([4, 5, 6, 7])
Building a single character lstm model
class char_lstm(nn.Module):
def __init__(self, n_char, char_dim, char_hidden):
super(char_lstm, self).__init__()
self.char_embed = nn.Embedding(n_char, char_dim)
self.lstm = nn.LSTM(char_dim, char_hidden)
def forward(self, x):
x = self.char_embed(x)
out, _ = self.lstm(x)
return out[-1] # (batch, hidden)
Constructing lstm model of part of speech classification
class lstm_tagger(nn.Module):
def __init__(self, n_word, n_char, char_dim, word_dim,
char_hidden, word_hidden, n_tag):
super(lstm_tagger, self).__init__()
self.word_embed = nn.Embedding(n_word, word_dim)
self.char_lstm = char_lstm(n_char, char_dim, char_hidden)
self.word_lstm = nn.LSTM(word_dim + char_hidden, word_hidden)
self.classify = nn.Linear(word_hidden, n_tag)
def forward(self, x, word):
char = []
for w in word: # Make the lstm of characters for each word
char_list = make_sequence(w, char_to_idx)
char_list = char_list.unsqueeze(1) # (seq, batch, feature) meets lstm input conditions
char_infor = self.char_lstm(Variable(char_list)) # (batch, char_hidden)
char.append(char_infor)
char = torch.stack(char, dim=0) # (seq, batch, feature)
x = self.word_embed(x) # (batch, seq, word_dim)
x = x.permute(1, 0, 2) # Change order
x = torch.cat((x, char), dim=2) # The word embedding of each word and the result of character lstm output are spliced together along the feature channel
x, _ = self.word_lstm(x)
s, b, h = x.shape
x = x.view(-1, h) # Reclassify linear layer with reshape
out = self.classify(x)
return out
Start training
net = lstm_tagger(len(word_to_idx), len(char_to_idx), 10, 100, 50, 128, len(tag_to_idx)) criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(net.parameters(), lr=1e-2)
# Start training
for e in range(300):
train_loss = 0
for word, tag in training_data:
word_list = make_sequence(word, word_to_idx).unsqueeze(0) # Add first dimension batch
tag = make_sequence(tag, tag_to_idx)
word_list = Variable(word_list)
tag = Variable(tag)
# Forward propagation
out = net(word_list, word)
loss = criterion(out, tag)
train_loss += loss.data
# Back propagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (e + 1) % 50 == 0:
print('Epoch: {}, Loss: {:.5f}'.format(e + 1, train_loss / len(training_data)))
forecast
Finally, we can look at the predicted results
net = net.eval() test_sent = 'Everybody ate the apple' test = make_sequence(test_sent.split(), word_to_idx).unsqueeze(0) out = net(Variable(test), test_sent.split()) print(out)
tensor([[-0.9812, 1.6600, -0.8180],
[-0.8561, -0.5893, 1.5312],
[ 1.7873, -0.6825, -0.6958],
[-0.3254, 1.7655, -1.3631]], grad_fn=<AddmmBackward>)
print(tag_to_idx)
{'det': 0, 'nn': 1, 'v': 2}
Finally, we can get the above results. Because the linear layer of the last layer does not use softmax, the value is not very like a probability, but the largest value in each line indicates that it belongs to this category. You can see that the first word 'everyone' belongs to nn, the second word 'ate' belongs to v, the third word 'the' belongs to det, and the fourth word 'apple' belongs to nn, So the prediction result is correct