I have written about design patterns before< 23 design patterns of GoF using Go >However, after three articles in that series, I didn't continue, mainly because I couldn't find the appropriate sample code. Considering that if we take things close to life such as "whether ducks can fly" and "baking production process" as examples, it is difficult to make contact in our daily development. (there should be few software systems with these logic at present) Practicing 23 design patterns of GoF can be regarded as the restart of the series of 23 design patterns of GoF using Go. The lessons from the last unfinished work have been learned. The sample code implementation of 23 design patterns has been completed before writing this article. Different from last time, this sample code is implemented in Java, taking some technologies / problems / scenarios we often encounter in our daily development as the starting point to demonstrate how to use design patterns to complete relevant implementation.
preface
Twenty five years have passed since GoF proposed 23 design patterns in 1995. Design patterns are still a hot topic in the software field. Design patterns are usually defined as:
Design Pattern is a set of code design experience that is repeatedly used, known by most people, classified and catalogued. The purpose of using Design Pattern is to reuse code, make code easier to be understood by others and ensure code reliability.
From the definition, design pattern is actually a summary of experience and a concise and elegant solution to specific problems. Since it is a summary of experience, the most direct benefit of learning design patterns is that they can solve some specific problems in the process of software development on the shoulders of giants.
The highest level of learning design patterns is to understand their essential ideas, so that even if you have forgotten the name and structure of a design pattern, you can easily solve specific problems. The essential idea behind the design pattern is the well-known SOLID principle. If the design mode is compared to the martial arts moves in the martial arts world, the SOLID principle is internal skill and internal power. Generally speaking, practicing internal skills first and then learning moves will achieve twice the result with half the effort. Therefore, before introducing the design pattern, it is necessary to introduce the SOLID principle first.
This article will first introduce the overall structure of the sample code demo used in this series of articles, and then introduce the SOLID principle one by one, that is, the single responsibility principle, the opening and closing principle, the Richter substitution principle, the interface isolation principle and the dependency inversion principle.
A simple distributed application system
The sample code demo of this series is available at: https://github.com/ruanrunxue/Practice-Design-Pattern--Java-Implementation
The sample code demo project implements a simple distributed application system (stand-alone version), which is mainly composed of the following modules:
- Network, network function module, simulates and realizes the functions of message forwarding, socket communication, http communication and so on.
- Database Db, database function module, simulates and realizes the functions of table, transaction, dsl and so on.
- Message queue Mq, message queue module, simulates and implements the message queue of Producer / consumer based on topic.
- The monitoring system Monitor and the monitoring system module simulate the collection, analysis and storage of service logs.
- Sidecar, sidecar module, simulates the interception of network messages, and realizes the functions of access log reporting, message flow control and so on.
- Service, running service. At present, services such as service registration center, online mall service cluster and service message intermediary are simulated and realized.

The main directory structure of the sample code demo project is as follows:
├── db # Database module, defining Db, Table, TableVisitor and other abstract interfaces [@ singleton mode] │ ├── cache # Database caching agent, adding caching function for Db [@ agent mode] │ ├── console # Database console implementation, support dsl statement query and result display [@ adapter mode] │ ├── dsl # Realize the query ability of database dsl statement. Currently, only select statement query [@ interpreter mode] is supported │ ├── exception # Database module related exception definition │ ├── iterator # Traversal table iterator, including sequential traversal and random traversal [@ iterator mode] │ └── transaction # Realize the transaction functions of the database, including execution, submission, rollback, etc. [@ command mode] [@ memo mode] ├── monitor # The monitoring system module adopts the plug-in architecture style, and currently realizes the access log etl function │ ├── config # Monitoring system plug-in configuration module [@ abstract factory mode] [@ combination mode] │ │ ├── json # Realize the configuration loading function based on json format file │ │ └── yaml # Realize the configuration loading function based on yaml format file │ ├── entity # Monitoring system entity object definition │ ├── exception # Relevant abnormalities of monitoring system │ ├── filter # Implementation definition of Filter plug-in [@ responsibility chain mode] │ ├── input # Implementation definition of Input plug-in [@ policy mode] │ ├── output # Implementation definition of Output plug-in │ ├── pipeline # Implementation definition of pipeline plug-in. A pipeline represents an ETL processing flow [@ bridging mode] │ ├── plugin # Plug in abstract interface definition │ └── schema # Data sheet definition related to monitoring system ├── mq # Message queue module ├── network # The network module simulates network communication and defines socket, packet and other general types / interfaces [@ observer mode] │ └── http # The server and client capabilities such as http communication are simulated and realized ├── service # The service module defines the basic interface of the service │ ├── mediator # Service message intermediary, as the relay of service communication, realizes the ability of service discovery and message forwarding [@ intermediary mode] │ ├── registry # The service registration center provides service registration, de registration, update, discovery, subscription, de subscription, notification and other functions │ │ ├── entity # Entity definitions related to service registration / discovery [@ prototype mode] [@ builder mode] │ │ └── schema # Data table definitions related to the service registry [@ visitor mode] [@ sharing mode] │ └── shopping # [@ online shopping mall, service and payment mode, including appearance, order and service] └── sidecar # The side car module intercepts the socket and provides http access log and flow control functions [@ decorator mode] [@ factory mode] └── flowctrl # The flow control module performs random flow control based on the message rate [@ template method mode] [@ status mode]
SRP: single responsibility principle
The Single Responsibility Principle (SRP) should be one of the SOLID principles, which is the easiest to understand, but also the most misunderstood. Many people will equate the reconstruction technique of "reconstituting large functions into small functions with single responsibility" with SRP, which is wrong. Small functions certainly reflect single responsibility, but this is not SRP.
The broadest definition of SRP propagation should be given by Uncle Bob:
A module should have one, and only one, reason to change.
That is, a module should have and only have one reason for its change.
There are two points to understand in this explanation:
(1) How to define a module
We usually define a source file as the smallest granularity module.
(2) How to find this reason
A software change is often to meet the needs of a user, so this user is the reason for the change. However, there is often more than one user / client program for a module, such as the ArrayList class in Java. It may be used by thousands of programs, but we can't say that ArrayList has different responsibilities. Therefore, we should change "one user" to "one type of role". For example, the client program of ArrayList can be classified as the role of "requiring linked list / array function".
Therefore, Uncle Bob gives another explanation of SRP:
A module should be responsible to one, and only one, actor.
With this explanation, we can understand that single function responsibility is not equivalent to SRP. For example, there are two functions A and B in A module, both of which have single responsibility, but the user of function A is class A user, and the user of function B is class B user. Moreover, the reasons for the changes of class A user and class B user are different, so this module does not meet SRP.
Next, take our distributed application system demo as an example to further explore. For the Registry class (service Registry), its basic external capabilities include service registration, update, deregistration and discovery. Then, we can implement it as follows:
// demo/src/main/java/com/yrunz/designpattern/service/Registry.java
public class Registry implements Service {
private final HttpServer httpServer;
private final Db db;
...
@Override
public void run() {
httpServer.put("/api/v1/service-profile", this::register)
.post("/api/v1/service-profile", this::update)
.delete("/api/v1/service-profile", this::deregister)
.get("/api/v1/service-profile", this::discovery)
.start();
}
// Service registration
private HttpResp register(HttpReq req) {
...
}
// Service update
private HttpResp update(HttpReq req) {
...
}
// Service to register
private HttpResp deregister(HttpReq req) {
...
}
// Service discovery
private HttpResp discovery(HttpReq req) {
...
}
}In the above implementation, Registry includes four main methods: register, update, deregister and discovery, which exactly correspond to the external capabilities provided by Registry. It seems that it has a single responsibility.
However, after careful consideration, we will find that service registration, update and de registration are functions for service providers, while service discovery is functions for service consumers. Service providers and service consumers are two different roles, and the time and direction of their changes may be different. For example:
The current service discovery function is implemented in this way: Registry selects one of all service profiles that meet the query conditions and returns it to the service consumer (that is, registry has done load balancing by itself). Suppose that the service consumer puts forward a new demand: Registry returns all service profiles that meet the query conditions, and the service consumer does the load balancing himself. In order to achieve this function, we need to modify the code of Registry. Normally, the functions of service registration, update and de registration should not be affected, but because they are in the same module as the service discovery function, they are forced to be affected, such as code conflict.
Therefore, a better design is to integrate register, update and deregister into one service management module SvcManagement, and discovery into another service discovery module SvcDiscovery. The service Registry combines SvcManagement and SvcDiscovery.

The specific implementation is as follows:
// demo/src/main/java/com/yrunz/designpattern/service/SvcManagement.java
class SvcManagement {
private final Db db;
...
// Service registration
HttpResp register(HttpReq req) {
...
}
// Service update
HttpResp update(HttpReq req) {
...
}
// Service to register
HttpResp deregister(HttpReq req) {
...
}
}
// demo/src/main/java/com/yrunz/designpattern/service/SvcDiscovery.java
class SvcDiscovery {
private final Db db;
...
// Service discovery
HttpResp discovery(HttpReq req) {
...
}
}
// demo/src/main/java/com/yrunz/designpattern/service/Registry.java
public class Registry implements Service {
private final HttpServer httpServer;
private final SvcManagement svcManagement;
private final SvcDiscovery svcDiscovery;
...
@Override
public void run() {
// Use the sub module method to complete the specific business
httpServer.put("/api/v1/service-profile", svcManagement::register)
.post("/api/v1/service-profile", svcManagement::update)
.delete("/api/v1/service-profile", svcManagement::deregister)
.get("/api/v1/service-profile", svcDiscovery::discovery)
.start();
}
}In addition to repeated code compilation, violation of SRP also brings the following two common problems:
1. Code conflict. Programmer A has modified the A function of the module, while programmer B is also modifying the B function of the module without knowing it (because the A function and B function are oriented to different users and may be maintained by two different programmers). When they submit modifications at the same time, code conflicts will occur (modifying the same source file).
2. The modification of function A affects function B. If both function A and function B use A common function C in the module, and function A has new requirements and needs to modify function C, then if the modifier does not consider function B, the original logic of function B will be affected.
Thus, violation of SRP will lead to poor maintainability of software. However, we should not blindly split modules, which will lead to too fragmented code and increase the complexity of software. For example, in the previous example, there is no need to split the service management module into service registration module, service update module and service de registration module. First, they target the same users; Second, in the foreseeable future, they will either change at the same time or remain unchanged.
Therefore, we can conclude that:
- If a module targets the same type of users (the reasons for the changes are the same), there is no need to split it.
- If there is no judgment of user classification, the best time to split is when the change occurs.
SRP is a balance between aggregation and splitting. Too much aggregation will lead to pulling the whole body, and too fine splitting will increase the complexity. We should grasp the degree of separation from the perspective of users and separate the functions facing different users. If it is really impossible to judge / predict, split it when changes occur to avoid excessive design.
OCP: opening and closing principle
In the open close principle (OCP), "open" refers to opening to extension and "close" refers to closing to modification. Its complete interpretation is as follows:
A software artifact should be open for extension but closed for modification.
Generally speaking, a software system should have good scalability, and the new functions should be realized by extension, rather than modifying on the basis of the existing code.
However, from the literal meaning, OCP seems to be contradictory: you want to add functions to a module, but you can't modify it.
How can we break this dilemma? The key is abstraction! Excellent software systems are always based on good abstraction, which can reduce the complexity of software systems.
So what is abstraction? Abstract not only exists in the field of software, but also can be seen everywhere in our life. Below with< Linguistic invitation >To explain the meaning of abstraction:
Suppose there is a cow named "ah Hua" in a farm, then: 1. When we call it "a Hua", we see some of its unique features: there are many spots on the body and a lightning shaped scar on the forehead. 2. When we call it a cow, we ignore its unique characteristics and see what it has in common with the cow "a Hei" and the cow "a Huang": it is a cow and a female. 3. When we call it a domestic animal, we ignore its characteristics as a cow, but see the same characteristics as pigs, chickens and sheep: it is an animal, which is kept in a farm. 4. When we call it farm property, we only focus on what it has in common with other marketable objects on the farm: it can be sold and transferred. From "ah Hua", to cows, to livestock, and then to farm property, this is a process of continuous abstraction.
From the above examples, we can draw the following conclusion:
- Abstraction is the process of constantly ignoring details and finding common ground between things.
- Abstraction is layered. The higher the level of abstraction, the less details.
Back to the software field, we can also compare the above examples to the database. The abstraction level of the database can be as follows: MySQL version 8.0 - > MySQL - > relational database - > database. Now suppose there is a requirement that the business module needs to save the business data to the database, then there are the following design schemes:
- Scheme 1: the business module is designed to directly rely on MySQL version 8.0. Because the version always changes frequently, if MySQL upgrades the version one day, we have to modify the business module for adaptation, so scheme 1 violates OCP.
- Scheme 2: design the business module to rely on MySQL. Compared with scheme 1, scheme 2 eliminates the impact of MySQL version upgrade. Now consider another scenario. If the company prohibits the use of MySQL for some reasons, we must switch to PostgreSQL. At this time, we still have to modify the business module to switch and adapt the database. Therefore, in this scenario, scheme 2 also violates OCP.
- Scheme 3: design the business module as a dependency database. In this scheme, we basically eliminate the impact of relational database switching. We can switch on MySQL, PostgreSQL, Oracle and other relational databases at any time without modifying the business module. However, you who are familiar with the business predict that with the rapid increase of users in the future, relational databases are likely to be unable to meet the business scenario of high concurrent writing, so you have the following final scheme.
- Scheme 4: the business module is designed to rely on the database. In this way, no matter whether MySQL or PostgreSQL, relational database or non relational database is used in the future, the business module does not need to be changed. So far, we can basically think that the business module is stable, will not be affected by the changes of the underlying database, and meets the OCP.
We can find that the evolution process of the above scheme is the process of constantly abstracting the database modules that our business depends on, and finally designing stable software that serves OCP.
So, in the programming language, what do we use to represent the abstraction of "database"? It's an interface!
The most common database operations are CRUD, so we can design such a Db interface to represent "database":
public interface Db {
Record query(String tableName, Condition cond);
void insert(String tableName, Record record);
void update(String tableName, Record record);
void delete(String tableName, Record record);
}In this way, the dependency between the business module and the database module becomes as shown in the following figure:

Another key point to meet OCP is to separate the change. Only by separating the change point identification first can we abstract it. Next, take our distributed application system demo as an example to explain how to realize the separation and abstraction of change points.
In the demo, the monitoring system is mainly responsible for ETL operation on the access log of the service, which involves the following three operations: 1) obtaining log data from the message queue; 2) Process the data; 3) Store the processed data in the database.
We call the processing flow of the whole log data pipeline, so we can implement it as follows:
public class Pipeline implements Plugin {
private Mq mq;
private Db db;
...
public void run() {
while (!isClose.get()) {
// 1. Get data from message queue
Message msg = mq.consume("monitor.topic");
String accessLog = msg.payload();
// 2. Clean up the data and convert it into json string format
ObjectNode logJson = new ObjectNode(JsonNodeFactory.instance);
logJson.put("content", accessLog);
String data = logJson.asText();
// 3. Store on Database
db.insert("logs_table", logId, data);
}
}
...
}Now consider launching a new service, but this service does not support docking message queue and only supports socket data transmission. Therefore, we have to add an InputType on the Pipeline to judge whether to use socket input source:
public class Pipeline implements Plugin {
...
public void run() {
while (!isClose.get()) {
String accessLog;
// Using message queuing as a message source
if (inputType == InputType.MQ) {
Message msg = mq.consume("monitor.topic");
accessLog = msg.payload();
} else {
// Using socket as the message source
Packet packet = socket.receive();
accessLog = packet.payload().toString();
}
...
}
}
}After a period of time, it is necessary to stamp the access log to facilitate subsequent log analysis. Therefore, we need to modify the data processing logic of Pipeline:
public class Pipeline implements Plugin {
...
public void run() {
while (!isClose.get()) {
...
// Clean up the data and convert it into json string format
ObjectNode logJson = new ObjectNode(JsonNodeFactory.instance);
logJson.put("content", accessLog);
// Add a timestamp field
logJson.put("timestamp", Instant.now().getEpochSecond());
String data = logJson.asText();
...
}
}
}Soon, there was another need to store the processed data on ES to facilitate subsequent log retrieval, so we modified the data storage logic of Pipeline again:
public class Pipeline implements Plugin {
...
public void run() {
while (!isClose.get()) {
...
// Store on ES
if (outputType == OutputType.DB) {
db.insert("logs_table", logId, data);
} else {
// Store on ES
es.store(logId, data)
}
}
}
}In the above pipeline example, the pipeline module needs to be modified every time a new requirement is added, which obviously violates OCP. Next, let's optimize it to meet OCP.
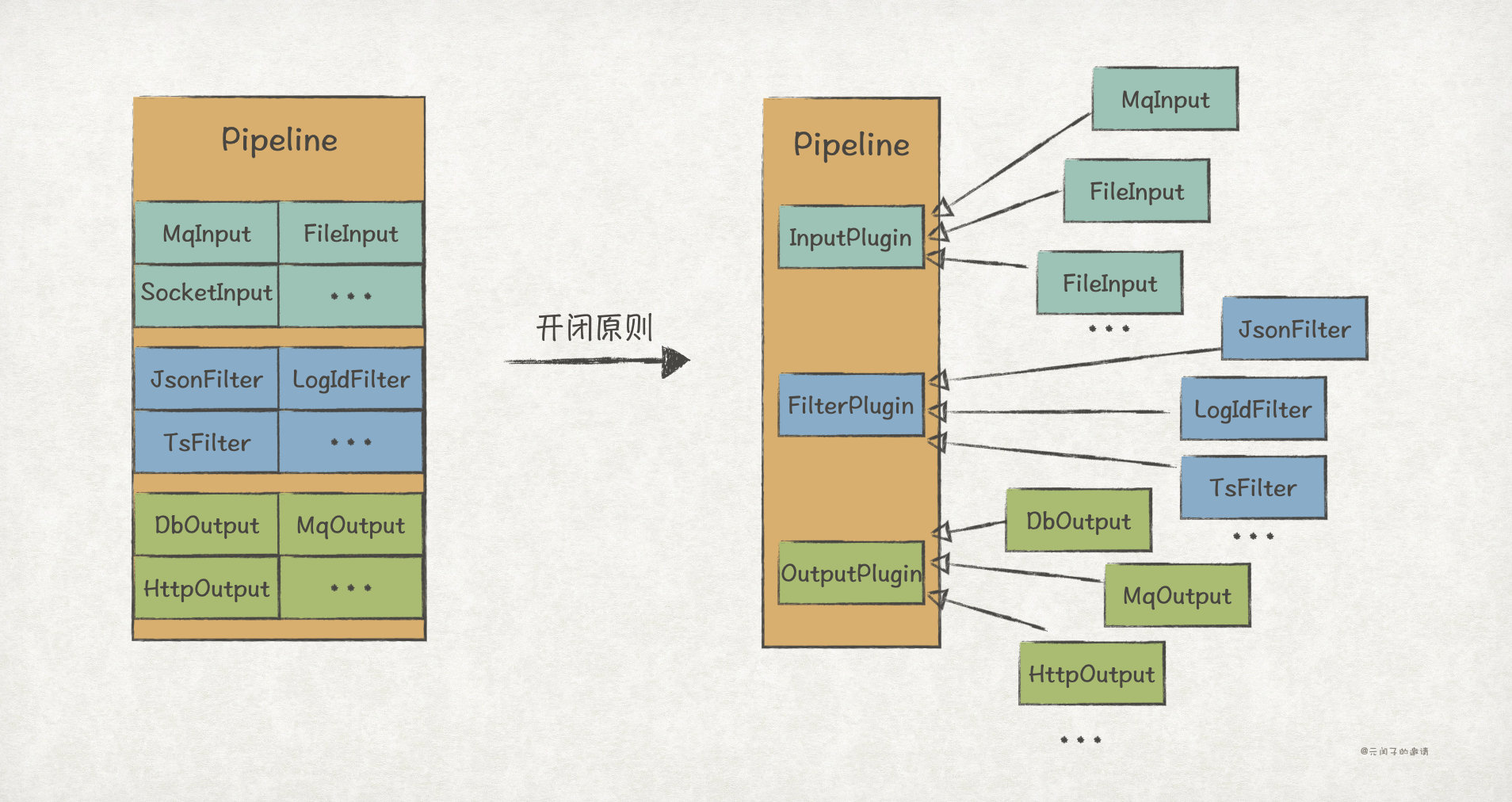
The first step is to separate the change points. According to the business processing logic of pipeline, we can find three independent change points, including data acquisition, processing and storage. In the second step, we abstract the three change points and design the following three abstract interfaces:
// demo/src/main/java/com/yrunz/designpattern/monitor/input/InputPlugin.java
// Data acquisition abstract interface
public interface InputPlugin extends Plugin {
Event input();
void setContext(Config.Context context);
}
// demo/src/main/java/com/yrunz/designpattern/monitor/filter/FilterPlugin.java
// Processing interface abstract data
public interface FilterPlugin extends Plugin {
Event filter(Event event);
}
// demo/src/main/java/com/yrunz/designpattern/monitor/output/OutputPlugin.java
// Data storage abstraction interface
public interface OutputPlugin extends Plugin {
void output(Event event);
void setContext(Config.Context context);
}Finally, the implementation of Pipeline is as follows, which only depends on three abstract interfaces: InputPlugin, FilterPlugin and OutputPlugin. If there is any subsequent demand change, just expand the corresponding interface, and there is no need to change the Pipeline:
// demo/src/main/java/com/yrunz/designpattern/monitor/pipeline/Pipeline.java
// ETL process definition
public class Pipeline implements Plugin {
final InputPlugin input;
final FilterPlugin filter;
final OutputPlugin output;
final AtomicBoolean isClose;
public Pipeline(InputPlugin input, FilterPlugin filter, OutputPlugin output) {
this.input = input;
this.filter = filter;
this.output = output;
this.isClose = new AtomicBoolean(false);
}
// Run pipeline
public void run() {
while (!isClose.get()) {
Event event = input.input();
event = filter.filter(event);
output.output(event);
}
}
...
}
OCP is the ultimate goal of software design. We all hope to design software that can add new functions without moving the old code. However, 100% modification closure is definitely impossible. In addition, the cost of following OCP is also huge. It requires software designers to identify those points that are most likely to change according to specific business scenarios, and then separate them and abstract them into stable interfaces. This requires designers to have rich practical experience and be very familiar with the business scenarios in this field. Otherwise, blind separation of change points and excessive abstraction will lead to more complex software systems.
LSP: Richter substitution principle
In the introduction of the previous section, a key point of OCP is abstraction, and how to judge whether an abstraction is reasonable is a question that needs to be answered by The Liskov Substitution Principle (LSP).
The initial definition of LSP is as follows:
If for each object o1 of type S there is an object o2 of type T such that for all programs P defined in terms of T, the behavior of P is unchanged when o1 is substituted for o2 then S is a subtype of T.
Simply put, subtypes must be able to replace their base type, that is, all properties in the base class can still be established in the subclass. A simple example: suppose there is a function f whose input parameter type is base class B. At the same time, base class B has a derived class D. if an instance of D is passed to function f, the behavior and function of function f should be unchanged.
It can be seen that the consequences of violating LSP are very serious, which will lead to unexpected behavior errors in the program. Next, let's look at a classic reverse example, rectangle and square.
Assuming that there is a rectangular Rectangle, you can set the width through setWidth method, set the length through setLength method, and get the rectangular area through area method:
// Rectangle definition
public class Rectangle {
private int width; // width
private int length; // length
// Set width
public void setWidth(int width) {
this.width = width;
}
// Set length
public void setLength(int length) {
this.length = length;
}
// Returns the rectangular area
public int area() {
return width * length;
}
}In addition, there is a client program Cient. Its method f takes Rectangle as the input parameter, and the logic is the logic of checking Rectangle:
// Client program
public class Client {
// Verify that the rectangular area is length * width
public void f(Rectangle rectangle) {
rectangle.setWidth(5);
rectangle.setLength(4);
if (rectangle.area() != 20) {
throw new RuntimeException("rectangle's area is invalid");
}
System.out.println("rectangle's area is valid");
}
}
// Run program
public static void main(String[] args) {
Rectangle rectangle = new Rectangle();
Client client = new Client();
client.f(rectangle);
}
// Operation results:
// rectangle's area is validNow, we're going to add a new type, Square. Mathematically, Square is also a kind of Rectangle, so we let Square inherit Rectangle. In addition, Square requires the same length and width, so Square rewrites the setWidth and setLength methods:
// Square with equal length and width
public class Square extends Rectangle {
// Set width
public void setWidth(int width) {
this.width = width;
// The length and width are equal, so the length is set at the same time
this.length = width;
}
// Set length
public void setLength(int length) {
this.length = length;
// The length and width are equal, so the length is set at the same time
this.width = length;
}
}Next, we instantiate Square and pass it into cient. Com as an input parameter On F:
public static void main(String[] args) {
Square square = new Square();
Client client = new Client();
client.f(square);
}
// Operation results:
// Exception in thread "main" java.lang.RuntimeException: rectangle's area is invalid
// at com.yrunz.designpattern.service.mediator.Client.f(Client.java:8)
// at com.yrunz.designpattern.service.mediator.Client.main(Client.java:16)We found cient The behavior of F has changed. The subtype Square cannot replace the base type Rectangle, which violates LSP.
The main reason for the above design violating LSP is that we design the model in isolation and do not examine whether the design is correct from the perspective of client program. In isolation, we believe that the mathematically established relationship (square IS-A rectangle) must also be established in the program, while ignoring the use method of the client program (first set the width to 5, the length to 4, and then check the area to 20).
This example tells us that the correctness or effectiveness of a model can only be reflected through the client program.
Next, we summarize some constraints that need to be followed in order to design a model conforming to LSP under the inheritance system (IS-A):
- The base class should be designed as an abstract class (it cannot be instantiated directly, but can only be inherited).
- Subclasses should implement the abstract interface of the base class, rather than overriding the specific methods already implemented by the base class.
- Subclasses can add new functions, but they cannot change the functions of the base class.
- Subclasses cannot add constraints, including throwing exceptions that are not declared by the base class.
In the previous examples of rectangles and squares, these constraints are almost broken, resulting in the abnormal behavior of the program: 1) square's base class Rectangle is not an abstract class, breaking constraint 1; 2) Square rewrites the setWidth and setLength methods of the base class to break the constraint 2; 3) Square adds a constraint that Rectangle doesn't have. The length and width are equal. Break the constraint 4.
In addition to inheritance, another mechanism for implementing abstraction is the interface. If we are an interface oriented design, the above constraints 1 ~ 3 have been met: 1) the interface itself does not have instantiation ability and meets constraint 1; 2) The interface has no specific implementation method (the default method of the interface in Java is an exception, which will not be considered in this paper first), so it will not be rewritten and meet constraint 2; 3) The interface itself only defines the behavior contract and has no actual function, so it will not be changed to meet constraint 3.
Therefore, using interface instead of inheritance to realize polymorphism and abstraction can reduce many inadvertent errors. However, the interface oriented design still needs to follow constraint 4. Let's take the distributed application system demo as an example to introduce a relatively obscure way to break constraint 4, which violates the implementation of LSP.
Take the process, which data needs to be stored in the ETL System as an example. At present, json and yaml configuration file formats need to be supported. Take yaml configuration as an example. The configuration content is as follows:
# src/main/resources/pipelines/pipeline_0.yaml name: pipeline_0 # pipeline name type: single_thread # pipeline type input: # input plug-in definition (where data comes from) name: input_0 # input plug-in name type: memory_mq # input plug-in type context: # Initialization context of input plug-in topic: access_log.topic filter: # filter plug-in definition (what processing is required) - name: filter_0 # Processing flow filter_0 is defined, and the type is log_to_json type: log_to_json - name: filter_1 # Processing flow filter_1 definition, type: add_timestamp type: add_timestamp - name: filter_2 # Processing flow filter_2 definition, type json_to_monitor_event type: json_to_monitor_event output: # output plug-in definition (where to store after processing) name: output_0 # output plug-in name type: memory_db # output plug-in type context: # Initialization context of the output plug-in tableName: monitor_event_0
First, we define a Config interface to represent the abstraction of "configuration":
// demo/src/main/java/com/yrunz/designpattern/monitor/config/Config.java
public interface Config {
// Load configuration from json string
void load(String conf);
}In addition, the input, filter and output sub items in the above configuration can be considered as the configuration items of InputPlugin, FilterPlugin and OutputPlugin plug-ins, which are combined by the configuration items of Pipeline plug-in. Therefore, we define the following abstract classes of Config:
// demo/src/main/java/com/yrunz/designpattern/monitor/config/InputConfig.java
public abstract class InputConfig implements Config {
protected String name;
protected InputType type;
protected Context ctx;
// Subclasses implement specific loading logic and support the loading methods of yaml and json
@Override
public abstract void load(String conf);
...
}
// demo/src/main/java/com/yrunz/designpattern/monitor/config/FilterConfig.java
public abstract class FilterConfig implements Config {
protected List<Item> items;
// Subclasses implement specific loading logic and support the loading methods of yaml and json
@Override
public abstract void load(String conf);
...
}
// demo/src/main/java/com/yrunz/designpattern/monitor/config/OutputConfig.java
public abstract class OutputConfig implements Config {
protected String name;
protected OutputType type;
protected Context ctx;
// Subclasses implement specific loading logic and support the loading methods of yaml and json
@Override
abstract public void load(String conf);
...
}
// demo/src/main/java/com/yrunz/designpattern/monitor/config/PipelineConfig.java
public abstract class PipelineConfig implements Config {
protected String name;
protected PipelineType type;
protected final InputConfig inputConfig;
protected final FilterConfig filterConfig;
protected final OutputConfig outputConfig;
// Subclasses implement specific loading logic and support the loading methods of yaml and json
@Override
public abstract void load(String conf);
}Finally, implement specific subclasses based on json and yaml:
// Load Config subclass directory in json mode: src/main/java/com/yrunz/designpattern/monitor/config/json
public class JsonInputConfig extends InputConfig {...}
public class JsonFilterConfig extends FilterConfig {...}
public class JsonOutputConfig extends OutputConfig {...}
public class JsonPipelineConfig extends PipelineConfig {...}
// Load Config subclass directory in yaml mode: src/main/java/com/yrunz/designpattern/monitor/config/yaml
public class YamlInputConfig extends InputConfig {...}
public class YamlFilterConfig extends FilterConfig {...}
public class YamlOutputConfig extends OutputConfig {...}
public class YamlPipelineConfig extends PipelineConfig {...}Because it involves the process from configuration to object instantiation, it is natural to think of using the factory pattern to create objects. In addition, because Pipeline, InputPlugin, FilterPlugin and OutputPlugin all implement the Plugin interface, it is easy to think of defining a PluginFactory interface to represent the abstraction of "plug-in factory", and then the specific plug-in factory implements the interface:
// The plug-in factory interface instantiates the plug-in according to the configuration
public interface PluginFactory {
Plugin create(Config config);
}
// input plug-in factory
public class InputPluginFactory implements PluginFactory {
...
@Override
public InputPlugin create(Config config) {
InputConfig conf = (InputConfig) config;
try {
Class<?> inputClass = Class.forName(conf.type().classPath());
InputPlugin input = (InputPlugin) inputClass.getConstructor().newInstance();
input.setContext(conf.context());
return input;
} ...
}
}
// filter plug-in factory
public class FilterPluginFactory implements PluginFactory {
...
@Override
public FilterPlugin create(Config config) {
FilterConfig conf = (FilterConfig) config;
FilterChain filterChain = FilterChain.empty();
String name = "";
try {
for (FilterConfig.Item item : conf.items()) {
name = item.name();
Class<?> filterClass = Class.forName(item.type().classPath());
FilterPlugin filter = (FilterPlugin) filterClass.getConstructor().newInstance();
filterChain.add(filter);
}
} ...
}
}
// output plug-in factory
public class OutputPluginFactory implements PluginFactory {
...
@Override
public OutputPlugin create(Config config) {
OutputConfig conf = (OutputConfig) config;
try {
Class<?> outputClass = Class.forName(conf.type().classPath());
OutputPlugin output = (OutputPlugin) outputClass.getConstructor().newInstance();
output.setContext(conf.context());
return output;
} ...
}
}
// pipeline plug-in factory
public class PipelineFactory implements PluginFactory {
...
@Override
public Pipeline create(Config config) {
PipelineConfig conf = (PipelineConfig) config;
InputPlugin input = InputPluginFactory.newInstance().create(conf.input());
FilterPlugin filter = FilterPluginFactory.newInstance().create(conf.filter());
OutputPlugin output = OutputPluginFactory.newInstance().create(conf.output());
...
}
}Finally, create a pipeline object through PipelineFactory:
Config config = YamlPipelineConfig.of(YamlInputConfig.empty(), YamlFilterConfig.empty(), YamlOutputConfig.empty());
config.load(Files.readAllBytes("pipeline_0.yaml"));
Pipeline pipeline = PipelineFactory.newInstance().create(config);
assertNotNull(pipeline);
// Operation results:
PassSo far, the above design seems reasonable and there is no problem in operation.
However, careful readers may find that the first line of the create method of each plug-in factory subclass is a transformation statement. For example, the PipelineFactory is PipelineConfig conf = (PipelineConfig) config;. Therefore, the premise for the previous code to work normally is to pass in PipelineFactory The input parameter of the create method must be PipelineConfig. If the client program passes in an instance of InputConfig, PipelineFactory The create method will throw an exception if the transformation fails.
The above example is a typical scenario of violating LSP. Although the program can run correctly on the premise of the agreement, if a client accidentally breaks the agreement, it will lead to abnormal program behavior (we can never predict all the behaviors of the client).
It is also very simple to correct this problem, that is, remove the abstraction of PluginFactory and let PipelineFactory The input parameters of factory methods such as create are declared as specific configuration classes. For example, PipelineFactory can be implemented as follows:
// demo/src/main/java/com/yrunz/designpattern/monitor/pipeline/PipelineFactory.java
// pipeline plug-in factory, no longer implements PluginFactory interface
public class PipelineFactory {
...
// The factory method input parameter is PipelineConfig implementation class to eliminate transformation
public Pipeline create(PipelineConfig config) {
InputPlugin input = InputPluginFactory.newInstance().create(config.input());
FilterPlugin filter = FilterPluginFactory.newInstance().create(config.filter());
OutputPlugin output = OutputPluginFactory.newInstance().create(config.output());
...
}
}
From the above examples, we can see the importance of following LSP, and the key point of designing LSP compliant software is to examine whether it is effective and correct according to the reasonable assumptions made by the user behavior of the software.
ISP: interface isolation principle
The Interface Segregation Principle (ISP) is a principle about interface design. The "interface" here does not only refer to the narrow interface declared by interface on Java or Go, but also includes the narrow interface, abstract class, concrete class, etc. It is defined as follows:
Client should not be forced to depend on methods it does not use.
That is, a module should not force clients to rely on interfaces they do not want to use, and the relationship between modules should be based on the smallest set of interfaces.
Next, we will introduce ISP in detail through an example.

In the above figure, Client1, Client2 and Client3 all rely on Class1, but in fact, Client1 only needs to use Class1 Func1 method, Client2 only need to use Class1 Func2, Client3 only need to use Class1 Func3, then we can say that the design violates the ISP.
Violation of ISP will mainly bring the following two problems:
- Increase the dependence between the module and the client program. For example, in the above example, although neither Client2 nor Client3 calls func1, when Class1 modifies func1, it must notify Client1 ~ 3, because Class1 does not know whether they use func1.
- If the programmer who develops Client1 accidentally types func1 as func2 when writing code, it will lead to abnormal behavior of Client1. That is, Client1 is contaminated by func2.
In order to solve the above two problems, we can isolate func1, func2 and func3 through the interface:

After interface isolation, Client1 only depends on Interface1, and there is only one method of func1 on Interface1, that is, Client1 will not be polluted by func2 and func3; In addition, after Class1 modifies func1, it only needs to notify the clients that depend on Interface1, which greatly reduces the coupling between modules.
The key to the implementation of ISP is to split the large interface into small interfaces, and the key to splitting is to grasp the interface granularity. To split well, the interface designer is required to be very familiar with the business scenario and know the scenario of interface use like the back of his hand. Otherwise, if the interface is designed in isolation, it is difficult to meet the requirements of ISP.
Next, we take the distributed application system demo as an example to further introduce the implementation of ISP.
A message queue module usually contains two behaviors: production and consumer. Therefore, we have designed an abstract interface of Mq message queue, including two methods: production and consumer:
// Message queue interface
public interface Mq {
Message consume(String topic);
void produce(Message message);
}
// demo/src/main/java/com/yrunz/designpattern/mq/MemoryMq.java
// Currently, it provides the implementation of MemoryMq memory message queue
public class MemoryMq implements Mq {...}There are two modules using interfaces in the current demo, namely MemoryMqInput as a consumer and AccessLogSidecar as a producer:
public class MemoryMqInput implements InputPlugin {
private String topic;
private Mq mq;
...
@Override
public Event input() {
Message message = mq.consume(topic);
Map<String, String> header = new HashMap<>();
header.put("topic", topic);
return Event.of(header, message.payload());
}
...
}
public class AccessLogSidecar implements Socket {
private final Mq mq;
private final String topic
...
@Override
public void send(Packet packet) {
if ((packet.payload() instanceof HttpReq)) {
String log = String.format("[%s][SEND_REQ]send http request to %s",
packet.src(), packet.dest());
Message message = Message.of(topic, log);
mq.produce(message);
}
...
}
...
}From the domain model, the design of Mq interface is really no problem. It should include two methods: consume and produce. However, from the perspective of the client program, it violates the ISP. For MemoryMqInput, it only needs the consume method; For AccessLogSidecar, it only needs the produce method.
One design scheme is to split the Mq interface into two sub interfaces, Consumable and Producible, so that MemoryMq can directly realize Consumable and Producible:
// demo/src/main/java/com/yrunz/designpattern/mq/Consumable.java
// Consumer interface, consuming data from message queue
public interface Consumable {
Message consume(String topic);
}
// demo/src/main/java/com/yrunz/designpattern/mq/Producible.java
// The producer interface produces consumption data to the message queue
public interface Producible {
void produce(Message message);
}
// Currently, it provides the implementation of MemoryMq memory message queue
public class MemoryMq implements Consumable, Producible {...}If you think about it carefully, you will find that the above design is not in line with the domain model of message queue, because the abstraction of Mq really should exist.
A better design should be to retain the Mq abstract interface and let Mq inherit from Consumable and Producible. After such hierarchical design, it can not only meet the ISP, but also make the implementation conform to the domain model of message queue:

The specific implementation is as follows:
// demo/src/main/java/com/yrunz/designpattern/mq/Mq.java
// The message queue interface inherits Consumable and Producible, and also has two behaviors: consume and produce
public interface Mq extends Consumable, Producible {}
// Currently, it provides the implementation of MemoryMq memory message queue
public class MemoryMq implements Mq {...}
// demo/src/main/java/com/yrunz/designpattern/monitor/input/MemoryMqInput.java
public class MemoryMqInput implements InputPlugin {
private String topic;
// Consumers rely only on the Consumable interface
private Consumable consumer;
...
@Override
public Event input() {
Message message = consumer.consume(topic);
Map<String, String> header = new HashMap<>();
header.put("topic", topic);
return Event.of(header, message.payload());
}
...
}
// demo/src/main/java/com/yrunz/designpattern/sidecar/AccessLogSidecar.java
public class AccessLogSidecar implements Socket {
// Producers rely only on the Producible interface
private final Producible producer;
private final String topic
...
@Override
public void send(Packet packet) {
if ((packet.payload() instanceof HttpReq)) {
String log = String.format("[%s][SEND_REQ]send http request to %s",
packet.src(), packet.dest());
Message message = Message.of(topic, log);
producer.produce(message);
}
...
}
...
}Interface isolation can reduce the coupling between modules and improve the stability of the system, but excessively refining and splitting interfaces will also lead to the increase of the number of interfaces of the system, resulting in greater maintenance costs. The granularity of the interface needs to be determined according to the specific business scenario. You can refer to the principle of single responsibility to combine those interfaces that provide services for the same type of client programs.
DIP: Dependency Inversion Principle
When introducing OCP in Clean Architecture, it is mentioned that if module A is to be free from the change of module B, module B must depend on module A. This sentence seems contradictory. Module A needs to use the functions of module B. how can module B rely on module A in turn? This is the question to be answered by The Dependency Inversion Principle (DIP).
DIP is defined as follows:
- High-level modules should not import anything from low-level modules. Both should depend on abstractions.
- Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.
Translated as:
1. High level modules should not rely on low-level modules, and both should rely on abstraction 2. Abstract should not rely on details, details should rely on abstraction
In the definition of DIP, there are four Keywords: high-level module, low-level module, abstraction and detail. To understand the meaning of DIP, it is very important to understand the four keywords.
(1) High level module and low level module
Generally speaking, we believe that the high-level module is a module that contains the core business logic and strategy of the application, and is the soul of the whole application; Low level modules are usually some infrastructure, such as database, Web framework, etc. They mainly exist to assist high-level modules to complete business.
(2) Abstraction and detail
In the previous section "OCP: opening and closing principles", we can know that abstraction is the common ground among many details, and abstraction is the result of constantly ignoring details.
Now let's look at the definition of DIP. It is not difficult for us to understand the second point. From the definition of abstraction, abstraction will not depend on details, otherwise it will not be abstract; Details depend on abstraction, which is often true.
The key to understanding DIP lies in point 1. According to our positive thinking, high-level modules should complete business with the help of low-level modules, which will inevitably lead to high-level modules relying on low-level modules. But in the software field, we can invert this dependency, and the key is abstraction. We can ignore the details of the low-level module, abstract a stable interface, then let the high-level module rely on the interface, and let the low-level module implement the interface, so as to realize the inversion of dependency relationship:
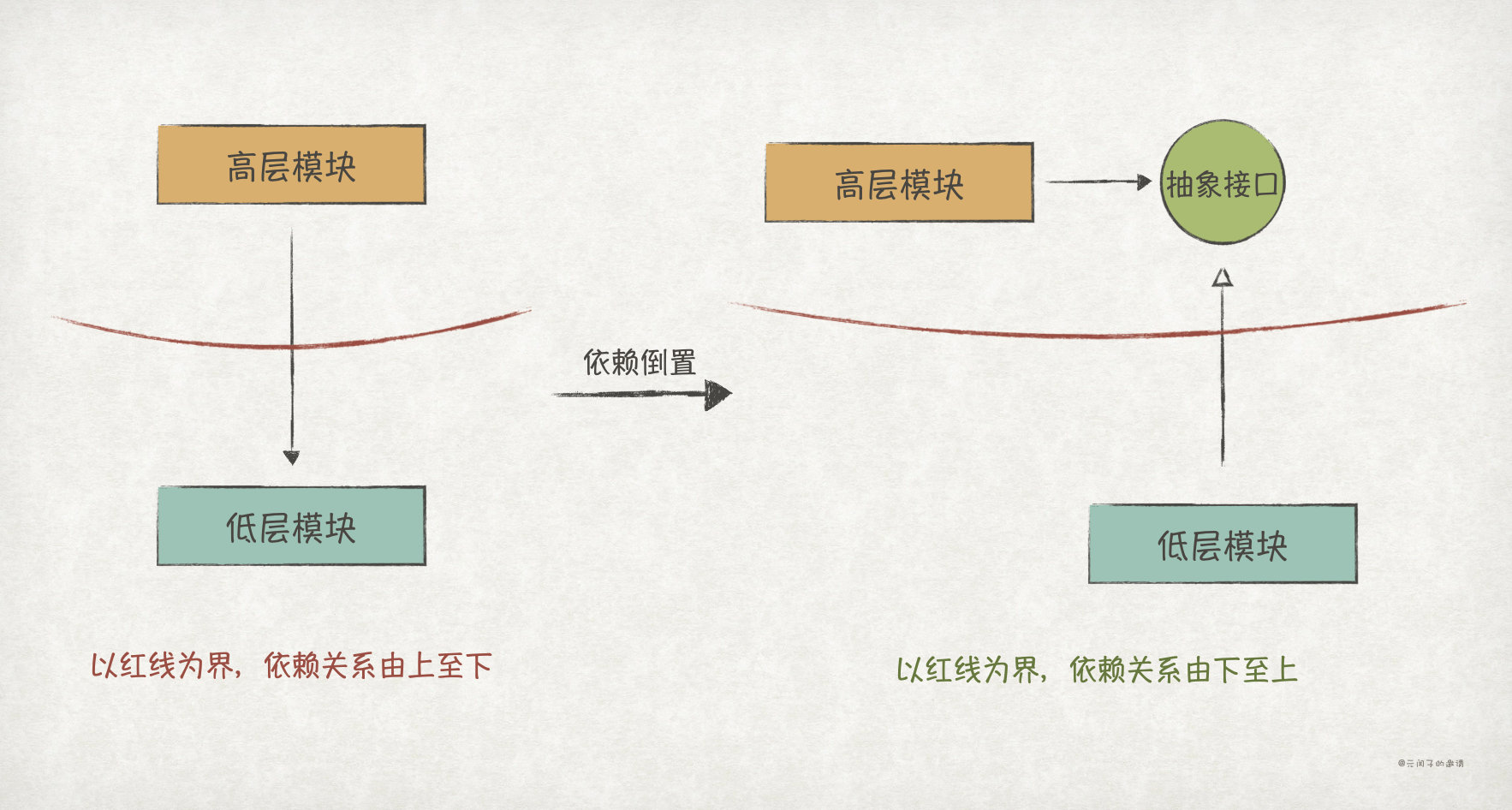
The reason why we should invert the dependency between high-level modules and low-level modules is mainly because the high-level modules as the core should not be affected by the changes of low-level modules. There should be only one reason for the change of high-level modules, that is, the business change requirements from software users.
Next, we introduce the implementation of DIP through the distributed application system demo.
For the service Registry, when a new service is registered, it needs to save the service information (such as service ID, service type, etc.) so that it can be returned to the client in the subsequent service discovery. Therefore, Registry needs a database to help it complete its business. As it happens, our database module implements a memory database MemoryDb, so we can implement Registry as follows:
// Service registry
public class Registry implements Service {
...
// Directly dependent on MemoryDb
private final MemoryDb db;
private final SvcManagement svcManagement;
private final SvcDiscovery svcDiscovery;
private Registry(...) {
...
// Initialize MemoryDb
this.db = MemoryDb.instance();
this.svcManagement = new SvcManagement(localIp, this.db, sidecarFactory);
this.svcDiscovery = new SvcDiscovery(this.db);
}
...
}
// Memory database
public class MemoryDb {
private final Map<String, Table<?, ?>> tables;
...
// Query table record
public <PrimaryKey, Record> Optional<Record> query(String tableName, PrimaryKey primaryKey) {
Table<PrimaryKey, Record> table = (Table<PrimaryKey, Record>) tableOf(tableName);
return table.query(primaryKey);
}
// Insert table record
public <PrimaryKey, Record> void insert(String tableName, PrimaryKey primaryKey, Record record) {
Table<PrimaryKey, Record> table = (Table<PrimaryKey, Record>) tableOf(tableName);
table.insert(primaryKey, record);
}
// Update table records
public <PrimaryKey, Record> void update(String tableName, PrimaryKey primaryKey, Record record) {
Table<PrimaryKey, Record> table = (Table<PrimaryKey, Record>) tableOf(tableName);
table.update(primaryKey, record);
}
// Delete table record
public <PrimaryKey> void delete(String tableName, PrimaryKey primaryKey) {
Table<PrimaryKey, ?> table = (Table<PrimaryKey, ?>) tableOf(tableName);
table.delete(primaryKey);
}
...
}According to the above design, the dependency between modules is that Registry depends on MemoryDb, that is, high-level modules depend on low-level modules. This dependency is fragile. If the database storing service information needs to be changed from MemoryDb to DiskDb one day, we also have to change the code of Registry:
// Service registry
public class Registry implements Service {
...
// Change to rely on DiskDb
private final DiskDb db;
...
private Registry(...) {
...
// Initialize DiskDb
this.db = DiskDb.instance();
this.svcManagement = new SvcManagement(localIp, this.db, sidecarFactory);
this.svcDiscovery = new SvcDiscovery(this.db);
}
...
}A better design should be to invert the dependency between Registry and MemoryDb. First, we need to abstract a stable interface Db from the detail MemoryDb:
// demo/src/main/java/com/yrunz/designpattern/db/Db.java
// DB abstract interface
public interface Db {
<PrimaryKey, Record> Optional<Record> query(String tableName, PrimaryKey primaryKey);
<PrimaryKey, Record> void insert(String tableName, PrimaryKey primaryKey, Record record);
<PrimaryKey, Record> void update(String tableName, PrimaryKey primaryKey, Record record);
<PrimaryKey> void delete(String tableName, PrimaryKey primaryKey);
...
}Next, let Registry rely on Db interface and MemoryDb implement Db interface to complete dependency inversion:
// demo/src/main/java/com/yrunz/designpattern/service/registry/Registry.java
// Service registry
public class Registry implements Service {
...
// Only rely on Db abstract interface
private final Db db;
private final SvcManagement svcManagement;
private final SvcDiscovery svcDiscovery;
private Registry(..., Db db) {
...
// Dependency injection Db
this.db = db;
this.svcManagement = new SvcManagement(localIp, this.db, sidecarFactory);
this.svcDiscovery = new SvcDiscovery(this.db);
}
...
}
// demo/src/main/java/com/yrunz/designpattern/db/MemoryDb.java
// Memory database to realize Db abstract interface
public class MemoryDb implements Db {
private final Map<String, Table<?, ?>> tables;
...
// Query table record
@Override
public <PrimaryKey, Record> Optional<Record> query(String tableName, PrimaryKey primaryKey) {...}
// Insert table record
@Override
public <PrimaryKey, Record> void insert(String tableName, PrimaryKey primaryKey, Record record) {...}
// Update table records
@Override
public <PrimaryKey, Record> void update(String tableName, PrimaryKey primaryKey, Record record) {...}
// Delete table record
@Override
public <PrimaryKey> void delete(String tableName, PrimaryKey primaryKey) {...}
...
}
// demo/src/main/java/com/yrunz/designpattern/Example.java
public class Example {
// Complete dependency injection in main function
public static void main(String[] args) {
...
// Set memorydb Instance() is injected into the Registry
Registry registry = Registry.of(..., MemoryDb.instance());
registry.run();
}
}When high-level modules rely on abstract interfaces, implementation details (low-level modules) must be injected into high-level modules at some time and somewhere. In the above example, we choose to inject MemoryDb into the main function when creating the Registry object.

Generally, we will complete dependency injection on the main / startup function. The common injection methods are as follows:
- Constructor injection (method used by Registry)
- setter method injection
- Provide the interface of dependency injection, and the client can call the interface directly
- Inject through the framework, such as the annotation injection capability in the Spring framework
In addition, DIP is not only applicable to module / class / interface design, but also applicable at the architecture level. For example, the hierarchical architecture of DDD and the neat architecture of Uncle Bob all use DIP:
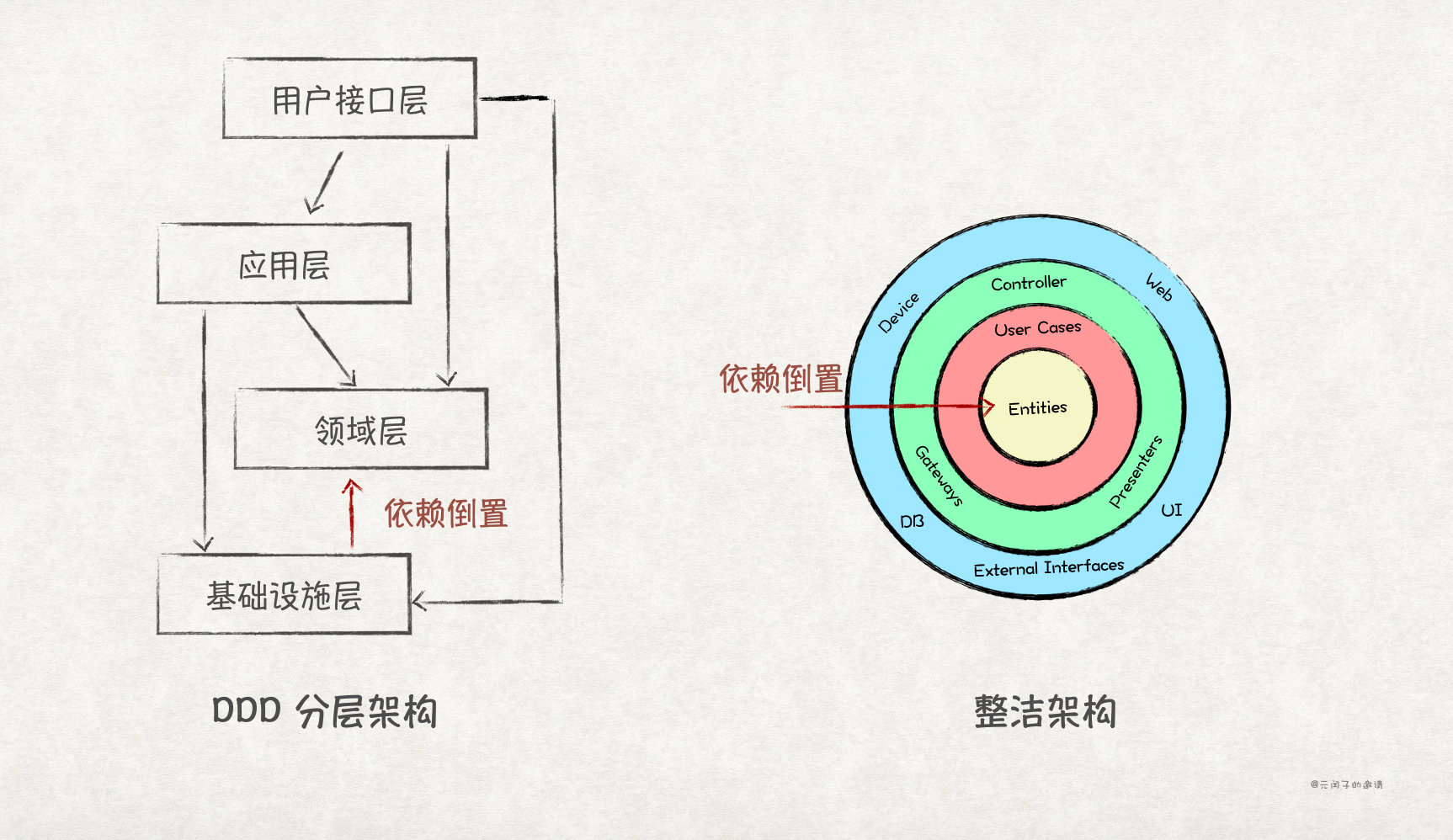
Of course, DIP does not mean that high-level modules can only rely on abstract interfaces. Its original intention should be to rely on stable interfaces / abstract classes / concrete classes. If a concrete class is stable, such as String in Java, there is no problem for high-level modules to rely on it; On the contrary, if an abstract interface is unstable and often changes, it is also against DIP for high-level modules to rely on the interface. At this time, we should consider whether the interface is abstract and reasonable.
last
This paper spent a long time discussing the core idea behind 23 design patterns - SOLID principle, which can guide us to design high cohesion and low coupling software systems. However, it is only a principle after all. How to land on the actual engineering project still needs to refer to the successful practical experience. These practical experiences are the design patterns we want to explore next.
The best way to learn design patterns is to practice. In the follow-up article of "practice 23 design patterns of GoF", we will introduce it in this article Distributed application system demo As a practical demonstration, this paper introduces the program structure, applicable scenarios, implementation methods, advantages and disadvantages of 23 design patterns, so that everyone can have a deeper understanding of design patterns, and can use and do not abuse design patterns.
reference resources
- Clean Architecture, Robert C. Martin ("Uncle Bob")
- Agile software development: principles, models and practices, Robert C. Martin ("Uncle Bob")
- 23 design patterns of GoF using Go , yuan Runzi
- Riemannian substitution principle LSP of SOLID principle , deputy chief of the people