1, BRIN index principle
In this article, we will continue to learn another characteristic index in Postgresql - BRIN index. BRIN index is the abbreviation of Block Range Index. It groups the blocks of data on the disk according to a certain number, which can be determined by the parameter pages when creating BRIN_ per_ Range. The default value is 128. After grouping, calculate the value range of each group. When searching for data, it will traverse these value ranges and exclude groups that are not within the range.
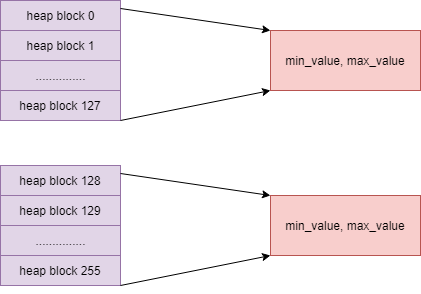
Unlike other indexes:
(1) BTree and other indexes locate the data row according to the data when looking for data, while BRIN index excludes the data blocks that are no longer in the range. Once the data block range containing the target data is found, the corresponding data row is obtained by bitmap scanning.
(2) Because BRIN is a combination of adjacent disk blocks, it is suitable for indexing data columns with linear growth in value, and the data rows should not be deleted frequently, otherwise the indexes may be rebuilt frequently due to the deletion operation.
(3) BRIN consolidates disk blocks according to a certain number, so the occupied space is smaller than that of BTree. However, due to the elimination of data by traversal, the performance is bound to be worse than that of BTree.
Next, the author combines examples to verify these characteristics of BRIN index.
2, BRIN index and BTree index space comparison
First, we verify the difference in storage space between BRIN index and BTree index. Before that, we still need to create two test tables t1 and t2. Except for the table name and index type, the other two tables are exactly the same, and 1000W pieces of data are inserted into them.
Establish t1 and t2 respectively:
stock_analysis_data=# create table t1 (id serial,name varchar(32)); CREATE TABLE stock_analysis_data=# create table t2 (id serial,name varchar(32)); CREATE TABLE
Insert 1000W pieces of data into tables t1 and t2 respectively:
stock_analysis_data=# insert into t1 (name) select 't1'||t.d from generate_series(1,10000000) as t(d); INSERT 0 10000000 stock_analysis_data=# insert into t2 (name) select 't2'||t.d from generate_series(1,10000000) as t(d); INSERT 0 10000000
Create BTree index in id field of t1:
stock_analysis_data=# create index t1_id_btree_inx on t1 using btree(id); CREATE INDEX Time: 13437.652 ms (00:13.438)
We can see that for 1000W data, the establishment process took 13 seconds. Then create the BRIN index on the t2 table, first according to the default pages_per_range (128):
stock_analysis_data=# create index t2_id_brin_inx on t2 using brin(id); CREATE INDEX Time: 5037.331 ms (00:05.037)
In terms of the time taken to establish the index, it is less than the BTree index. It takes only 5 seconds for 1000W data to establish the BRIN index. Let's look at the size of the next two indexes:
stock_analysis_data=# select relname,pg_size_pretty(pg_relation_size(oid)) from pg_class where relname ='t1_id_btree_inx';
relname | pg_size_pretty
-----------------+----------------
t1_id_btree_inx | 214 MB
(1 row)
Time: 0.896 msstock_analysis_data=# select relname,pg_size_pretty(pg_relation_size(oid)) from pg_class where relname ='t2_id_brin_inx';
relname | pg_size_pretty
----------------+----------------
t2_id_brin_inx | 32 kB
(1 row)
Time: 0.557 msYou can see that the BRIN index is 7000 times smaller than the BTree index. Let's try to set a smaller page when creating the BRIN index_ per_ range:
stock_analysis_data=# create index t2_id_brin_inx on t2 using brin(id) WITH (pages_per_range=64, autosummarize=on); CREATE INDEX
Put pages_ per_ Set the range to 64, that is, now set 64 disk leaves as a group. Check the size of the BRIN index at this time, and you will find that the space occupied by the whole index is indeed larger than before.
stock_analysis_data=# select relname,pg_size_pretty(pg_relation_size(oid)) from pg_class where relname ='t2_id_brin_inx';
relname | pg_size_pretty
----------------+----------------
t2_id_brin_inx | 40 kB
(1 row)3, Comparison of query performance between BRIN index and BTree index
Above, we compare the space occupied by the BRIN index and BTree index. Next, we compare the query performance of the following two. First, query the data with id 100W from the t1 table:
stock_analysis_data=# explain(analyze,verbose,costs,timing) select * from t1 where id=1000000;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Index Scan using t1_id_btree_inx on public.t1 (cost=0.43..8.45 rows=1 width=13) (actual time=0.026..0.028 rows=1 loops=1)
Output: id, name
Index Cond: (t1.id = 1000000)
Planning Time: 0.096 ms
Execution Time: 0.059 ms
(5 rows)Then, use the BRIN index to query the data with id 100W from table t2:
stock_analysis_data=# explain(analyze,verbose,costs,timing) select * from t2 where id=1000000;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on public.t2 (cost=20.02..28620.29 rows=1 width=13) (actual time=16.657..26.042 rows=1 loops=1)
Output: id, name
Recheck Cond: (t2.id = 1000000)
Rows Removed by Index Recheck: 11839
Heap Blocks: lossy=64
-> Bitmap Index Scan on t2_id_brin_inx (cost=0.00..20.02 rows=11834 width=0) (actual time=0.247..0.247 rows=640 loops=1)
Index Cond: (t2.id = 1000000)
Planning Time: 0.135 ms
Execution Time: 26.076 ms
(9 rows)It can be seen that the BRIN index is indeed inferior to the BTree index in terms of query efficiency.
4, Summary
To sum up, we can draw the following conclusions:
(1) BRIN index groups disk blocks and traverses and excludes groups that do not contain target data during query. The number of blocks in each group can be set through the parameter pages_per_range when creating BRIN index.
(2) BRIN index is suitable for columns with linear growth of values, such as sequential record type data, and data cannot be deleted frequently.
(3) Compared with BTree index, BRIN index saves a lot of storage space, but the query performance is inferior to the latter. In order to save storage cost when processing large data, BRIN index can be considered.