Official account: Special House
Author: Peter
Editor: Peter
Hello, I'm Peter~
Before, when the crawler parsed the data, it almost used the regular expression re module to parse the data. Regular parsing data is indeed very powerful, but the expression is very troublesome and sometimes needs to be tried many times; And the speed is relatively slow. I will write a special article on Python regular in the future.
This article describes how to get started quickly with another data parsing tool: Xpath.
Introduction to Xpath
XPath (XML Path) is a language for finding information in XML documents. XPath can be used to traverse elements and attributes in XML documents.
XPath is a major element of the W3C XSLT standard, and both XQuery and XPointer are built on XPath expressions.
- Xpath is a query language
- Look for nodes in the tree structure of XML (Extensible Markup Language) and HTML
- XPATH is a language that 'looks for people' based on 'address'
Quick start website: https://www.w3schools.com/xml/default.asp
Xpath installation
Installation in MacOS is very simple:
pip install lxml
The installation in Linux takes Ubuntu as an example:
sudo apt-get install python-lxml
Please Baidu yourself for the installation in Windows. There will certainly be a tutorial, but the process will be more troublesome.
How do I verify that the installation is successful? No error is reported in the command line when importing lxml, which means the installation is successful!

Xpath parsing principle
- Instantiate an etree parsing object, and load the parsed page source code data into the object
- Call the xpath parsing method in xpath and combine the xpath expression to locate the tag and capture the content
How to instantiate etree objects?
- Load the source data in the local html document into the etree object: etree parse(filePath)
- Load the source code data obtained on the Internet into the object: etree HTML ('page_text '), where page_ Text refers to the source code content we obtained
Xpath usage
3 special symbols
- /: indicates that the resolution starts from the root node, and it is a single level, positioning step by step
- //: indicates multiple levels, and some of them can be skipped; It also means positioning from any position
- .: a point indicates the current node
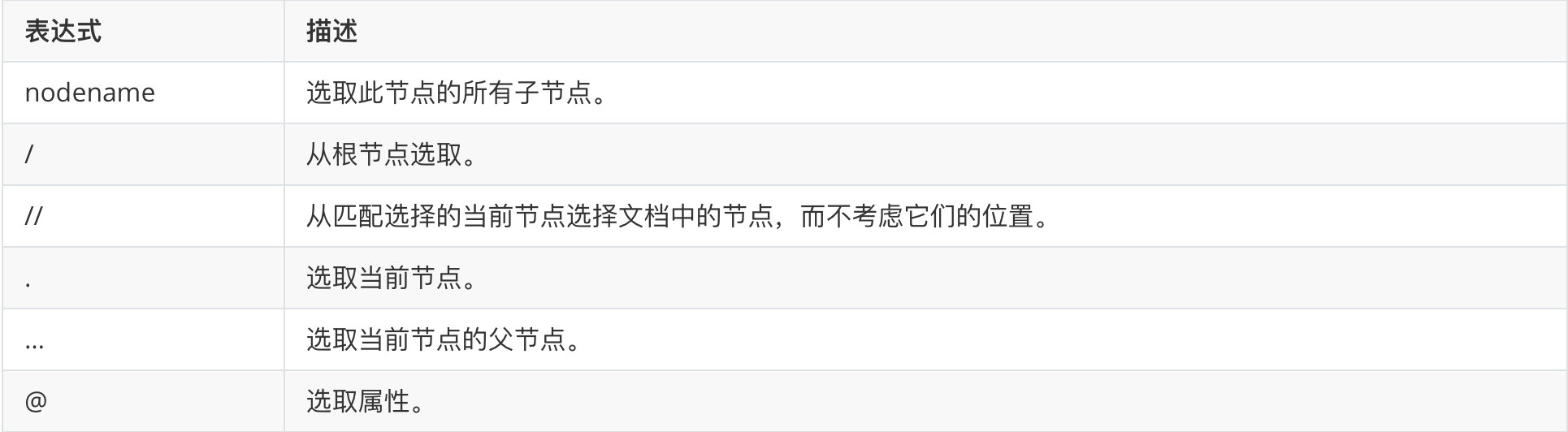
Common path expressions
The following is a common Xpath path expression:
give an example
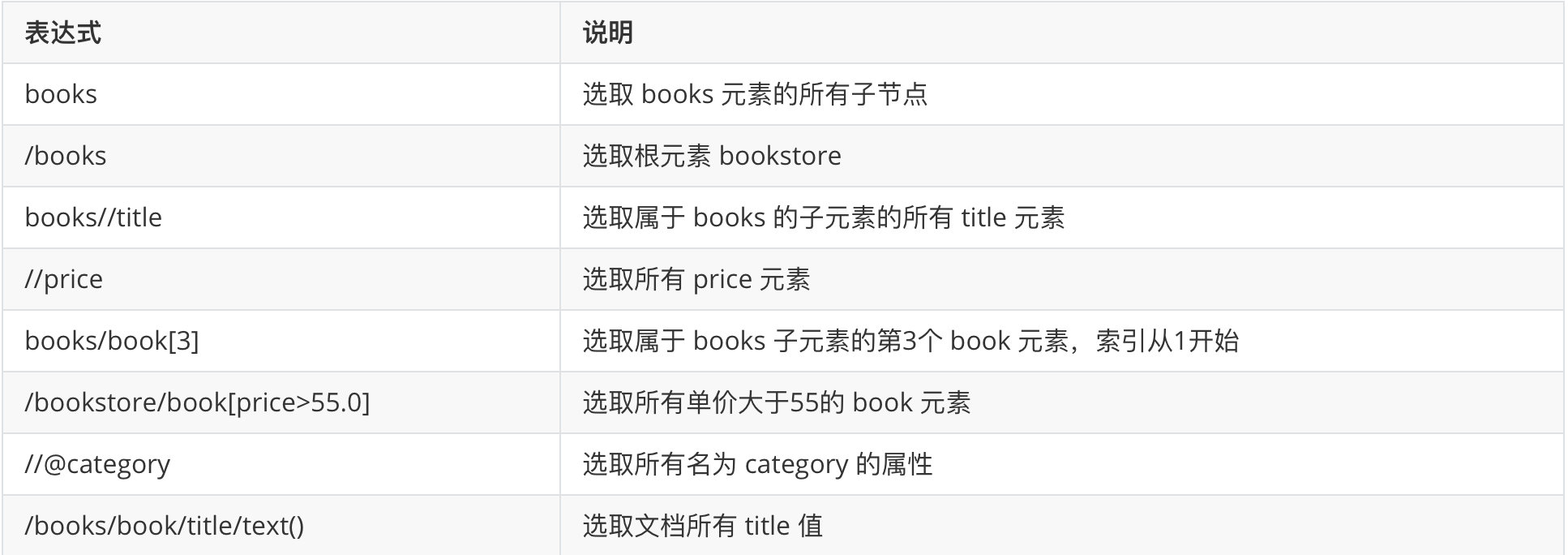
Xpath operator
Operators are directly supported in Xpath expressions:
HTML Element
Because the data parsed by Xpath are basically structured data related to HTML elements, the following introduces a very basic knowledge of HTML.
HTML elements refer to all code from the start tag to the end tag. Basic syntax:
- HTML elements start with the start tag; HTML elements terminate with end tags
- The content of the element is the content between the start tag and the end tag
- Some HTML elements have empty content
- Empty elements are closed in the start tag (ending at the end of the start tag)
- Most HTML elements can have attributes; Attributes are recommended in lowercase
About the use of empty elements: adding slashes in the start tag, such as < br / >, is the correct way to close empty elements. HTML, XHTML and XML all accept this method.
Common properties

| attribute | value | describe |
|---|---|---|
| class | classname | Specifies the class name of the element |
| id | id | Specifies the unique id of the element |
| style | style_definition | Specifies the inline style of the element |
| title | text | Additional information specifying the element (can be displayed in tooltips) |
HTML title
There are 6 levels of titles in HTML.
Heading is defined by tags such as < H1 > - < H6 >.
<h1>Define the largest title, < H6 > define the smallest title.
Original data
Before using Xpath to parse the data, we need to import the data and instantiate an etree object at the same time:
# Import library
from lxml import etree
# Instantiate resolution object
tree = etree.parse("test.html")
tree
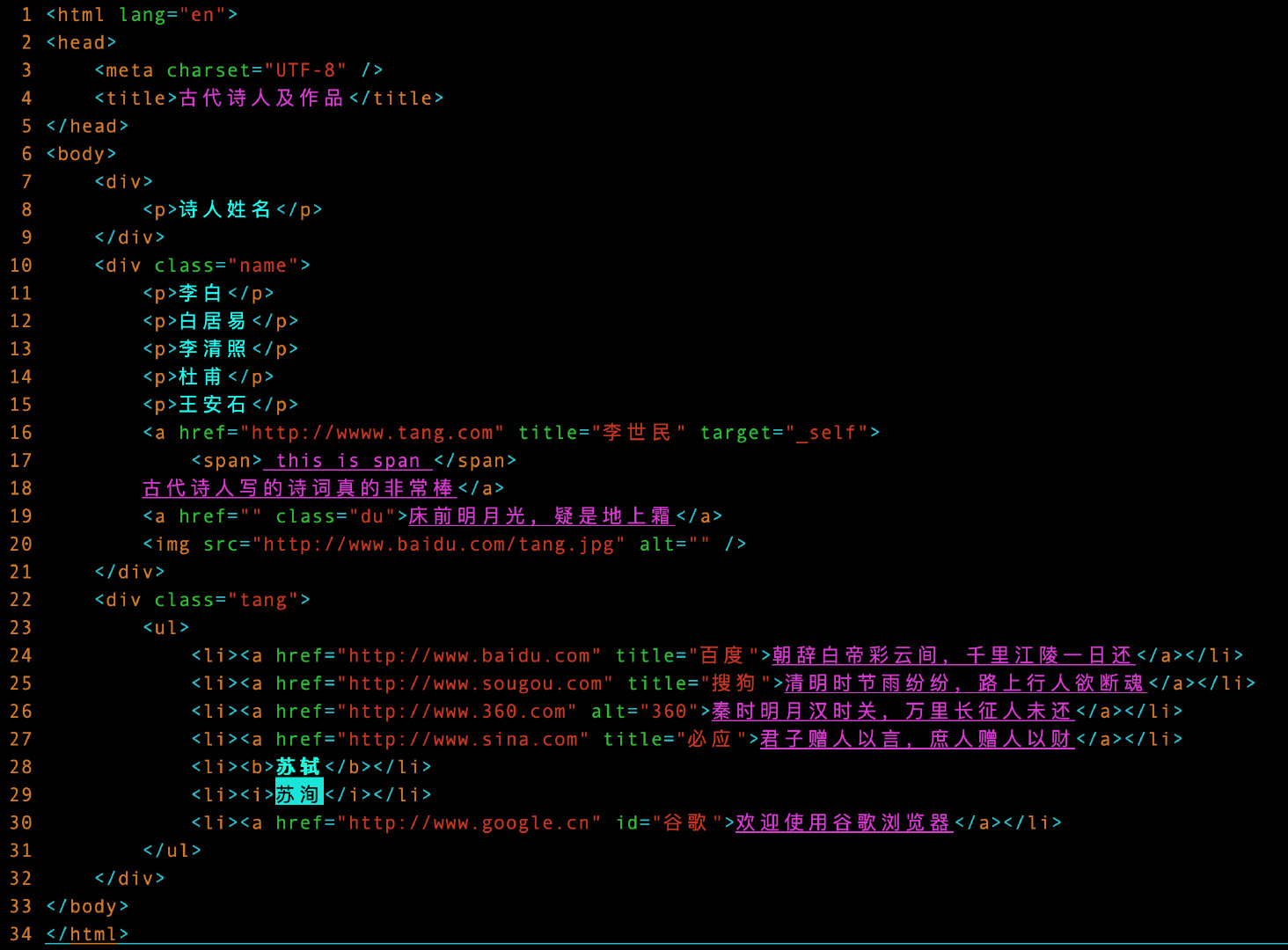
The following is the original data to be parsed: test html:
<html lang="en"> <head> <meta charset="utf-8" /> <title>Ancient poets and works</title> </head> <body> <div> <p>Poet's name</p> </div> <div class="name"> <p>Li Bai</p> <p>Bai Juyi</p> <p>Li Qingzhao</p> <p>Du Fu</p> <p>Wang Anshi</p> <a href="http://wwww. tang. com" target="_ Self "title =" Li Shimin "> <span> this is span </span> The poems written by ancient poets are really great</a> <a class="du" href="">The bright moon in front of the bed is suspected to be frost on the ground</a> <img alt="" src="http://www.baidu.com/tang.jpg" /> </div> <div class="tang"> <ul> <li><a href="http://www.baidu. Com "title =" Baidu "> farewell to the White Emperor, between the clouds, thousands of miles of Jiangling will return in one day</a></li> <li><a href="http://www.sougou. Com "title =" Sogou "> during the Qingming Festival, it rains in succession, and pedestrians on the road want to break their souls</a></li> <li><a alt="360" href="http://www.360. Com "> in the Qin Dynasty, the moon was bright and the Han Dynasty was closed, and the people on the long march had not returned</a></li> <li><a href="http://www.sina. Com "title =" Bing "> a gentleman gives words to others, while a commoner gives money to others</a></li> <li><b>Su Shi</b></li> <li><i>Su Xun</i></li> <li><a href="http://www.google. Cn "id =" Google "> welcome to Google browser</a></li> </ul> </div> </body> </html>
Get single label content
For example, you want to get the content in the title tag: ancient poets and works

title = tree.xpath("/html/head/title")
title

Through the above results, it is found that the result of each Xpath parsing is a list
If you want to get the text content in the label, use text():
# Extract the corresponding content from the list
title = tree.xpath("/html/head/title/text()")[0] # Index 0 means to get the first element value
title

Get multiple contents in the tag
For example, we want to get the contents of div tags. There are three pairs of div tags in the original data. The result is that the list contains three elements:
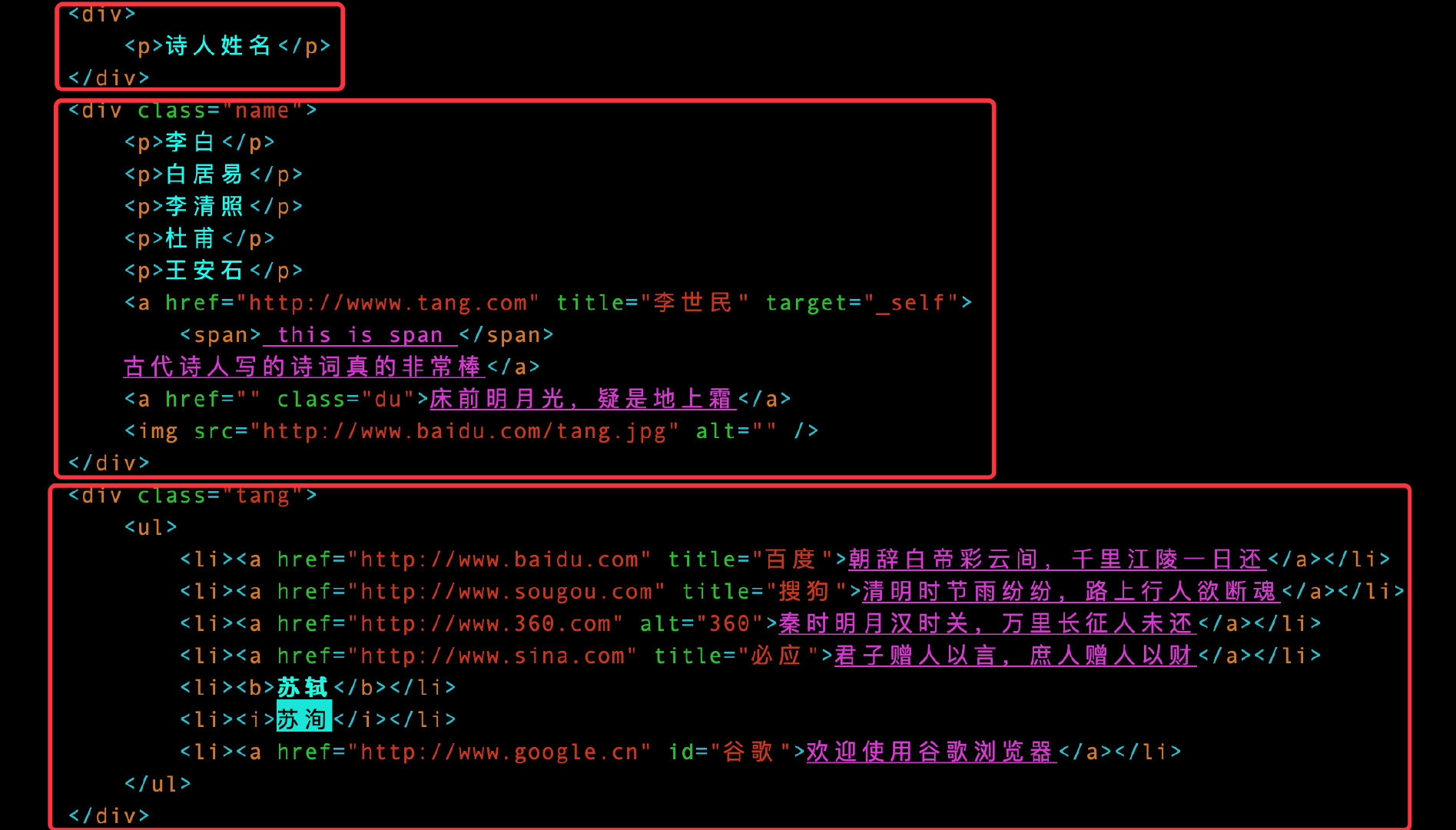
1. Use single slash /: indicates that the root node html starts positioning, indicating a level
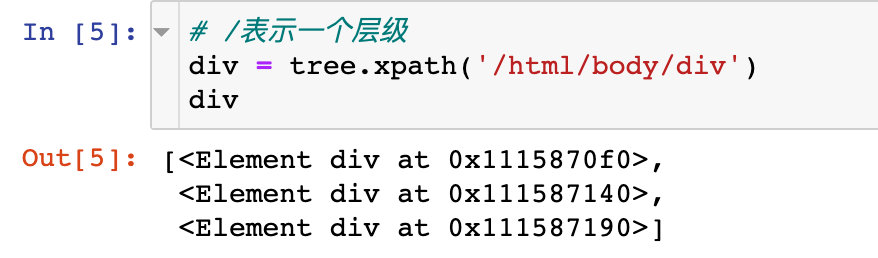
2. Use double slash / / in the middle: it means skipping the middle level and multiple levels
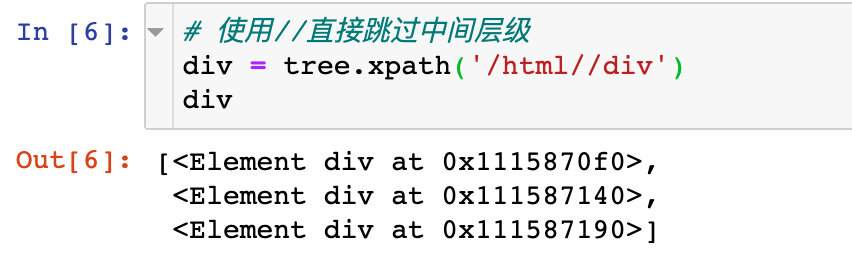
3. Double slash / / at the beginning: indicates starting from any position

Attribute positioning
When using attribute positioning, directly follow the label [@ attribute name = "attribute value"):
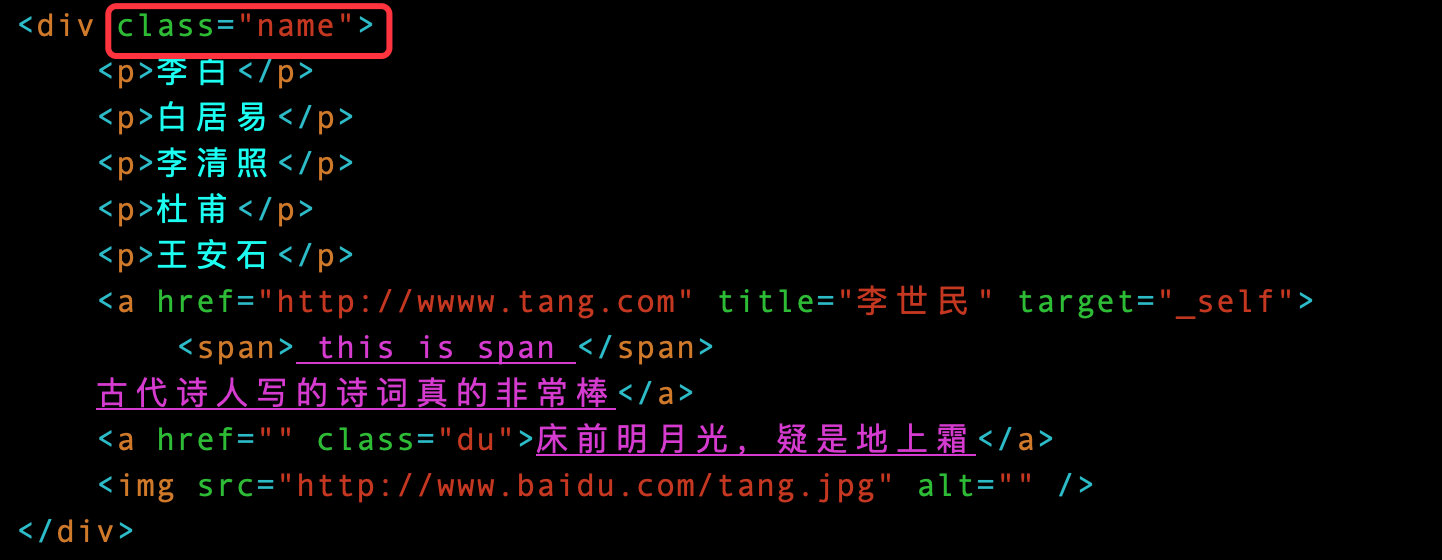
name = tree.xpath('//div[@class="name"]) # locate the class attribute, and the value is name
name

Index location
The index in Xpath starts from 1, which is different from the index in python starting from 0. For example, if you want to locate all the p tags under the class attribute (the value is name) under the div tag: 5 pairs of p tags, the result should be 5 elements
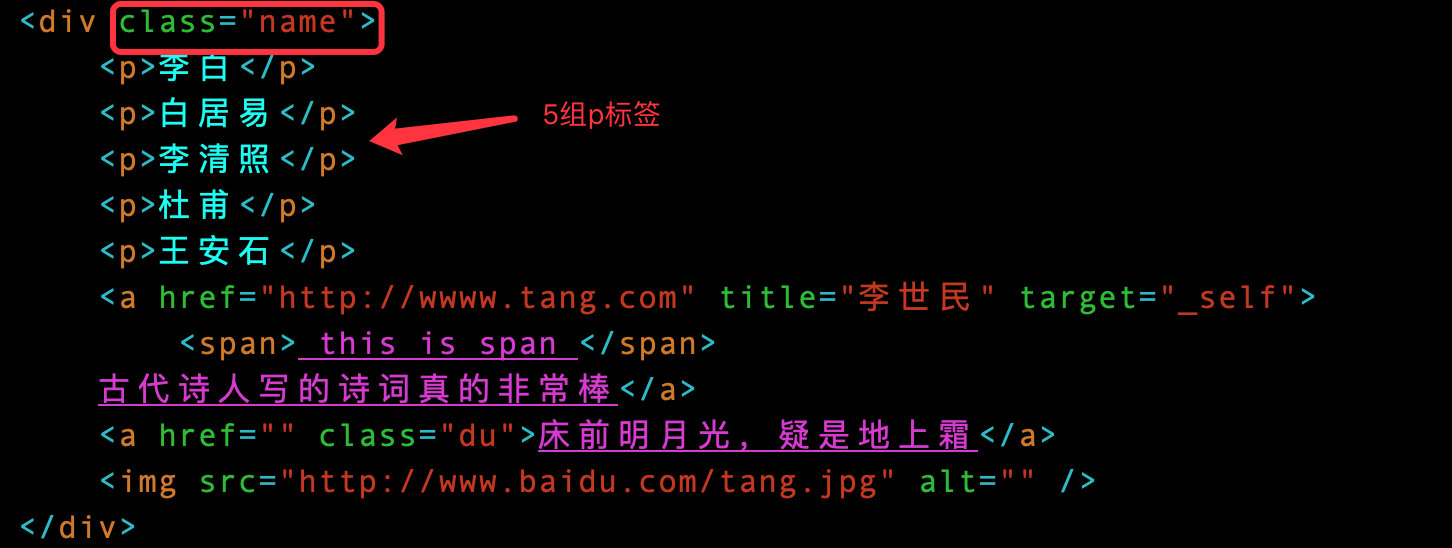
# Get all data
index = tree.xpath('//div[@class="name"]/p')
index
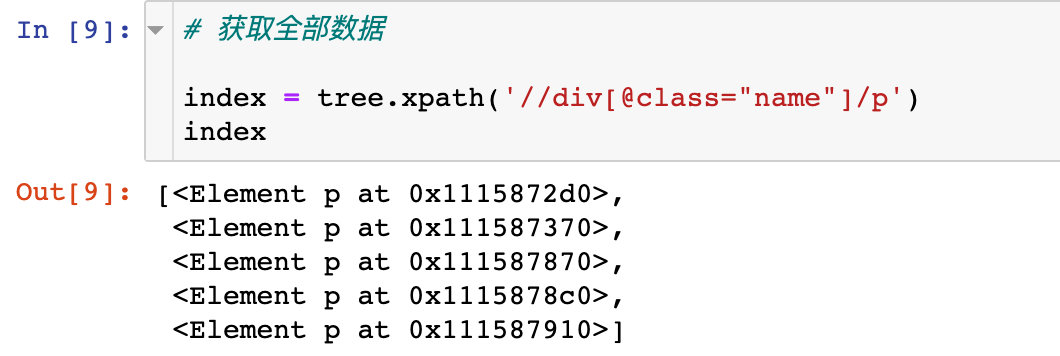
If we want to get the third p tag:
# Get single specified data: index starts at 1
index = tree.xpath('//div[@class="name"]/p[3] '# index starts from 1
index

Get text content
The first method: text() method
1. Get the elements below a specific tag:
# 1. /: single level
class_text = tree.xpath('//div[@class="tang"]/ul/li/b/text()')
class_text
# 2. / /: multiple levels
class_text = tree.xpath('//div[@class="tang"]//b/text()')
class_text

2. Multiple contents under a label
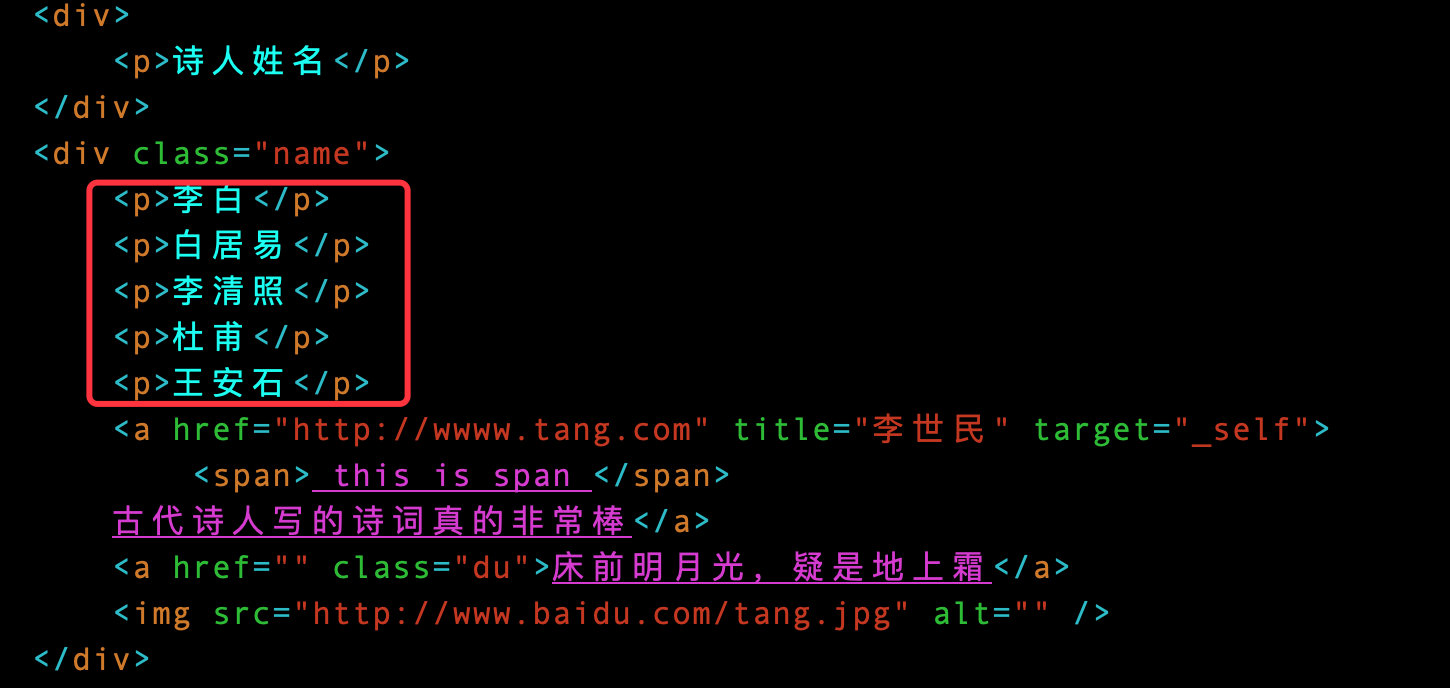
For example, if you want to get all the contents under the p tag:
# Get all data
p_text = tree.xpath('//div[@class="name"]/p/text()')
p_text

For example, if you want to get the content below the third p tag:
# Get the third label content
p_text = tree.xpath('//div[@class="name"]/p[3]/text()')
p_text
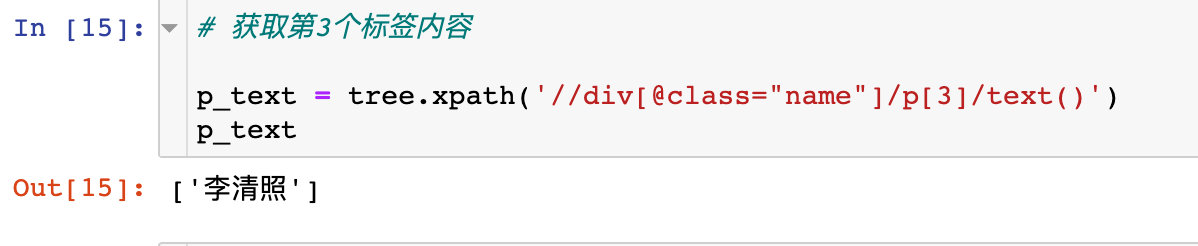
If you first get all the contents in the p tag, the result is a list, and then use the python index to get it. Note that the index is 2:

Acquisition of non label direct content:

Acquisition of tag direct content: the result is empty, and there is no content in the direct li tag

If you want to get all the contents of the li tag, you can combine the following a, b and i tags and use vertical lines|
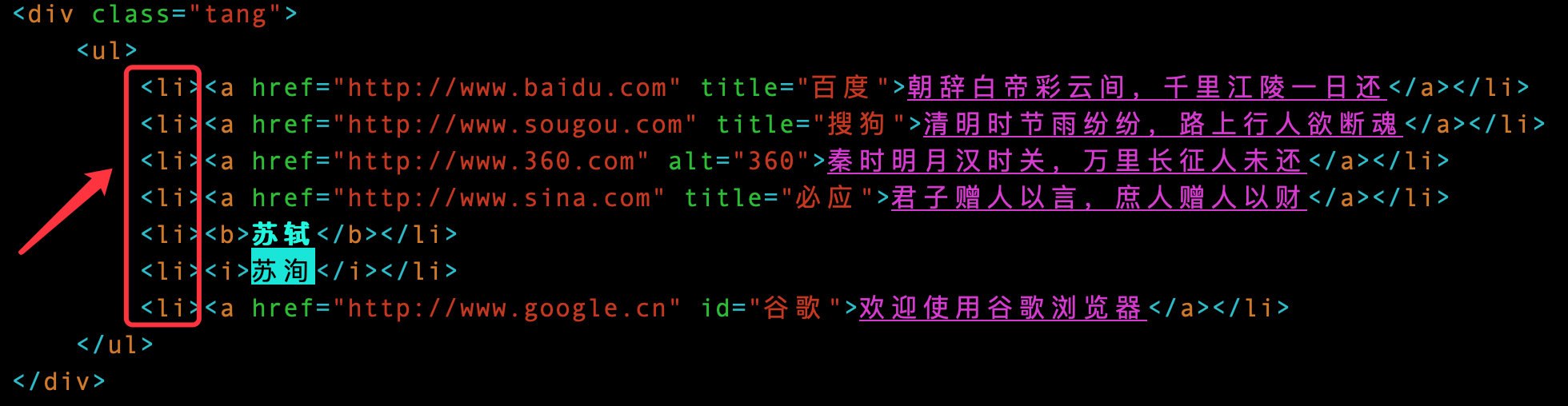
# At the same time, get the contents of a/b/i tag under li tag, which is equivalent to all the contents of li tag
abi_text = tree.xpath('//div[@class="tang"]//li/a/text() | //div[@class="tang"]//li/b/text() | //div[@class="tang"]//li/i/text()')
abi_text

Direct and indirect understanding
- Direct: indicates to obtain the text content of the first level under the label
- Indirect: it means to obtain the text content of all levels below the label

Get attribute content
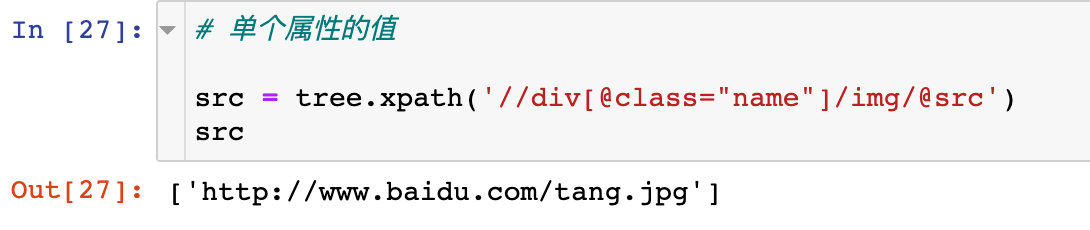
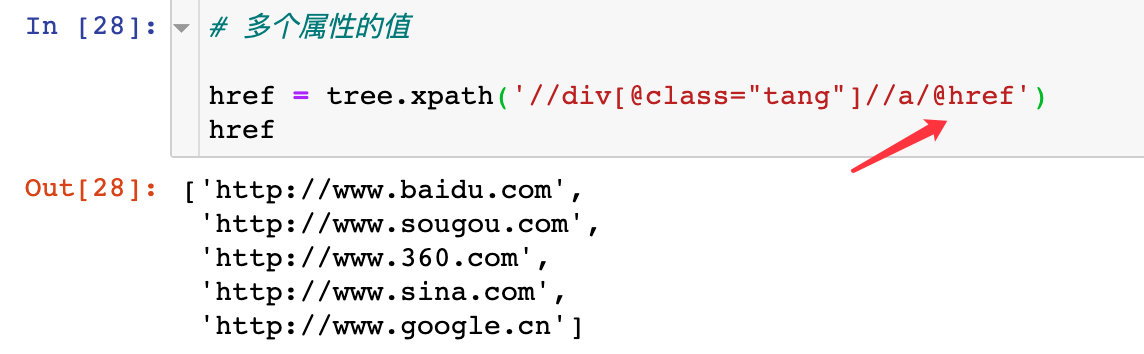
If you want to get the value of the attribute, add: @ + attribute name to the final expression to get the value of the corresponding attribute
1. Gets the value of a single property

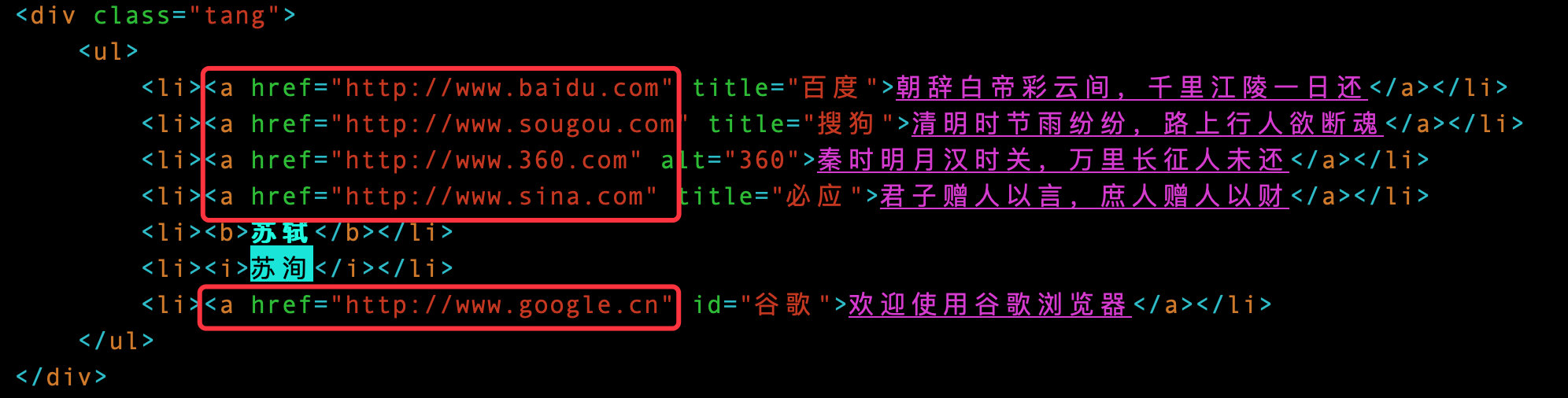
2. Gets multiple values of a property
actual combat
Use Xpath to obtain all the novel name s and URL addresses of Gu Long on a novel website. Introduction to Gu Long:
His real name is Xiong Yaohua, from Jiangxi; Taiwan's Tamkang English College (the predecessor of Tamkang University) graduated (i.e. studied as an undergraduate). Hemingway's novels are generally inspired by the western novels of Jack, George W. Steinbeck and even George W. Steinbeck. (Gulong himself said, "I like to steal tricks from modern Japanese and western novels." Therefore, it can be renewed day by day, catch up from behind, and don't open a new realm of martial arts novels.
Web page analysis
The crawled information is on this website: https://www.kanunu8.com/zj/10867.html , the following figure shows the names of all the novels:

By looking at the source code of the web page, we find that the name and URL address are all in the following tags:
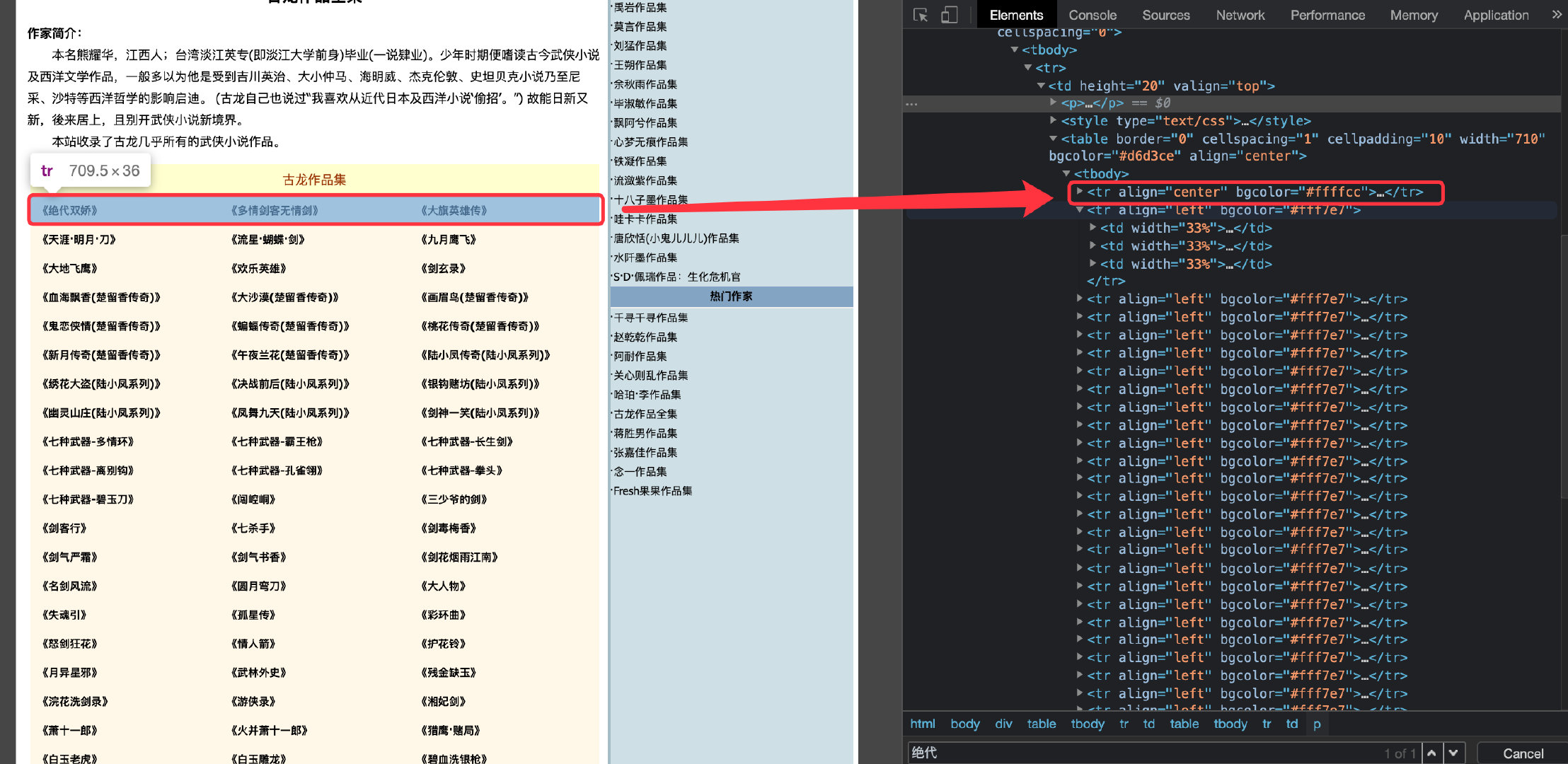
There are three td tags under each tr tag, representing three novels, and one td contains the address and name
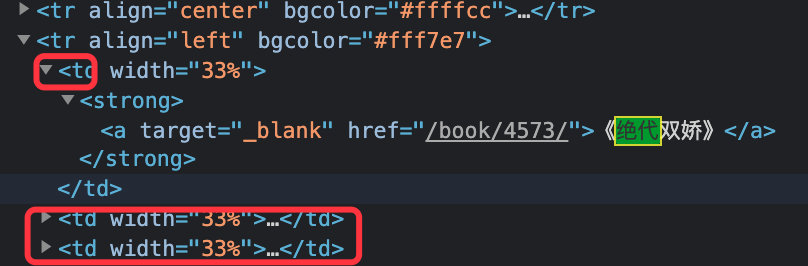
When we click on a specific novel, such as "peerless double pride", we can go to the specific chapter page of the novel:

Get web source code
Send a web page request to get the source code
import requests
from lxml import etree
import pandas as pd
url = 'https://www.kanunu8.com/zj/10867.html'
headers = {'user-agent': 'Request header'}
response = requests.get(url = url,headers = headers)
result = response.content.decode('gbk') # The web page needs to parse the data through gbk coding
result

pick up information
1. Get the exclusive link address of each novel
tree = etree.HTML(result)
href_list = tree.xpath('//tbody/tr//a/@href ') # specifies the information of the attribute
href_list[:5]

2. Get the name of each novel
name_list = tree.xpath('//tbody/tr//a/text() '# specifies the entire content under the label
name_list[:5]

3. Generate data frame
# Address and name of the novel generated by Gulong
gulong = pd.DataFrame({
"name":name_list,
"url":href_list
})
gulong

4. Perfect URL address
In fact, the URL address of each novel has a prefix, such as the complete address of the peerless double pride: https://www.kanunu8.com/book/4573/ , the data we obtained above is only the last part. Prefix each URL address:
gulong['url'] = 'https://www.kanunu8. COM / book '+ Gulong ['url'] # plus public prefix
gulong
# Export as excel file
gulong.to_excel("gulong.xlsx",index=False)

summary
Here is a summary of the use of Xpath:
- //: indicates that the tag is not directly related to the content, and there is a cross level
- /: indicates that only the immediate content of the tag is obtained, and does not cross the level
- If the index is in the Xpath expression, the index starts from 1; If you get the list data from the Xpath expression and then use the python index to get the data, the index starts from 0