1. Concept combing
1.1 PostgreSQL database file composition:
-
Physical file
It consists of a series of physical files located on the operating system, which are usually called databases.
-
Logical file
During the operation of the database, these physical files are managed through a complete set of efficient and rigorous logic.
1.2 database instance
-
Physical files, processes managing these physical files, and process management memory are called instances of this database.
1.3 internal composition of PostgreSQL
- System controller, query analyzer, transaction system, recovery system, file system
- System controller: responsible for receiving external connection requests.
- Query Analyzer: analyze the connection request query and generate the optimized query tree.
- File system: obtain the result set from the file system or process the data through the transaction system, and the file system will persist the data.
2. Logical and physical storage structure
2.1 database clustering
-
Database cluster
The database cluster is a collection of databases managed by a single PostgreSQL server instance. These databases that make up the database cluster use the same global configuration file, listening port, common process and memory structure.
2.2 logical structure of database
When creating a Database, a default schema named public will be created for the Database. Each Database can have multiple schemas. If no schema is specified when creating other Database objects in the Database, they will be in the public schema. Schema can be understood as a namespace in a Database. All objects created in the Database are created in the schema. A user can access different schemas from the same client connection. Different schemas can have multiple Database objects with the same name, such as Table, Index, View, Sequence, Function, etc.
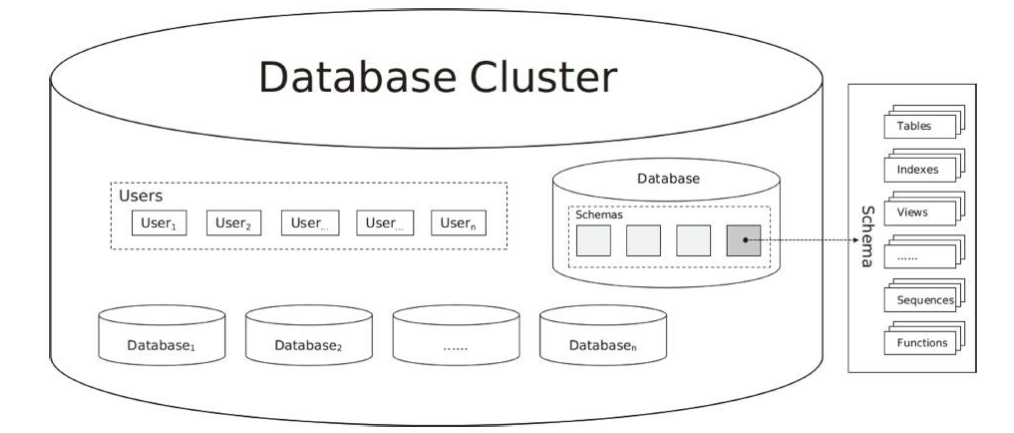
2.3 physical storage structure
The database files are saved in the data directory created at initdb by default. There are many directories and files with different types and functions in the data directory. In addition to the data files, there are also parameter files, control files, database operation logs and pre write logs.
The data directory is used to store the persistent data of PostgreSQL. Generally, the data directory path can be configured as PGDATA environment variable. The commands to view the subdirectories and files of the data directory are as follows:
Catalog file:
[root@node03 ~]# tree -L 1 -d /var/lib/pgsql/12/data/ /var/lib/pgsql/12/data/ ├── base ├── global ├── log ├── pg_commit_ts ├── pg_dynshmem ├── pg_logical ├── pg_multixact ├── pg_notify ├── pg_replslot ├── pg_serial ├── pg_snapshots ├── pg_stat ├── pg_stat_tmp ├── pg_subtrans ├── pg_tblspc ├── pg_twophase ├── pg_wal └── pg_xact 18 directories
Profile:
[root@node03 ~]# tree -L 1 -f /var/lib/pgsql/12/data/ /var/lib/pgsql/12/data ├── /var/lib/pgsql/12/data/base ├── /var/lib/pgsql/12/data/current_logfiles ├── /var/lib/pgsql/12/data/global ├── /var/lib/pgsql/12/data/log ├── /var/lib/pgsql/12/data/pg_commit_ts ├── /var/lib/pgsql/12/data/pg_dynshmem ├── /var/lib/pgsql/12/data/pg_hba.conf ├── /var/lib/pgsql/12/data/pg_ident.conf ├── /var/lib/pgsql/12/data/pg_logical ├── /var/lib/pgsql/12/data/pg_multixact ├── /var/lib/pgsql/12/data/pg_notify ├── /var/lib/pgsql/12/data/pg_replslot ├── /var/lib/pgsql/12/data/pg_serial ├── /var/lib/pgsql/12/data/pg_snapshots ├── /var/lib/pgsql/12/data/pg_stat ├── /var/lib/pgsql/12/data/pg_stat_tmp ├── /var/lib/pgsql/12/data/pg_subtrans ├── /var/lib/pgsql/12/data/pg_tblspc ├── /var/lib/pgsql/12/data/pg_twophase ├── /var/lib/pgsql/12/data/PG_VERSION ├── /var/lib/pgsql/12/data/pg_wal ├── /var/lib/pgsql/12/data/pg_xact ├── /var/lib/pgsql/12/data/postgresql.auto.conf ├── /var/lib/pgsql/12/data/postgresql.conf ├── /var/lib/pgsql/12/data/postmaster.opts └── /var/lib/pgsql/12/data/postmaster.pid 18 directories, 8 files
Purpose of subdirectories and files in data directory:
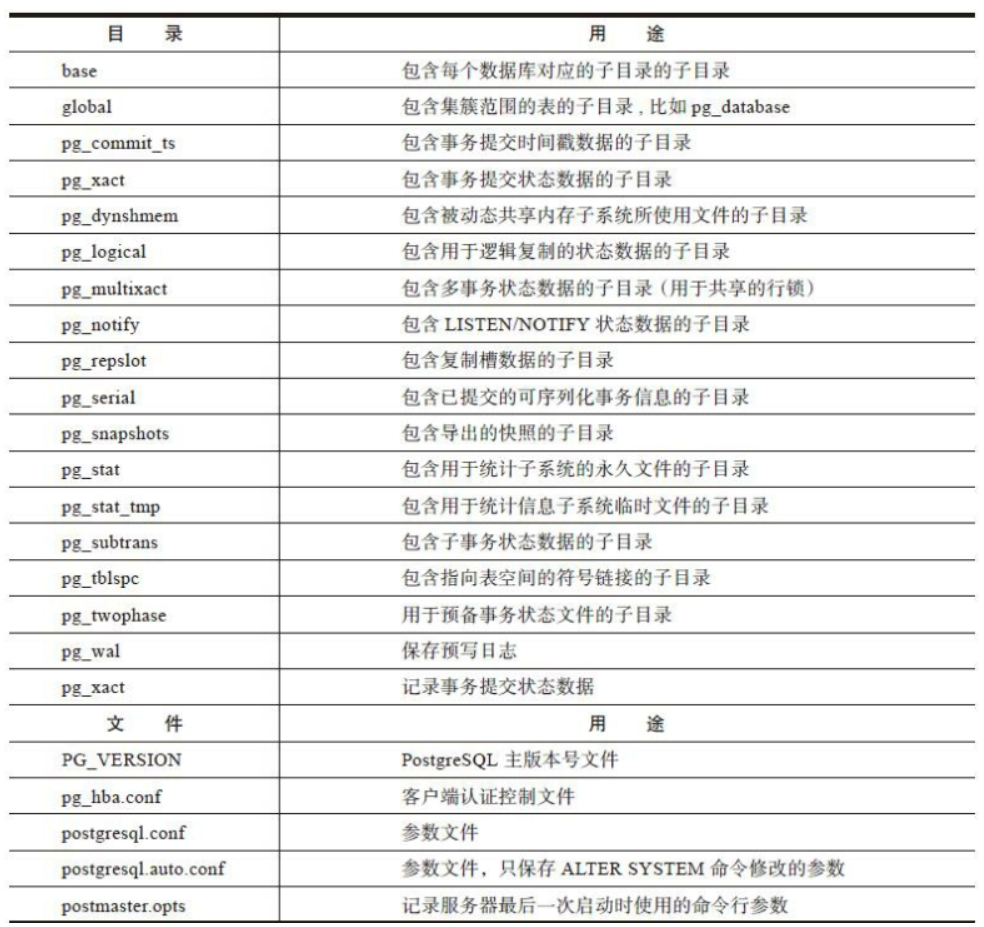
The base subdirectory in the data directory is the default storage location of our data files and the default table space after database initialization.
1) Explanation of terms:
OID: all database objects in PostgreSQL are identified by their respective object identifiers. OIDs are internally managed. They are unsigned 4-byte integers. The relationship between database objects and individual OIDs is stored in the appropriate system directory, depending on the type of object. The OID of the database is stored in pg_database system table.
- Query database OID:
mydb=# select oid, datname from pg_database where datname = 'mydb'; oid | datname -------+--------- 16384 | mydb (1 row)
- OID of query table:
mydb=# select oid, relname, relkind from pg_class where relname ~ 'user'; oid | relname | relkind -------+-----------------------------------+--------- 174 | pg_user_mapping_oid_index | i 175 | pg_user_mapping_user_server_index | i 16432 | users_id_seq | S 16434 | users | r 16441 | users_pkey | i 1418 | pg_user_mapping | r
- Tablespaces:
In PostgreSQL, the largest logical storage unit is the table space. The objects created in the database are saved in the table space. For example, tables, indexes and the whole database can be allocated to a specific table space# The table space of the database object is specified by the distance from the file of the database object. If it is not specified, the default table space is used, that is, the location of the file of the database object.
PG is automatically created when the database directory is initialized_ Default and pg_global two tablespaces. As follows:
mydb=# \db
List of tablespaces
Name | Owner | Location
------------+----------+----------
pg_default | postgres |
pg_global | postgres |
(2 rows)
① pg_ The physical file location of the global table space is in the global directory of the data directory, which is used to save system tables.
② pg_ The physical file location of the default tablespace is in the base directory in the data directory. It is the default tablespace of template0 and template1 databases. We know that when creating a database, it is cloned from template1 database by default. Therefore, unless the tablespace of the new database is specially specified, the tablespace of template1, that is, PG, is used by default_ default.
2) User defined create tablespace
- The port solves the problem that the disk of the existing table space is insufficient and cannot be logically expanded by creating a table space;
- Allocate indexes, WAL and data files on disks with different performance to maximize hardware utilization and performance. Since solid-state storage is now very common, this file layout will increase the maintenance cost.
[root@node03 ~]# mkdir -p /pgdata/10/mytblspc
[root@node03 ~]# su - postgres
-bash-4.2$ /usr/pgsql-12/bin/psql mydb
mydb=# create tablespace myspc location '/pgdata/10/mytblspc';
CREATE TABLESPACE
mydb=# \db
List of tablespaces
Name | Owner | Location
------------+----------+---------------------
myspc | postgres | /pgdata/10/mytblspc
pg_default | postgres |
pg_global | postgres |
(3 rows)
mydb=# create table t1(id serial primary key, ival int) tablespace myspc;
CREATE TABLE
mydb=# \d t1
Table "public.t1"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+--------------------------------
id | integer | | not null | nextval('t1_id_seq'::regclass)
ival | integer | | |
Indexes:
"t1_pkey" PRIMARY KEY, btree (id)
Tablespace: "myspc"
Because the table space defines the storage location, when creating database objects, a directory named after database OID will be created in the current table space directory, and all objects of the database will be saved in this directory unless the table space is specified separately. For example, we have been using the database mydb from PG_ The database system table queries its OID, as shown below:
mydb=# select oid,datname from pg_database where datname = 'mydb'; oid | datname -------+--------- 16384 | mydb (1 row)
The above query shows that the OID of mydb is 16384. We can know that the tables and indexes of mydb will be saved in the directory $PGDATA/base/16384, as shown below:
-bash-4.2$ ll /var/lib/pgsql/12/data/base/16384/ -d drwx------ 2 postgres postgres 8192 Jul 8 16:38 /var/lib/pgsql/12/data/base/16384/
Table users table OID
mydb=# select oid, relfilenode from pg_class where relname = 'users'; oid | relfilenode -------+------------- 16434 | 16434 (1 row) mydb-# \! ls -l /var/lib/pgsql/12/data/base/16384/16434 -rw------- 1 postgres postgres 8192 Jul 2 15:26 /var/lib/pgsql/12/data/base/16384/16434
mydb=# truncate users; mydb=# checkpoint; mydb=# \! ls -l /var/lib/pgsql/12/data/base/16384/16434 ls: cannot access /var/lib/pgsql/12/data/base/16384/16434: No such file or directory mydb=# select oid, relfilenode from pg_class where relname = 'users'; oid | relfilenode -------+------------- 16434 | 16479 (1 row) mydb=# \! ls -l /var/lib/pgsql/12/data/base/16384/16479 -rw------- 1 postgres postgres 0 Jul 8 17:08 /var/lib/pgsql/12/data/base/16384/16479

As mentioned earlier, the naming rule of the data file is, < sequence number >, the size of the tbl table exceeds 1GB, the relfilenode of the tbl table is 24591, and the data beyond 1GB will be cut per GB. When viewed in the file system, it is the data file named 24591.1. In the above output resu lt s, the suffix is_ fsm and_ The attached files of these two table files of vm are free space mapping table file and visibility mapping table file.
-
Free space mapping is used to map the available space in the table file;
-
The visibility mapping table file tracks which pages contain only tuples known to be visible to all active transactions, and it also tracks which pages contain only unfrozen tuples.
Structure overview of PostgreSQL data directory, tablespace and file:
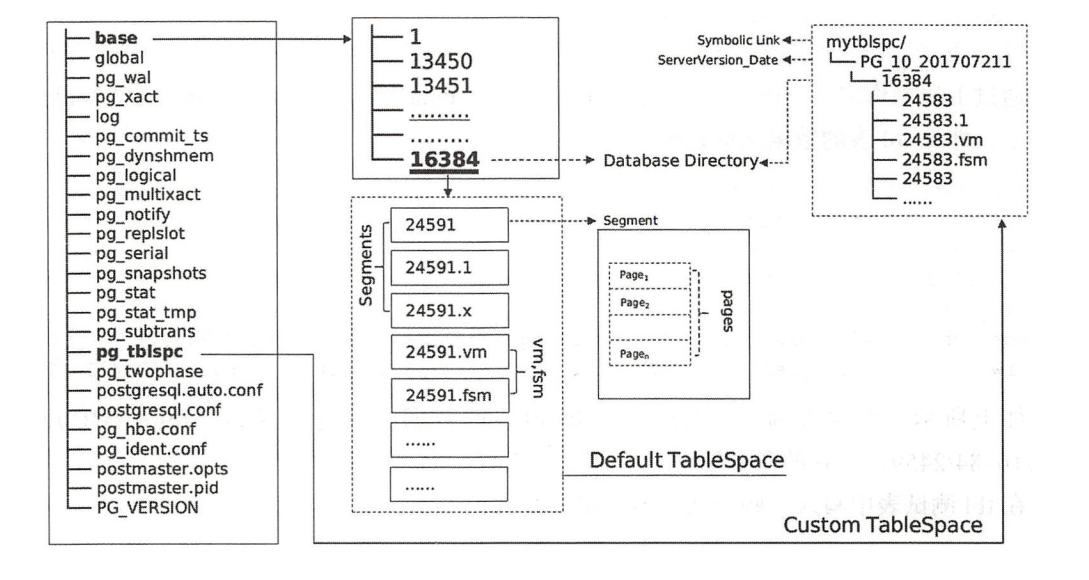
- Internal structure of bid documents:
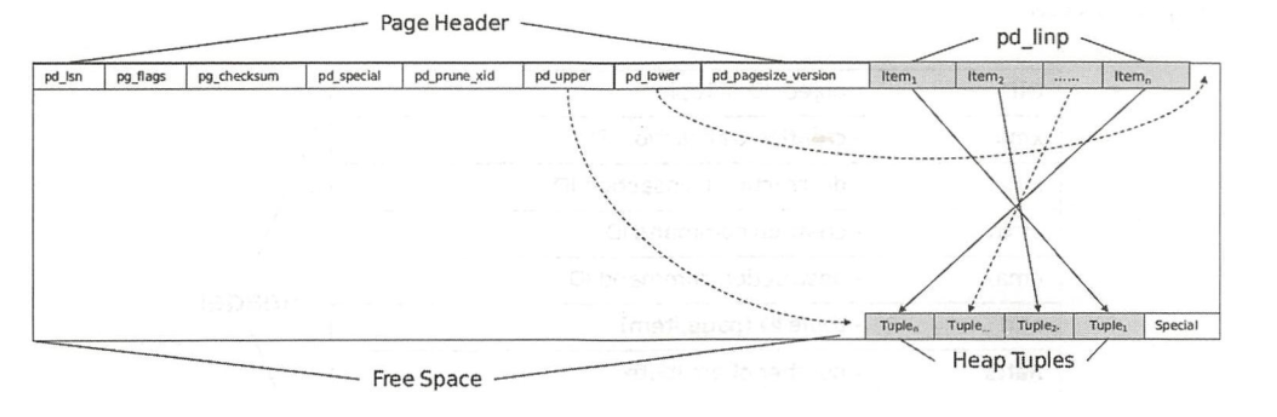
In PostgreSQL, blocks saved on disk are called pages, blocks in memory are called buffers, tables and indexes are called relations, and rows are called tuples, as shown in Figure 5-3. Data is read and written with Page as the minimum unit. The default size of each Page is 8kB. The BLCKSZ size specified when compiling PostgreSQL determines the size of the Page. Each table file consists of multiple BLCKSZ byte pages, and each Page contains several tuples. For the hardware with good I/O performance and the database based on analysis, appropriately increasing the size of BLCKSZ can slightly improve the database performance.
page internal structure
3. Process structure
3.1 daemon & service process
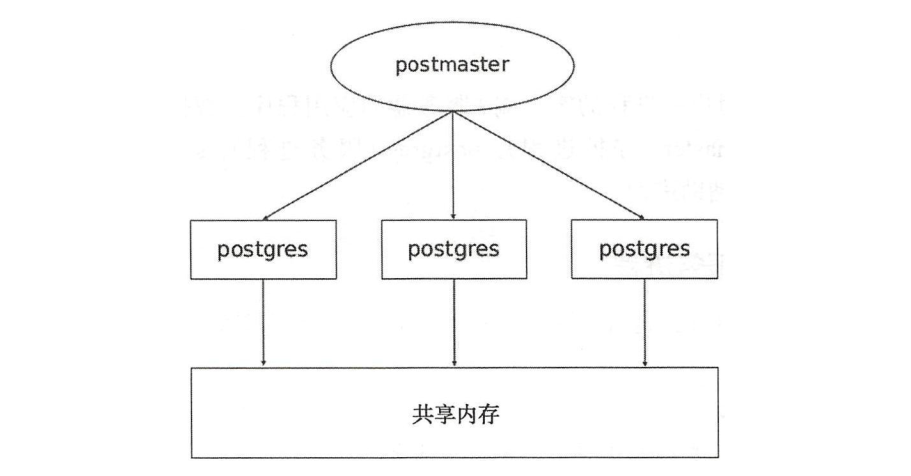
PostgreSQL is a client / server application with one user and one process. When the database is started, several processes will be started, including postmaster (daemon), Postgres (service process), syslogger, checkpoint, bgwriter, walwriter and other auxiliary processes.
postmaster responsibilities:
- Start and stop of database.
- Listen for client connections.
- fork a separate postgres service process for each client connection. Repair when the service process fails.
- Manage data files.
- Manage worker processes related to database operation.
When the client invokes the interface library to initiate a connection request to the database, the daemon postmaster will fork a separate service process postgres to provide services for the client. Thereafter, the postgres process will execute various commands for the client. The client does not need postmaster transfer, and communicates directly with the service process postgres until the client disconnects.
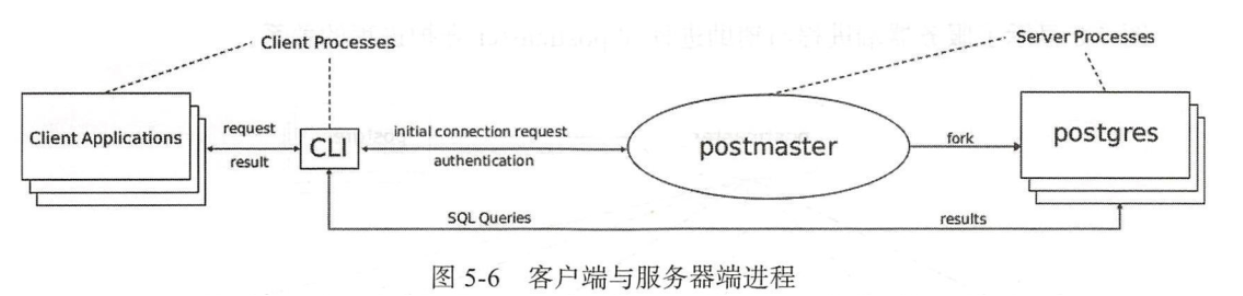
PostgreSQL uses a message based protocol for communication between the front end and the back end (server and client). Communication is carried out through a message flow. The first byte of the message identifies the message type, followed by four bytes that declare the length of the rest of the message. This protocol is implemented on TCP/IP and Unix domain sockets. Server jobs communicate with each other through signals and shared memory to ensure data integrity during concurrent access.
3.2 auxiliary process
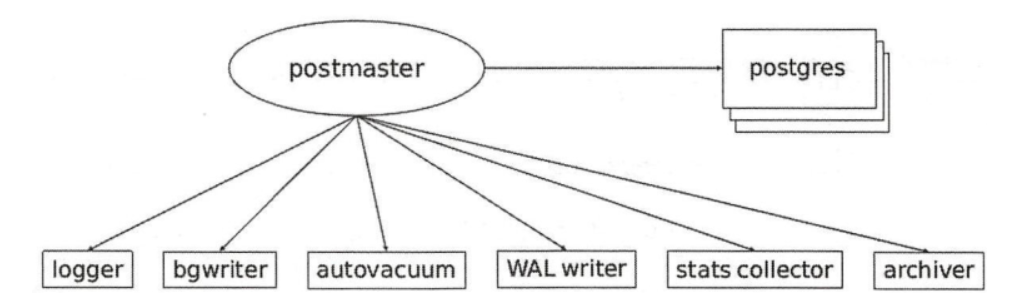
In addition to the daemon postmaster and the service process postgres, PostgreSQL requires some auxiliary processes to work during operation, including:
- background writer: it can also be called the bgwriter process. The bgwriter process is often in sleep. After waking up each time, it will search the shared buffer pool to find the modified pages and brush them out of the shared buffer pool.
- autovacuum launcher: automatically clean up the garbage collection process.
- WAL writer: periodically writes WAL data on the WAL buffer to disk. statistics collector: statistics collection process.
- logging collector: a logging process that writes messages or error information to the log. archiver: WAL archiving process.
- Checkpoint: checkpoint process.
Relationship between server-side process and worker process and postmaster daemon:
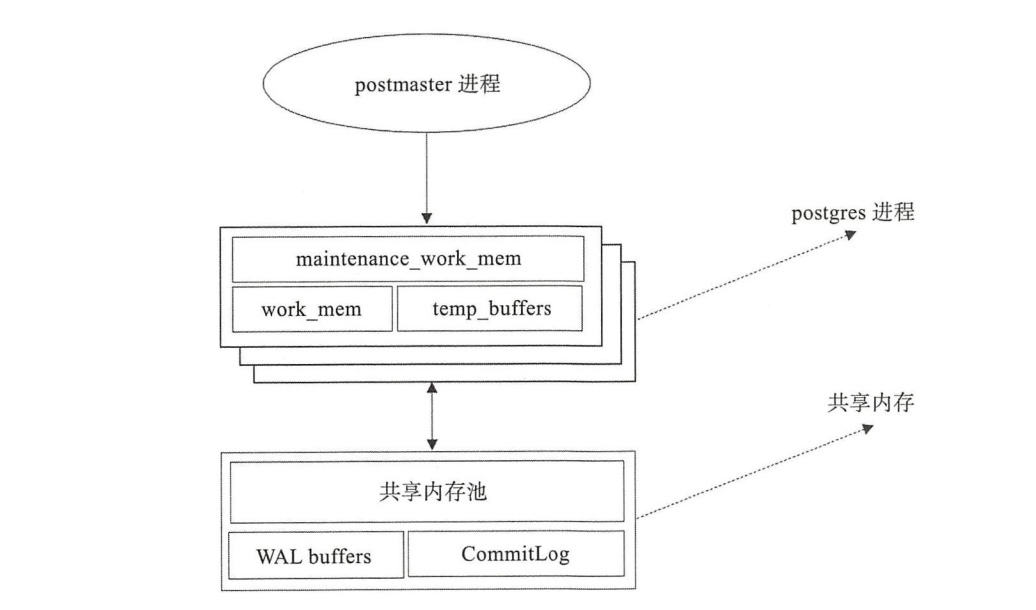
4. Memory structure
PostgreSQL memory is divided into two categories: local memory and shared memory, and some memory allocated for auxiliary processes.
4.1 local memory
Local memory is allocated by each back-end service process for its own use. When the back-end service process is fork ed, each back-end process allocates a local memory area for the query. The local memory consists of three parts: work_mem,maintwork_mem and temp_buffers.
- work mem: this part of memory is used when sorting tuples using the order by or DISTINCT operation.
- VACUUM, REINDEX, CREATE IND and other operations use this memory.
- temp_buffers: temporary table related operations use this part of memory.
4.2 shared memory
Shared memory is allocated when the PostgreSQL server starts and is used by all back-end processes. Shared memory is mainly composed of three parts:
- Shared buffer pool: PostgreSQL loads pages in tables and indexes from persistent storage and operates on them directly.
- Wal buffer: the buffer before the wal file is persisted.
- Commitlog buffer: PostgreSQL saves the state of transactions in the Commit Log and keeps these states in the shared memory buffer for use during the whole transaction processing.
Memory structure: