1. Why divide tables?
The database data becomes larger and larger, with too much data in a single table.This results in slower queries and database performance bottlenecks due to the lock mechanism of tables, which can seriously affect application operations.
One mechanism in mysql is table and row locking to ensure data integrity.A table lock means you can't operate on this table until I'm done with it.Row locks are the same, and other SQLs must wait until I have finished manipulating this data before they can manipulate it.When this happens, we can consider subtables or partitions.
2. MySQL Subtable
Subtables divide a large table into several entity tables with independent storage space according to certain rules, each table corresponds to three files, MYD data file,.MYI index file,.frm table structure file.These tables can be distributed on the same disk or on different machines.The app reads and writes with the corresponding table name based on a predefined rule, and then operates on it.
By splitting a single database table into multiple tables, users can access different tables according to certain algorithms (such as hash or redundancy) when accessing them. This allows data to be dispersed across multiple tables and reduces the pressure of accessing a single data table.Improved database access performance.The purpose of table breaking is to reduce the burden on the database and the query time.
The Mysql sub-table is divided into vertical and horizontal slices, with the following specific differences:
Vertical splitting refers to the splitting of columns in a data table, splitting a table with more columns into multiple tables. Usually, we split a table vertically according to the following principles: putting uncommon fields in a single table; splitting large fields such as text, blob (binary large object) into appended tables;
Columns of frequently combined queries are placed in a table; more vertical splits should be performed at the beginning of the table design, then join s can be used to key queries.
Horizontal splitting refers to the splitting of rows in a data table and the splitting of data from one table into multiple tables for storage.Horizontal splitting principle. Usually, we use hash, modelling and other methods to split tables, such as a 400 W user table. To improve its query efficiency, we divide it into four tables, users1, users2, users3, users4, which use ID modelling to disperse data into four tables, Id%4= [0,1,2,3], and then query and update.Deletion is also a modelling method to query part of business logic. It can also be archived and split by region, year and other fields. After the table is split, we need to restrict user query behavior.For example, when we split by year, page design constrains users to select a year before they can query.
3. Using merge Storage Engine to Implement Subtables
Note: Only the original tables of the myisam engine can be subtabled using the merge storage engine.
merge sub-tables are divided into main and sub-tables. The main table is like a shell and logically encapsulates the sub-tables. In fact, the data is stored in the sub-tables.We can insert and query data through the main table, or directly operate on the sub-tables if the rules of table breaking are clear.
Example:
1) Create a complete table
mysql> create database test1;
mysql> use test1;
mysql> create table member
-> (
-> id bigint auto_increment primary key,
-> name varchar(20),
-> sex tinyint not null default '0'
-> )engine=myisam default charset=utf8 auto_increment=1;
#insert data
mysql> insert into member(name,sex) values('tom1',1);
mysql> insert into member(name,sex) select name,sex from member; # Insertion statements can be executed several times to insert large amounts of data
mysql> select count(*) from member; # Base hand, I inserted 16,384 pieces of data here
+----------+
| count(*) |
+----------+
| 16384 |
+----------+
1 row in set (0.00 sec)2) Subtable the complete table above
Notes for table breakdown:
- Field definitions of subtables and primary tables need to be consistent, including data type, data length, and so on.
- When the sub-table is finished, all operations (addition, deletion, and alteration) need to be performed on the main table, although the main table does not store the actual data.
#To create two sub-tables, the table structure must be consistent with the complete table structure above
mysql> create table tb_member1 like member;
mysql> create table tb_member2 like member;
#Create a merge engine table as the main table and associate the two tables above
mysql> create table tb_member
-> (
-> id bigint auto_increment primary key,
-> name varchar(20),
-> sex tinyint not null default '0'
-> )engine=merge union=(tb_member1,tb_member2) insert_method=last charset=utf8;Note: When the main table was created above, the specified "insert_method=last"has three optional parameters: last: to insert into the last table; first: to insert into the first table; and NO: to indicate that the table cannot do any write operations and is used only as a query.
3) Look at the three table structures you just created as follows: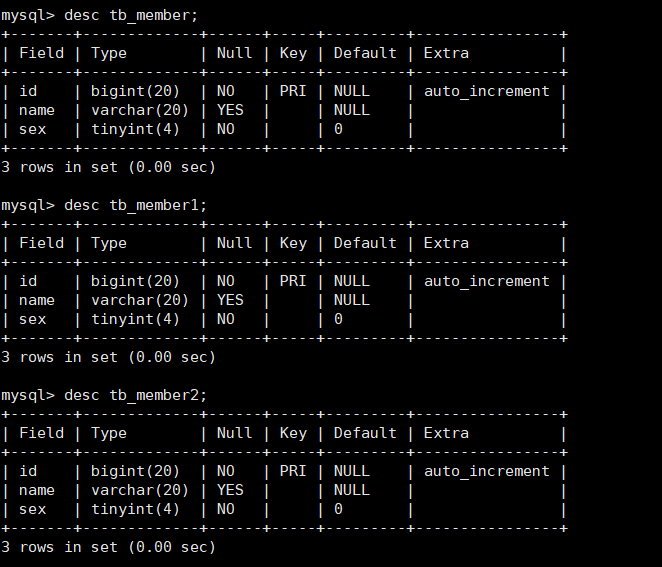
4) Divide the data into two tables:
mysql> insert into tb_member1(id,name,sex) select id,name,sex from member where id%2=0; Query OK, 8192 rows affected (0.01 sec) Records: 8192 Duplicates: 0 Warnings: 0 mysql> insert into tb_member2(id,name,sex) select id,name,sex from member where id%2=1; Query OK, 8192 rows affected (0.02 sec) Records: 8192 Duplicates: 0 Warnings: 0
5) View data in the main table and two subtables
The first sub-table contains some data as follows: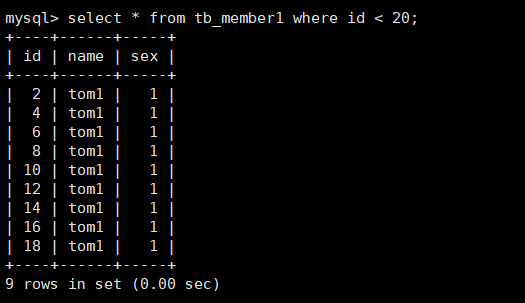
The second sub-table contains some data as follows: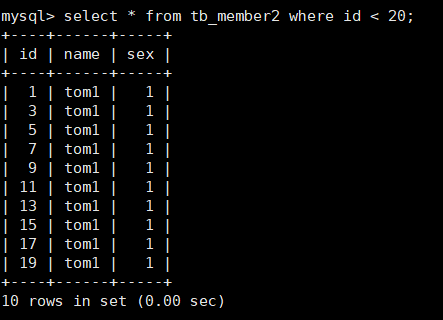
Part of the data queried in the main table is as follows: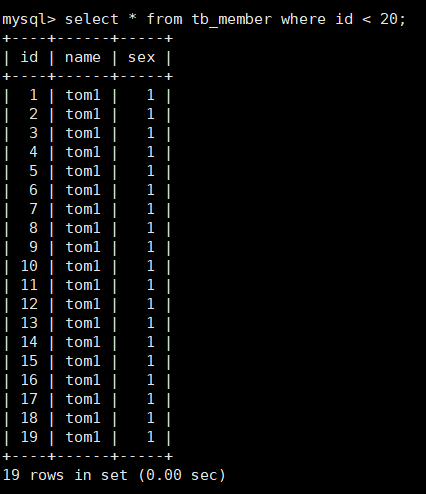
The total number of rows of data is as follows: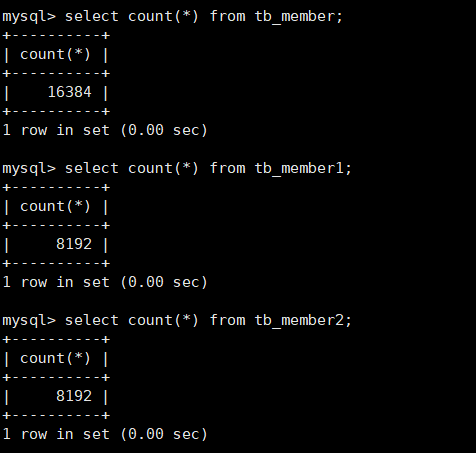
Note: The master table is just a shell, accessing data occurs in one subtable.Each sub-table has its own independent related table file, while the main table is only a shell, and there is no complete related table file. When it is determined that the data that can be found in the main table and the data that can be found before the sub-table are identical, the original table can be deleted, and then the table can be read and written, so the main table after the table can be processed.
The local files corresponding to the three tables above are as follows: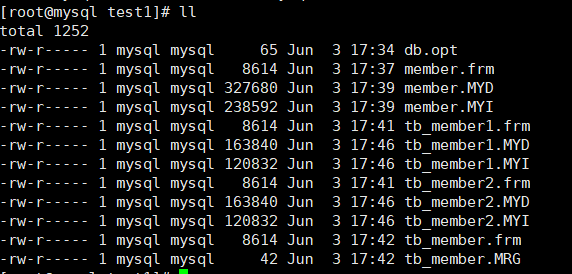
You can see that the local data files that can query the main table of all the data are very small, which also verifies that the data does not exist in the main table.
6) Insert data into the main table as follows:
mysql> insert into tb_member values(16385,'tom2',0),(16386,'tom3',1);
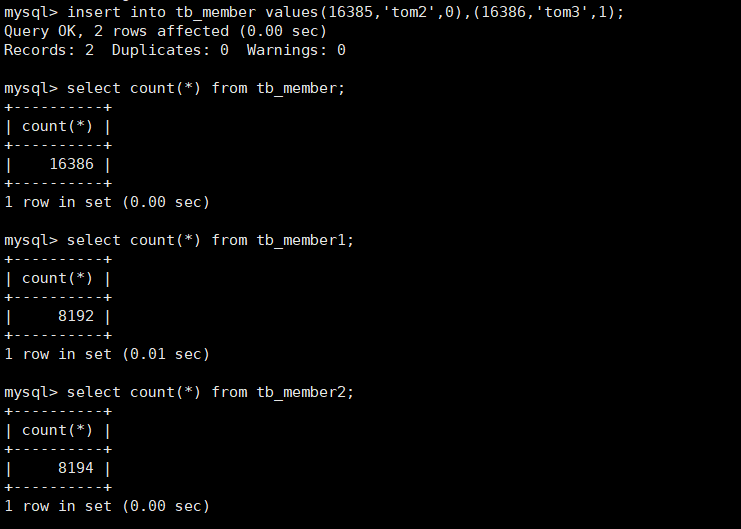
As you can see, both of the new data are inserted into the second table, because when you create the main table, you specify "insert_"Method" is last, that is, all insertions are made to the last table. You can modify the insertion method with the alter command as follows:
mysql> alter table tb_member INSERT_METHOD=first;
After modifying the insertion method and inserting data into the table on your own, you can see that all the data is written to the first table (I inserted four pieces of data here). See below:
mysql> insert into tb_member values(16387,'tom4',2),(16388,'tom5',3),(16389,'tom6',4),(16390,'tom7',5);
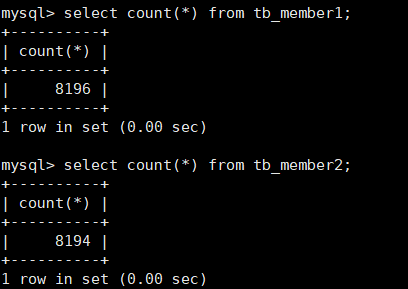
Four new pieces of data have been added above, and you can see that they have all been inserted into the first table.
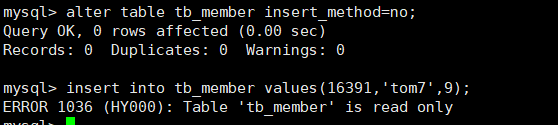
Modifying the insertion method to no means that the table cannot insert any more data, as follows:
mysql> alter table tb_member insert_method=no; mysql> insert into tb_member values(16391,'tom7',9);
4. MySQL partition
1) What are partitions?
Partitions are similar to tables in that they decompose tables according to rules.The difference is that a subtable breaks a large table into separate entity tables, while a partition divides the data into segments that are stored in multiple locations. After partitioning, the table is still a table, but the data is scattered across multiple locations.Apps read and write with the name of the table, and db automatically organizes the partitioned data.
There are two main forms of partitioning:
Horizontal partitioning: This form of partitioning partitions the rows of a table so that all columns defined in the table are found in each dataset, so the characteristics of the table are maintained.
A simple example is that a table containing ten-year invoice records can be partitioned into ten different partitions, each of which contains records for one year.
Vertical partitioning: This partitioning generally reduces the width of the target table by vertically partitioning the table so that certain columns are partitioned into specific partitions, each of which contains the rows for the columns.
A simple example is a table with large text and BLOB columns that are not frequently accessed. Divide these infrequently used texts and BLOBs into a different partition to ensure their data relevance while increasing access speed.
2) Check if the current database supports partitioning
Prior to MySQL 5.6, use the following parameters to see if the current configuration supports partitioning (yes means partitioning):
mysql> SHOW VARIABLES LIKE '%partition%'; +-----------------------+---------------+ |Variable_name | Value | +-----------------------+---------------+ | have_partition_engine | YES | +-----------------------+------------------+
View at 5.6 and beyond in the following ways:
mysql> show plugins;
The following fields are returned (supporting partitions if status is listed as ACTIVE):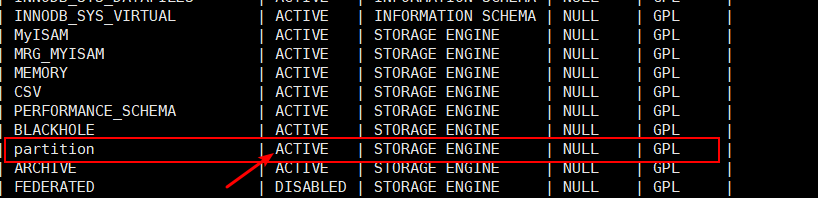
3) Table partitioning by range
mysql> create table user
-> (
-> id int not null auto_increment,
-> name varchar(30) not null default '',
-> sex int(1) not null default '0',
-> primary key(id)
-> )default charset=utf8 auto_increment=1
-> partition by range(id)
-> (
-> partition p0 values less than (3),
-> partition p1 values less than (6),
-> partition p2 values less than (9),
-> partition p3 values less than (12),
-> partition p4 values less than maxvalue
-> );Note: In the table created above, when the value of the id column is less than 3, records with a value greater than 3 and less than 6 are inserted into the p1 partition, and so on, all records with an id value greater than 12 are inserted into the p4 partition.
4) Insert some data using stored procedures
mysql> delimiter //
mysql> create procedure adduser()
-> begin
-> declare n int;
-> declare summary int;
-> set n = 0;
-> while n <= 20
-> do
-> insert into test1.user(name,sex) values("tom",0);
-> set n=n+1;
-> end while;
-> end //
Query OK, 0 rows affected (0.01 sec)
mysql> delimiter ;
mysql> delimiter ;
mysql> call adduser();
Query OK, 1 row affected (0.01 sec)
mysql> select * from user;
+----+------+-----+
| id | name | sex |
+----+------+-----+
| 1 | tom | 0 |
| 2 | tom | 0 |
| 3 | tom | 0 |
| 4 | tom | 0 |
| 5 | tom | 0 |
| 6 | tom | 0 |
| 7 | tom | 0 |5) Go to the directory where the data table files are stored and have a look: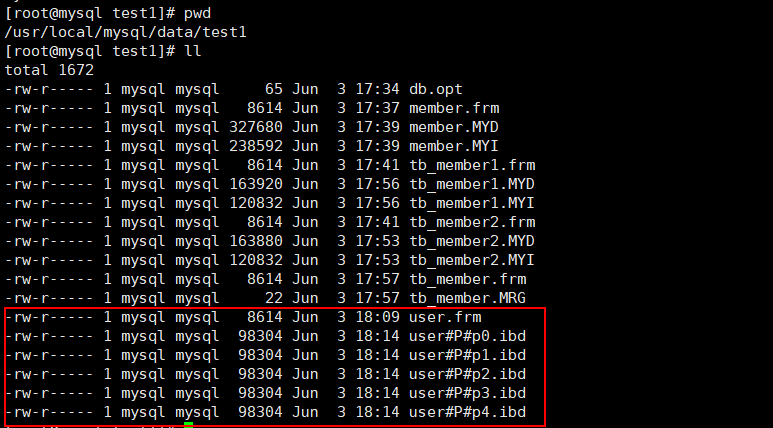
You can see that the data is scattered into different files, and the local file names are named "user#P#p0...", where P0 is the custom partition name.
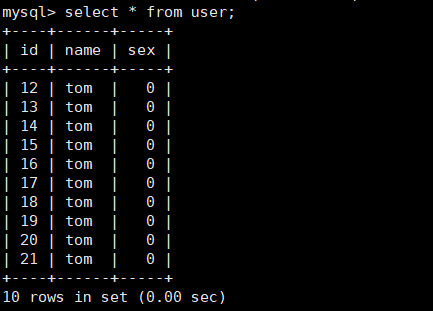
6) Number of rows of Statistics
mysql> select count(*) from user; +----------+ | count(*) | +----------+ | 21 | +----------+ 1 row in set (0.00 sec)
7) From information_Viewing partition information in the partition table in the schema system library
mysql> select * from information_schema.partitions where table_schema='test1' and table_name='user'\G
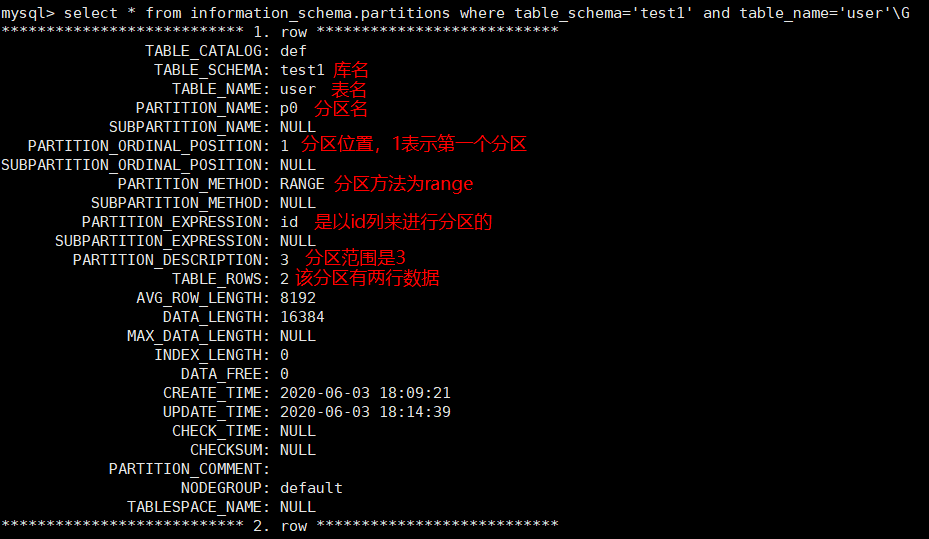
8) Query data from partitions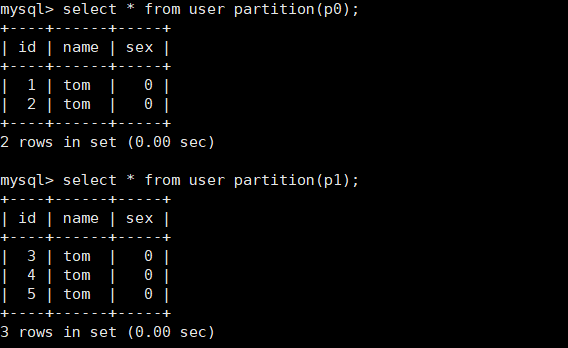
9) Add and merge partitions (need to merge partitions before adding new partitions)
1. Add partitions:
Note: Since the last partition range specified at the time of table creation is maxvalue, it is not possible to add partitions directly, as follows:
mysql> alter table user add partition (partition p5 values less than (20)); ERROR 1481 (HY000): MAXVALUE can only be used in last partition definition
To the effect that MAXVALUE can only be used in the last partition definition
However, it is not possible to delete the partition that finally defines the maxvalue directly, because data in the partition will also be lost if the partition is deleted, so the correct way to add a new partition is to merge the partition first and then add the partition, so that data integrity can be guaranteed as follows:
mysql> alter table user reorganize partition p4 into (partition p03 values less than (15),partition p04 values less than maxvalue );
The purpose of the above command is to divide the last partition into two partitions, one that you need, the last partition or maxvalue (which must also be maxvalue), so that you are done adding partitions.
The local table files are as follows: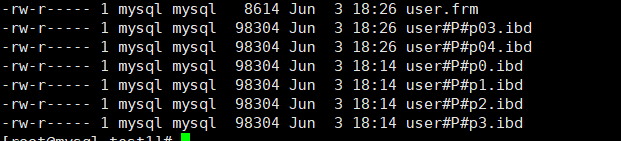
Query the data in the new partition as follows: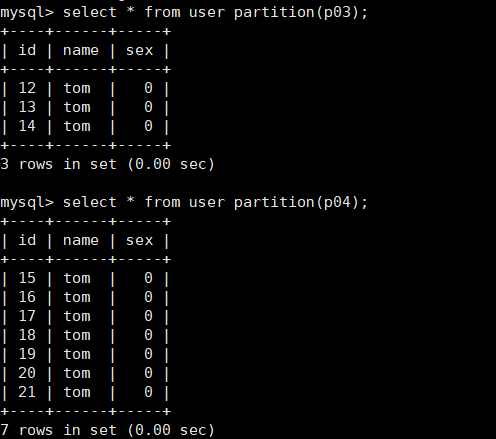
2. Merge partitions
Merge p0, p1, p2, p3 partitions into p02:
mysql> alter table user reorganize partition p0,p1,p2,p3 into
-> (partition p02 values less than (12));You can see that p02 integrates data from p0,p1,p2,p3 partitions as follows: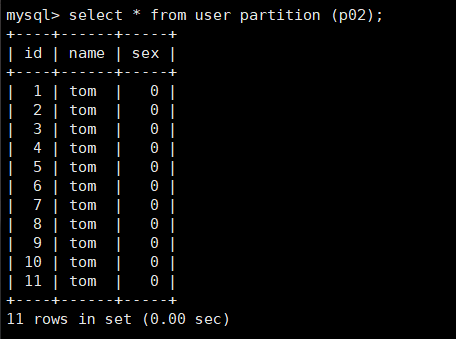
The local files are as follows:
10) Delete partition
mysql> alter table user drop partition p02;
Note: When the partition is deleted, the data in the partition will also be deleted. Delete all data in the partition p02 table as follows: