Article catalog- Problem background
- System environment
- Optimization process
- A little wave of analysis
- Stage 1: directly access torch.cuda.empty_cache() cleanup.
- The second stage (creating sub process loading model and training)
- Phase 3 (Global thread pool + release GPU)
- summary
- reference resources
- Exclusive benefits for fans
- A little wave of analysis
- Stage 1: directly access torch.cuda.empty_cache() cleanup.
- The second stage (creating sub process loading model and training)
- Phase 3 (Global thread pool + release GPU)
Problem background
There is a training interface for automatic generation of ancient poetry. The interface generates the training model (i.e. generation of ancient poetry) through pytoch. In order to speed up the use of GPU, but the GPU cannot be released after the training is completed. Therefore, it needs to be optimized, that is, release the GPU after the generation of ancient poetry. The project is a web service built through flash. In order to realize concurrency on the server, gunicorn is used to start the application. Ancient poetry training through python. The project is deployed on a CentOS server.
System environment
Software | edition |
|---|---|
flask | 0.12.2 |
gunicorn | 19.9.0 |
CentOS 6.6 | Servers with GPU cannot add machines |
pytorch | 1.7.0+cpu |
For special reasons, the next server is available for use, so the addition of machines cannot be considered.
Optimization process
When training the model, pytorch needs to load the model and data first. If there is GPU video memory, we can put it into GPU video memory for acceleration. If there is no GPU, we can only use CPU. Because the process of loading model and data is relatively slow. Therefore, I put the loading process at the start of the project.
import torch device = "cuda" if torch.cuda.is_available() else "cpu" model = GPT2LMHeadModel.from_pretrained(os.path.join(base_path, "model")) model.to(device) model.eval()
This part takes about 6 seconds. cuda means cuda using torch. The GPU video memory occupied by the model data after loading is about 1370MB. The goal of optimization is to release the occupied video memory after training.
A little wave of analysis
The current situation is that if the model model and data are loaded at the start of the project, when the model data is released in the GPU, there will be no model model and data for the next model training? If you want to release the GPU, you need to consider how to reload the GPU. Therefore, the model and data cannot be loaded when the project is started, but only when the training function is called. However, due to the slow loading, it can only be run in an asynchronous sub thread or sub process. Therefore, I first put the loading process of model data and training in a separate thread.
Stage 1: directly access torch.cuda.empty_cache() cleanup.
If the GPU is not released, release it. Isn't that simple? Baidu wave pytorch how to release GPU video memory.
Click and you'll find the answer. That is torch.cuda.empty after training_ cache() . Run the code after adding it, and find it useless!!!!, The first application of CV method failed What is the reason? We will analyze later!!!
The second stage (creating sub process loading model and training)
Since the sub thread loading model and training can not release the GPU, can we change our thinking. Create a sub process to load model data and train, When the training is completed, kill the sub process, and the resources it occupies (mainly GPU video memory) will not be released? There seems to be nothing wrong with this idea. Just do it.
- Define the method of loading model data and training. (code for reference only)
def training(queue):
manage.app.app_context().push()
current_app.logger.error('Foundation loading start')
with manage.app.app_context():
device = "cuda" if torch.cuda.is_available() else "cpu"
current_app.logger.error('device1111 Start cheering')
model.to(device)
current_app.logger.error('device2222')
model.eval()
n_ctx = model.config.n_ctx
current_app.logger.error('Foundation loading completed')
#training method
result_list=start_train(model,n_ctx,device)
current_app.logger.error('Finish training')
#Put the results returned by the training method into the queue
queue.put(result_list)
- Create a sub process, execute the training method, and then obtain the training results through the blocking method
from torch import multiprocessing as mp
def sub_process_train():
#Define a queue to get training results
train_queue = mp.Queue()
training_process = mp.Process(target=training, args=(train_queue))
training_process.start()
current_app.logger.error('Subprocess execution')
# When the training is completed
training_process.join()
current_app.logger.error('Execution complete')
#Get training results
result_list = train_queue.get()
current_app.logger.error('Get data')
if training_process.is_alive():
current_app.logger.error('The child process is still alive')
#Kill child process
os.kill(training_process.pid, signal.SIGKILL)
current_app.logger.error('Kill child process')
return result_list
- Because the subprocess needs to block the execution result, it needs to define a thread to execute the sub_process_train method to ensure that the training interface can return normally.
import threading threading.Thread(target=sub_process_train).start()
The code is written, and it's time to witness miracles. First, start with python manage.py and look at the results. The running results are as follows. An error is reported. From the error prompt, CUDA cannot be loaded repeatedly in the child process of forked. "Cannot re-initialize CUDA in forked subprocess. " + msg) RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method.
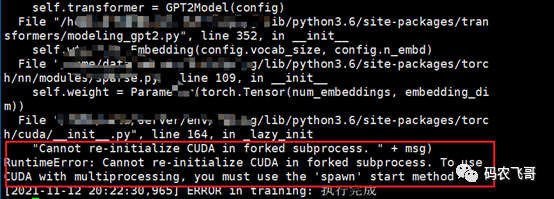
The question here is, what is forked and what is spawn? Here you need to know how to create a child process. Create a child process through torch.multiprocessing.Process(target=training, args=(train_queue)) fork and spawn are different ways to build subprocesses. The difference is 1. fork: in addition to the necessary startup resources, other variables, packages and data are integrated from the parent process, that is, they share some memory pages of the parent process, so they start faster. However, most of them use the data from the parent process, and all of them are unsafe child processes. 2. spawn: build a child process from scratch. The data of the parent process is copied to the space of the child process. It has its own Python interpreter. All packages of the parent process need to be reloaded. Therefore, the startup is slow, but because the data is its own, the security is relatively high. Go back to the error report just now. Why prompt to not load repeatedly. This is because the use of the spawn startup method in Python 3 supports the sharing of CUDA tensors between processes. multiprocessing uses fork to create subprocesses, which is not supported by CUDA runtime. Therefore, you can only add mp.set before creating a child process_ start_ Method ('spawn ') method. Namely
def sub_process_train(prefix, length):
try:
mp.set_start_method('spawn')
except RuntimeError:
pass
train_queue = mp.Queue()
training_process = mp.Process(target=training, args=(train_queue))
##Omit other codes
Run the project again through python manage.py. The operation results are shown in Figure 1 and Figure 2. It can be seen that the GPU memory can be used correctly, and the GPU can also be released after the training is completed.
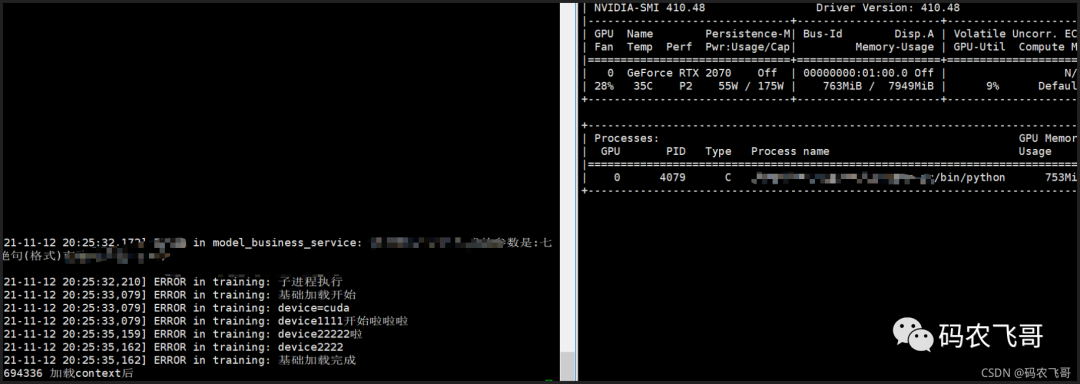
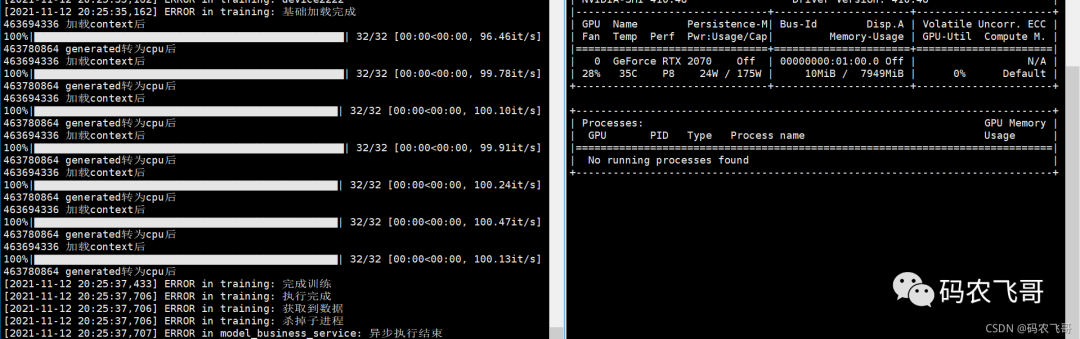
Everything looks perfect. But,But. After starting the project through gunicorn, call the interface again, and the following results will appear.
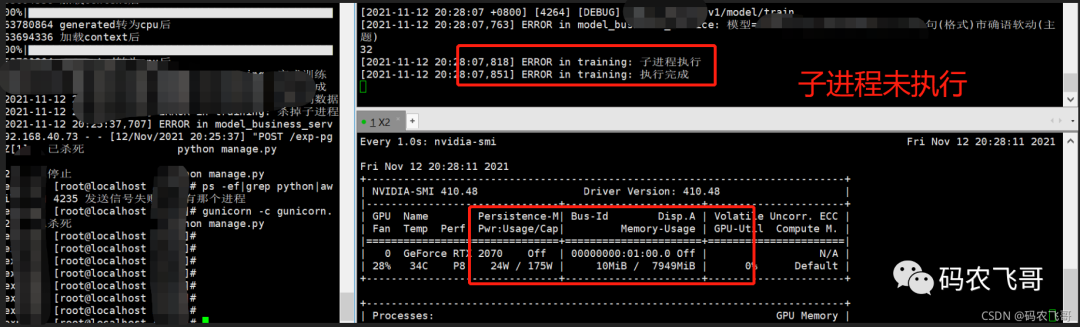
It's a big deal that the sub process of starting the project with gunicorn is not executed. Without mp.set_start_method('spawn ') method model data cannot be loaded, In addition, the sub process of this method cannot be executed. It is really the first two.
Phase 3 (Global thread pool + release GPU)
The way of subprocess is also not good. We can only go back to the previous thread mode. The previous methods of creating threads are to directly create a new thread. When too many threads are running at the same time, it is easy to fill the GPU, resulting in application crash. Therefore, the global thread pool is used to create and manage threads, and then release resources after thread execution is completed.
- A global thread pool is created after the project is started. The size is 2. Ensure that there are remaining GPU s.
from multiprocessing.pool import ThreadPool pool = ThreadPool(processes=2)
- Perform training through thread pool
pool.apply_async(func=async_produce_poets)
- Load model and release GPU with thread
def async_produce_poets():
try:
print("Child process start" + str(os.getpid())+" "+str(threading.current_thread().ident))
start_time = int(time.time())
manage.app.app_context().push()
device = "cuda" if torch.cuda.is_available() else "cpu"
model = GPT2LMHeadModel.from_pretrained(os.path.join(base_path, "model"))
model.to(device)
model.eval()
n_ctx = model.config.n_ctx
result_list=start_train(model,n_ctx,device)
#Transfer model to cpu
model = model.to('cpu')
#To delete a model is to delete a reference
del model
#Release the GPU when using it.
torch.cuda.empty_cache()
train_seconds = int(time.time() - start_time)
current_app.logger.info('The total training time is={0}'.format(str(train_seconds)))
except Exception as e:
manage.app.app_context().push()
After this operation, the ideal effect was finally achieved.
This is because gunicorn is used to start the project. Therefore, gunicorn related knowledge is essential. It is ideal to use sync in the system with limited CPU. See gunicorn's brief summary for details
In the first stage of problem analysis, torch.cuda.empty is directly used_ Cache () failed to release the GPU because the model was not deleted. The model has been loaded into the GPU.
summary
This paper starts with the optimization of the actual project and records all aspects of the optimization. I hope it will be helpful to readers.
reference resources
multiprocessing fork() vs spawn()