1. Introduction to beautiful soup

Beautiful soup is a python library that can extract data from HTML or XML files; It can realize the usual way of document navigation, searching and modifying through the converter.
Beautiful soup is a parsing library developed based on re, which can provide some powerful parsing functions; Using beautiful soup can improve the efficiency of data extraction and crawler development.
2. Web crawler
Basic process of crawler:

Initiate request:
Send a request to the target site through the HTTP library and wait for the response of the target site server.
Get response:
If the server responds normally, it will return a Response, which is the obtained page content. The Response can be HTML JSON String, binary data and other data types.
Parsing content:
utilize regular expression The web page parsing library parses HTML; Convert JSON data into JSON objects for parsing; Save the binary data we need (pictures, videos).
Save data:
The crawled and parsed content can be saved as text, or saved to the database, etc.
It was explained in the last article Requests Library , the two processes of initiating a request and obtaining a response in the web crawler have been completed, and the next content parsing will be completed by BeautifulSoup.
3. Overview of beautiful soup
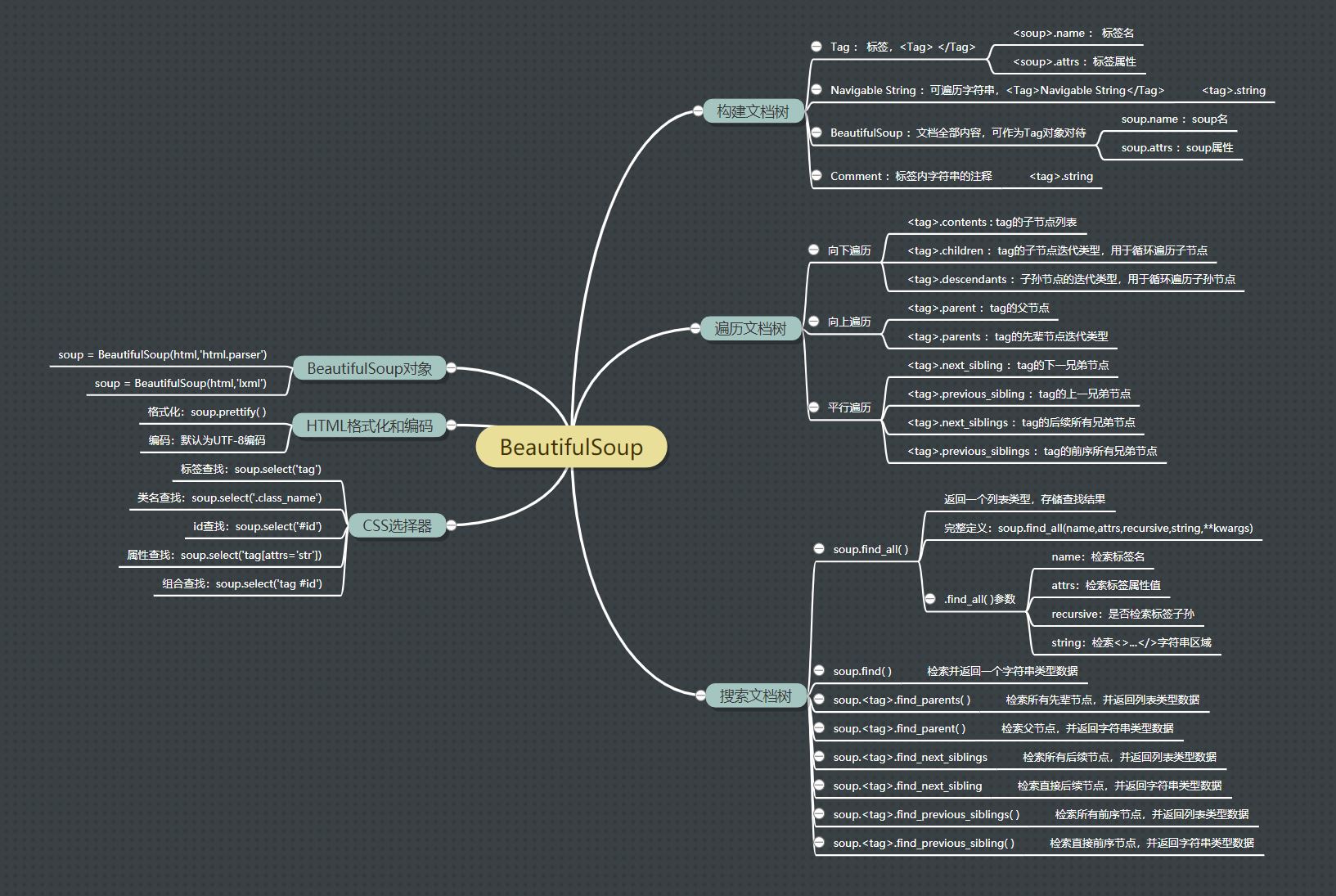
Build document tree
The document parsing of beautulsoup is based on the document tree structure, and the document tree is constructed from four data objects in beautulsoup.

| Document tree object | describe |
|---|---|
| Tag | label; Access method: soup tag; Attribute: tag Name, tag Attrs (tag attribute) |
| Navigable String | Traversable string; Access method: soup tag. string |
| BeautifulSoup | All contents of the document can be regarded as Tag objects; Attribute: soup Name (Tag name), soup Attrs (Tag attribute) |
| Comment | Comment on the string in the tag; Access method: soup tag. string |
import lxml import requests from bs4 import BeautifulSoup html = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1"><!--Elsie--></a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ #1. BeautifulSoup object soup = BeautifulSoup(html,'lxml') print(type(soup)) #2. Tag object print(soup.head,'\n') print(soup.head.name,'\n') print(soup.head.attrs,'\n') print(type(soup.head)) #3. Navigable String object print(soup.title.string,'\n') print(type(soup.title.string)) #4. Comment object print(soup.a.string,'\n') print(type(soup.a.string)) #5. Structured output soup object print(soup.prettify())
Traverse the document tree
The reason why beautiful soup turns the document into a tree structure is that the tree structure is more convenient for traversal and extraction of content.
| Downward traversal method | describe |
|---|---|
| tag.contents | tag child node |
| tag.children | Tag tag child node iteration type, which is used to cycle through child nodes |
| tag.descendants | Tag tag descendant node, which is used to cycle through descendant nodes |
| Upward traversal method | describe |
|---|---|
| tag.parent | Tag tag parent node |
| tag.parents | tag the iteration type of the predecessor node, which is used to loop through the predecessor nodes |
| Parallel traversal method | describe |
|---|---|
| tag.next_sibling | Tag tag next sibling node |
| tag.previous_sibling | A sibling node on the tag |
| tag.next_siblings | Tag tag all subsequent sibling nodes |
| tag.previous_siblings | All sibling nodes before tag |
import requests
import lxml
import json
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!--Elsie--></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html,'html.parser')
#1. Traversal down
print(soup.p.contents)
print(list(soup.p.children))
print(list(soup.p.descendants))
#2. Traversal up
print(soup.p.parent.name,'\n')
for i in soup.p.parents:
print(i.name)
#3. Parallel traversal
print('a_next:',soup.a.next_sibling)
for i in soup.a.next_siblings:
print('a_nexts:',i)
print('a_previous:',soup.a.previous_sibling)
for i in soup.a.previous_siblings:
print('a_previouss:',i)
Search document tree
Beautiful soup provides many search methods, which can easily get the content we need.
| traversal method | describe |
|---|---|
| soup.find_all( ) | Find all qualified tags and return list data |
| soup.find | Find the first tag that meets the conditions and return string data |
| soup.tag.find_parents() | Retrieve all previous nodes of tag tag and return list data |
| soup.tag.find_parent() | Retrieve the parent node of tag tag and return string data |
| soup.tag.find_next_siblings() | Retrieve all subsequent nodes of tag tag and return list data |
| soup.tag.find_next_sibling() | Retrieve the next node of tag tag and return string data |
| soup.tag.find_previous_siblings() | Retrieve all pre order nodes of tag tag and return list data |
| soup.tag.find_previous_sibling() | Retrieve the previous node on the tag tag and return string data |
import requests
import lxml
import json
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!--Elsie--></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html,'html.parser')
#1,find_all( )
print(soup.find_all('a')) #Retrieve tag name
print(soup.find_all('a',id='link1')) #Retrieve property values
print(soup.find_all('a',class_='sister'))
print(soup.find_all(text=['Elsie','Lacie']))
#2,find( )
print(soup.find('a'))
print(soup.find(id='link2'))
#3. Search up
print(soup.p.find_parent().name)
for i in soup.title.find_parents():
print(i.name)
#4. Parallel retrieval
print(soup.head.find_next_sibling().name)
for i in soup.head.find_next_siblings():
print(i.name)
print(soup.title.find_previous_sibling())
for i in soup.title.find_previous_siblings():
print(i.name)
CSS selector
The beautiful soup selector supports most of the CSS selector , in the Tag or BeautifulSoup object By passing in the string parameter in the select() method, you can use the CSS selector to find the Tag.
Common HTML Tags:
HTML title:<h> </h> HTML Paragraph:<p> </p> HTML Link:<a href='httts://www.baidu.com/'> this is a link </a> HTML Image:<img src='Ai-code.jpg',width='104',height='144' /> HTML Form:<table> </table> HTML List:<ul> </ul> HTML Block:<div> </div>
import requests
import lxml
import json
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!--Elsie--></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html,'html.parser')
print('Label lookup:',soup.select('a'))
print('Attribute lookup:',soup.select('a[id="link1"]'))
print('Class name lookup:',soup.select('.sister'))
print('id lookup:',soup.select('#link1'))
print('Combined search:',soup.select('p #link1'))
Crawl image instance
import requests
from bs4 import BeautifulSoup
import os
def getUrl(url):
try:
read = requests.get(url)
read.raise_for_status()
read.encoding = read.apparent_encoding
return read.text
except:
return "Connection failed!"
def getPic(html):
soup = BeautifulSoup(html, "html.parser")
all_img = soup.find('ul').find_all('img')
for img in all_img:
src = img['src']
img_url = src
print(img_url)
root = "F:/Pic/"
path = root + img_url.split('/')[-1]
print(path)
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
read = requests.get(img_url)
with open(path, "wb")as f:
f.write(read.content)
f.close()
print("File saved successfully!")
else:
print("File already exists!")
except:
print("File crawling failed!")
if __name__ == '__main__':
html_url=getUrl("https://findicons.com/search/nature")
getPic(html_url)
Write at the end
Through the study of this article, we have mastered the knowledge of document parsing and its programming implementation, which brings great traversal for us to extract the required data by using crawlers.
