I. Preface
The ijcai article published in 2017 mainly uses FM and attention mechanism to recommend items, and achieves good results.
The address of the paper is: https://www.ijcai.org/proceedings/2017/0435.pdf
2. Algorithmic Principle
(1) Firstly, the overall framework of the model gives a weight to the result of factor decomposition, which is obtained by learning to express the degree of concern between different features.
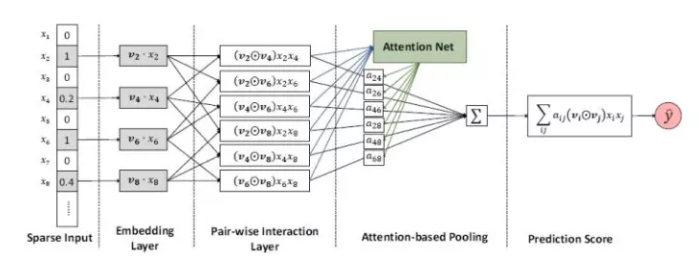
(2) The whole model can be expressed by the following formulas: the first-order part and the second-order part of attention mechanism;

(3) The realization of the attention part, the following is a way to realize the attention mechanism, called the multiplicative attention mechanism. Specifically, the realization can refer to the code, and then through a software Max layer, after normalization, get a weight;
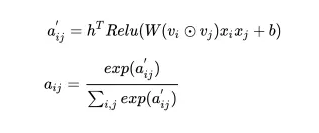
(4) The loss function used in the model is as follows.
(5) Improvement strategy of the model, I have checked the articles of other big men. Because the features of the second item are not crossed through a DNN layer after crossing, it may not be better to learn the deeper crossing features, so we can add a DNN layer, which may get a better result.
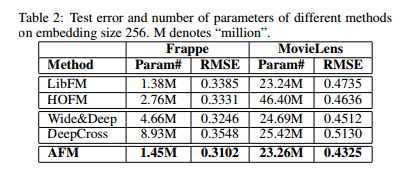
III. EXPERIMENTAL EFFECT
The experimental results of different models are compared. The following figure is the schematic diagram of convergence effect in the original paper.
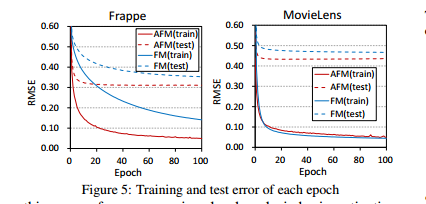
It is explained in the paper that deepcross has the worst effect in this area. The reason may be that deep layers and high complexity of the model have already appeared the problem of fitting.
So sometimes the deeper the model is, the better the effect is.
4. Code Implementation
The code implementation part only implements the attention mechanism of the core part, while the other parts need to be supplemented by themselves.
from tensorflow.python.keras.layers import Layer
from tensorflow.python.keras.initializers import glorot_normal, Zeros
import tensorflow as tf
import itertools
class afm(Layer):
def __init__(self, attention_size=4, seed=1024, **kwargs):
self.seed = seed
self.attention_size = attention_size
super(afm, self).__init__(**kwargs)
def build(self, input_shape):
embed_size = input_shape[-1].value
self.att_w = self.add_weight(name='att weights', shape=(embed_size, self.attention_size), initializer=glorot_normal(self.seed))
self.att_b = self.add_weight(name='att bias', shape=(self.attention_size, ), initializer=Zeros())
self.projection_h = self.add_weight(name='projection_h', shape=(self.attention_size, 1), initializer=glorot_normal(self.seed))
self.projection_p = self.add_weight(name='projection_p', shape=(embed_size, 1), initializer=Zeros())
self.tensordot = tf.keras.layers.Lambda(lambda x : tf.tensordot(x[0], x[1], axes=(-1, 0)))
super(afm, self).build(input_shape)
def call(self, inputs):
embed_vec_list = inputs
row = []
col = []
for r, w in itertools.combinations(embed_vec_list, 2):
row.append(r)
col.append(w)
p = tf.concat(row, axis=1)
q = tf.concat(col, axis=1)
inner_product = p * q
att_tmp = tf.nn.relu(tf.nn.bias_add(tf.tensordot(inner_product, self.att_w, axes=(-1, 0)), self.att_b))
self.att_normalized = tf.nn.softmax(tf.tensordot(att_tmp, self.projection_h, axes=[-1, 0]), dim=1)
att_output = tf.reduce_sum(self.att_normalized * inner_product, axis=1)
att_output = tf.keras.layers.Dropout(0.2, seed=self.seed)
afm_out = tf.tensordot(att_output, self.projection_p)
return afm_out