Learning points of Java and big data development (under continuous update...)
Reference from HashMap? ConcurrentHashMap? I believe no one can stop you after reading this article!
1, Foreword
Key and value such as Map are very classic structures in software development. They are often used to store data in memory.
This article mainly wants to discuss concurrency container like ConcurrentHashMap. Before the official start, I think it is necessary to talk about HashMap to lead to subsequent ConcurrentHashMap.
2, HashMap
As we all know, the bottom layer of HashMap is based on array + linked list, but in jdk1 The specific implementation in 7 and 1.8 is slightly different.
Base 1.7
These are the core member variables in HashMap; See what they mean?
- Initialize the bucket size. Because the bottom layer is an array, this is the default size of the array.
- Maximum bucket_ CAPACITY.
- Default load factor_ LOAD_ FACTOR=0.75.
- table is an array that really stores data.
- Bucket size, which can be explicitly specified during initialization.
- Load factor, which can be specified explicitly during initialization.
Focus on the following load factors:
Because the capacity of a given HashMap is fixed, such as default initialization:
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
The given default capacity is 16 and the load factor is 0.75. During the use of Map, data is constantly stored in it. When the number reaches 16 * 0.75 = 12, the capacity of the current 16 needs to be expanded. This process involves rehash, copying data and other operations, so it consumes a lot of performance.
Therefore, it is generally recommended to estimate the size of HashMap in advance to minimize the performance loss caused by capacity expansion.
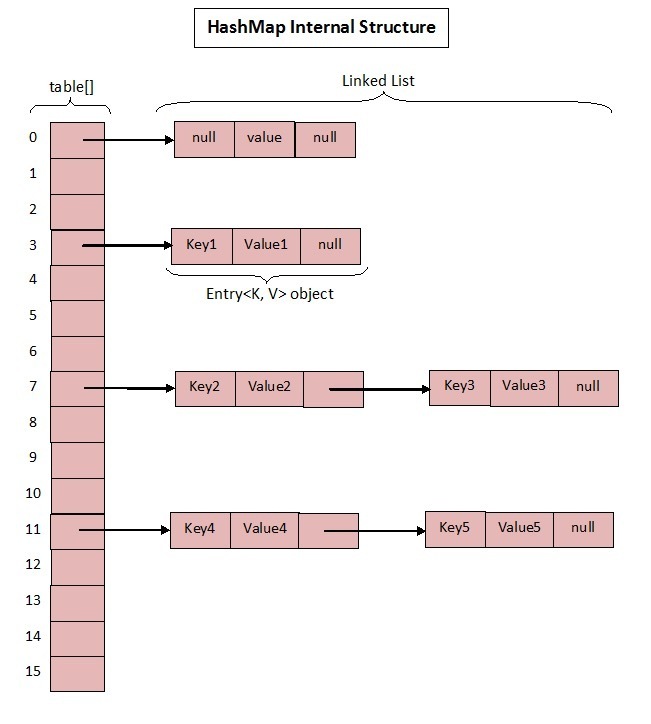
According to the code, you can see that what actually stores data is
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
How is this array defined?
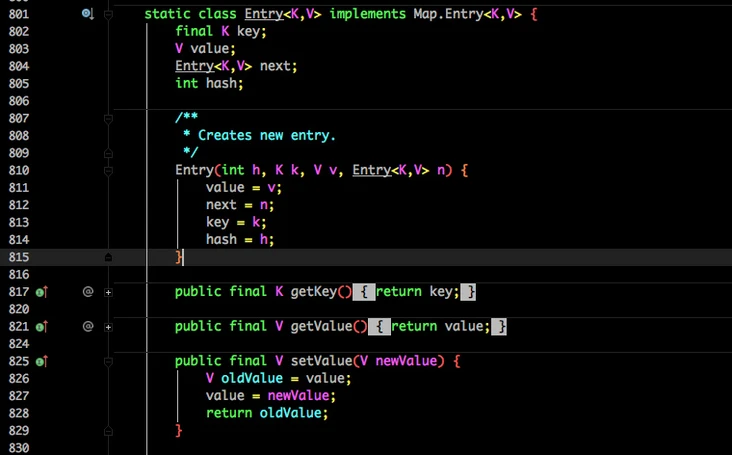
Entry is an internal class in HashMap. It is easy to see from its member variables:
- Key is the key when writing.
- Value is naturally value.
- At the beginning, I mentioned that HashMap is composed of arrays and linked lists, so this next is used to implement the linked list structure.
hash stores the hashcode of the current key.
After knowing the basic structure, let's take a look at the important write and get functions:
put method
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
- Determine whether the current array needs to be initialized.
- If the key is empty, put a null value into it.
- Calculate the hashcode according to the key.
- Locate the bucket according to the calculated hashcode.
- If the bucket is a linked list, you need to traverse to determine whether the hashcode and key in it are equal to the incoming key. If they are equal, overwrite them and return the original value.
- If the bucket is empty, it means that there is no data stored in the current location. Add an Entry object to write to the current location:
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
When calling addEntry to write Entry, you need to judge whether capacity expansion is required.
If necessary, double expand and re hash and locate the current key.
In createEntry, the bucket at the current location will be transferred into the new bucket. If the current bucket has a value, a linked list will be formed at the location.
get method
Let's look at the get function:
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
- First, calculate the hashcode according to the key, and then locate it in the specific bucket.
- Traverse the linked list until a node with equal key and hashcode is found.
- If you don't get anything, you can directly return null.
Base 1.8
I don't know the implementation of 1.7. Do you see the points that need to be optimized?
In fact, one obvious thing is:
When the Hash conflict is serious, the linked list formed on the bucket will become longer and longer, so the efficiency of query will be lower and lower, and the time complexity is O(N).
Therefore, 1.8 focuses on optimizing the query efficiency. The structure diagram after 1.8 is as follows:
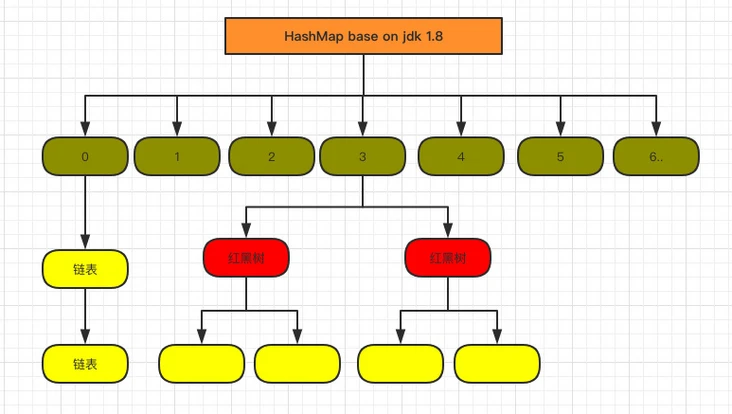
The core member variables are as follows:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int TREEIFY_THRESHOLD = 8;
transient Node<K,V>[] table;
/**
* Holds cached entrySet(). Note that AbstractMap fields are used
* for keySet() and values().
*/
transient Set<Map.Entry<K,V>> entrySet;
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
It is almost the same as 1.7, but there are still several important differences:
- TREEIFY_THRESHOLD is used to determine whether the linked list needs to be converted into a red black tree.
- The HashEntry is changed to node (the core composition of node is actually the same as the HashEntry in 1.7, which stores data such as key value hashcode next)
Let's look at the core method:
put method
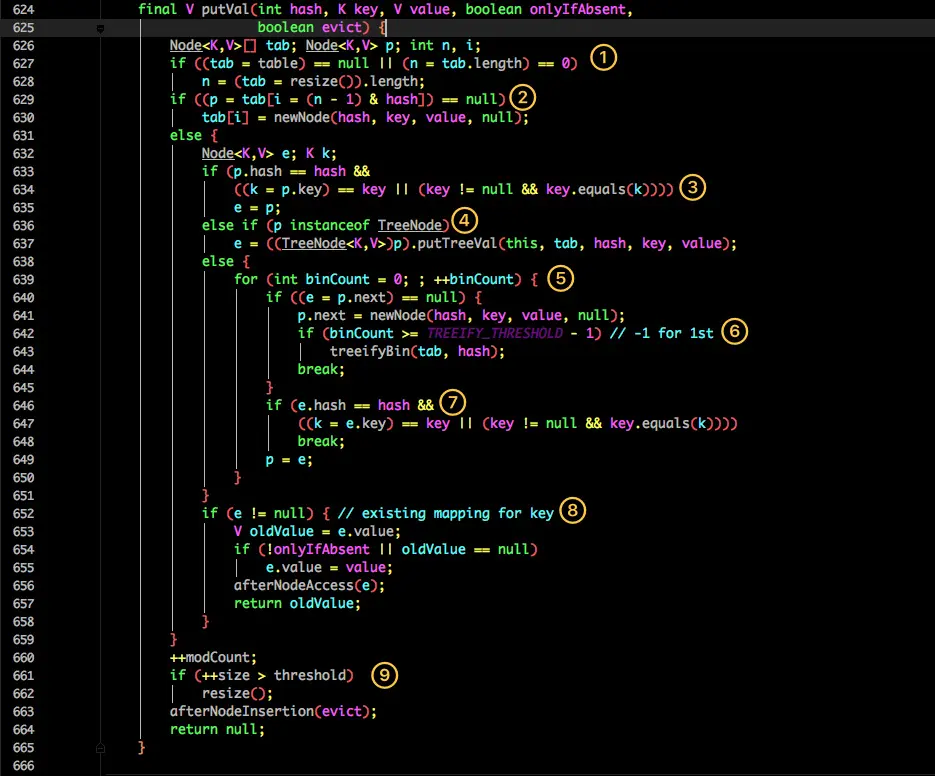
It seems to be more complex than 1.7. We disassemble it step by step:
- Judge whether the table is empty. If it is empty, it needs to be initialized (whether to initialize will be judged in resize).
- Locate the hashcode of the current key into a specific bucket and judge whether it is empty. If it is empty, it indicates that there is no hash conflict. Just create a new bucket at the current location.
- If the current bucket has a value (hash conflict), it is necessary to compare whether the key in the current bucket, the hashcode of the key and the corresponding key written are equal. If they are equal, they are assigned to e. in step 8, they will be assigned and returned uniformly.
- If the current bucket is a red black tree, the data should be written in the way of red black tree.
- If it is a linked list, you need to encapsulate the current key and value into a new node and write it to the back of the current bucket (add it to the head of the linked list).
- Then judge whether the size of the current linked list is greater than the preset threshold. If it is greater than, it will be converted to red black tree.
- If the same key is found during the traversal, exit the traversal directly.
- If e= Null is equivalent to the existence of the same key, so you need to overwrite the value.
- Finally, judge whether expansion is needed.
get method
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
The get method looks much simpler.
- First, hash the key and then get the positioned bucket.
- If the bucket is empty, null is returned directly.
- Otherwise, judge whether the key of the first position of the bucket (possibly linked list or red black tree) is the key of the query, and if so, directly return value.
- If the first one does not match, judge whether its next one is a red black tree or a linked list.
- The red black tree returns the value according to the search method of the tree.
- Otherwise, it will traverse the matching return value in the way of linked list.
From these two core methods (get/put), we can see that the large linked list is optimized in 1.8. After it is modified to red black tree, the query efficiency is directly improved to O(logn).
However, the original problems of HashMap also exist, such as:
(1) When used in concurrent scenarios, it is prone to dead cycles and data loss:
After reading the above, I still remember that the resize() method will be called when HashMap is expanded, that is, the concurrent operation here is easy to form a ring linked list on a bucket; In this way, when a nonexistent key is obtained, the calculated index is exactly the bucket where the ring linked list is located, and an endless loop will appear. At the same time, multiple threads expand at the same time, and the final result will lead to data loss.
(2) Modifying the value of the same key by multiple threads at the same time will lead to data overwrite:
The essence is to modify the invisibility and non atomicity of data, which makes the data modification unsafe in the concurrent scene of HashMap.
3, CurrentHashMap
Concurrent HashMap is also divided into versions 1.7 and 1.8, which are different in implementation.
Base 1.7
Let's take a look at the implementation of 1.7. Here is its structure diagram:
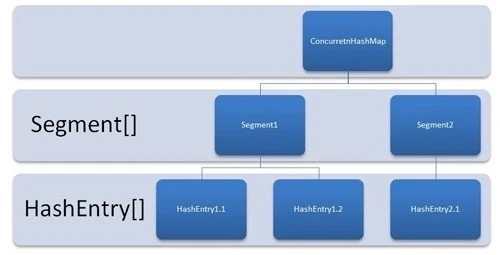
As shown in the figure, it is composed of Segment array and HashEntry. Like HashMap, it is still array + linked list.
Its core member variables are as follows:
/**
* Segment Array. When storing data, you first need to locate it in a specific Segment.
*/
final Segment<K,V>[] segments;
transient Set<K> keySet;
transient Set<Map.Entry<K,V>> entrySet;
Segment is an internal class of ConcurrentHashMap. Its main components are as follows:
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
// The function of HashEntry in HashMap is the same as that of the bucket for storing data
transient volatile HashEntry<K,V>[] table;
transient int count;
transient int modCount;
transient int threshold;
final float loadFactor;
}
See the composition of HashEntry:
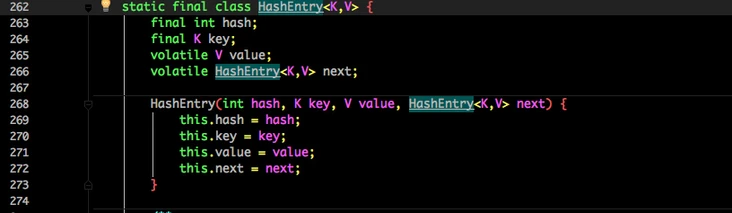
It is very similar to HashMap. The only difference is that the core data such as value and linked list are modified by volatile to ensure the visibility during acquisition.
In principle, ConcurrentHashMap adopts Segment lock technology, in which Segment inherits ReentrantLock. Not like HashTable, both put and get operations need to be synchronized. Theoretically, ConcurrentHashMap supports thread concurrency of currencylevel (the number of Segment arrays is 16). Every time a thread accesses a Segment using a lock, it will not affect other segments.
The core put and get methods are as follows:
put method
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
First, locate the Segment through the key, and then make specific put in the corresponding Segment:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
Although the value in HashEntry is modified with volatile keyword, it does not guarantee the atomicity of concurrency, so it still needs to be locked during put operation.
First, in the first step, you will try to obtain the lock. If the acquisition fails, there must be competition from other threads. Then you can use scanAndLockForPut() to spin to obtain the lock.
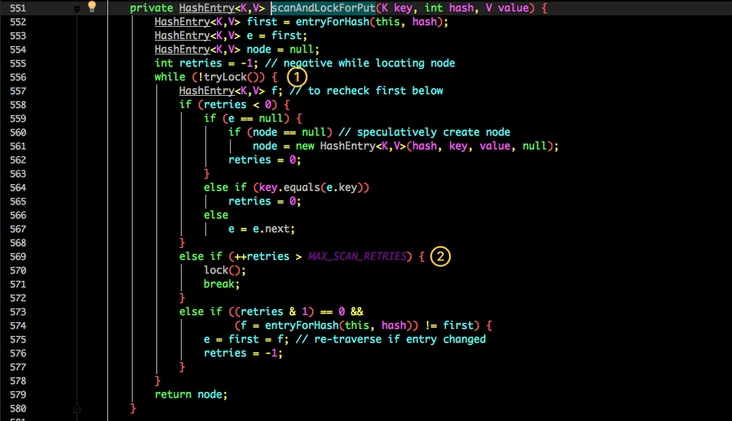
The typical idea of lock upgrade is used here: first, lightweight lock CAS + cycle contention, and then heavyweight lock() blocks threads after reaching a certain number of times.
- Try to acquire the lock.
- If the number of retries reaches max_ SCAN_ Restries is changed to block lock acquisition to ensure success.
Continue back to the put process:
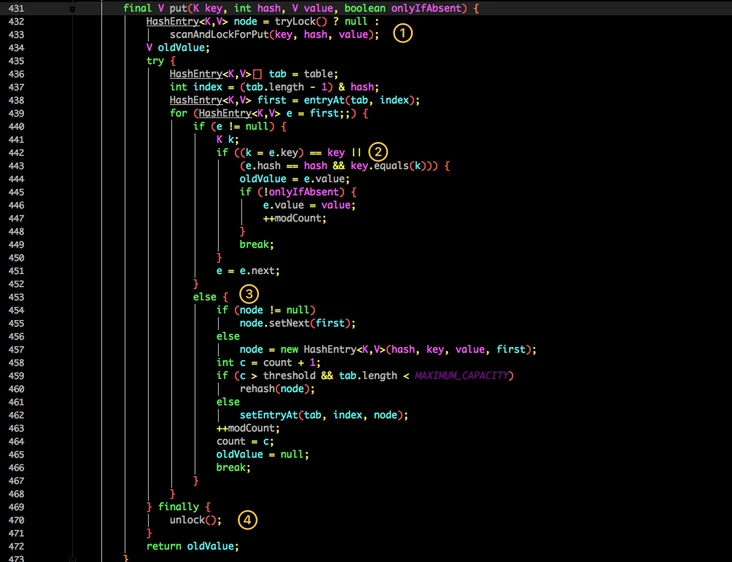
- Locate the table in the current Segment to the HashEntry through the hashcode of the key.
- Traverse the HashEntry. If it is not empty, judge whether the passed in key is equal to the currently traversed key. If it is equal, overwrite the old value.
- If it is not empty, you need to create a HashEntry and add it to the Segment. At the same time, you will first judge whether you need to expand the capacity.
- Finally, the lock of the current Segment obtained in 1 will be released.
get method
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
The get logic is relatively simple:
You only need to locate the Key to the specific Segment after passing through the Hash, and then locate the Key to the specific element through the Hash again.
Because the value attribute in HashEntry is decorated with volatile keyword to ensure memory visibility, it is the latest value every time it is obtained.
The get method of ConcurrentHashMap is very efficient, because the whole process does not need to be locked.
Base 1.8
1.7 has solved the concurrency problem and can support the concurrency of N segments for so many times, but there is still the problem of HashMap in version 1.7.
- The efficiency of query traversal linked list is too low.
- By observing HashMap and concurrenthashmap1 In fact, the segmented lock is an additional implementation, which is really unnecessary. Just lock the HashEntry bucket directly, so that the concurrency can increase with the increase of capacity.
Therefore, some data structure adjustments have been made in 1.8.
First, let's look at the composition of the bottom layer:
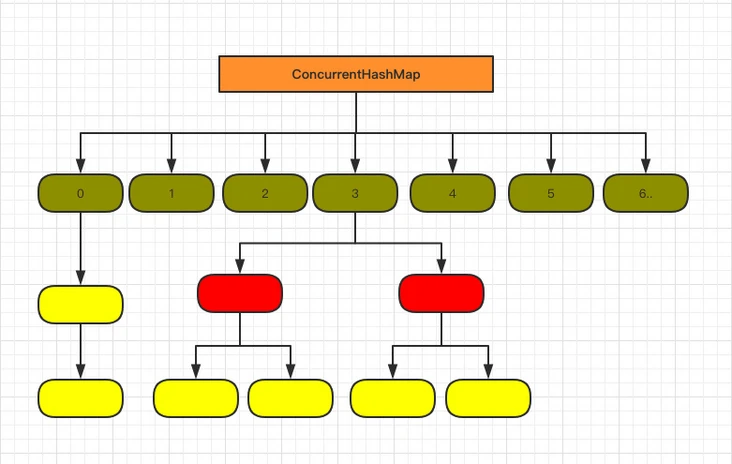
Does it look similar to the 1.8 HashMap structure?
The original Segment lock is abandoned and CAS + synchronized is used to ensure concurrency security.
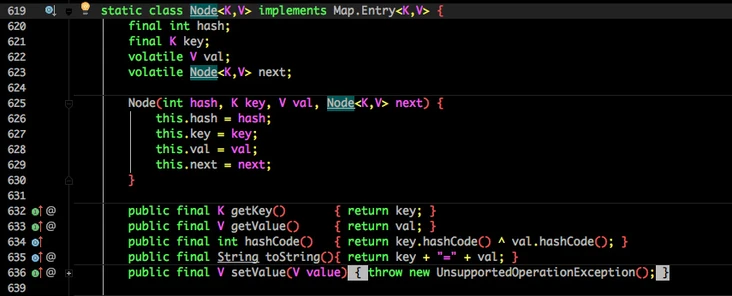
The HashEntry storing data in 1.7 is also changed to Node, but the function is the same.
val next is decorated with volatile to ensure visibility.
put method
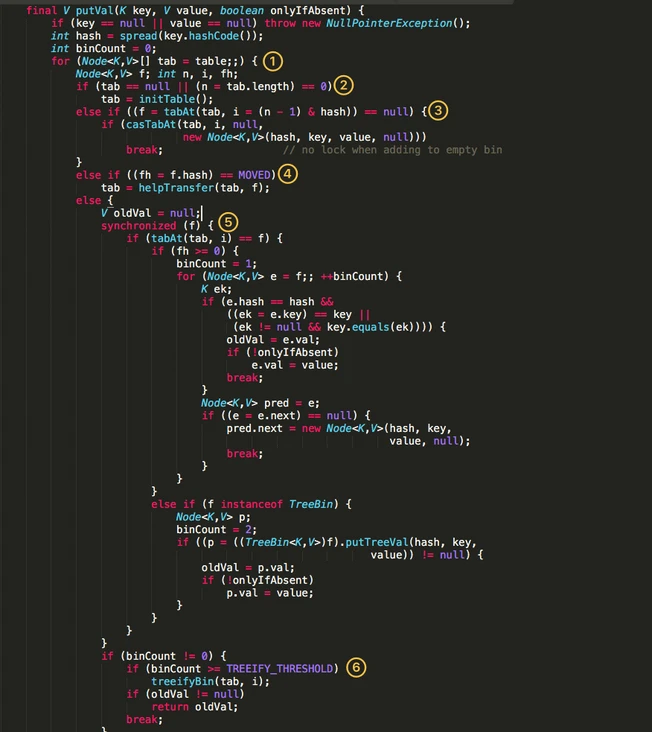
- An infinite loop of for to complete initialization, capacity expansion and new node operations.
- Determine whether initialization is required.
- f is the Node located by the current key. If it is empty, use CAS to try to create a new linked list. If it fails, it is guaranteed to succeed.
- If hashcode == MOVED in the current location, capacity expansion is required.
- If none is satisfied, data can be written in the synchronized synchronization code block.
- If the number of nodes in the linked list is greater than try_ Threshold is converted to red black tree.
get method
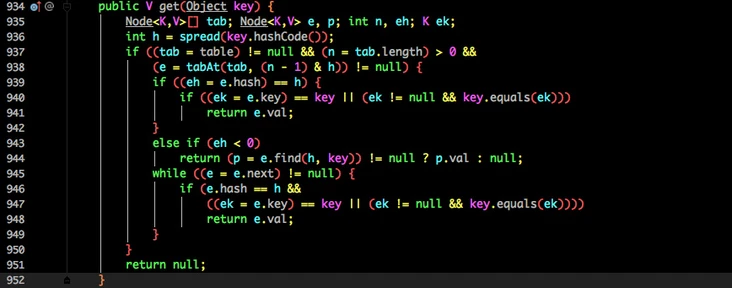
Similarly, the get method does not need to be locked:
- According to the calculated hashcode addressing, if it is on the bucket, the value will be returned directly.
- If it is a red black tree, get the value as a tree.
- If it is not satisfied, traverse and obtain the value in the way of linked list.
In summary, jdk1 In 8, ConcurrentHashMap gives up the segment lock in 1.7 and locks the bucket chain header to ensure the security of data modification (CAS is used when creating a new linked list when the bucket is empty, because CAS is more lightweight when modifying a single variable). And the red black tree is also used to optimize the efficiency of searching in the same bucket.