I Redis (in memory nosql database)
- NoSQL and RDBMS
1.1: the characteristics of RDBMS (relational database mysql): it reflects the relationship between data, supports transactions, ensures the integrity and stability of business, and has good performance with a small amount of data. However, high concurrency will lead to database crash.
1.2 NoSQL (non relational database Redis, HBASE, MongoDB) features: it is generally used for data caching or database storage in high concurrency and high performance scenarios. It has fast reading and writing speed and high concurrency. It is not as stable as RDBMS and is not friendly to transactional support.
Reading pays attention to concurrency and writing pays attention to security. - Redis functions and application scenarios:
2.1 definition: the memory based distributed nosql database stores all data in memory and has a persistence mechanism. Every time redis restarts, the data will be reloaded from the file to memory, and all reads and writes are only based on memory
2.2 function: high performance and high concurrency data storage, reading and writing
2.3 features: good interaction with hardware, fast data reading and writing based on memory, distributed (expanded and stable), kv structured database, with various rich data types (String, hash, list, set, zset)
2.4 application scenarios: cache (high concurrency, large amount of data cache, temporary cache), database (high performance, small amount of data read and write, big data storage, real-time processing results), message middleware (message queue, big data generally do not use kafka) - Stand alone deployment of redis:
3.1 upload and decompress, and install the C language compiler:
yum -y install gcc-c++ tcl
3.2 compilation and installation
Enter the source directory: / export/server/redis-3.2.8 / compile make; Installation: make PREFIX=/export/server/redis-3.2.8-bin install
3.3 modify the configuration (copy the configuration file):
cp /export/server/redis-3.2.8/redis.conf /export/server/redis-3.2.8-bin/
Create log file
mkdir -p /export/server/redis-3.2.8-bin/logs
Create data file
mkdir -p /export/server/redis-3.2.8-bin/datas
Modify configuration:
vim redis.conf
Change the bound machine address:
Background operation

Log storage location

Persistent data storage location in memory

Create a soft connection to redis-3.2.8-bin: ln -s redis-3.2.8-bin redis
Modify profile

Startup: edit the startup script in the bin directory of redis:
#!/bin/bash
REDIS_HOME=/export/server/redis
${REDIS_HOME}/bin/redis-server ${REDIS_HOME}/redis.conf
Add permission: CHMOD U + X / export / server / redis / bin / redis start sh

Port: 6379
Client connection: redis cli - H node1 - P 6379
shutdown closes the server. Or: kill -9 `cat /var/run/redis_6379.pid ``
-
Data structure and data type of redis
Data structure: kv structure exists k as unique identifier and is fixed as string type; v: The real stored data can be string, hash, list, set, zset and bitmap. hypeloglog.
4.1 string is used to store a single string and store the result
pv: page views. Every time a user visits a page, pv will be increased by one
uv: user visits. Each user is counted as one uv
4.2 hash: map set, which is used to store the values of multiple attributes
4.3 list: list, orderly and repeatable, can store multiple values
4.4 set: set removes duplicate values and is unique
It combines the features of map, top, and tre: list, which are not ordered -
General commands of redis:
5.1 keys: list all keys of the current database
5.2 del key: delete key
5.3 exists key: determine whether the key exists
5.4 type key: view type
5.5 expire key 20s: the key expires after 20s
5.6 ttl key: how long does the key expire
5.7 select n: switch the database. By default, there are 16 databases starting from 0. The number of databases can be modified through the configuration file db0
5.8 move key n: move a key to a database
5.9 flushdb: clear database
5.10 flush: clear the key s of all databases -
Operation on string:
6.1 set : set s1 hadoop

6.2 get key: get the value of the specified key
get s1

6.3 set the value of the given key to value and return the old value of the key
getset key value

6.4 set multiple string type kv: mset k1 v1 k2 v2

6.5 get multiple value s: mget k1 k2
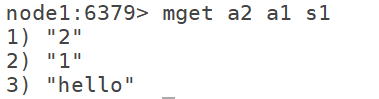
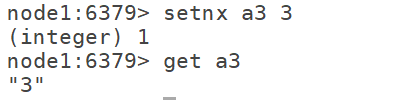
6.6 build preemptive lock and use it with expire. It can only be used to add data. When k does not exist, add setnx k v
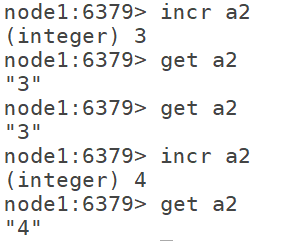
6.7 incr: used to increment the string of numeric type by 1, generally used for counter incr k
6.8 specify a fixed step for the growth of numeric strings: incrby k n

6.9 decrement of numerical data by 1: decr k

6.10 decrby: decrease by K n according to the specified step size

6.11 strlen: counts the length of the string strlen k
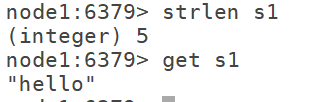
Getrange: used to intercept string 12.6

-
hash type
7.1 hset: used to add an attribute hset k V for a key

7.2hmset: assign value to a k in batch:
hmset K k1 v1 k2 v2 ......

7.2 hget: used to get a property value of a k

7.3hmget: get the values of multiple attributes of a k in batch
hmget k k1 k2 k3 k4

7.4hgetall: get the value of all attributes hgetall k
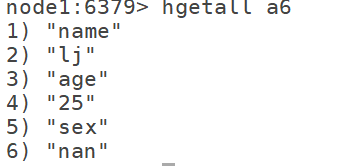
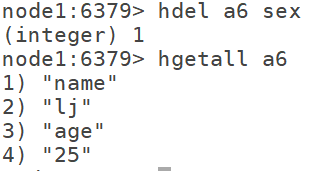
7.5hdel: delete an attribute
hdel k k1 k2 k3
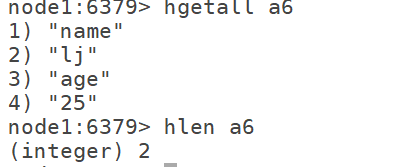
7.6 hlen: count the total number of attributes of value corresponding to k
hlen k
7.7 hexists: judge whether the k contains this attribute
hexists k k

7.8 hvals: get the value of all attributes

7.9 hkeys: get all attributes

-
Common commands of type list
8.1 lpush: put each element to the left of the set and put it in the left order
lpush k e1 e2
8.2 rpush: put each element on the right side of the set and put it in the right order
rpush k e1 e2
8.3lrange: obtain the data of elements through the range of subscripts
lrange k start end from 0 or - 1
8.4llen: length of statistical set
llen k
8.5 lpop: delete an element on the left
lpop k
8.6 rpop: delete an element on the right
rpop k -
Common commands of type set
9.1 sadd: used to add elements to the set

9.2 smembers: used to view all members of the set

9.3 sismember: judge whether this element is included

9.4 srem: delete one of the elements

9.5 scar: Statistics set length

9.6 sunion: take the union of two sets
sunion k1 k2
9.7 sinter: take the intersection of two sets
sinter k1 k2 -
Common commands of Zset type
10.1 zadd: add element to zset set
10.2 zrevrange: reverse order query
10.3 zrem: remove an element
10.4 zcard: length of statistical set
10.5 zscore: get score
node1:6379> zadd zset1 10000 hadoop 2000 hive 5999 spark 3000 flink (integer) 4 node1:6379> zrange zset1 0 -1 1) "hive" 2) "flink" 3) "spark" 4) "hadoop" node1:6379> zrange zset1 0 -1 withscores 1) "hive" 2) "2000" 3) "flink" 4) "3000" 5) "spark" 6) "5999" 7) "hadoop" 8) "10000" node1:6379> zrange zset1 0 2 withscores 1) "hive" 2) "2000" 3) "flink" 4) "3000" 5) "spark" 6) "5999" node1:6379> zrevrange zset1 0 -1 1) "hadoop" 2) "spark" 3) "flink" 4) "hive" node1:6379> zrevrange zset1 0 2 1) "hadoop" 2) "spark" 3) "flink" node1:6379> zrevrange zset1 0 2 withscores 1) "hadoop" 2) "10000" 3) "spark" 4) "5999" 5) "flink" 6) "3000" node1:6379> zadd zset1 4000.9 oozie (integer) 1 node1:6379> zrange zset1 0 -1 1) "hive" 2) "flink" 3) "oozie" 4) "spark" 5) "hadoop" node1:6379> zrange zset1 0 -1 withscores 1) "hive" 2) "2000" 3) "flink" 4) "3000" 5) "oozie" 6) "4000.9000000000001" 7) "spark" 8) "5999" 9) "hadoop" 10) "10000" node1:6379> zrem zset1 oozie (integer) 1 node1:6379> zrange zset1 0 -1 withscores 1) "hive" 2) "2000" 3) "flink" 4) "3000" 5) "spark" 6) "5999" 7) "hadoop" 8) "10000" node1:6379> zcard zset1 (integer) 4 node1:6379> zscore zset1 flink "3000" node1:6379>
- Common commands of type bitmap
11.1 construct bitmaps through the storage space of a string object, and each bit is represented by 0 and 1.
11.2 setbit: modify the value of a bit
setbit bit1 0 1
11.3 bitcount: count the number of a
bitcount bit1 0 10: how many ones are there in 0-80
11.4 bitop: and or not operation
bitop and/or/xor/not - hyperloglog: similar to set, it is used with a large amount of data and has a certain error rate
12.1 pfadd: add element
12.2 pfcount: number of Statistics

12.3 pfmerge: Consolidation

- Code construction
13.1 adding dependencies
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
</plugins>
</build>
13.2 building connections
package bigdata.redis;
import org.junit.After;
import org.junit.Before;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisClientTest {
Jedis jedis=null;//Ordinary jedis object
@Before
public void getConnectipn() {
//Method 1: directly instantiate and specify the server address: machine port
//jedis=new Jedis("node1",6379);
//Method 2: build thread pool
//Configuration object of thread pool
JedisPoolConfig config=new JedisPoolConfig();
config.setMaxTotal(10);//Maximum number of connections to the thread pool
config.setMaxIdle(5);
config.setMinIdle(2);
JedisPool jedisPool=new JedisPool(config,"node1",6379);
//Get connection from thread pool
jedis=jedisPool.getResource();
}
@After
//Close connection
public void closeconnect(){
jedis.close();
}
}
13.3 five types of operations are commonly used:
13.3.1 string operation:
public void StringTest(){
jedis.set("name", "lihua");
System.out.println(jedis.get("name"));
jedis.set("s2", "10");
System.out.println(jedis.incr("s2"));
Boolean s2 = jedis.exists("s2");
System.out.println(s2);
jedis.expire("s2", 10);
while (true){
System.out.println(jedis.ttl("s2"));
if(jedis.ttl("s2")==-2)break;
}
13.3.2 hash operation:
public void hashTest(){
jedis.hset("hash1", "k1", "hash Is the best");
System.out.println(jedis.hget("hash1","k1"));
//hmset
Map map=new HashMap();
map.put("name", "lihua");
map.put("age", "26");
map.put("sex", "nan");
jedis.hmset("m11",map);
System.out.println(jedis.hmget("m11", "age","sex"));
Map<String, String> hgetAll = jedis.hgetAll("m11");
System.out.println(hgetAll);
}
13.3.3 list type:
public void listTest(){
jedis.lpush("list1", "3","2","1","0");
System.out.println(jedis.lrange("list1",0,4));
}
13.3.4 set type:
public void setTest(){
jedis.sadd("set1", "1","2","3","1","9","10","5","3");
System.out.println(jedis.smembers("set1"));
System.out.println(jedis.scard("set1"));
}
13.3.5 zset type
public void zsetTest(){
jedis.zadd("zset11", 0,"hadoop");
jedis.zadd("zset11", 30,"hive");
jedis.zadd("zset11", 40,"flash");
jedis.zadd("zset11", 20,"happy");
jedis.zadd("zset11", 100,"hp");
System.out.println(jedis.zrange("zset11",0, -1));//Sort output
System.out.println(jedis.zrangeWithScores("zset11", 0,-1));
System.out.println(jedis.zrevrange("zset11", 0, -1));
}
- Data storage design:
14.1 how does data storage ensure data security?
Disk storage: large space, relatively high security, but relatively poor read-write performance; Data security: Replica mechanism (hardware replica: RAIDI, software replica: HDFS block)
Memory storage: data is stored in memory, with relatively high reading and writing, small space and instability; Data security: the operation log of memory, which appends the changes of memory to the file written to disk or stores the data of the whole memory to disk
14.2 how to ensure the security of HDFS data?
The linux disk is through the copy mechanism.
14.3 how to ensure the security of HDFS metadata?
The metadata is stored in the memory of the namenode or the fsimage file on the disk of the namenode
Fault restart: record the changes of memory metadata in the edits file
Every time you start namenode, merge the edits file with the fsimage file to recover the memory metadata - Persistence of Redis
15.1 each time redis writes to memory, it synchronizes the data to the disk. If it is restarted, it reloads the data from the disk to memory to provide read and write.
15.2 RDB scheme: the default persistence scheme of redis: within a certain period of time, if the data in redis memory is updated for a certain number of times, take a full snapshot of all data of the whole redis, and store the file on the hard disk. The new snapshot covers the old snapshot. The snapshot is a full snapshot, which is basically consistent with the memory.
Manual trigger: data / dump. In redis directory rdb
Command: save (blocking) or bgsave
Automatic trigger: take a snapshot according to the number of updates within a certain time.
There are corresponding configurations in the configuration file:
There are three groups by default. If there is only one group, it will lead to data loss in different scenarios. For different read and write speeds, it meets the data saving strategy in various cases. There is some data loss.


15.3 AOF design
Append the operation log of the memory data to a file. When redis fails and restarts, read all the operation logs from the file and recover the data in memory.
15.3.1 always: every time a new piece of data is added, the synchronous update operation is added to the file
15.3.2 appendfsync everysec: write the operation of data in memory asynchronously to the file every second. There is a risk of data loss, with a maximum loss of 1s
15.3.3 appendfsync no: handed over to the operating system and not controlled by redis