Today's article is about how to use requests to crawl data from public reviews.
After reading this article, you can:
1. Understanding CSS Anti-Crawler Mechanism of Public Comments
2. Cracking Anti-Crawler Mechanism
3. Use requests to get the correct number of comments, average price, service, taste, environmental data, and commentary text data;
At the same time, the code I ** did not do much optimization because there were not a lot of agents and not much content to crawl.
Here's just to share the process
Start of text.

1. Preface
In the work life, we find that more and more people are interested in the data of public comment, and the anti-crawling of public comment is more strict.The strategy adopted was almost to kill 10,000 people by mistake rather than let one go.Sometimes you skip the verification code when browsing normally.
In addition, the display data on the PC side is controlled by CSS, which does not make a big difference from the web page, but when you fetch it with a normal script, you will find that the data is not available. The specific source code is as follows:
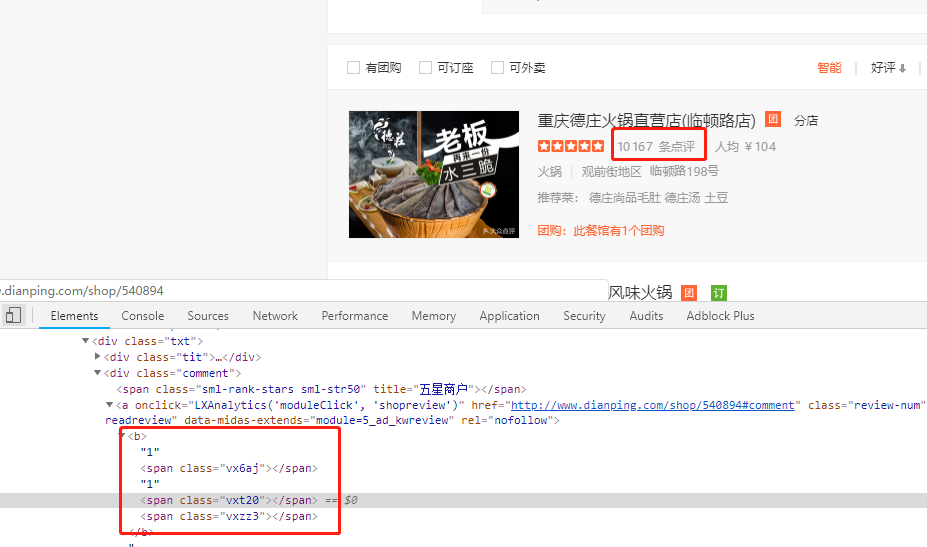
However, when you search for information, you will find that many tutorials are based on methods such as selenium, which are too inefficient and have no technical content.
So this article is targeting public reviews on the PC side; the goal is to address this anti-crawling measure and use requests to get clean and correct data.
Follow me and never let you down.
If you are still confused in the world of programming, you can join us in Python learning to deduct qun:784758214 and see how our forefathers learned.Exchange experience.From basic Python scripts to web development, crawlers, django, data mining, and so on, zero-based to project actual data are organized.For every Python buddy!Share some learning methods and small details that need attention, Click to join us python learner cluster

2. Beginning of text
I believe that students who have done public comment website should know that this is a css anti-crawling method, specific analysis operation, will start soon.
Find the secret css
When our mouse clicks on the span in the box above, the right part changes accordingly:
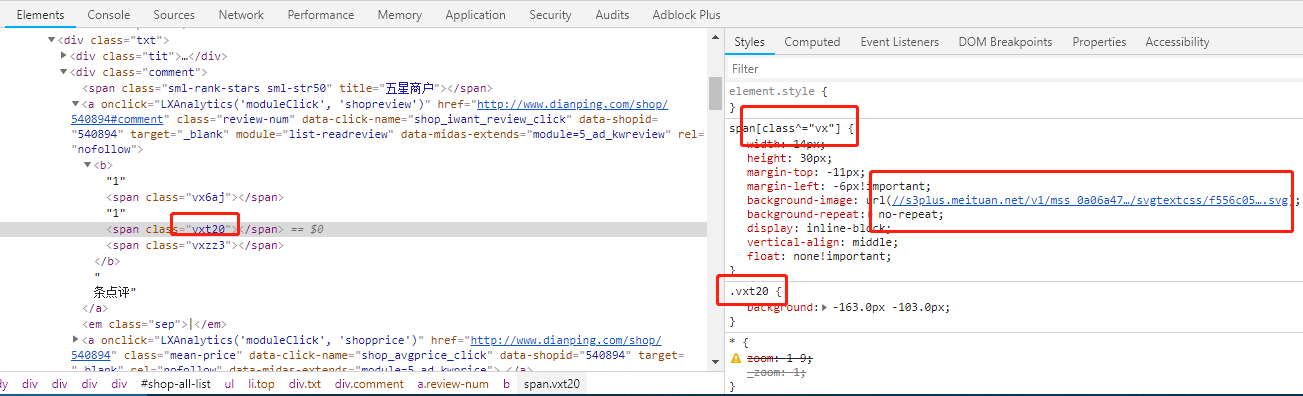
This picture is very important, very important, very important, and the values we want are almost matched from here.
Here we see the two pixel values corresponding to the variable "vxt20". The first one is to control which number to use, the second one is to control which segment of the number set to use. Write down first, then use later, and the value here should be 6;
This is actually the most critical step in the whole cracking process.Here we see a link.
A blind cat is a dead rat. Click in to see it.
https://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/f556c0559161832a4c6192e097db3dc2.svg
You will find that some numbers are returned. I didn't know what it was at first. I just saw the analysis of some great gods. In fact, this is the source of the numbers we see, that is, the source of the whole cracking. Knowing what these numbers mean, I can directly break the whole process of anti-crawling.
Now look directly at the source code:
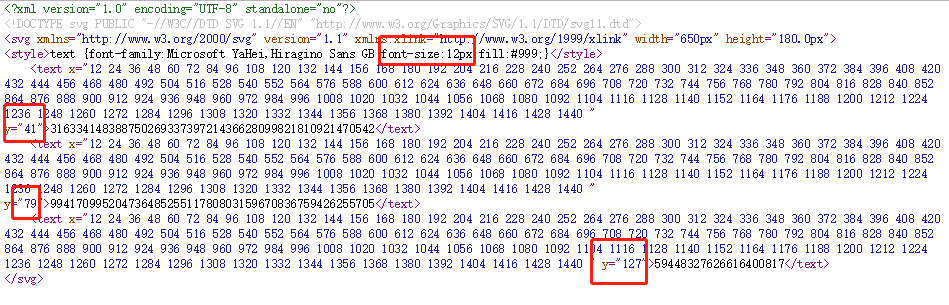
You can see the key numbers here: font-size: font size; and a few y values, so I know later that y was a threshold and played a controlling role.
So the principle of this backcrawl is:
Get the mapping of attribute values to offsets and thresholds and find the true data from the svg file.
Now we're going to use the pixel values above.
1. Take all values as absolute values;
2. Use the following values to choose which segment of the number to use, where the value is 103, so use the third segment of the number set;
3. Because each font is 12 pixels, use 163/12=13.58, which equals about 14, so let's count what the 14th number is, yes, 6, as expected.You can try it a few more times.
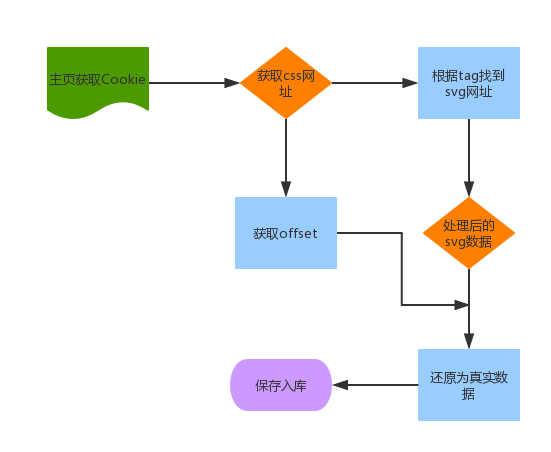
Above is the logical process of the whole solution.
Draw a flowchart to install a force:
3.Show Code
Start sun code below, as the saying goes, a big copy of the world's code.

The main step codes are explained here. If you want to get more code, please follow my public number and send a public comment.
1. Get the corresponding TAG values of css_url and span;
def get_tag(_list, offset=1):
# Start with the first check
_new_list = [data[0:offset] for data in _list]
if len(set(_new_list)) == 1:
# If there is only one value after set, repeating all, then add offset to 1
offset += 1
return get_tag(_list, offset)
else:
_return_data = [data[0:offset - 1] for data in _list][0]
return _return_data
def get_css_and_tag(content):
"""
:param url: Links to Crawl
:return: css Link, the span Corresponding tag
"""
find_css_url = re.search(r'href="([^"]+svgtextcss[^"]+)"', content, re.M)
if not find_css_url:
raise Exception("cannot find css_url ,check")
css_url = find_css_url.group(1)
css_url = "https:" + css_url
# The different fields on this page are controlled by different css segments, so to find the tag corresponding to this comment data, the value returned here is vx; and when you get the comment data, the tag is fu-;
# Specifically, you can see the attribute values corresponding to the three span s of the above screenshot, the longest part of which is equal to vx
class_tag = re.findall("<b class=\"(.*?)\"></b>", content)
_tag = get_tag(class_tag)
return css_url, _tag
2. Get the corresponding relationship between attributes and pixel values
def get_css_and_px_dict(css_url):
con = requests.get(css_url, headers=headers).content.decode("utf-8")
find_datas = re.findall(r'(\.[a-zA-Z0-9-]+)\{background:(\-\d+\.\d+)px (\-\d+\.\d+)px', con)
css_name_and_px = {}
for data in find_datas:
# Property value
span_class_attr_name= data[0][1:]
# Offset
offset = data[1]
# threshold
position = data[2]
css_name_and_px[span_class_attr_name] = [offset, position]
return css_name_and_px
3. Get url of svg file
def get_svg_threshold_and_int_dict(css_url, _tag):
con = requests.get(css_url, headers=headers).content.decode("utf-8")
index_and_word_dict = {}
# Match addresses to corresponding SVGs based on tag values
find_svg_url = re.search(r'span\[class\^="%s"\].*?background\-image: url\((.*?)\);' % _tag, con)
if not find_svg_url:
raise Exception("cannot find svg file, check")
svg_url = find_svg_url.group(1)
svg_url = "https:" + svg_url
svg_content = requests.get(svg_url, headers=headers).content
root = H.document_fromstring(svg_content)
datas = root.xpath("//text")
# Put thresholds and corresponding sets of numbers into a dictionary
last = 0
for index, data in enumerate(datas):
y = int(data.xpath('@y')[0])
int_data = data.xpath('text()')[0]
index_and_word_dict[int_data] = range(last, y+1)
last = y
return index_and_word_dict
4. Get the final value
//I don't know what to add to my learning
python Learning Communication Buttons qun,784758214
//There are good learning video tutorials, development tools and e-books in the group.
//Share with you the current talent needs of the python enterprise and how to learn Python from a zero-based perspective, and what to learn
def get_data(url ):
"""
:param page_url: To be acquired url
:return:
"""
con = requests.get(url, headers=headers).content.decode("utf-8")
# Get the css url, and tag
css_url, _tag = get_css(con)
# Get mapping of css name to pixel
css_and_px_dict = get_css_and_px_dict(css_url)
# Get the mapping of svg threshold and number set
svg_threshold_and_int_dict = get_svg_threshold_and_int_dict(css_url, _tag)
doc = etree.HTML(con)
shops = doc.xpath('//div[@id="shop-all-list"]/ul/li')
for shop in shops:
# Shop Name
name = shop.xpath('.//div[@class="tit"]/a')[0].attrib["title"]
print name
comment_num = 0
comment_and_price_datas = shop.xpath('.//div[@class="comment"]')
for comment_and_price_data in comment_and_price_datas:
_comment_data = comment_and_price_data.xpath('a[@class="review-num"]/b/node()')
# Traverse through each node, where the type of node is different, etree. _ElementStringResult (character), etree._Element (element), etree._ElementUnicodeResult (character)
for _node in _comment_data:
# If it is a character, take it out directly
if isinstance(_node, etree._ElementStringResult):
comment_num = comment_num * 10 + int(_node)
else:
# If it's a span type, look for data
# attr of span class
span_class_attr_name = _node.attrib["class"]
# Offset and segment
offset, position = css_and_px_dict[span_class_attr_name]
index = abs(int(float(offset) ))
position = abs(int(float(position)))
# judge
for key, value in svg_threshold_and_int_dict.iteritems():
if position in value:
threshold = int(math.ceil(index/12))
number = int(key[threshold])
comment_num = comment_num * 10 + number
print comment_num
4. Result Display
Number of Comments Data
Actually, I've written all the other things and I won't post them.


Comment on specific data

5. Conclusion
These are all the steps and some codes that people comment on Css anti-crawling.