Chiapos is a project on GitHub. If you want to know its specific content, you can know it by yourself. Address: https://github.com/Chia-Network/chiapos .
The current version number is e5830b182d155f8599426a7374306445cd7c0418, which is the latest version up to June 7, 2021.
We first open one of the files. We can see that this is a sorting module. Its main function is to read a certain length of data from the disk, and then sort it through the insertion method.
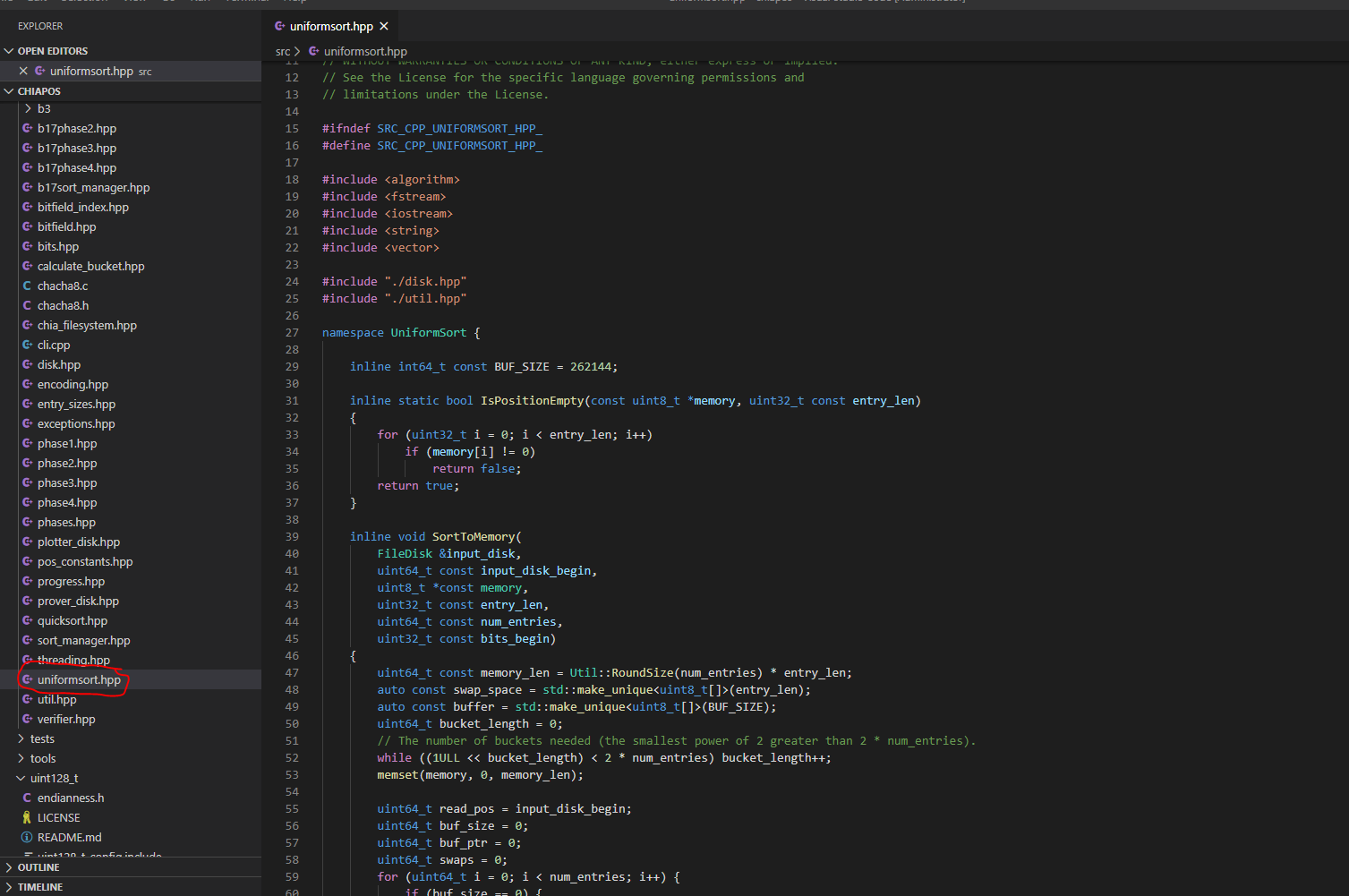
We need to optimize the following points:
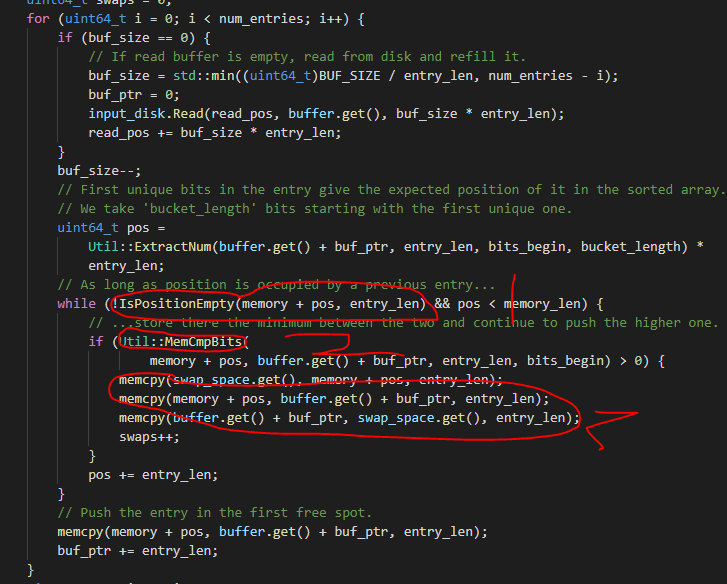
1 and 2 will uint8_ Change t to uint64_8. In this way, the number of cycles can be folded.
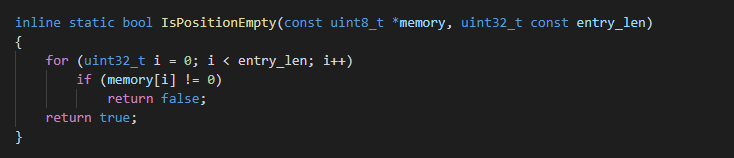
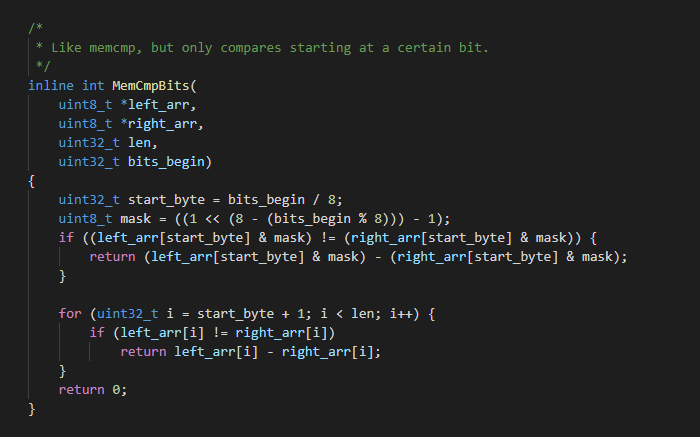
The optimized code is as follows:
inline static bool IsPositionEmpty(const uint8_t *memory, uint32_t const entry_len)
{
for (uint32_t i = 0; i < entry_len; i++){
if(entry_len - i >= 8){
uint64_t *a1 = (uint64_t*)memory;
if(*a1 == 0){
i += 7;
continue;
}
return false;
}
if(entry_len - i >= 4){
uint32_t *a2 = (uint32_t*)memory;
if(*a2 == 0){
i += 3;
continue;
}
return false;
}
if(entry_len - i >= 2){
uint16_t *a3 = (uint16_t*)memory;
if(*a3 == 0){
i += 1;
continue;
}
return false;
}
if (memory[i] != 0){
return false;
}
}
return true;
}
inline int MemCmpBits(
uint8_t *left_arr,
uint8_t *right_arr,
uint32_t len,
uint32_t bits_begin)
{
uint32_t start_byte = bits_begin / 8;
uint8_t mask = ((1 << (8 - (bits_begin % 8))) - 1);
if ((left_arr[start_byte] & mask) != (right_arr[start_byte] & mask)) {
return (left_arr[start_byte] & mask) - (right_arr[start_byte] & mask);
}
for (uint32_t i = start_byte + 1; i < len; i++) {
if(len - i >= 8) {
uint64_t *a1 = (uint64_t*)(left_arr + i);
uint64_t *b1 = (uint64_t*)(right_arr + i);
if(*a1 == *b1){
i += 7;
continue;
}
}
if(len - i >= 4) {
uint32_t *a2 = (uint32_t*)(left_arr + i);
uint32_t *b2 = (uint32_t*)(right_arr + i);
if(*a2 == *b2){
i += 3;
continue;
}
}
if(len - i >= 2) {
uint16_t *a3 = (uint16_t*)(left_arr + i);
uint16_t *b3 = (uint16_t*)(right_arr + i);
if(*a3 == *b3){
i += 1;
continue;
}
}
if (left_arr[i] != right_arr[i]){
return left_arr[i] - right_arr[i];
}
if (left_arr[i+1] != right_arr[i+1]){
return left_arr[i+1] - right_arr[i+1];
}
}
return 0;
}
In this way, we will fold the two for loops. If we consider the cpu extension instruction, we can even use avx to fold more, but only the general platform is considered here.
Then we open util HPP file, you can see the following functions and optimize them:
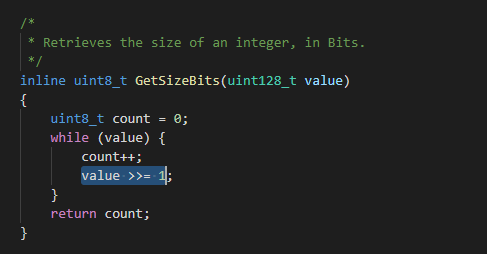
The main function of this function is to count uint128_t there are several binary 1s in the data types here. There are two optimization methods. One is to use the special instruction popcnt of cpu. However, only the optimization methods under the conventional platform are considered here.
By caching a small amount of data and using space for time, the optimization code is as follows:
inline uint8_t GetSizeBits(uint128_t value)
{
const uint8_t tab[] = {
0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
4, 5, 5, 6, 5, 6, 6, 7, 5, 6, 6, 7, 6, 7, 7, 8};
union {
uint128_t from;
uint8_t to[16];
} *ptr = &value;
count=0;
for(int i=0;i<16;i++)
count+=tab[ptr->to[i]];
return count;
}
Another function that needs to be optimized is:
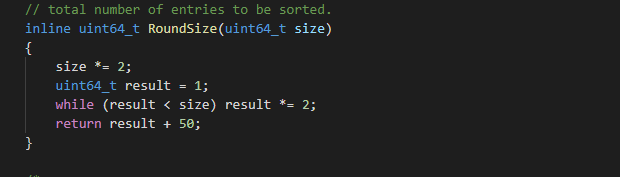
This cycle is not necessary at all. You can directly use the formula in one step:
inline uint64_t RoundSize(uint64_t size)
{
size *= 2;
uint64_t result = pow(2, ceil(log2f((float)size))) + 50;
return result;
}
So far, some simple changes can improve the performance of this program by more than 10%. The rest is the core part, mainly optimizing the SortToMemory function: the optimization points are as follows:
1. Change the read disk to asynchronous and fold the read time
2. In the process of sorting, change memcpy to pointer reference to reduce the copy overhead
3. Change the sorting algorithm to bucket sorting and let it calculate in parallel
4. Introduce thread pool
After these are completed, the program performance can be improved by more than 30%. You can try according to the method I said.