Thread pool principle
It is very convenient for Java to create a thread. It only needs new Thread(). However, when there are multiple tasks to be processed, frequent thread creation and enabling also requires system overhead and is not conducive to management. Therefore, like mysql connection pool, there is naturally a thread management pool, that is, thread pool.
As an analogy, a thread pool is like a company, so threads themselves are employees to manage the creation and destruction of threads and maximize the rational scheduling of resources.
The creation of Java thread pool is also very simple. Executors are included in the concurrent package, which can easily create four common threads:
newFixedThreadPool: creates a thread pool with a fixed number of threads, which can control the maximum number of concurrent threads. It is often used to know the number of specific tasks. Multi threading operations are required, such as batch inserting database tasks. 100000 data pages are required. One thread is configured for every 10000 data pages. A total of 10 threads are configured for parallel batch inserting, You can use this thread pool to greatly reduce the response time
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}newCachedThreadPool: create a thread pool that can be reused for a period of time. It is often used when the specific number of tasks is unknown but parallel processing is required. For example, springboot @Aysnc can specify to use this thread pool for asynchronous processing of various businesses such as buried points
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}Newsinglethreadexecution: create a thread pool for a single thread. This thread pool can restart a thread after the thread dies (or when an exception occurs) to continue executing instead of the original thread!
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}newScheduledThreadPool: create a thread pool that can be executed regularly and repeatedly, which is commonly used for the execution thread pool of scheduled tasks and delayed tasks
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory);
}Of course, the thread pool can also be customized. Java only provides several common methods for creating static thread pools. The source codes of the four thread pools have been shown above. It can be found that the creation of thread pools is realized through new ThreadPoolExecutor(). Now we mainly introduce the following important parameters and interfaces:
Firstly, ThreadPoolExecutor inherits the AbstractExecutorService class and provides four constructors. AbstractExecutorService implements the ExecutorService interface, which inherits the Executor with only one method execute.
The meanings of the parameters in the constructor are explained below:
- corePoolSize: the size of the core pool. This parameter is closely related to the implementation principle of the thread pool described later. After a thread pool is created, by default, there are no threads in the thread pool. Instead, a thread is created to execute a task when a task arrives, unless the prestartAllCoreThreads() or prestartCoreThread() methods are called. From the names of these two methods, we can see that they mean pre created threads, That is, create a corePoolSize thread or a thread before the task arrives. By default, after the thread pool is created, the number of threads in the thread pool is 0. When a task comes, a thread will be created to execute the task. When the number of threads in the thread pool reaches the corePoolSize, the arriving task will be placed in the cache queue;
- maximumPoolSize: the maximum number of threads in the thread pool. This parameter is also a very important parameter. It indicates the maximum number of threads that can be created in the thread pool;
- keepAliveTime: indicates how long the thread will terminate if it has no task to execute. By default, keepAliveTime works only when the number of threads in the thread pool is greater than corePoolSize, until the number of threads in the thread pool is not greater than corePoolSize, that is, when the number of threads in the thread pool is greater than corePoolSize, if a thread is idle for keepAliveTime, it will terminate until the number of threads in the thread pool does not exceed corePoolSize. However, if the allowCoreThreadTimeOut(boolean) method is called and the number of threads in the thread pool is not greater than corePoolSize, the keepAliveTime parameter will also work until the number of threads in the thread pool is 0;
- Unit: the time unit of the parameter keepAliveTime. There are seven values, representing one time unit: second, minute, hour, etc
- workQueue: a blocking queue used to store tasks waiting to be executed. The selection of this parameter is also very important and will have a significant impact on the running process of the thread pool. Generally speaking, the blocking queue here has the following options:
ArrayBlockingQueue; The bounded blocking queue is implemented by an array, and the array size needs to be specified LinkedBlockingQueue; Unbounded blocking queue, implemented by linked list, the maximum value is Integer Maximum value of SynchronousQueue; This queue will not save the submitted task, but will directly create a new thread to execute the new task.
- threadFactory: thread factory, mainly used to create threads;
- handler: indicates the policy when processing a task is rejected. There are four values:
ThreadPoolExecutor.AbortPolicy:Discard task and throw RejectedExecutionException Abnormal. ThreadPoolExecutor.DiscardPolicy: It also discards the task without throwing an exception. ThreadPoolExecutor.DiscardOldestPolicy: Discard the task at the top of the queue, and then try to execute the task again (repeat the process) ThreadPoolExecutor.CallerRunsPolicy: The task is handled by the calling thread
Note that these parameters are modified by volatile to ensure the visibility under multithreading. We can also generate the thread pool we need according to different configurations of these parameters.

After having a thread pool, we need to pay attention to the status of several thread pools:
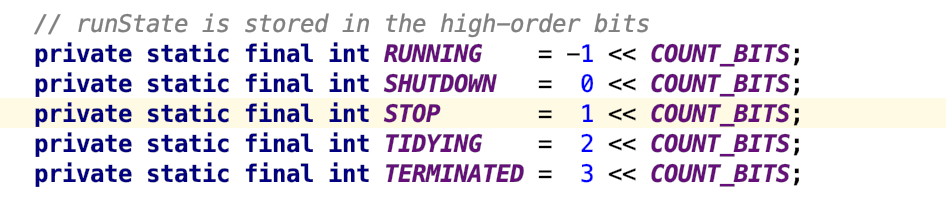
The following figure shows the transformation relationship between several states:
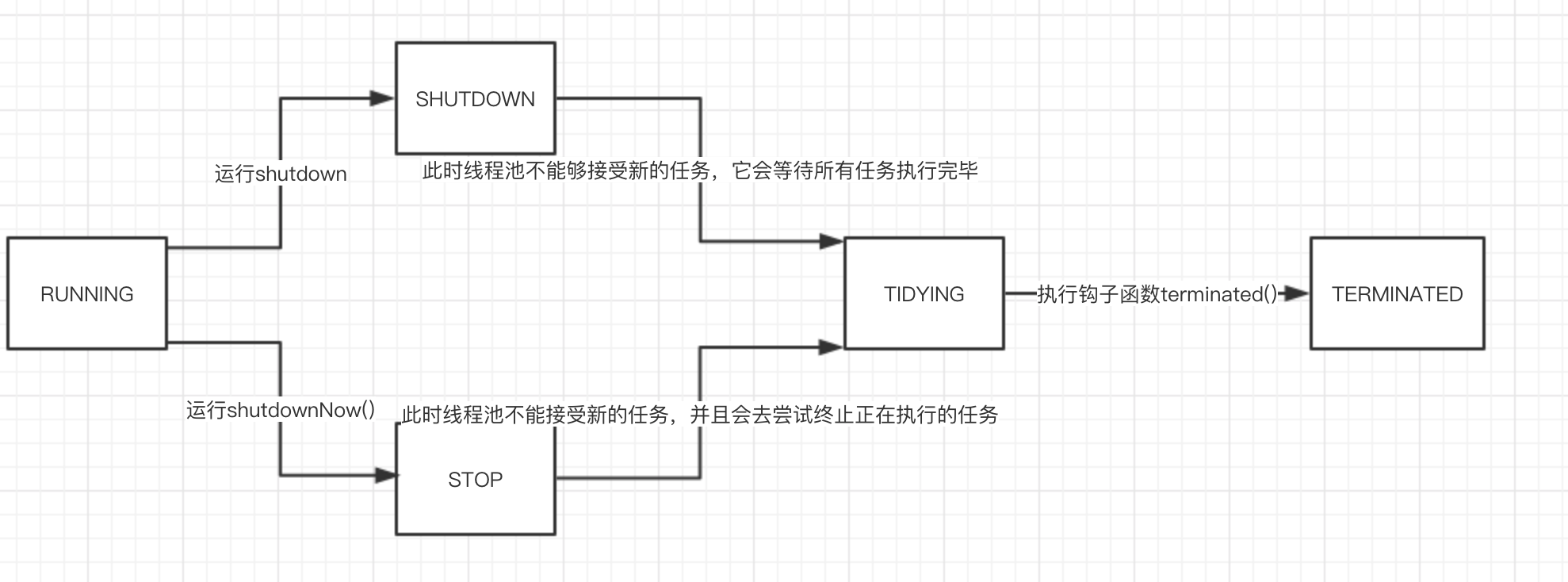
Next is a chestnut to show how to use:
ExecutorService executorService = Executors.newFixedThreadPool(15);
After executing the above code, we actually created a thread pool with 15 core threads, the maximum is 15 threads, the storage time of idle threads is 1 minute, infinite blocking queue is adopted, and AbortPolicy is adopted for task rejection: discard the task and throw RejectedExecutionException exception. After creation, no active thread workers are generated, and the number of available threads is 0. For example, if 10 tasks come in, 10 thread workers will be created to work, and they will not be destroyed after work. Then there are 10 tasks, and the previous 10 threads have not completed their own tasks, At this time, five thread workers will be created to process the tasks. If there is any doubt about it, what about the remaining five tasks? By the way, there is a blocking queue. These tasks without workers will enter the blocking queue like to-do items, first in, first out, and be processed in turn after 15 workers finish their work, Because the blocking queue is an unbounded blocking queue, tasks will be continuously thrown into the queue. Therefore, it will not be created. Because the queue is too small, several temporary workers have to be created to process. These numbers are the difference between the maximum thread and the core thread. The effective time of these temporary threads is only keepAliveTime, In addition, after multiple tasks arrive, if the queue is bounded and the number of tasks exceeds the maximum number of threads that can be created, that is, workers can no longer be recruited and the to-do list is full, the company will quit, throw an exception and reject the task policy.
Next is the actual combat, which is displayed in combination with completable future:
A brief introduction to completable Future: completable Future provides a very powerful extension of Future, which can help us simplify the complexity of asynchronous programming, and provides the ability of functional programming. It can process the calculation results through callback, and also provides the method of converting and combining completable Future. Combined with thread pool, it can achieve the purpose of concurrent programming
package cn.chinotan;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import java.util.List;
import java.util.concurrent.*;
/**
* @program: test
* @description: Multithreading test
* @author: xingcheng
* @create: 2019-03-23 17:27
**/
@Slf4j
public class ExecutorTest {
@Test
public void test() {
ExecutorService executorService = Executors.newFixedThreadPool(15);
CompletableFuture[] completableFutures = new CompletableFuture[15];
List<Integer> integers = new CopyOnWriteArrayList<>();
for (int i = 0; i < 15; i++) {
int finalI = i;
CompletableFuture<Integer> integerCompletableFuture = CompletableFuture.supplyAsync(() -> costMethod(finalI), executorService)
.whenComplete((r, e) -> {
if (null != e) {
e.printStackTrace();
} else {
integers.add(r);
}
});
completableFutures[i] = integerCompletableFuture;
}
CompletableFuture.allOf(completableFutures).join();
long count = integers.stream().count();
log.info("Successfully processed:{}", count);
}
/**
* Time consuming operation
*
* @param i
* @return
*/
public int costMethod(int i) {
try {
TimeUnit.SECONDS.sleep(5);
log.info("Time consuming operation {}", i);
return 1;
} catch (InterruptedException e) {
e.printStackTrace();
return 0;
}
}
}Operation results:
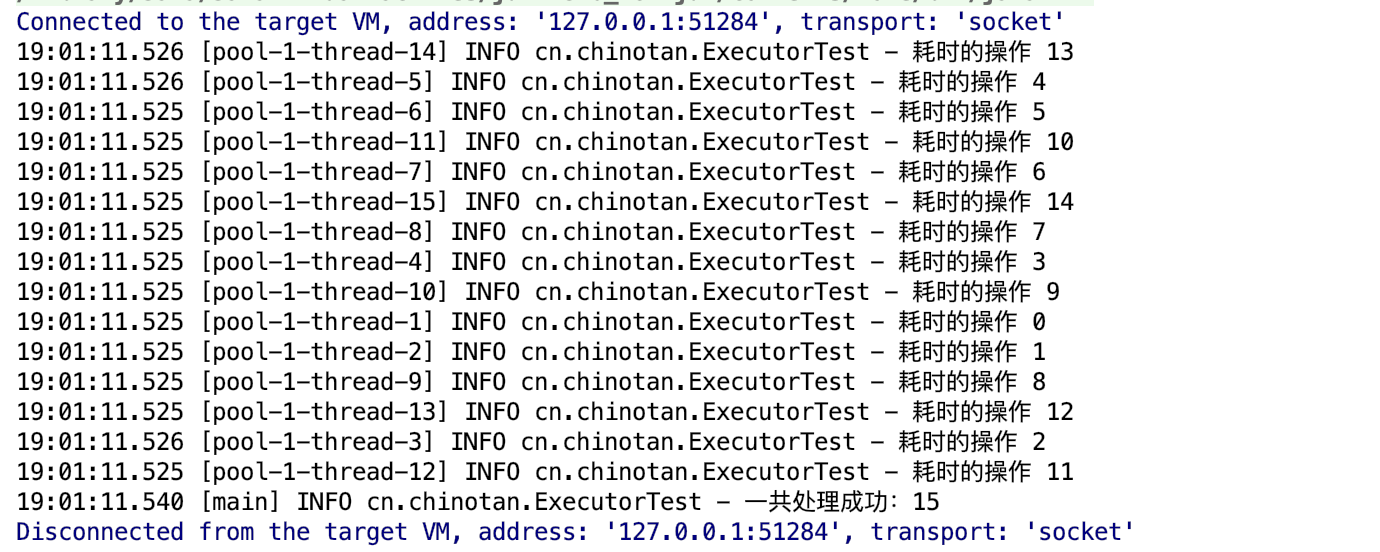
You can see that 15 time-consuming operations are completed in parallel soon, and the number of successful results can be returned
The above is my understanding and application of thread pool. Welcome to pay attention, browse and ask questions. Thank you