Penetration test idea
Another: Shadow
(mainly record some small processes and experiences of daily penetration)
Tools
preface
If a worker wants to do well, he must sharpen his tools first
A good tool can save a lot of time, so a tool set can quickly complete penetration testing
Real IP
Nslookup
Own tools
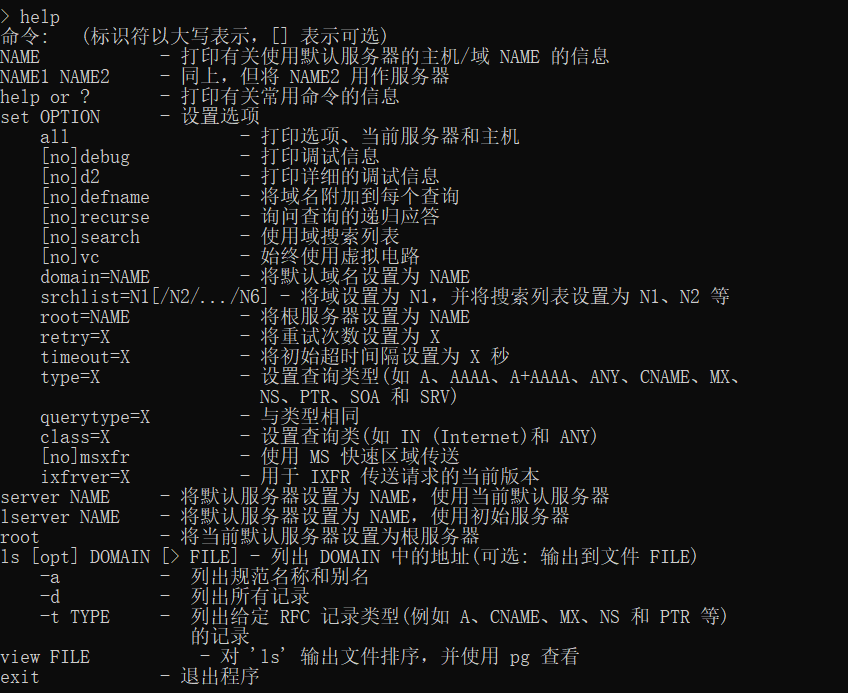
When nslookup obtains more than one IP, you can judge whether it is a CDN, mostly a false IP
Parse record
The real IP address of the website may exist in the historical resolution record
Online tools http://toolbar.netcraft.com/ http://viewdns.info/
mailbox
By subscribing to the website and subscribing to e-mail, the website can send e-mail to itself, and obtain the real IP address of the website by viewing the e-mail source code
Information disclosure
Some websites have website information, and the test page has not been deleted
For example: phpinfo php
Don't think it won't exist phpinfo This kind of document, so and so po It seems to exist on the main station phpinfo File, I saw it in the big crowd one day and ate melon once. It's really fragrant!
To get the real IP address of the website
Information disclosure on Github, etc
Cyberspace
Online tools: https://www.shodan.io/ https://fofa.so/
Ping
When using CDN in many places, enterprises may only conduct CDN for domestic ones. They can try global Ping
Recommended online tools: Webmaster Tools
Subdomain explosion
Layer subdomain excavator 4.2 Commemorative Edition
People who have used this tool should know that it is powerful, fast blasting speed, high accuracy and rich in built-in dictionaries

subDomainsBrute
Github: https://github.com/lijiejie/subDomainsBrute/
Fast scanning speed, multithreading and high concurrency,
The author has a small bug when using the domain name. When using pan resolution, there will be problems with the blasting of the domain name, which may be a problem in the local environment. Finally, the blasting structure needs to be manually obtained and filtered
A small script of title was written at that time
There is a BUG that doesn't automatically identify https or http. The boss can add this function and let the little shadow have a look. Hey, hey, hey
#coding:utf-8
import requests
import os
import sys
import getopt
import re
reload(sys)
sys.setdefaultencoding('GBK')
def title(url):
file = open(url)
headers = {
'Host': 'www.starsnowsec.com',
'Connection': 'close',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie': '',
}
try:
for line in file:
line = line.strip('\n')
url = 'https://' + line
r = requests.get(url,headers=headers)
if r.status_code == 200:
title = re.findall('<title>(.+)</title>',r.text)
result = '[*]URL:' + str(url) + ' +title:' + str(title[0])
f = open('result.txt','a+')
f.write(result+'\n')
f.close()
print result
pass # do something
# with open(url, "r") as f: #Open file
# data = f.read() #read file
# print data
# print "1"
else:
print "-" * 40
print r.text
pass
except:
print "error!"
pass
def main():
# Read the command line option. If it is not available, the usage is displayed
try:
# opts: a list in which each element is a key value pair
# args: actually sys argv[1:]
# sys.argv[1:]: only the second and subsequent parameters are processed
# "ts:h": abbreviation of option. Colon indicates that it must be followed by the value of this option (such as - s hello)
# ["help", "test1", "say]: of course, you can write it in detail, but you need two horizontal bars (- -)
opts, args = getopt.getopt(sys.argv[1:], "u:h",["url", "help"])
# print opts
# Specific processing command line parameters
for o,v in opts:
if o in ("-h","--help"):
usage()
elif o in ("-u", "--url"):
title(v)
# Tested -- it can't take subsequent value
#
except getopt.GetoptError as err:
# print str(err)
print 'Error!'
main()
R3con1z3r
# install pip install r3con1z3r # use r3con1z3r -d domain.com
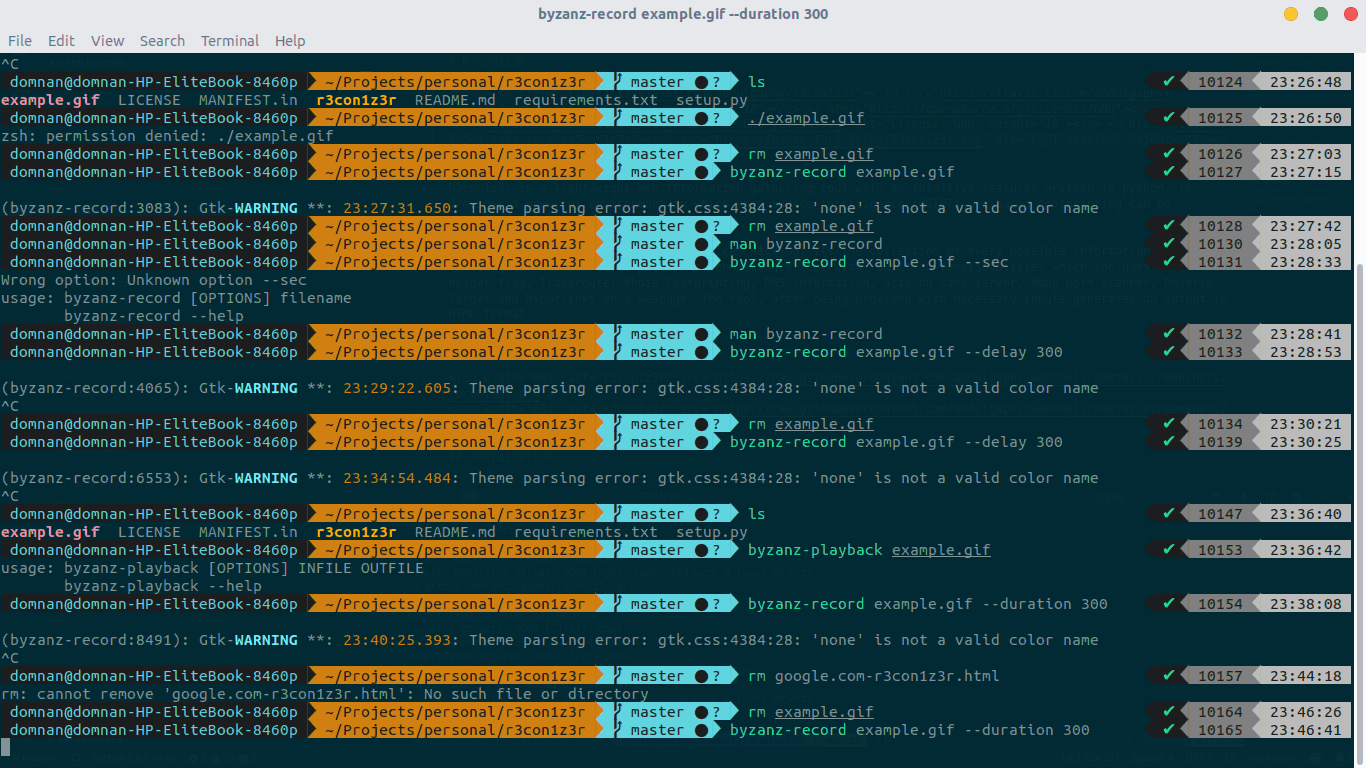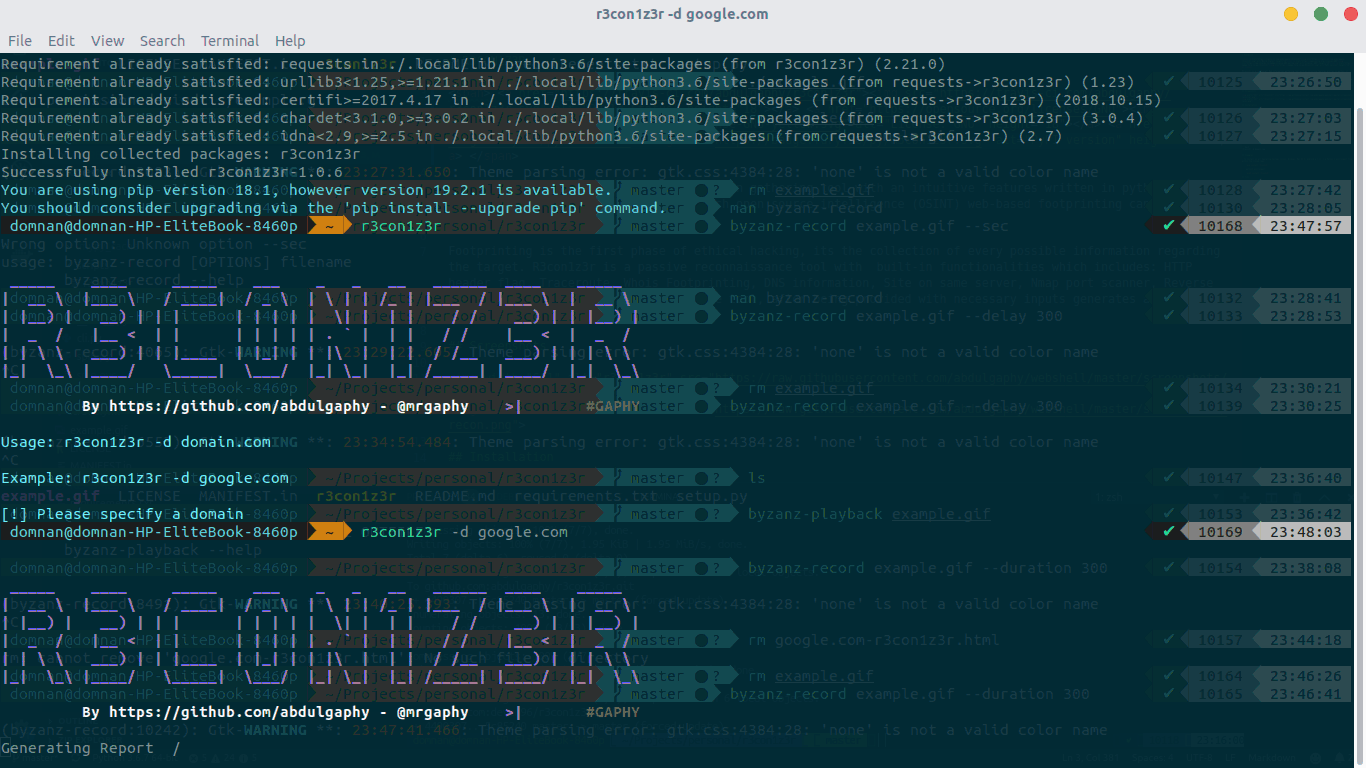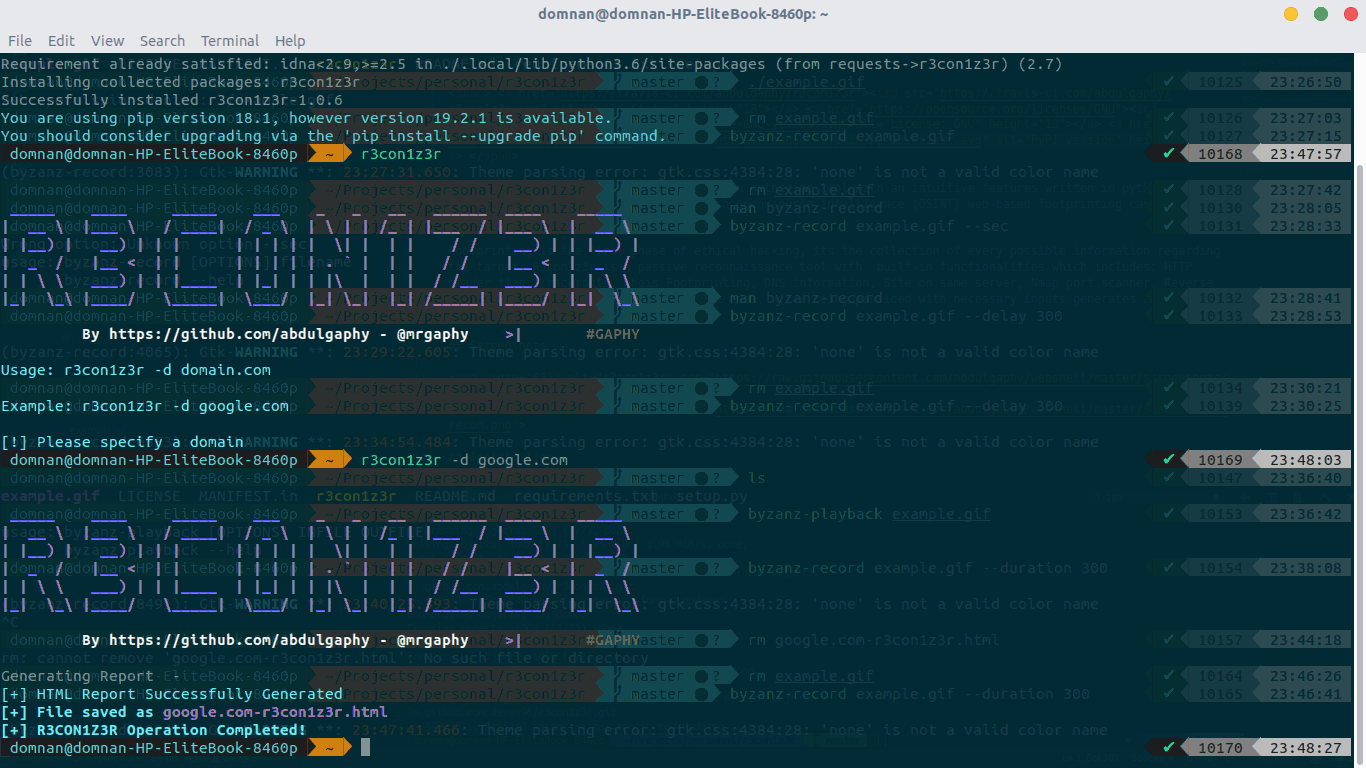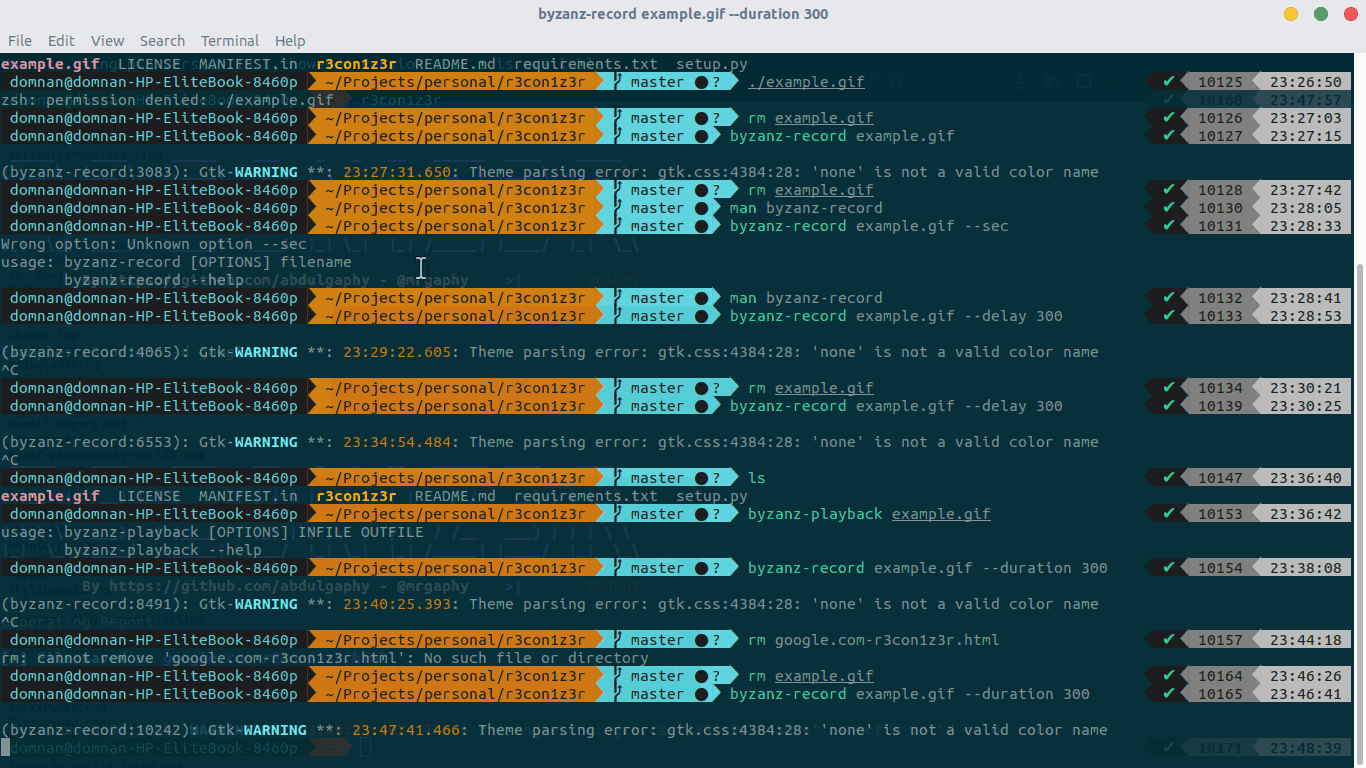 Use results
Use results



r3con1z3r will collect HTTP Header, Route, Whois, DNS, IP, port and internal chain crawls
Advantages: simple to use, simple interface and high accuracy
Disadvantages: when I use it, the speed is too slow, and I have to hang an agent
OneForAll
Github git clone https://github.com/shmilylty/OneForAll.git Gitee git clone https://gitee.com/shmilylty/OneForAll.git
👍 Functional characteristics
- Powerful collection ability. Please read the detailed module Collection module description.
- Use certificate transparency to collect sub domains (currently there are 6 modules: censys_api, certpotter, crtsh, trust, google, spyse_api)
- Routine check and collection of sub domains (currently there are four modules: domain transfer vulnerability utilization axfr, cross domain policy file cdx, HTTPS certificate cert, content security policy csp, robots file robots, sitemap file sitemap, use NSEC records to traverse DNS domain dnssec, and then add NSEC3 records and other modules)
- Use web crawler files to collect subdomains (there are currently two modules: archivecrawl and commoncrawl. This module is still under debugging and needs to be added and improved)
- Use DNS data set to collect subdomains (currently there are 24 modules: binary edge_api, buffer over, cebaidu, Chinaz, chinaz_api, circle_api, cloudflare, dnsdb_api, dnsdumpster, hackertarget, ip138, IPv4 info_api, NetCraft, passive dns_api, ptrarchive, Qianxun, rapiddns, Riddler, robtex, securitytails_api, sitedossier, threatrow, wzpc, ximcx)
- Use DNS query to collect subdomains (currently there are 5 modules: collect subdomains SRV by enumerating common SRV records and making queries, and collect subdomains by querying MX, NS, SOA and TXT records in DNS records of domain names)
- Using threat intelligence platform data collection sub domain (currently there are 6 modules: alienvault, riskiq_api, threatbook_api, threatminer, VirusTotal, and virustotal_api, which need to be added and improved)
- Search engines are used to discover subdomains (currently there are 18 modules: ask, baidu, bing, bing_api, duckduckgo, exalead, fofa_api, gitee, github, github_api, google, google_api, shodan_api, so, sogou, yahoo, yandex, zoomeye_api). In the search module, except for special search engines, general search engines support automatic exclusion search, full search and recursive search.
- It supports sub domain blasting. This module has both conventional dictionary blasting and user-defined fuzz y mode. It supports batch blasting and recursive blasting, and automatically judges, analyzes and processes.
- Support sub domain verification. By default, sub domain verification is enabled, the sub domain DNS is automatically resolved, the sub domain is automatically requested to obtain the title and banner, and the survival of the sub domain is comprehensively judged.
- Sub domain takeover is supported. By default, sub domain takeover risk check is enabled, sub domain automatic takeover is supported (currently only Github, to be improved), and batch inspection is supported.
- The processing function is powerful. The discovered sub domain results support automatic removal, automatic DNS resolution, HTTP request detection, automatic screening of effective sub domains, and expansion of the sub domain's Banner information. The final supported export formats are rst, csv, tsv, json, yaml, html, xls, xlsx, dbf, latex, ods.
- Very fast, Collection module Using multithreaded calls, Blasting module use massdns , DNS resolution speed can resolve more than 350000 domain names per second. In sub domain verification, DNS resolution and HTTP requests use asynchronous multi process and multi-threaded inspection Subdomain takeover Risk.
- Good experience, each module has a progress bar, and the results of each module are saved asynchronously.
Online tools
https://phpinfo.me/domain / subdomain
Directory scan
Mitsurugi
Speaking of directory scanning, most people know Yujian and have used it. I don't say much. I recommend it
Tips: You can try to collect several different imperial swords, and the results of different imperial swords are also different(Under the same circumstances)
There are four kinds here

WebPathBrute
https://github.com/7kbstorm/7kbscan-WebPathBrute
WebPathBrute of 7kb boss
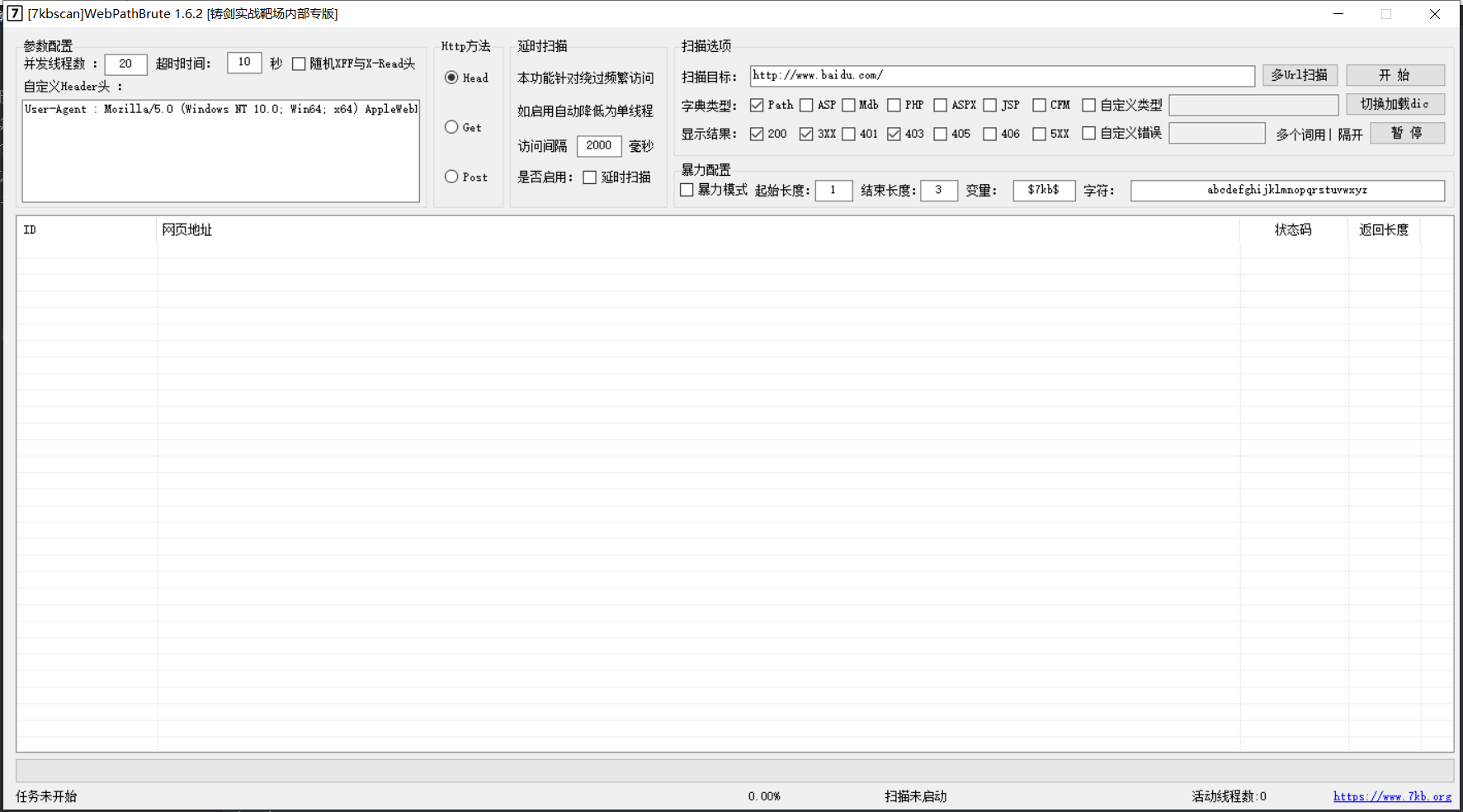
The interface is simple and powerful,
The following is the original introduction to the WebPathBrute tool in the hanging sword:
1, Let's talk about the number of concurrent threads first. Although the default is 20, it doesn't matter to increase it. It depends on your own parameter settings and machine network configuration. 2, The timeout depends on the situation, and there is no need to introduce it. 3, This random xff Head and xr It doesn't matter whether you know it or not. You rarely meet the situation you need to use. After checking, these two will be randomly generated for each visit IP If the thread is turned on, it may consume more energy cpu. 1,X-Forwarded-For It is used to record agent information. After each level of agent X-Forwarded-For It is used to record agent information. After each level of agent(Except Anonymous Proxy),The proxy server will send the source of this request IP Append in X-Forwarded-For From 4.4.4.4 A request from, header Include such a line X-Forwarded-For: 1.1.1.1, 2.2.2.2, 3.3.3.3 Representative request by 1.1.1.1 Layer 1, through layer 2.2.2.2,The second floor is 3.3.3.3,And the source of this request IP4.4.4.4 It's the third tier agent 2,X-Real-IP,Generally, only the real requesting clients are recorded IP,In the above example, if configured X-Read-IP,Will be X-Real-IP: 1.1.1.1 4, Custom User Agent You don't have to explain this. 5, The custom error page keyword is a common function for websites that have modified the error page, so I won't be wordy here. Vi http Access method HEAD GET POST Three ways, head Request scanning is the fastest, but the accuracy is not as good as the following two, post The request is bypassed for certain situations waf Used. 7, When the delay scanning function is checked, the effect is: Single threaded scanning, accessed every 2 seconds by default. Applicable to some existing CCwaf It is considered that the website is free from frequent access CC Attack. (by default, two seconds have passed the default of cloud lock and security dog CC Settings) 8, Scan types correspond to multiple in the same directory txt The file corresponding to the custom file is custom.txt,Suffix format is".xxx",If you do not need a suffix, you can directly modify the dictionary content to"111.svn"This type is OK. 9, I won't explain more about the status code 10, Double click a row in the table to call the system default browser to open the current row Url Right click to copy Url Content. Xi. Batch imported Url And filled in Url All need to http:// https: / /.
Dirsearch
Lightweight, powerful and fast
Using Python 3 X run
Install
git clone https://github.com/maurosoria/dirsearch.git cd dirsearch python3 dirsearch.py -u <URL> -e <EXTENSION>
Usage: dirsearch.py [-u|--url] target [-e|--extensions] extensions [options] More usage dirsearch.py -h, --help
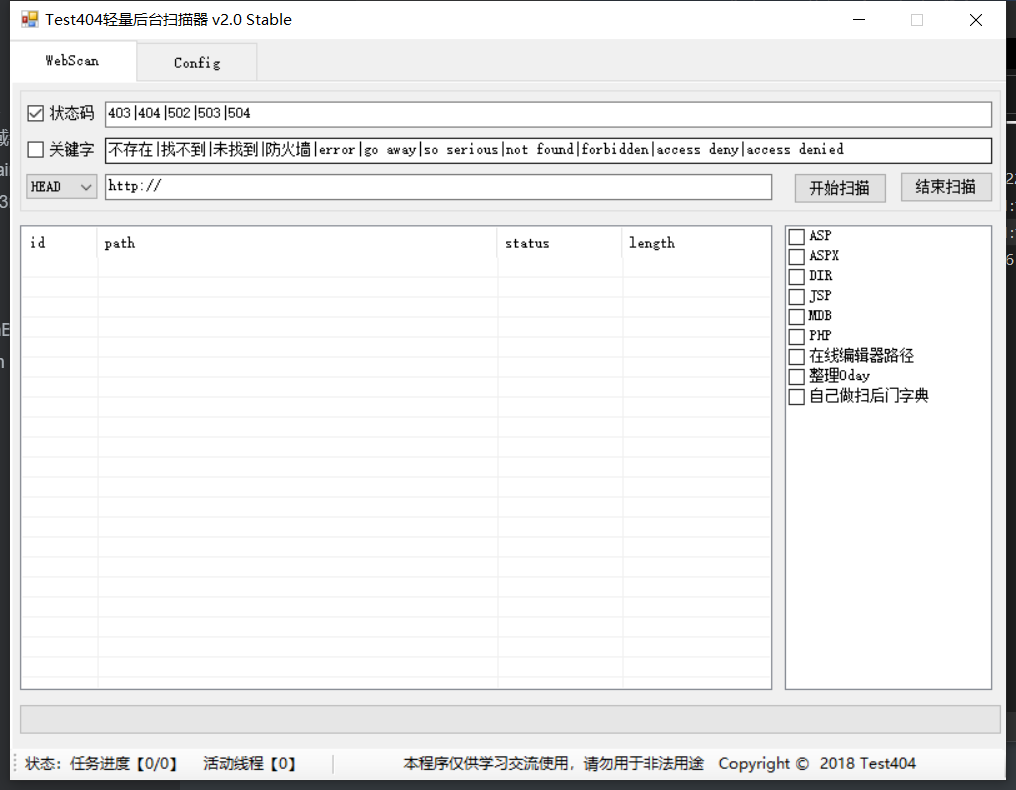
Test404
Lightweight and easy to use
Port scan
Nmap
Not much
Yujian high speed port scanning tool
Simple configuration, fast scanning and simple interface
Masscan
Very fast (depending on network and computer performance)
I should have heard of Masscan, so I won't say more
Comprehensive scanning
Goby
The interface is the best UI I've ever used
This interface, love, love~~
Xray
I don't need to say more about this. Hang up the agent, click where and dig there
It smells good after using it
WVS
The report is concise and powerful
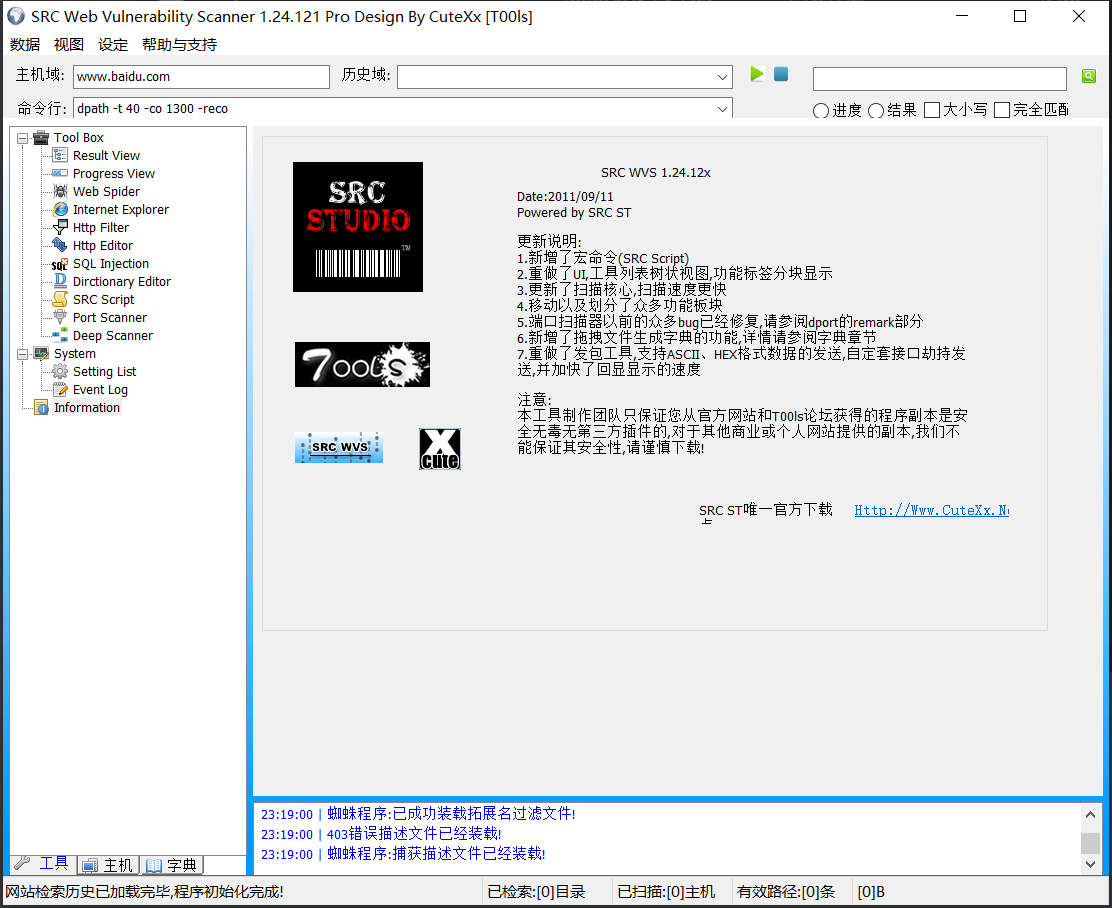
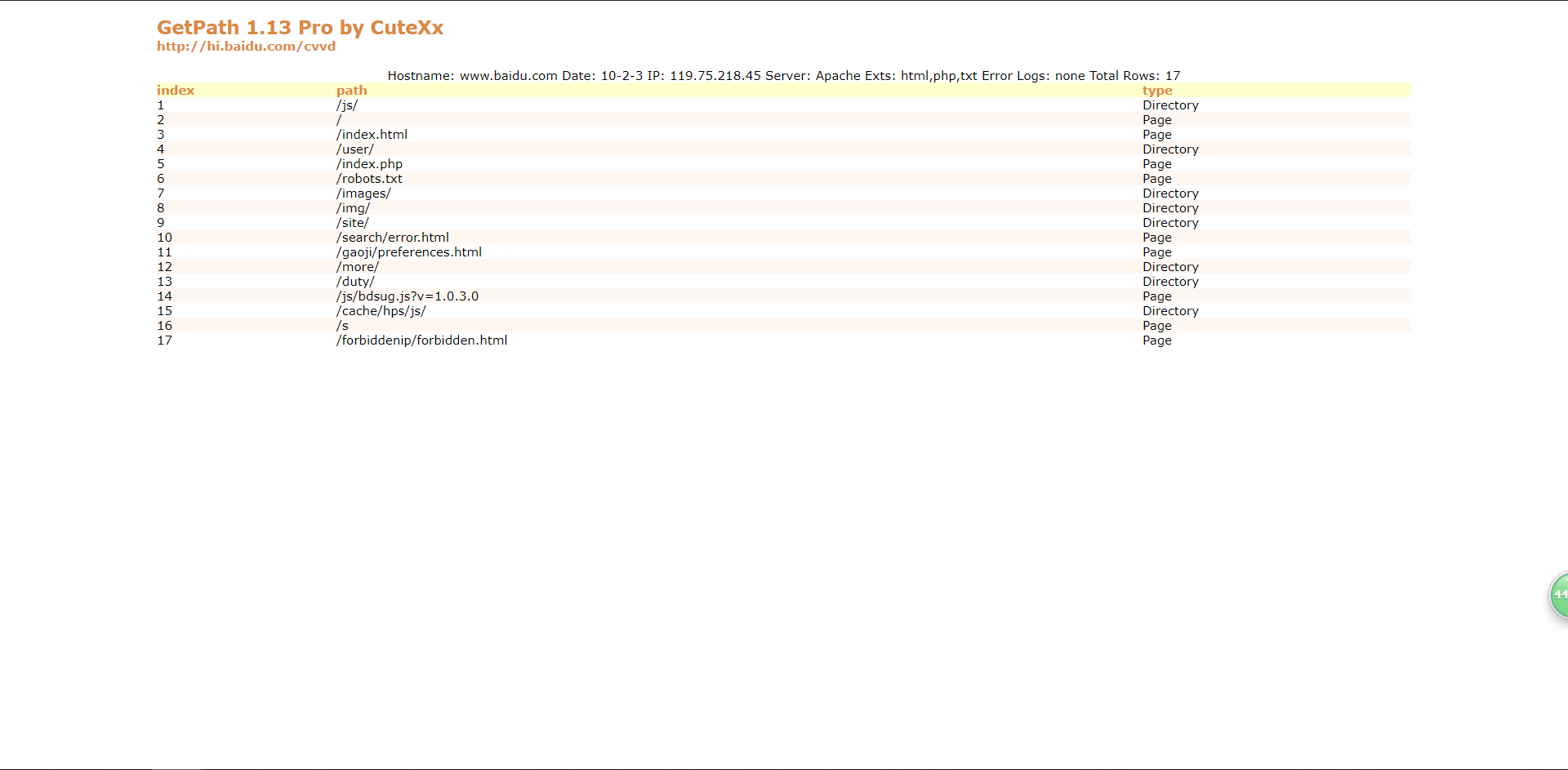
The report generated is as follows
Nessus
At present, the most widely used system vulnerability scanning and analysis software in the world
Needless to say
AWVS
Needless to say
Authority management
AntSword
There is also a downloadable plug-in market
Ice scorpion
Scorpio
I haven't used it yet, but it's recommended in the hanging sword. It should be good!
SQL injection
At the beginning, the tools used by the author were streamer, bright boy, class D ~ ~ (script boy) ~ ~. Then at that time, they all brought back doors and made a mess of the computer. Just think about it and want to laugh, ha ha
When I was a child, I was rubbish ~ ~ (script boy). I thought it would be great when I grew up. I didn't expect that the more I grew up, the more useless I became (script boy). Woo woo woo~
Sqlmap
Needless to say, it has powerful functions. The author likes a shuttle best
Remote control
NC
nc is called Swiss Army knife, and its strength goes without saying
CobaltStrike
Needless to say, this kind of thing is a post CS penetration plug-in
Github: https://github.com/DeEpinGh0st/Erebus
Packet capture and packet change
BurpSuite
There is no bp feeling about learning security. I can't say it. It's basically a cracked version. Ha ha ha
Fiddler
Like burpsuite, grab packets
I prefer to use BurpSuite. Fiddler has not used it too much
Wireshark
Needless to say, Wireshark, I would like to call you data analysis first
RawCap
A very lightweight tool

But I haven't used it several times
Big guys who pursue lightness can try it
Batch test
Baidu URL keyword URL extraction
# -*- coding: UTF-8 -*-
import requests
import re
from bs4 import BeautifulSoup as bs
def main():
for i in range(0,100,10):
expp=("/")
# print(i)
url='https://www.baidu.com/s?wd=inurl admin.php&pn=%s'%(str(i))
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0'}
r=requests.get(url=url,headers=headers)
soup=bs(r.content,'lxml')
urls=soup.find_all(name='a',attrs={'data-click':re.compile(('.')),'class':None})
for url in urls:
r_get_url=requests.get(url=url['href'],headers=headers,timeout=4)
if r_get_url.status_code==200:
url_para= r_get_url.url
url_index_tmp=url_para.split('/')
url_index=url_index_tmp[0]+'//'+url_index_tmp[2]
with open('cs.txt') as f:
if url_index not in f.read():#Here is a de duplication judgment to judge whether the URL is already in the text. If it does not exist, open txt and write our spliced exp link.
print(url_index)
f2=open("cs.txt",'a+')
f2.write(url_index+expp+'\n')
f2.close()
if __name__ == '__main__':
f2=open('cs.txt','w')
f2.close()
main()
If necessary, you can search on Github 'or write a small script yourself
(Tips: don't forget to de duplicate the results!)
Collection collection
Fofa acquisition
ZoomEye collection
There are tools on github, and the author doesn't have many bb
Browser plug-in
Hackbar
It goes without saying how easy it is to use
I prefer this version of Firefox + this hackbar
Wappalyzer
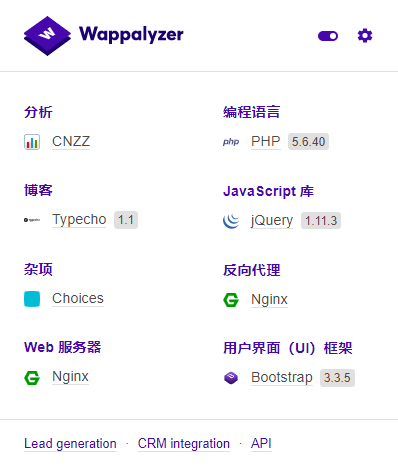
It clearly shows the front-end libraries, languages, frameworks, versions, etc
FoxyProxy
Agent tool
Right click to directly change the agent to facilitate Burpsuite to switch back and forth
Site Spider
The front-end small crawler is used to climb the inner chain and outer chain links
FireBug
Needless to say
an account of happenings after the event being told
I use Firefox in Pentest Box
www.pentestbox.com
The plug-ins carried inside are quite complete
If you are interested, you can try to download and play. There are two versions, one with metasploit and the other without. You can choose at will
The environment and tools inside have basically been downloaded, and there are also update functions
Download function, etc