For detailed syntax, see Official website grammar Here are just some common grammars
Common command operations of Phoenix Shell
!table --View table information !describe tablename --You can view table field information !history --You can view the execution history SQL !dbinfo !index tb; --see tb Index of !quit; --sign out phoenix shell help --View additional actions
Importing HDFS data directly into a table
hadoop jar /home/phoenix-4.12/phoenix-4.6.0-HBase-1.0-client.jar org.apache.phoenix.mapreduce.CsvBulkLoadTool -t POPULATION -i /datas/us_population.csv -t : tableName -i: input file File must be in hdfs On the file.
Schema operations commonly used in Phoenix SQL
Configure schema to save namespace mapping
There is no concept of Database in Phoenix. All tables are in the same namespace. However, multiple namespaces are supported in HBase site Set the following parameters in XML to true, and the created table with schema will be mapped to a namespace.
<property> <name>phoenix.schema.isNamespaceMappingEnabled</name> <value>true</value> </property>
CREATE SCHEMA: (CREATE SCHEMA)

Create Schema and corresponding namespace in HBase. The user executing this command should have administrator privileges to create HBase namespaces in.
--If it exists, it will not be created CREATE SCHEMA IF NOT EXISTS my_schema; --establish SCHEMA CREATE SCHEMA my_schema;

This operation is only supported in the shell, not in the visualizer client.
Switch schema: (USE SCHEMA_NAME)

use default; use schema_name;
Delete Schema: (DROP SCHEMA)
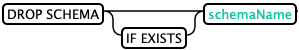
Delete the schema and the corresponding namespace from HBase. To enable namespace mapping, this statement will succeed only if the schema does not contain any tables.
--Exist delete SCHEMA DROP SCHEMA IF EXISTS my_schema --delete SCHEMA DROP SCHEMA my_schema
Permission management operation of Phoenix SQL
GRANT authority: (GRANT)

Permission levels: R-read, W-write, X-execute, C-create, A-administrator. To enable / disable access control, see hbase configuration.
Permissions should be granted on the base table. It propagates to all its indexes and views. Group permissions apply to all users in the group, and schema permissions apply to all tables with the schema. Grant statements that do not specify a table / schema are assigned at the GLOBAL level.
Phoenix does not expose the Execute ('X ') function to end users. However, variable tables with secondary indexes are required.
GRANT 'RXC' TO 'User1'--by User1 Add read, execute and create permissions GRANT 'RWXC' TO GROUP 'Group1'--by Group1 Add read, write, execute and create permissions GRANT 'A' ON Table1 TO 'User2' --To users User2 add to Table1 Administrative authority GRANT 'RWX' ON my_schema.my_table TO 'User2'--by User2 add to my_schema.my_table Read, write and execute permissions GRANT 'A' ON SCHEMA my_schema TO 'User3'--by User3 add to my_schema Add administrative permissions
Cancel permission: (REVOKE)

- Revoke permissions at the table, schema, or user level. Permissions are managed by in the HBase hbase: acl table, so access control needs to be enabled. Phoenix version 4.14 and later will provide this feature. To enable / disable access control, see hbase configuration.
- Group permission applies to all users in the group, and schema permission applies to all tables with this schema. Permission for the base table should be revoked. It propagates to all its indexes and views. Revocation statements that do not specify a table / schema are assigned at the GLOBAL level.
- Revoking will delete all permissions at this level.
- The revoke permission must be exactly the same as the permission assigned through the grant permission statement. Level refers to table, schema or user. Revoking any '' permission on any RXPhoenix SYSTEM table will cause an exception. Revoke any 'RWX' permissions, system Sequence will cause an exception when accessing the sequence.
The following example is used to revoke permissions granted using the example in the GRANT statement above.
REVOKE FROM 'User1'--revoke User1 Read, execute and create permissions REVOKE FROM GROUP 'Group1'--revoke Group1 jurisdiction REVOKE ON Table1 FROM 'User2'--revoke User2 of Table1 jurisdiction REVOKE ON my_schema.my_table FROM 'User2'--revoke User2 yes my_schema.my_table Permissions for REVOKE ON SCHEMA my_schema FROM 'User3'--revoke User3 yes my_schema Permissions for
Common table operations in Phoenix SQL:
Presentation table: (list corresponding syntax)
!table Or! tables
CREATE TABLE: (CREATE TABLE)
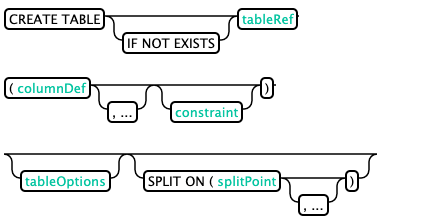
Hbase is case sensitive. Phoenix will convert lowercase in sql statements into uppercase by default, and then build the table. If you don't want to convert, you need to use quotation marks for table names and field names.
By default, the primary key of the phoenix table in Hbase corresponds to row, and the column family name is 0. You can also specify the column family when creating the table.
--The table name and column family name are capitalized by default, and the column family primary key is specified CREATE TABLE IF NOT EXISTS my_schema.population ( State CHAR(2) NOT NULL, City VARCHAR NOT NULL, Population BIGINT CONSTRAINT my_pk PRIMARY KEY (state, city));
In phoenix, by default, table names are automatically converted to uppercase. To lowercase, use double quotation marks, such as "population".
Create salt_buckets
Salting can significantly improve the read-write performance by pre splitting data into multiple regions. The essence is that in hbase, the first byte position of the byte array of rowkey sets a system generated byte value, which is calculated by a hash algorithm of the byte array of rowkey generated by the primary key. After salting, the data can be distributed to different regions, which is conducive to phoenix concurrent read and write operations. SALT_ The value range of buckets is (1 ~ 256).
--Create salt table
create table test
(
host varchar not null primary key,
description varchar
)
salt_buckets=16;
--Update salt dosing table
upsert into test (host,description) values ('192.168.0.1','s1');
upsert into test (host,description) values ('192.168.0.2','s2');
upsert into test (host,description) values ('192.168.0.3','s3');
The salted table can automatically add a byte before each rowkey, so that for a continuous section of rowkeys, when they are actually stored in the table, they will be automatically distributed to different regions. When you specify that you want to read and write the data in this section, you can avoid that the read and write operations are concentrated in the same region. In short, if we create a saltedtable with Phoenix, when writing data to the table, a byte will be automatically added to the front of the original rowkey (different rowkeys will be assigned different bytes), so that continuous rowkeys can also be evenly distributed to multiple regions.
Set pre partition: (pre split)
Salting can automatically set table pre partition, but you have to control how the table is partitioned. Therefore, when creating phoenix table, you can accurately specify what value to do pre partition according to, for example:
create table test
(
host varchar not null primary key,
description varchar
)
split on ('cs','eu','na');
Using multi column families
Column families contain relevant data in separate files. Setting multiple column families in Phoenix can improve query performance. Create two column families:
--Create a multi column family table
create table test_colunms
(
mykey varchar not null primary key,
a.col1 varchar,
a.col2 varchar,
b.col3 varchar
);
--Update record
upsert into test_colunms values ('key1','a1','b1','c1');
upsert into test_colunms values ('key2','a2','b2','c2');
Use compression
create table test
(
host varchar not null primary key,
description varchar
)
compression='snappy';
other
In the table creation statement, you can also attach some HBase table and column family configuration options, such as DATA_BLOCK_ENCODING,VERSIONS,MAX_FILESIZE ,TTLetc. The specific setting value needs to be further understood.
--DATA_BLOCK_ENCODING,VERSIONS,MAX_FILESIZE Use of CREATE TABLE IF NOT EXISTS "my_case_sensitive_table"( "id" char(10) not null primary key, "value" integer) DATA_BLOCK_ENCODING='NONE', VERSIONS=5, MAX_FILESIZE=2000000 split on (?, ?, ?) --TTL Use of CREATE TABLE IF NOT EXISTS my_schema.my_table ( org_id CHAR(15), entity_id CHAR(15), payload binary(1000), CONSTRAINT pk PRIMARY KEY (org_id, entity_id) ) TTL=86400
Delete table: (DROP TABLE)

To delete a table, optionally use the CASCADE keyword, which will cause all views created on the table to be deleted. When deleting a table, HBase will delete the basic data table and index table by default. Configure Phoenix schema. Dropmetadata can be used to change the default configuration. The data will not be deleted during deletion, and the HBase table will be retained for point in time query.
--Delete directly drop table my_schema.population; --Delete if table exists drop table if exists my_schema.population; --Deleting a table deletes all views created on the table at the same time drop table my_schema.population cascade;
Query record: (SELECT)
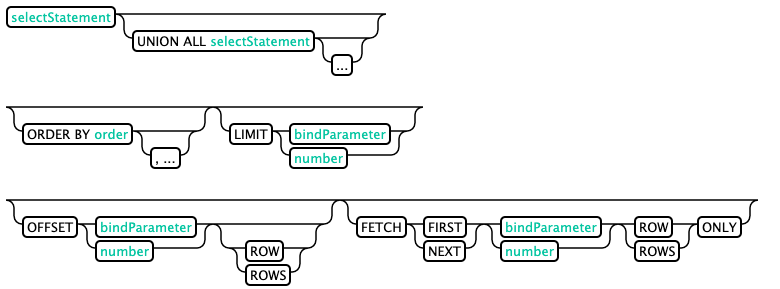
Phoenix's SELECT syntax union all, group by, order by, limit (offset first is the same as limit), and offset is supported.
--1000 query results are reserved select * from test limit 1000; --Return result 100-1000,Offset Skip before returning results n that 's ok select * from test limit 3 offset 2; select * from test limit 3 offset 1; --union all select full_name from sales_person where ranking >= 5.0 union all select reviewer_name from customer_review where score >= 8.0
Insert record: (UPSERT)
In Phoenix, there is no Insert statement, instead, there is an Upsert statement. There are two usages of Upsert: upsert into and upsert select.
UPSERT VALUES
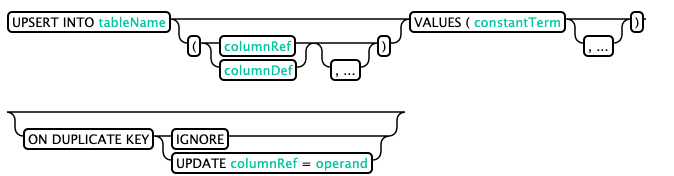
Statements similar to insert into are designed to insert external data in a single entry
--No field information
upsert into my_schema.population values('BJ','BeiJing',8143197);
--Add field information
upsert into my_schema.population(State,City,population) values('SZ','ShenZhen',6732422);
UPSERT SELECT

Similar to the insert select statement in Hive, it aims to insert data from other tables in batches.
--Insert with field upsert into population (state,city,population) select state,city,population from tb2 where population < 7000000; --Insert without field upsert into population select state,city,population from tb2 where population > 7000000; --support select * upsert into population select * from tb2 where population > 7000000;
Inserting statements in Phoenix does not have duplicate data like traditional databases. Because Phoenix is built on HBase, that is, there must be a primary key. The later ones will overwrite the previous ones, but the time stamps are different.
Modification record:
Due to the primary key design of HBase, the contents of the same rowkey can be directly overwritten, which updates the data in a disguised form. Therefore, the update operations of Phoenix are still upsert into and upsert select. The instance is the same as above, and the record is inserted.
DELETE record: (DELETE)
delete from population; #Clear all records in the table. truncate table tb cannot be used in Phoenix; delete from my_schema.population where city = 'LinYin';#Delete the record whose city is kenai in the table delete from system.catalog where table_name = 'int_s6a';#Delete system Table in catalog_ Name is int_s6a record