The following describes an advanced data structure based on a single-chain table, jump table.
Sort the single-chain list first, then for the ordered list For efficient lookup, jump tables can be used as a data structure.
Its basic idea is the idea of dichotomous search.
The precondition for jumping tables is In the light of Ordered single-chain list for efficient search, insertion, deletion.
Ordered set sorted in Redis It is achieved by jumping tables.
1. Principle of Jump Table
For single-chain tables, even the stored ordered data (i.e. ordered chain table) can only be traversed from beginning to end in order to find a certain data, which is inefficient and time-complex as O(n), as shown in the following figure:
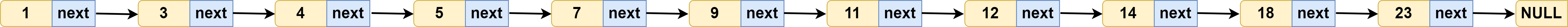
How can I improve search efficiency?
In order to improve the efficiency of searching, a first-level "index" is built on the ordered chain table using the idea of binary search.One node per two nodes is extracted to the index layer. Each node in the index layer contains two pointers, one pointing to the next node and one pointing down to the next node.

Suppose you want to find the 18 node in the graph:
First traverse in the first index level, when traversing to 14 nodes, found that its next node is 23, then the 18 to find is between 14 and 23. Then, through the 14-node Down pointer, down to the original list, continues to traverse through the original list. At this point, you only need to traverse two nodes, 14 and 18, in the original list to find 18. Finding 18 nodes requires traversing 10 nodes in the original chain table, but now only 7 nodes (five in the first index level and two in the original chain table).
From the example above, it can be seen that with a layer of index, the number of traversal nodes to find a node is reduced and the efficiency is improved.Would it be more efficient to add another level of index?
Create secondary index
Similar to creating a first-level index, on the basis of the first-level index, one node is extracted from each of the two nodes to the second-level index, as shown in the following figure:

Now, if you want to find 18 nodes, you only need to traverse 6 nodes (secondary index level traverses 3 nodes, primary index level 1 node, and original chain table 2 nodes).
By indexing, the more data the ordered list is, the more efficient the search will be by building a multilevel index.
This chain table with multilevel index structure Namely Jump table.
2. Jump Table Time Complexity And spatial complexity
Query Time Complexity of 2.1 Jump Table
Assuming a chain table contains n nodes, the time complexity of querying a data in a single-chain table is O(n).
How many levels of indexes can an ordered single-chain table with n nodes have at most?
If one node is extracted from each of the two nodes as the node of the previous index level, then:
The number of nodes in the first level index is approximately n/2, the number of nodes in the second index is about n/4, and the number of nodes in the third index is about n/8, then the number of k-level index nodes is approximately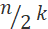 .
.
Assume h Level index, the highest level index has two nodes, that is 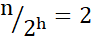 And then get
And then get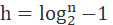 If the original chain table is also included, the height of the jump table is about
If the original chain table is also included, the height of the jump table is about 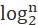

In jump table queries, each index level needs to traverse up to three nodes.
(Because suppose in the jump table above, look up from the secondary index level Node 12, traverse from Node 1 to Node 7, then traverse Node 14 (Node 12 is less than Node 14), traversing from Node 7 to the next index level to Node 7, then right to Node 11, and then through Node 14, node 12 is found to be less than Node 14. Then continue traversing down to node 12 at the next level.
In the process of traversing node 12 above, three nodes (1->7---->14) are traversed in the secondary index level and three nodes (7->11-->14) are traversed in the primary index level.So each level traverses up to three nodes.)
So the time complexity of querying data in a jump table is Number of nodes traversed per layer multiplied by number of layers _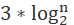 Therefore, the time complexity of the lookup in the jump table is O(logn). The time complexity is the same as that of a binary search.
Therefore, the time complexity of the lookup in the jump table is O(logn). The time complexity is the same as that of a binary search.
Binary lookup based on single-chain table is implemented, and the improvement of query efficiency depends on the construction of a multilevel index, which is a space-for-time design idea.
2.2 Spatial Complexity
Total index point spatial complexity after indexing:
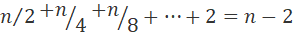
The spatial complexity of the query data for a jump table is O(n), which means that constructing a jump table based on a single-chain table requires an additional double of the storage space.
Is there any way to reduce the storage space occupied by the index?
If every 3 nodes or every 5 nodes draws one node to the next index level, the number of index nodes will be reduced accordingly.Assuming that one node per 3 nodes is selected to the next level, the total number of index nodes is:
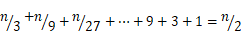
Method of extracting 1 node per 3 nodes to the index level above This reduces the storage space of index nodes by half compared to the way that one node per two nodes is selected to build the index.
Therefore, by adjusting the spacing of the extracted nodes, the storage space occupied by index nodes is controlled to achieve a balance between space complexity and time complexity.
3. Insertion and deletion of jump tables
As a dynamic data structure, jump tables support not only lookup but also insertion and deletion of data. The time complexity of insert and delete operations is O(logn).
3.1 Insert operation
To ensure the ordering of the data in the original chain table, we need to first find where the new data should be inserted.You can quickly find the insertion location of new data based on a multilevel index with O(log n) time complexity.
Suppose you insert a node with data 6 as follows:

3.2 Delete operation
Delete the node in the original chain table, and also delete the node in the index if it exists in the index.Because deletion in a single-chain list requires a front-drive node to delete the node.The deletion can be accomplished by iterating down the original chain table through the index layer by layer, recording the precursor nodes to be deleted.
4. Dynamic Update of Jump Table Index
When frequently inserting data into a jump table, if the insertion process is not accompanied by an index update, it may result in a very large amount of data between two index nodes. In extreme cases, the jump table will degenerate into a single-chain table.
As a dynamic data structure, in order to avoid performance degradation, we need to update the index structure of jump tables dynamically during data insertion and deletion. Like a red-black tree, a binary balance tree maintains the size balance of left and right subtrees by rotating left and right, while a jump table updates the index structure by using random functions.
When inserting data into the jump table, we choose to insert the data into some index layers at the same time.How do I decide which index layers to insert?Decide by a random function, such as by If the random function gets a value K, then the node is added to the first to the K level index.
V. Summary
Why are ordered collections in Redis implemented using jump tables instead of red-black trees?
1. For insert, delete, find and output ordered sequence operations, the red-black tree can also be completed, the time complexity is the same as that achieved with a jump table.However, for the operation of finding data by intervals (e.g. [20,300]), the efficiency of red-black trees is not as high as the jump table, which locates the start of an interval with O(logn) time complexity, and then sequentially traverses the output backwards in the original chain table until a node with a value greater than the end of the interval is encountered.
2. The jump table is more flexible, it can balance the space and time complexity flexibly by changing the extraction interval of nodes.
3. Compared with red and black trees, jumping tables is easier and the code is simpler.
6. Code implementation
1.C+ (refer to Leetcode1206 problem solving)
struct Node
{
//Right Down Pointer
Node* right;
Node* down;
int val;
Node(Node *right, Node *down, int val)
: right(right), down(down), val(val){}
};
class Skiplist {
private:
Node *head;
// Improve performance after pre-allocation
const static int MAX_LEVEL = 32;
// Variables temporarily used in lookup
vector<Node*> pathList;
public:
Skiplist() {
//Initialize header nodes
head = new Node(NULL, NULL, -1);
pathList.reserve(MAX_LEVEL);
}
bool search(int target)
{
Node *p = head;
while(p)
{
// Search left and right for target interval
while(p->right && p->right->val < target)
{
p = p->right;
}
// If no target is found, move on
if(!p->right || target < p->right->val)
{
p = p->down;
}
else
{
//Find target value, end
return true;
}
}
return false;
}
void add(int num) {
//Record search paths from top to bottom
pathList.clear();
Node *p = head;
// Searching for numbers less than num from top to bottom is equivalent to prevs in another implementation
while(p)
{
// Find p less than num to the right
while (p->right && p->right->val < num)
{
p = p->right;
}
pathList.push_back(p);
p = p->down;
}
bool insertUp = true;
Node* downNode = NULL;
// Search path backtracking from bottom to search, 50% probability
// This implementation guarantees that the current number of layers will not be exceeded, and then adds additional layers by the end node, one layer at a time
while (insertUp && pathList.size() > 0)
{
Node *insert = pathList.back();
pathList.pop_back();
// add new node
insert->right = new Node(insert->right,downNode,num);
// Assign the new node to downNode
downNode = insert->right;
// 50% probability
insertUp = (rand()&1)==0;
}
// Insert new head node, add layer
if(insertUp)
{
head = new Node(new Node(NULL,downNode,num), head, -1);
}
}
bool erase(int num) {
Node *p = head;
bool seen = false;
while (p)
{
// The current layer finds the next smallest point to the right
while (p->right && p->right->val < num)
{
p = p->right;
}
// Invalid point, or too large, go to the next level
if (!p->right || p->right->val > num)
{
p = p->down;
}
else
{
// Search for target node, delete operation, result recorded as true
// Continue searching down and delete a set of target nodes
seen = true;
p->right = p->right->right;
p = p->down;
}
}
return seen;
}
};2.Java version (refer to Leetcode1206 problem solving)
class Skiplist {
/**
* Max layers
*/
private static int DEFAULT_MAX_LEVEL = 32;
/**
* The probability of random layers, that is, the number of layers randomly generated, above the first layer (excluding the first layer), with no more than maxLevel layers and a starting number of layers of 1
*/
private static double DEFAULT_P_FACTOR = 0.25;
Node head = new Node(null,DEFAULT_MAX_LEVEL); //Head Node
int currentLevel = 1; //Represents the actual number of layers of the current node, starting at 1
public Skiplist() {
}
public boolean search(int target) {
Node searchNode = head;
for (int i = currentLevel-1; i >=0; i--) {
searchNode = findClosest(searchNode, i, target);
if (searchNode.next[i]!=null && searchNode.next[i].value == target){
return true;
}
}
return false;
}
/**
*
* @param num
*/
public void add(int num) {
int level = randomLevel();
Node updateNode = head;
Node newNode = new Node(num,level);
// Calculate the actual number of levels of the current num index, and add the index from that level
for (int i = currentLevel-1; i>=0; i--) {
//Find the list closest to num in this layer
updateNode = findClosest(updateNode,i,num);
if (i<level){
if (updateNode.next[i]==null){
updateNode.next[i] = newNode;
}else{
Node temp = updateNode.next[i];
updateNode.next[i] = newNode;
newNode.next[i] = temp;
}
}
}
if (level > currentLevel){ //If the number of layers randomly generated is larger than the current number, the head er that exceeds currentLevel points directly to newNode
for (int i = currentLevel; i < level; i++) {
head.next[i] = newNode;
}
currentLevel = level;
}
}
public boolean erase(int num) {
boolean flag = false;
Node searchNode = head;
for (int i = currentLevel-1; i >=0; i--) {
searchNode = findClosest(searchNode, i, num);
if (searchNode.next[i]!=null && searchNode.next[i].value == num){
//Find the node in this layer
searchNode.next[i] = searchNode.next[i].next[i];
flag = true;
continue;
}
}
return flag;
}
/**
* Find a node whose level layer value is greater than node
*/
private Node findClosest(Node node,int levelIndex,int value){
while ((node.next[levelIndex])!=null && value >node.next[levelIndex].value){
node = node.next[levelIndex];
}
return node;
}
/**
* Random One Layer
*/
private static int randomLevel(){
int level = 1;
while (Math.random()<DEFAULT_P_FACTOR && level<DEFAULT_MAX_LEVEL){
level ++ ;
}
return level;
}
class Node{
Integer value;
Node[] next;
public Node(Integer value,int size) {
this.value = value;
this.next = new Node[size];
}
public String toString() {
return String.valueOf(value);
}
}
}