I was lucky to participate Flomesh The organization's workshop learned about their Pipy network agent and the ecology built around Pipy. In ecology, Pipy is not only the role of agent, but also the data plane in the Flomesh service grid.
Sort it out, make a record, and take a look at some of the source code of Pipy.
introduce
The following is about pithub:
Pipy is a lightweight, high-performance, highly stable and programmable network agent. Pipy core framework is developed in C + +, and ASIO library is used for network IO. The executable file of pipy is only about 5M, and the memory occupied during the running period is about 10M. Therefore, pipy is very suitable for Sidecar proxy.
Pipy has built-in self-developed pjs as script extension, so that pipy can quickly customize logic and functions according to specific needs with JS script.
Pipy adopts a modular and chained processing architecture, and uses sequentially executed modules to process network data blocks. This simple architecture makes the bottom layer of pipy simple and reliable, and has the ability to dynamically arrange traffic, taking into account simplicity and flexibility. By using REUSE_PORT mechanism (both mainstream Linux and BSD versions support this function). Pipy can run in multi process mode, which makes pipy applicable not only to Sidecar mode, but also to large-scale traffic processing scenarios. In practice, pipy is used as a "soft load" when deployed independently, which can achieve load balancing throughput comparable to hardware with low latency, and has flexible scalability.
The core of Pipy is the message flow processor:

Flow of Pipy flow processing:
Core concept
- Stream: Pipy
- Pipeline
- Module
- Session
- Context
Here are some personal opinions:
Pipy uses the pjs engine to parse the Configuration in JavaScript format into its abstract Configuration object. Each Configuration contains multiple pipelines, and each Configuration uses multiple filters. These belong to the static Configuration part of pipy. (three different types of Pipeline will be mentioned later)
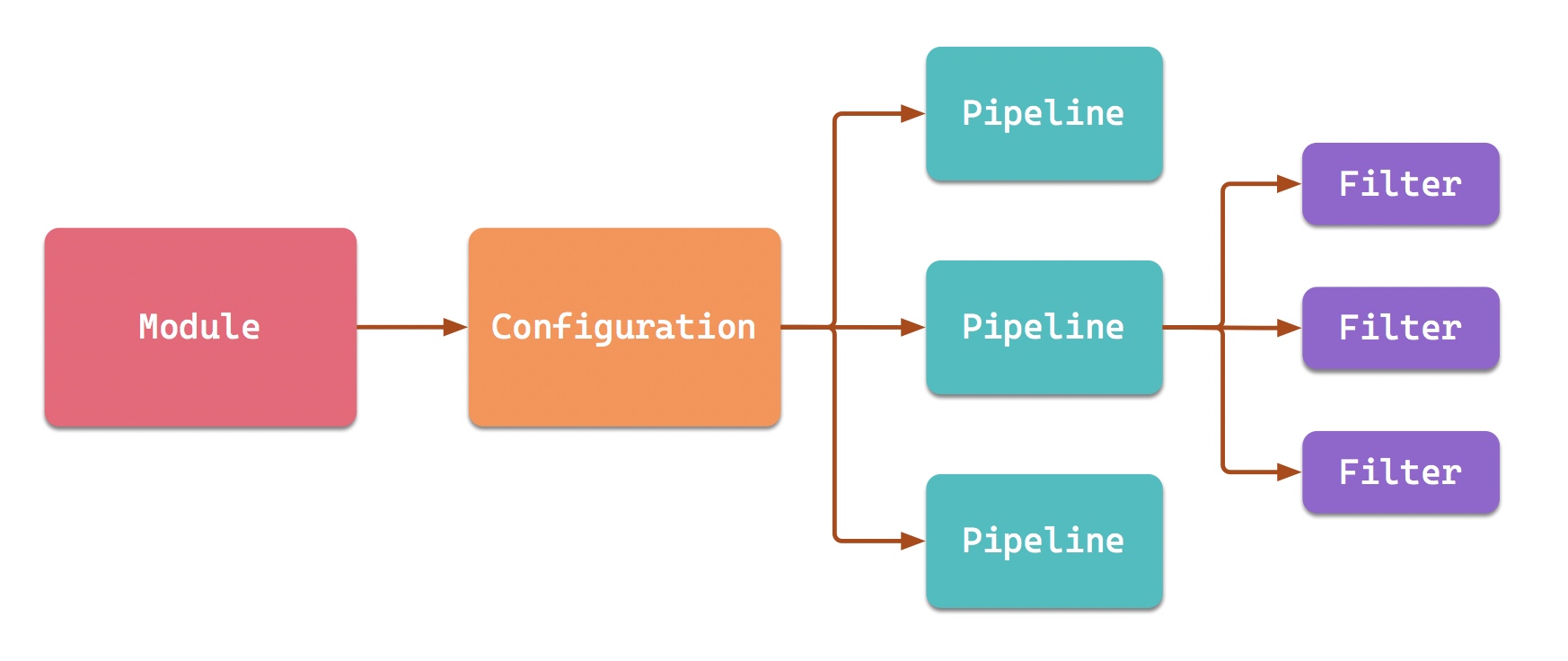
What belongs to the runtime is the flow, session and context. In Pipy, the data flow is composed of objects (the abstraction of Pipy). These objects arrive at Pipy and are abstracted into different events. Events trigger the execution of different filters.
Personally, I prefer to understand its core as: event processing engine for data flow.
Understanding belongs to understanding, and practice produces true knowledge. "Make bold assumptions and be careful to verify!"
Local compilation
Start by compiling Pipy.
Environmental preparation
#Installing nodejs $ nvm install lts/erbium #Installing cmake $ brew install cmake
Compile Pipy
From https://github.com/flomesh-io/pipy.git Clone code.
The compilation of Pipy includes two parts, GUI and Pipy ontology.
GUI is an interface provided by Pipy for configuration in development mode. First compile Pipy GUI.
# pipy root folder $ cd gui $ npm install $ npm run build
Then compile the ontology of Pipy
# pipy root folder $ mkdir build $ cd build $ cmake -DCMAKE_BUILD_TYPE=Release -DPIPY_GUI=ON .. $ make
After completion, check the bin directory under the root directory. You can see the executable file of pipy, which is only 11M in size.

$ bin/pipy --help Usage: pipy [options] <script filename> Options: -h, -help, --help Show help information -v, -version, --version Show version information --list-filters List all filters --help-filters Show detailed usage information for all filters --log-level=<debug|info|warn|error> Set the level of log output --verify Verify configuration only --reuse-port Enable kernel load balancing for all listening ports --gui-port=<port> Enable web GUI on the specified port
Demo: Hello Pipy
In the development mode, Pipy can be started with GUI and configured through GUI.
#The port of the specified gui is 6060. Load the configuration from the test directory $ bin/pipy --gui-port=6060 test/ 2021-05-30 22:48:41 [info] [gui] Starting GUI service... 2021-05-30 22:48:41 [info] [listener] Listening on 0.0.0.0:6060
Open in browser 
Configuration interface 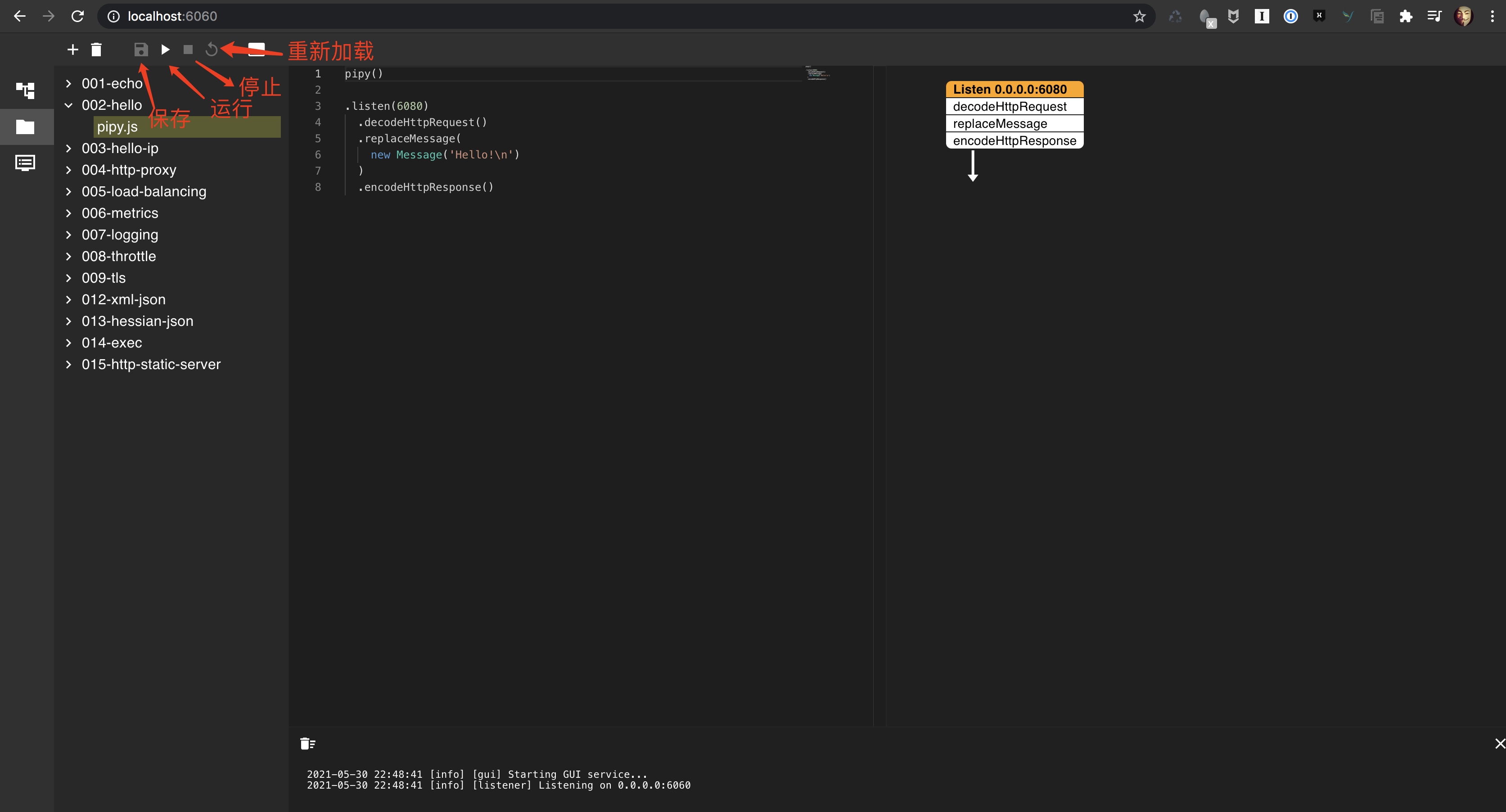
Expand the 002 Hello subdirectory, click pipy and click the run button:
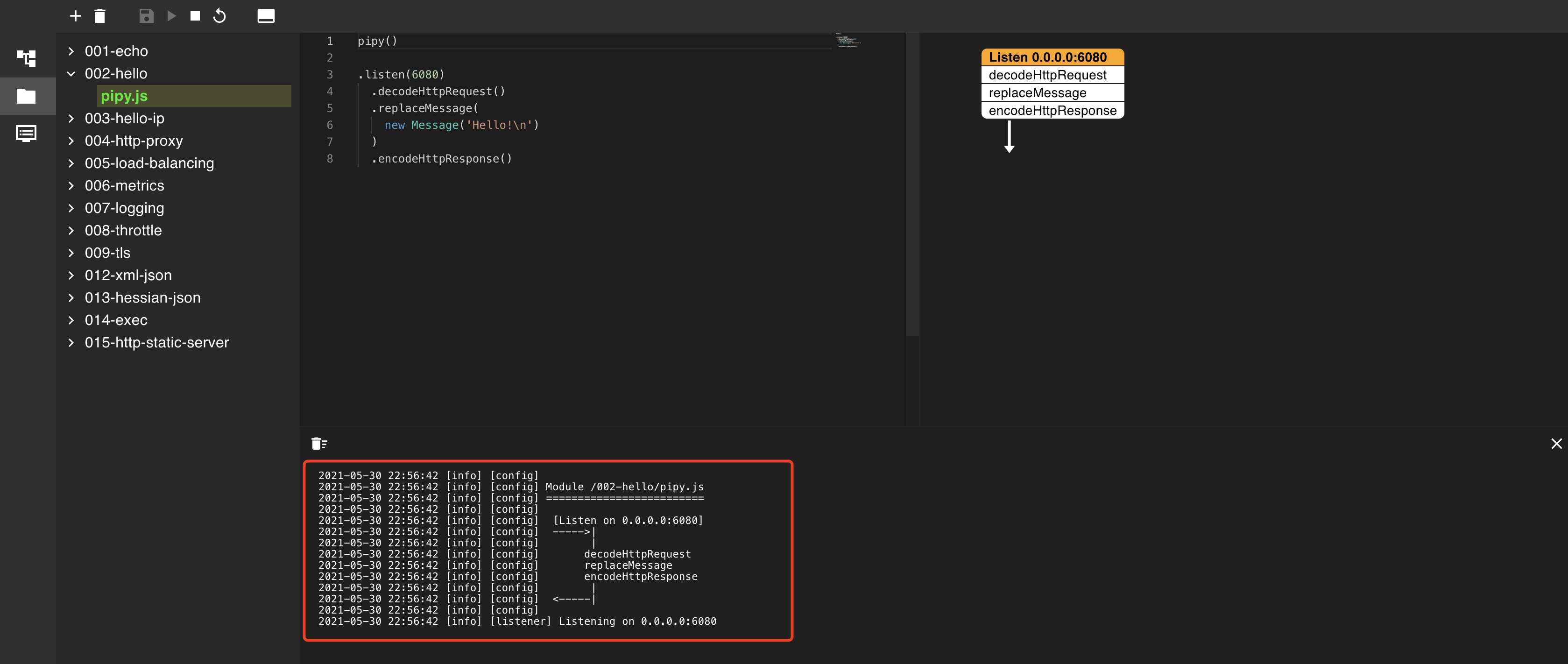
$ curl -i localhost:6080 HTTP/1.1 200 OK Connection: keep-alive Content-Length: 7 Hello!
Pipy filter
Through the pipe command, you can output a list of 31 supported filters. By assembling a series of filters, complex flow processing can be realized.
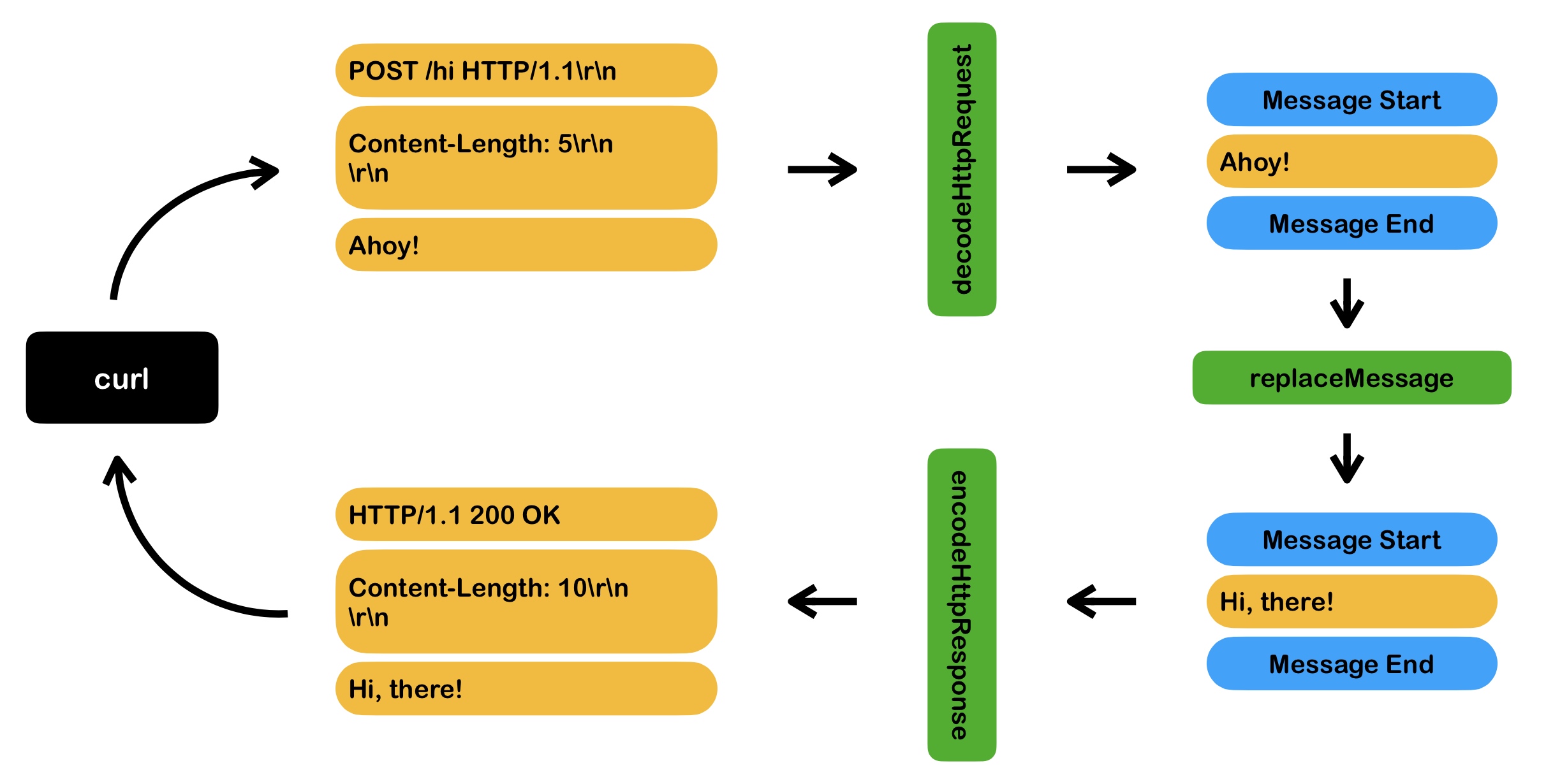
For example, the 007 logging configuration realizes the function of logging: recording the data of requests and responses and sending them to ElasticSearch in batches. Twelve filters are used here: fork, connect, onSessionStart, encodeHttpRequest, decodeHttpRequest, onMessageStart, onMessage, decodeHttpResponse, replaceMessage, link, mux and task.
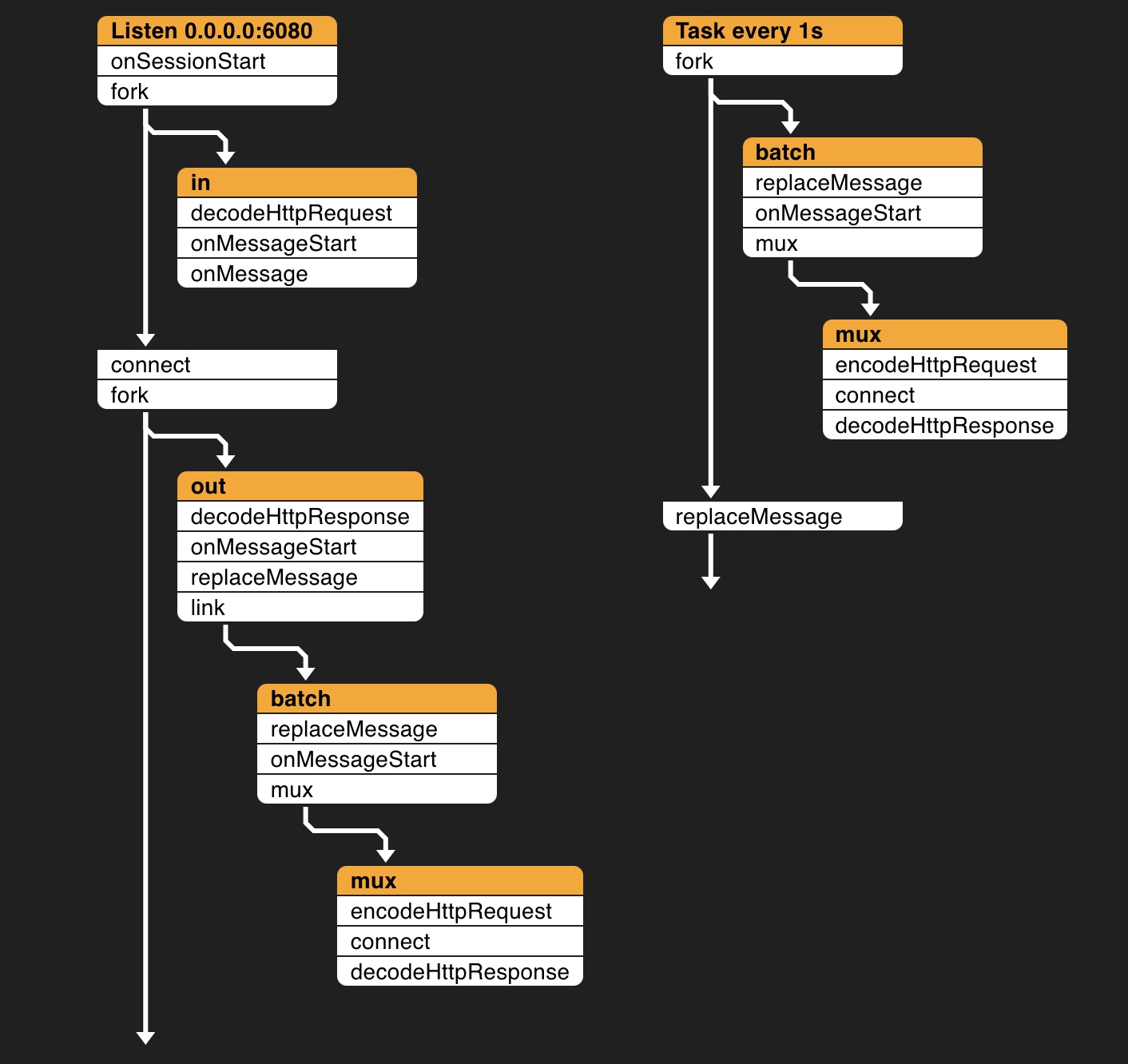
$ bin/pipy --list-filters connect (target[, options]) Sends data to a remote endpoint and receives data from it demux (target) Sends messages to a different pipline with each one in its own session and context decodeDubbo () Deframes a Dubbo message decodeHttpRequest () Deframes an HTTP request message decodeHttpResponse () Deframes an HTTP response message dummy () Eats up all events dump ([tag]) Outputs events to the standard output encodeDubbo ([head]) Frames a Dubbo message encodeHttpRequest ([head]) Frames an HTTP request message encodeHttpResponse ([head]) Frames an HTTP response message exec (command) Spawns a child process and connects to its input/output fork (target[, sessionData]) Sends copies of events to other pipeline sessions link (target[, when[, target2[, when2, ...]]]) Sends events to a different pipeline mux (target[, selector]) Sends messages from different sessions to a shared pipeline session onSessionStart (callback) Handles the initial event in a session onData (callback) Handles a Data event onMessageStart (callback) Handles a MessageStart event onMessageEnd (callback) Handles a MessageEnd event onSessionEnd (callback) Handles a SessionEnd event onMessageBody (callback) Handles a complete message body onMessage (callback) Handles a complete message including the head and the body print () Outputs raw data to the standard output replaceSessionStart (callback) Replaces the initial event in a session replaceData ([replacement]) Replaces a Data event replaceMessageStart ([replacement]) Replaces a MessageStart event replaceMessageEnd ([replacement]) Replaces a MessageEnd event replaceSessionEnd ([replacement]) Replaces a SessionEnd event replaceMessageBody ([replacement]) Replaces an entire message body replaceMessage ([replacement]) Replaces a complete message including the head and the body tap (quota[, account]) Throttles message rate or data rate use (module, pipeline[, argv...]) Sends events to a pipeline in a different module wait (condition) Buffers up events until a condition is fulfilled
principle
"Talk is cheap, show me the code."
Configuration loading
I prefer to look at the source code to understand the implementation, even C + +. Starting with the browser request, it is found that the runtime sent a POST request to / api/program. The content of the request is the address of the configuration file.
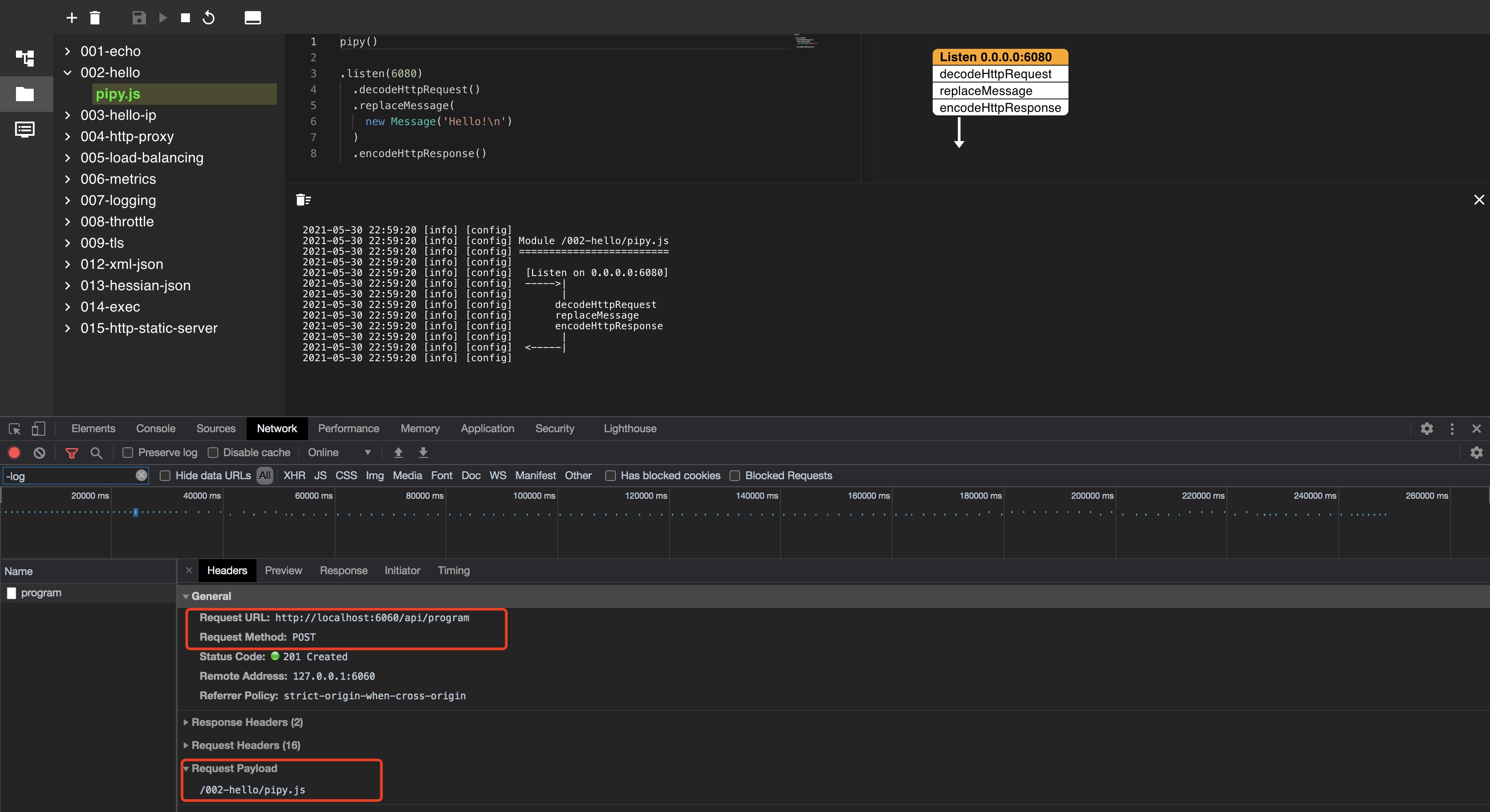
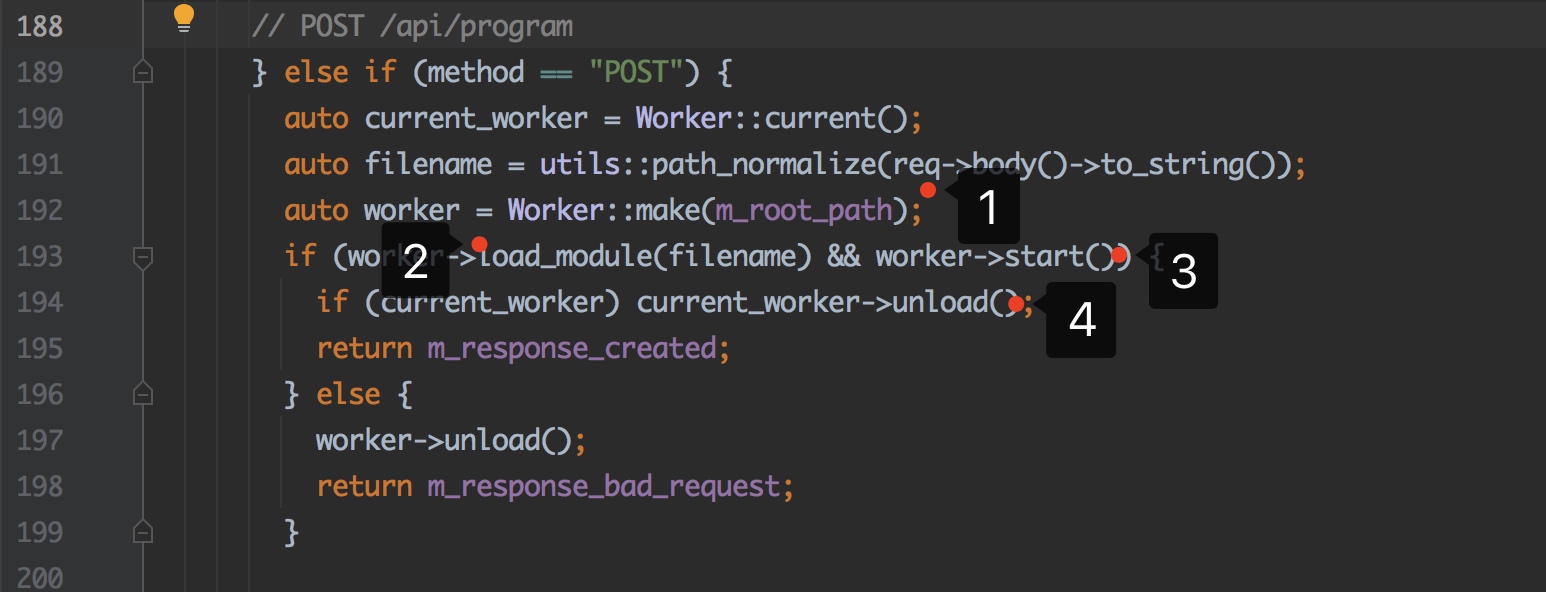
After checking the source code, find the implementation of the logic in Src / GUI cpp:189:
- Create a new worker
- Load the Configuration and parse the JavaScrip t code into a Configuration object
- Start the worker and execute Configuration::apply()
- Uninstall old worker
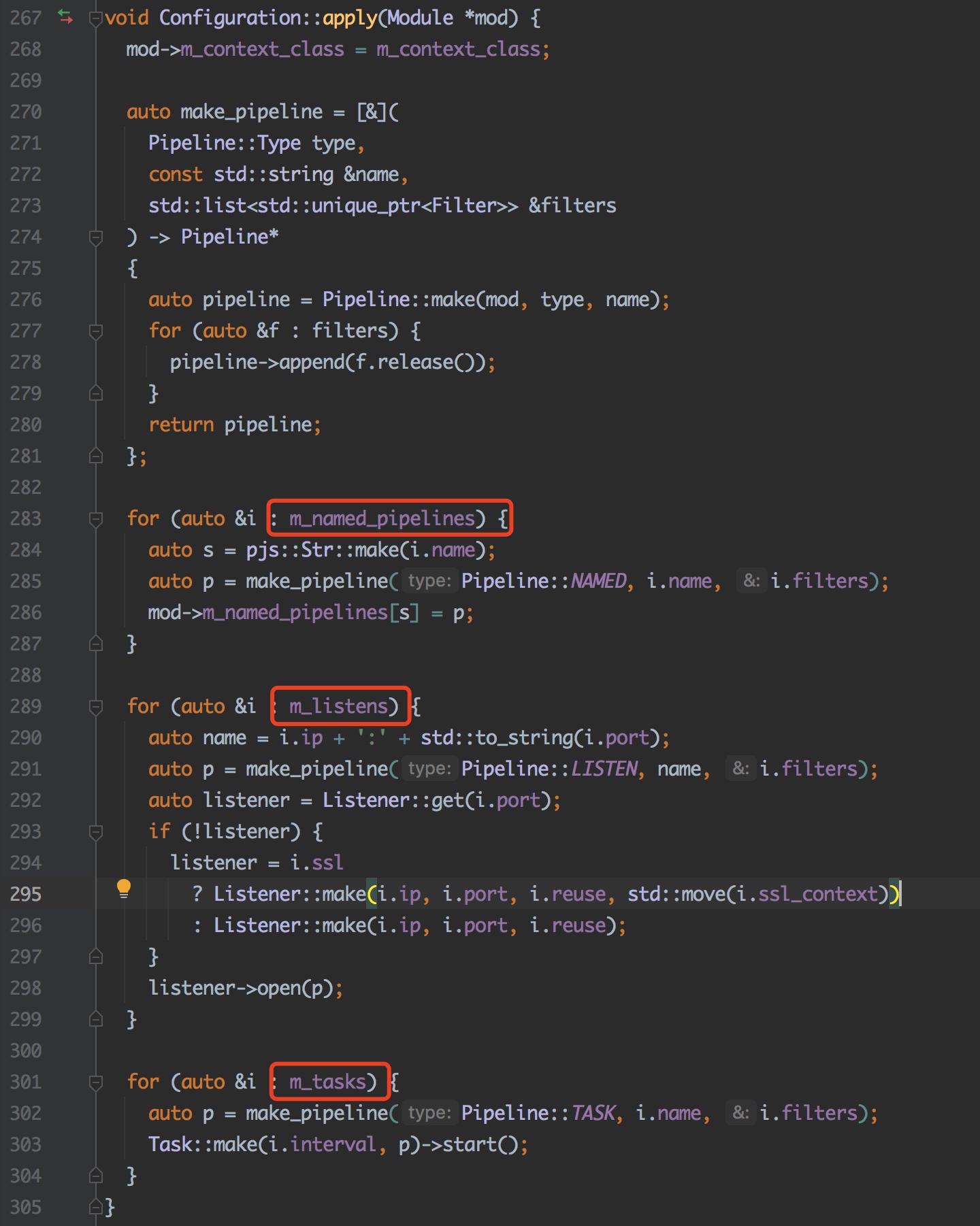
From Src / API / configuration CPP: 267: pipeline, listen and TASK configurations are actually abstracted as pipeline objects in the configuration of Pipy, but there are differences in types: NAMED, listen and TASK. For example, in listen, you can send a copy of the event to the specified pipeline through the fork filter.
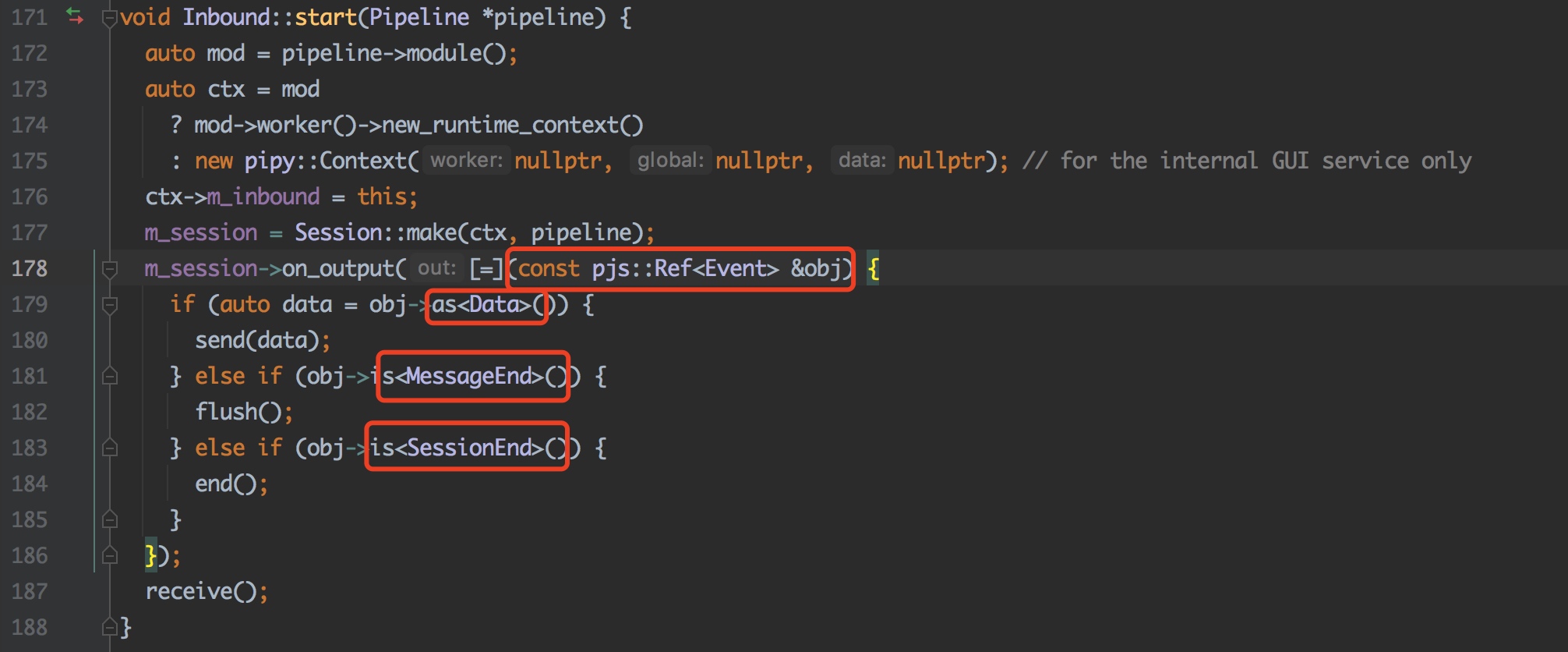
Event processing based on data flow
src/inbound.cpp:171
epilogue
Pipy is small (only 11M), but with its programmable characteristics, it provides flexible configuration capability and unlimited potential.
Pipy handles arbitrary seven layer protocols like HTTP. The internal version supports Dubbo, Redis, Socks, etc., and is currently migrating to the open source version.
Look forward to the upcoming open source Portal and the service grid Flomesh. Continue to pay attention and consider writing more articles later.
"The future can be expected!"
The article is unified in the official account of the cloud.
